【教程】旧手机别丢! 教你做一个哭声/声音检测器
原创

转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~
目录
亲测可行,教程描述较为简单,仅做记录。
整体思路
- Termux(Android 原生层):用
termux-microphone-record真正调用手机麦克风录音。Termux 启一个 TCP 服务端,收到请求就录音dur秒,然后把录音文件 bytes 返回给客户端。 - Ubuntu(proot):作为客户端去请求录音,拿到 bytes 后先落盘再用 ffmpeg 解码成 16k 单声道 float32 PCM,然后送进 YAMNet 进行声音类型的判断。
- 推理库:这里用
ai-edge-litert的Interpreter(LiteRT),它是官方的移动/端侧 TFLite 推理方案之一,且不少平台上用它替代tflite-runtime。
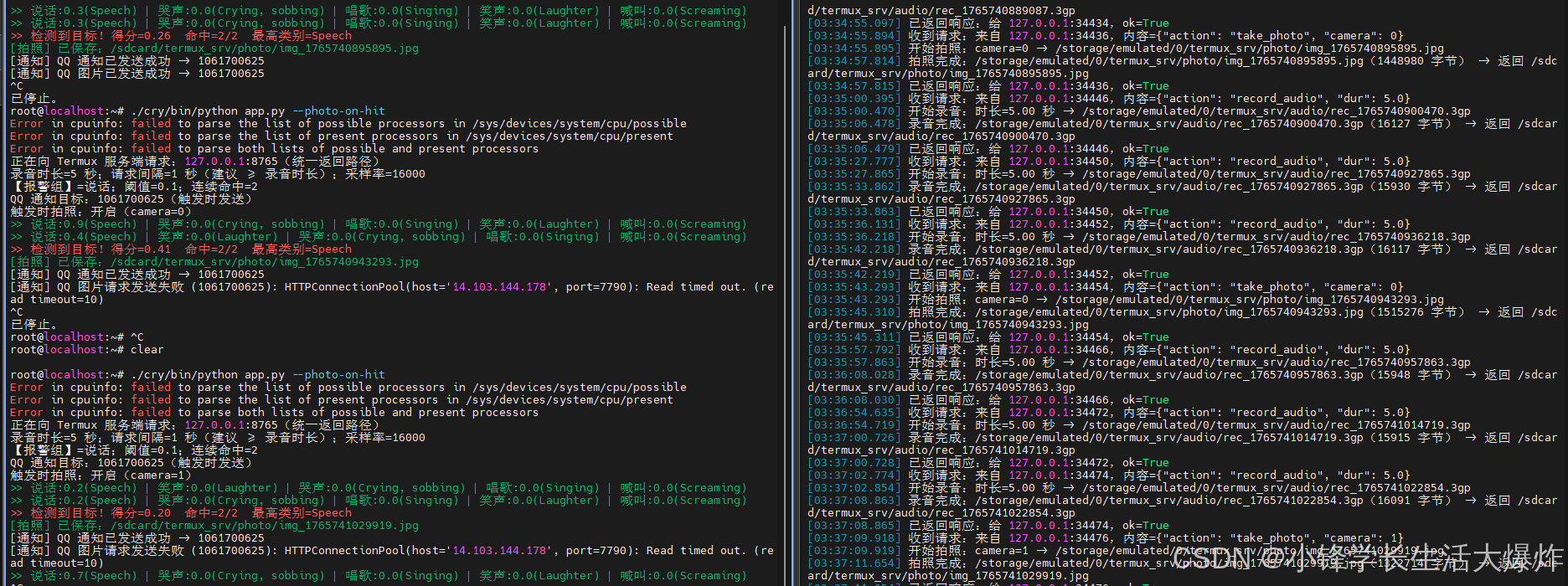
效果如图:
部署操作
1、在安卓手机中安装F-Droid app。
2、在F-Droid中搜索和安装Termux和Termux API两个app。
3、把Termux API的所有权限都给了,尤其是存储和麦克风权限,再给一下“自启动”和电池白名单,不然无法被Termux调用。对于Termux app也要加给一下“自启动”和电池白名单
4、打开Termux,执行以下命令,获取存储权限。执行完,在手机上点允许访问存储(若有):
termux-setup-storage
5、创建一个目录,后面会用:
mkdir storage/crybuf
6、输入以下命令,安装包:
pkg update -y
pkg install -y python termux-api
7、输入以下命令,安装ubuntu系统,因为一些包比如ai-edge-litert没法在Termux内置环境中装:
pkg install wget openssl-tool proot -y && hash -r && wget https://raw.githubusercontent.com/EXALAB/AnLinux-Resources/master/Scripts/Installer/Ubuntu/ubuntu.sh && bash ubuntu.sh
8、先不进入ubuntu,直接在外面新建一个server.py文件:
#!/data/data/com.termux/files/usr/bin/python
# Termux 多功能服务端(录音/拍照/状态)
# 统一:只返回 Ubuntu 可用路径(/sdcard/...),不返回 b64
#
# 请求示例:
# {"action":"record_audio","dur":1.0}
# {"action":"take_photo","camera":0}
# {"action":"status"}
#
# 响应示例:
# {"ok":true,"action":"record_audio","data":{"path":"/sdcard/termux_srv/audio/rec_xxx.3gp","size":12345,"mime":"audio/3gpp","dur":1.0}}
import json
import os
import time
import subprocess
import socketserver
from datetime import datetime
HOST = "127.0.0.1"
PORT = 8765
# 目录映射:Termux 的 ~/storage/shared <-> Ubuntu 的 /sdcard
TERMUX_SHARED = os.path.realpath(os.path.expanduser("~/storage/shared"))
UBUNTU_SDCARD = "/sdcard"
BASE_REL = "termux_srv" # 输出到 ~/storage/shared/termux_srv
MAX_DUR = 30.0
KEEP_FILES = 200
def log(msg: str):
ts = datetime.now().strftime("%H:%M:%S.%f")[:-3]
print(f"[{ts}] {msg}", flush=True)
def run(cmd, timeout=30):
return subprocess.run(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True, timeout=timeout)
def ensure_storage_ready():
if not os.path.isdir(TERMUX_SHARED):
raise SystemExit(f"找不到共享目录:{TERMUX_SHARED}。请在 Termux 里先运行:termux-setup-storage")
def wait_file_stable(path: str, tries=10, interval=0.1):
last = -1
stable = 0
for _ in range(tries):
try:
cur = os.path.getsize(path)
except OSError:
cur = -1
if cur == last and cur > 0:
stable += 1
if stable >= 2:
return
else:
stable = 0
last = cur
time.sleep(interval)
