A simple method for identifying objective questions
原创
A simple method for identifying objective questions
原创
Swing Dunn
发布于 2025-10-18 16:27:32
发布于 2025-10-18 16:27:32
A simple method for identifying the answers to multiple-choice questions on general answer sheets. This method can effectively locate the filled-in answers for answer sheets with standardized filling procedures and good test paper quality.
[ps]The image has been corrected for both sides and inversion, as well as for the correction of the positioning points.
1.read the original scanned img

ori_img
2.Obtain the multiple-choice blocks, perform simple preprocessing, enhance contrast and reduce noise
#增强图像对比度
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
gray_c = clahe.apply(gray)
#高斯滤波
gray_c = cv2.GaussianBlur(gray_c, (3, 3), 0)
gray_c
3.convert to binary
g_threshold, binary = cv2.threshold(gray_c, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
binary
4.Taking into account that even after image correction, there may still be a very small error within the objective question area compared to the coordinate area provided by the template, this might be due to local deformation.It is also necessary to consider situations where students might fill in the option areas in an incorrect manner, such as illegibly or incompletely.Therefore, here we will appropriately expand the option area provided by the template to ensure that the statistical area completely covers the target area.
In the expanded area, count the number and ratio of white pixels.
input_rate = []
for i in range(len(template_block_pos)):
block_lt_pt = template_block_pos[i]
ex_block_ltpt = (block_lt_pt[0] - 6, block_lt_pt[1] - 3)
ex_block_size = (template_block_size[0] + 12, template_block_size[1] + 6)
ex_block_rbpt = (ex_block_ltpt[0] + ex_block_size[0] , ex_block_ltpt[1] + ex_block_size[1])
cv2.rectangle(display_bin, (ex_block_ltpt[0], ex_block_ltpt[1]), (ex_block_rbpt[0] , ex_block_rbpt[1]), (0,255,0), 1)
ex_block_arr = binary[ex_block_ltpt[1] : ex_block_rbpt[1], ex_block_ltpt[0] : ex_block_rbpt[0]]
non_zero_count = np.count_nonzero(ex_block_arr)
input_rate.append(non_zero_count / (ex_block_size[0] * ex_block_size[1]))
#img_show(display_bin)
input_rate_arr = np.reshape(input_rate,(5, 4))
Statistical range
Statistical data:
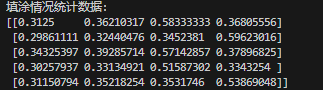
Statistical data
It can be seen that there are obvious differences between the filled blocks and the unfilled blocks.This can be more clearly seen through the line graph.The values of the filled-in items are all significantly greater than 0.5.
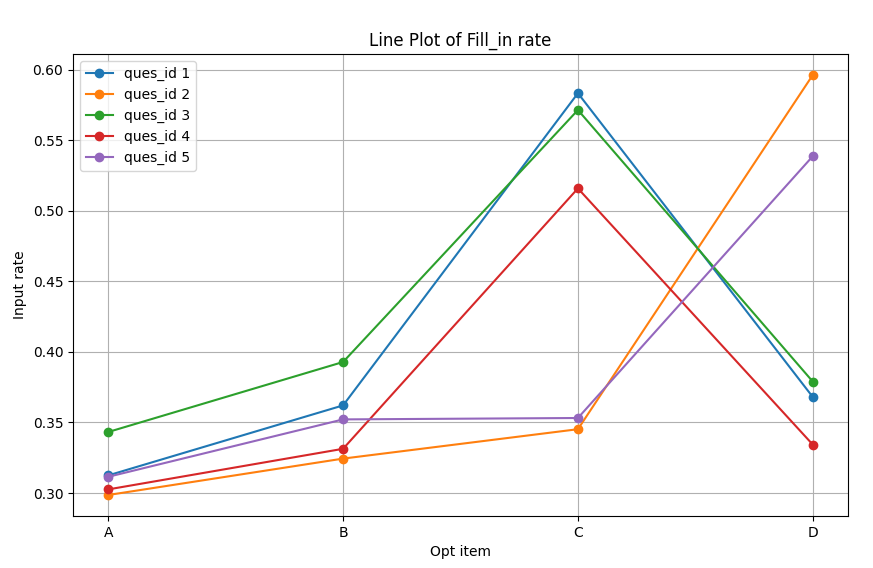
Fill-in condition
5.Perform a binomial k-means clustering on the result data.
Of course, there might be other methods to analyze the results. However, in this case, the filling method was used successfully, so this approach was chosen.
data = np.array([input_rate])
data_reshaped = data.T
# 创建KMeans对象,设置聚类数为2
kmeans = KMeans(n_clusters=2, random_state=0)
kmeans.fit(data_reshaped)
labels = kmeans.labels_
print("Cluster labels:", labels)
ans = np.reshape(labels,(5,4))
ans = np.where(ans > 0 , 0,1)
print('result: ', ans)The clustering results are as follows. It can be seen that the item marked as "1" is the one filled in, and it can effectively identify the location of the answer.
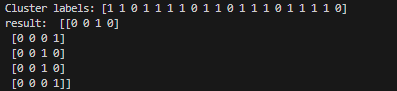
ans array
6.Final result

final result
The limitations of the method:
1.The influence of printing cannot be eliminated. Some question blocks on the test papers may be very small, while the printing of the letters and borders is rather thick.
2.Some of the answer sheets may have very illegible filling marks, or the filling may be very faint, with very small filled areas that cannot be effectively distinguished from the un-filled sections.This situation cannot yield effective clustering results.

unsatisfied fill-in condition
3.The size of the option blocks varies across different test papers. The fixed expansion value may cause changes in the effective range, thereby affecting the accuracy of the results.
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号