两张大图一次性讲透k8s调度器工作原理


面试常被追问k8s调度器工作原理,一图胜千言,收藏 == 学废。
kube-scheduler负责将k8s pod调度到worker节点上。
当你部署pod时,manifest文件pod规格会指定cpu、memory、亲和性affinity、污点taints、优先级、持久盘等。
调度器的主要工作是识别create request然后选择满足要求的最佳节点。
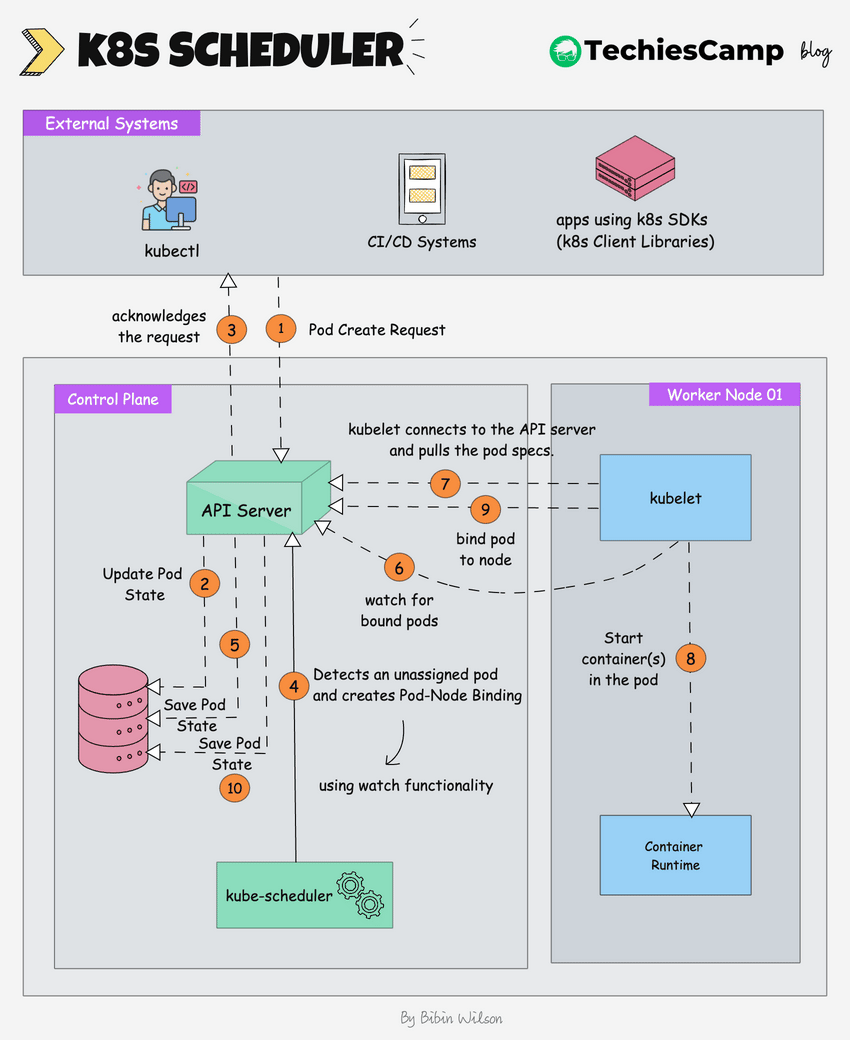
分步解释:
Pod Create Request: 外部系统(kubectl、cicd)发出了创建一个新pod的请求。kube-api server收到请求,然后将pod状态保存到etcd(集群的分布式kv存储)。- api server给外部系统回发确认信息。
kube scheduler持续监听unassignedods (使用watch机制),注意到新的pod。
4.1. scheduler会根据pod的规格(cpu、memory、亲和性)决定pod应在哪个节点上运行,并创建pod-node binding,它会将此绑定决定通知api server (调度的核心看下文)。
- scheduler更新etcd中pod的状态(通过api server): ① 标记pod为“scheduled”状态 ② 记录被分配的节点。
- 被选中节点上的
kubelet, 也会持续监听新pod分配(使用watch机制),侦测到最新的已经分配的pod。 kubelet从api server拉取pod manifest信息, 内容包含启动需要的镜像、volume、网络配置。- kubelet指示容器运行时为pod启动容器。
- kubelet 通知apiserver: 现在 pod 已与节点绑定。
- api server更新etcd 中pod的最终状态,确保当前状态正确反映在集群数据库etcd。
4.1 kube-scheduler是如何选中节点?[1]
在k8s集群,会存在不止一个节点,scheduler是如何从所有worker节点中选中节点。
scheduler一般包含两阶段:
- 调度选择期
- 绑定期

4.1.1 调度选择期: 预选-> 优选
在这个时期,kueb-scheduler使用过滤和打分策略选择最佳节点。
① 过滤Filtering :cheduler找到pod能被调度的最合适的节点。
从本质上讲,它会利用pod规格(cpu、memory、亲和性、污点、持久盘)过滤掉不适合运行特定pod的节点。
对于大集群, 预选Predicates之后, 也不会对剩下的所有节点都做打分。
scheduler有一个配置参数percentageOfNodesToScore决定了参与打分的节点比例。 默认值取值参考集群大小:小集群50%--->大集群5%
即使这个百分比被设置的很小,scheduler会持续搜索直到找到了𝗺𝗶𝗻𝗙𝗲𝗮𝘀𝗶𝗯𝗹𝗲𝗡𝗼𝗱𝗲𝘀𝗧𝗼𝗙𝗶𝗻𝗱数量。
② Scoring: 给节点打分, scheduler给节点排名
k8s使用Priorities(Scorers)来给节点打分,打分机制通过各种scheduling 插件来实现。
- pod priority: 高优先级的pod通过影响打分过程影响节点选择(高优Pod会先于低优Pod被调度)。
- pod拓扑分布: 确保 pod 分布在不同的拓扑域(如区域或节点)中,避免在一个地方集中过多pod。
scheduler通过调用多个调度插件给节点打分, 每个插件都会根据特定标准对节点进行评估,并累计到最终得分。
最后,排名最高的worker节点会被选中调度pod。如果所有节点的排名相同,则会随机选择一个节点。
一旦节点被选中,调度器在api server创建了binding event(pod+node)。
4.1.2 绑定期
scheduler尝试将pod绑定到得分最高的节点,如果绑定失败,scheduler一般会选用次高得分的节点。
自定义Scheduler
开发者可以创建自定义scheduler,在集群内和原生调度器一起运行。
当部署pod时,可以在pod manifest文件指定自定义的Scheduler, 这样调度器的调度决定就会基于你自定义的调度逻辑。
Pluggable Scheduling Framework
调度器有一个可插拔的调度框架,这意味着开发者可以在调度工作流中添加自定义的插件。
参考资料
[1]
kube-scheduler是如何选中节点?: https://blog.techiescamp.com/docs/kubernetes-scheduler-chooses-a-node/
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-10-25,如有侵权请联系 cloudcommunity@tencent.com 删除
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号