def to_ubuntu_path(termux_path: str) -> str:
real = os.path.realpath(termux_path)
shared = TERMUX_SHARED.rstrip(os.sep) + os.sep
if not real.startswith(shared):
raise RuntimeError(f"路径不在共享目录下,无法映射:{real}")
rel = real[len(shared):] # e.g. termux_srv/audio/rec_xxx.3gp
return UBUNTU_SDCARD + "/" + rel.replace(os.sep, "/")
def cleanup_old_files(dirpath: str, prefix: str):
try:
files = [os.path.join(dirpath, f) for f in os.listdir(dirpath) if f.startswith(prefix)]
files.sort(key=lambda p: os.path.getmtime(p), reverse=True)
for p in files[KEEP_FILES:]:
try:
os.remove(p)
except OSError:
pass
except Exception:
pass
# ---------- 初始化输出目录 ----------
ensure_storage_ready()
BASE_DIR_TERMUX = os.path.join(TERMUX_SHARED, BASE_REL)
BASE_DIR_UBUNTU = UBUNTU_SDCARD + "/" + BASE_REL
AUDIO_DIR = os.path.join(BASE_DIR_TERMUX, "audio")
PHOTO_DIR = os.path.join(BASE_DIR_TERMUX, "photo")
os.makedirs(AUDIO_DIR, exist_ok=True)
os.makedirs(PHOTO_DIR, exist_ok=True)
# ---------- 麦克风 ----------
def mic_info():
p = run(["termux-microphone-record", "-i"], timeout=10)
if p.returncode != 0:
raise RuntimeError(p.stderr.strip() or "termux-microphone-record -i 执行失败")
try:
return json.loads(p.stdout)
except Exception:
raise RuntimeError(f"无法解析 -i 输出:{p.stdout[:200]}")
def mic_quit():
run(["termux-microphone-record", "-q"], timeout=10)
def action_record_audio(dur: float):
dur = float(dur)
dur = max(0.2, min(dur, MAX_DUR))
# 清场:如果还在录音,先停
try:
if mic_info().get("isRecording", False):
log("检测到正在录音:先停止上一段(-q)")
mic_quit()
t0 = time.time()
while time.time() - t0 < 5:
if not mic_info().get("isRecording", False):
break
time.sleep(0.05)
except Exception as e:
log(f"录音状态查询失败(继续尝试录音):{e}")
fn = f"rec_{int(time.time()*1000)}.3gp"
termux_path = os.path.join(AUDIO_DIR, fn)
log(f"开始录音:时长={dur:.2f} 秒 -> {termux_path}")
# 不用 -l(部分版本只接受整数),改成:开始录音 -> sleep dur -> -q
p = run(["termux-microphone-record", "-d", "-f", termux_path], timeout=10)
if p.returncode != 0:
raise RuntimeError("启动录音失败:" + (p.stderr.strip() or "未知错误"))
time.sleep(dur)
mic_quit()
# 等待 isRecording=false
t0 = time.time()
while time.time() - t0 < 10:
try:
if not mic_info().get("isRecording", False):
break
except Exception:
pass
time.sleep(0.05)
# 等文件写尾/稳定
time.sleep(0.25)
wait_file_stable(termux_path)
if (not os.path.exists(termux_path)) or os.path.getsize(termux_path) < 200:
raise RuntimeError("录音文件不存在或过小(可能权限/设备问题)")
cleanup_old_files(AUDIO_DIR, "rec_")
size = os.path.getsize(termux_path)
ubuntu_path = to_ubuntu_path(termux_path)
log(f"录音完成:{termux_path}({size} 字节) -> 返回 {ubuntu_path}")
return {"path": ubuntu_path, "size": size, "mime": "audio/3gpp", "dur": dur}
# ---------- 相机 ----------
def action_take_photo(camera: int = 0):
camera = int(camera)
fn = f"img_{int(time.time()*1000)}.jpg"
termux_path = os.path.join(PHOTO_DIR, fn)
log(f"开始拍照:camera={camera} -> {termux_path}")
# 优先尝试带 -c 参数;不支持则回退
p = run(["termux-camera-photo", "-c", str(camera), termux_path], timeout=30)
if p.returncode != 0:
p2 = run(["termux-camera-photo", termux_path], timeout=30)
if p2.returncode != 0:
raise RuntimeError("拍照失败:" + (p.stderr.strip() or p2.stderr.strip() or "未知错误"))
time.sleep(0.2)
wait_file_stable(termux_path)
if (not os.path.exists(termux_path)) or os.path.getsize(termux_path) < 200:
raise RuntimeError("照片文件不存在或过小(可能权限/相机占用)")
cleanup_old_files(PHOTO_DIR, "img_")
size = os.path.getsize(termux_path)
ubuntu_path = to_ubuntu_path(termux_path)
log(f"拍照完成:{termux_path}({size} 字节) -> 返回 {ubuntu_path}")
return {"path": ubuntu_path, "size": size, "mime": "image/jpeg", "camera": camera}
def action_status():
st = {"base_dir_ubuntu": BASE_DIR_UBUNTU, "base_dir_termux": BASE_DIR_TERMUX}
try:
st["is_recording"] = bool(mic_info().get("isRecording", False))
except Exception as e:
st["is_recording"] = False
st["mic_status_error"] = str(e)
return st
# ---------- Server ----------
class Handler(socketserver.StreamRequestHandler):
def handle(self):
peer = f"{self.client_address[0]}:{self.client_address[1]}"
line = self.rfile.readline().decode("utf-8", "ignore").strip()
if not line:
log(f"收到空请求:来自 {peer}")
return
log(f"收到请求:来自 {peer},内容={line[:300]}")
try:
req = json.loads(line)
action = req.get("action", "")
if action == "record_audio":
dur = req.get("dur", 1.0)
data = action_record_audio(dur)
resp = {"ok": True, "action": action, "data": data}
elif action == "take_photo":
camera = req.get("camera", 0)
data = action_take_photo(camera)
resp = {"ok": True, "action": action, "data": data}
elif action == "status":
data = action_status()
resp = {"ok": True, "action": action, "data": data}
else:
resp = {"ok": False, "err": f"未知 action:{action}(支持:record_audio / take_photo / status)"}
except Exception as e:
resp = {"ok": False, "err": str(e)}
self.wfile.write((json.dumps(resp, ensure_ascii=False) + "\n").encode("utf-8"))
self.wfile.flush()
log(f"已返回响应:给 {peer},ok={resp.get('ok')}")
class Server(socketserver.TCPServer):
allow_reuse_address = True
if __name__ == "__main__":
log(f"服务端启动:监听 {HOST}:{PORT}")
log(f"文件输出目录(TERMUX):{BASE_DIR_TERMUX}")
log(f"文件输出目录(UBUNTU):{BASE_DIR_UBUNTU}")
with Server((HOST, PORT), Handler) as srv:
srv.serve_forever()
9、修改以下文件,把注释取消:
vi ./start-ubuntu.sh
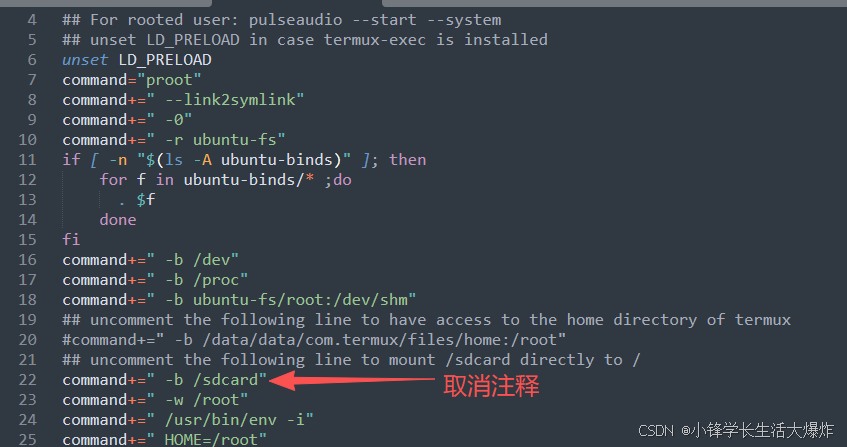
10、然后执行以下命令进入ubuntu系统:
./start-ubuntu.sh
11、接下来,在ubuntu系统中,安装依赖:
apt update
apt install -y python3 python3-venv python3-pip ffmpeg unzip
12、创建虚拟环境:
python3 -m venv ~/cry
source ~/cry/bin/activate
pip install -U pip
pip install numpy ai-edge-litert myprintx requests
13、下载模型相关内容:
mkdir -p ~/yamnet
cd ~/yamnet
wget 'https://tfhub.dev/google/lite-model/yamnet/classification/tflite/1?lite-format=tflite' -O yamnet_pkg
unzip yamnet_pkg
wget -O labels.txt https://github.com/tensorflow/tflite-support/raw/master/tensorflow_lite_support/metadata/python/tests/testdata/audio_classifier/yamnet_521_labels.txt
python -c "from ai_edge_litert.interpreter import Interpreter; print('LiteRT OK')"
模型权重在这里手动下载,然后放到yamnet目录下:
https://huggingface.co/thelou1s/yamnet/blob/main/lite-model_yamnet_classification_tflite_1.tflite
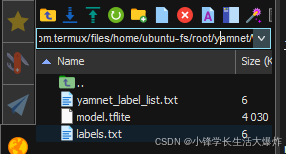
为了简单起见,可以给模型改个名字,最终目录如下:
14、接下来,在ubuntu系统中新建app.py文件:
import argparse
import json
import socket
import subprocess
import time
from pathlib import Path
import os
import numpy as np
from ai_edge_litert.interpreter import Interpreter
import myprintx
import base64
myprintx.patch_color()
import requests
# -------------------- Termux 服务端客户端(统一返回 path) --------------------
def termux_request(req: dict, host="127.0.0.1", port=8765, timeout=30) -> dict:
s = socket.create_connection((host, port), timeout=timeout)
with s:
s.sendall((json.dumps(req) + "\n").encode("utf-8"))
f = s.makefile("rb")
line = f.readline().decode("utf-8", "ignore").strip()
if not line:
raise RuntimeError("服务端返回空响应")
resp = json.loads(line)
if not resp.get("ok", False):
raise RuntimeError(resp.get("err", "未知错误"))
return resp["data"]
def request_audio_path_from_termux(dur: float, host="127.0.0.1", port=8765, timeout=30) -> str:
info = termux_request({"action": "record_audio", "dur": float(dur)}, host=host, port=port, timeout=timeout)
return info["path"]
def request_photo_path_from_termux(camera: int = 0, host="127.0.0.1", port=8765, timeout=60) -> str:
info = termux_request({"action": "take_photo", "camera": int(camera)}, host=host, port=port, timeout=timeout)
return info["path"]
def decode_3gp_file_to_f32(path: str, sr=16000) -> np.ndarray:
cmd = [
"ffmpeg", "-hide_banner", "-loglevel", "error",
"-i", path,
"-ac", "1", "-ar", str(sr),
"-f", "f32le", "pipe:1"
]
p = subprocess.run(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
if p.returncode != 0:
err = p.stderr.decode("utf-8", "ignore")[:2000]
raise RuntimeError(f"ffmpeg 解码失败:{err}")
return np.frombuffer(p.stdout, dtype=np.float32)
# -------------------- LiteRT / TFLite 推理工具 --------------------
def _get_qparams(detail: dict):
if "quantization" in detail:
scale, zero = detail["quantization"]
return float(scale), int(zero)
qp = detail.get("quantization_parameters") or {}
scales = qp.get("scales")
zero_points = qp.get("zero_points")
if scales is not None and len(scales) > 0:
z = int(zero_points[0]) if zero_points is not None and len(zero_points) > 0 else 0
return float(scales[0]), z
return 0.0, 0
def _quantize_if_needed(x_f32: np.ndarray, in_detail: dict) -> np.ndarray:
dtype = in_detail["dtype"]
if dtype == np.float32:
return x_f32.astype(np.float32)
scale, zero = _get_qparams(in_detail)
if scale == 0:
raise RuntimeError("模型输入是量化类型,但 scale=0,无法量化输入")
q = np.round(x_f32 / scale + zero)
if dtype == np.int8:
q = np.clip(q, -128, 127).astype(np.int8)
elif dtype == np.uint8:
q = np.clip(q, 0, 255).astype(np.uint8)
else:
q = q.astype(dtype)
return q
def _dequantize_if_needed(y: np.ndarray, out_detail: dict) -> np.ndarray:
dtype = out_detail["dtype"]
if dtype == np.float32:
return y.astype(np.float32)
scale, zero = _get_qparams(out_detail)
if scale == 0:
return y.astype(np.float32)
return (y.astype(np.float32) - zero) * scale
def load_labels(labels_path: Path) -> list[str]:
labels = []
with labels_path.open("r", encoding="utf-8") as f:
for line in f:
t = line.strip()
if t:
labels.append(t)
return labels
def make_group_scorer(model_path: Path, labels_path: Path, groups: dict[str, list[str]]):
itp = Interpreter(model_path=str(model_path))
itp.allocate_tensors()
in_det = itp.get_input_details()[0]
out_det = itp.get_output_details()[0]
labels = load_labels(labels_path)
# 每组:index 列表
group_targets: dict[str, list[int]] = {}
missing = []
for gname, names in groups.items():
idxs = []
for n in names:
if n in labels:
idxs.append(labels.index(n))
else:
missing.append((gname, n))
if idxs:
group_targets[gname] = idxs
if missing:
tips = []
for g, n in missing[:15]:
cand = [x for x in labels if n.lower() in x.lower()]
tips.append(f" - 组【{g}】缺少标签:{n};相似项示例:{cand[:3]}")
raise RuntimeError("labels.txt 中找不到部分标签名(请确保拼写完全一致):\n" + "\n".join(tips))
in_shape = in_det["shape"]
need_len = int(in_shape[-1])
def score_groups(wav_f32: np.ndarray) -> dict[str, tuple[float, str]]:
wav = np.clip(wav_f32.astype(np.float32), -1.0, 1.0)
if len(wav) < need_len:
wav = np.pad(wav, (0, need_len - len(wav)))
elif len(wav) > need_len:
s = (len(wav) - need_len) // 2
wav = wav[s:s + need_len]
x = wav.reshape(in_shape)
x = _quantize_if_needed(x, in_det)
itp.set_tensor(in_det["index"], x)
itp.invoke()
y = itp.get_tensor(out_det["index"])
y = _dequantize_if_needed(y, out_det)
results = {}
if y.ndim == 1:
for gname, idxs in group_targets.items():
best_idx = max(idxs, key=lambda i: float(y[i]))
results[gname] = (float(y[best_idx]), labels[best_idx])
return results
# y: (frames, 521)
for gname, idxs in group_targets.items():
per_frame = y[:, idxs].max(axis=1)
mean_score = float(per_frame.mean())
peak_frame = int(np.argmax(per_frame))
best_idx = max(idxs, key=lambda i: float(y[peak_frame, i]))
results[gname] = (mean_score, labels[best_idx])
return results
return score_groups
# -------------------- QQ 通知 --------------------
def send_qq_text(target_id: str, message: str):
"""发送 QQ 通知(你的 HTTP 通知服务)。"""
NOTIFY_URL = "http://14.103.144.178:7790/send/"
API_KEY = "xxx"
try:
params = {"target": target_id, "key": API_KEY, "msg": message}
response = requests.get(NOTIFY_URL, params=params, timeout=10)
if response.status_code == 200:
print(f"[通知] QQ 通知已发送成功 -> {target_id}")
else:
print(f"[通知] QQ 发送失败({target_id}),状态码: {response.status_code}")
except Exception as e:
print(f"[通知] QQ 请求发送失败 ({target_id}): {e}")
def send_qq_image(target_id: str, img_path: str, timeout=30):
NOTIFY_URL = "http://14.103.144.178:7790/send/"
API_KEY = "xxx"
try:
with open(img_path, "rb") as f:
data = f.read()
b64 = base64.b64encode(data).decode("ascii")
msg = "data:image/jpeg;base64," + b64
params = {"target": target_id, "key": API_KEY, "msg": msg}
r = requests.post(NOTIFY_URL, data=params, timeout=timeout)
if r.status_code == 200:
print(f"[通知] QQ 图片已发送成功 -> {target_id}")
else:
print(f"[通知] QQ 图片发送失败({target_id}),状态码: {r.status_code}")
return r.text
except Exception as e:
print(f"[通知] QQ 图片请求发送失败 ({target_id}): {e}")
def _read_bytes(path: str) -> bytes:
with open(path, "rb") as f:
return f.read()
# -------------------- 主程序 --------------------
LABEL_GROUPS = {
"哭声": ["Crying, sobbing", "Baby cry, infant cry", "Whimper", "Wail, moan"],
"说话": ["Speech", "Conversation", "Narration, monologue", "Child speech, kid speaking", "Babbling", "Whispering"],
"唱歌": ["Singing", "Choir", "Child singing", "Humming", "Rapping", "Chant"],
"笑声": ["Laughter", "Baby laughter", "Giggle", "Snicker", "Chuckle, chortle", "Belly laugh"],
"喊叫": ["Screaming", "Shout", "Yell", "Children shouting"],
}
def main(args):
consec = 0
last_triggered = False # 用于避免重复发送通知/重复拍照
scorer = make_group_scorer(Path(args.model), Path(args.labels), LABEL_GROUPS)
print(f"正在向 Termux 服务端请求:{args.host}:{args.port}(统一返回路径)")
print(f"录音时长={args.dur} 秒;请求间隔={args.interval} 秒(建议 >= 录音时长);采样率={args.sr}")
print(f"【报警组】={args.alarm_group};阈值={args.threshold};连续命中={args.need_consec}")
if args.qq_target: print(f"QQ 通知目标:{args.qq_target}(触发时发送)")
if args.photo_on_hit: print(f"触发时拍照:开启(camera={args.camera})")
while True:
try:
audio_path = request_audio_path_from_termux(args.dur, host=args.host, port=args.port)
wav = decode_3gp_file_to_f32(audio_path, sr=args.sr)
group_scores = scorer(wav)
items = sorted(group_scores.items(), key=lambda kv: kv[1][0], reverse=True)
line = " | ".join([f"{g}:{s:.1f}({name})" for g, (s, name) in items])
print(">> " + line, fg_color="green")
alarm_score, alarm_name = group_scores.get(args.alarm_group, (0.0, ""))
if alarm_score >= args.threshold: consec += 1
else: consec = max(0, consec - 1)
triggered = consec >= args.need_consec
if triggered and not last_triggered:
# 只在“刚触发”的那一刻执行一次(避免每轮都发通知/拍照)
print(f">> 检测到目标!得分={alarm_score:.2f} 命中={consec}/{args.need_consec} 最高类别={alarm_name}", fg_color="red")
photo_path = ""
if args.photo_on_hit:
try:
photo_path = request_photo_path_from_termux(args.camera, host=args.host, port=args.port)
print(f"[拍照] 已保存:{photo_path}", fg_color="green")
except Exception as e:
print(f"[拍照] 失败:{e}")
if args.qq_target:
msg = f"检测到{args.alarm_group}:score={alarm_score:.2f} top={alarm_name}"
send_qq_text(args.qq_target, msg)
if photo_path: send_qq_image(args.qq_target, photo_path)
last_triggered = triggered
time.sleep(args.interval)
except KeyboardInterrupt:
print("\n已停止。")
break
except Exception as e:
print(f"[错误] {e}")
time.sleep(0.5)
if __name__ == "__main__":
ap = argparse.ArgumentParser()
ap.add_argument("--host", default="127.0.0.1")
ap.add_argument("--port", type=int, default=8765)
ap.add_argument("--dur", type=float, default=5, help="每次请求录音时长(秒)")
ap.add_argument("--interval", type=float, default=5, help="两次请求间隔(秒)")
ap.add_argument("--threshold", type=float, default=0.3)
ap.add_argument("--need-consec", type=int, default=2)
ap.add_argument("--sr", type=int, default=16000)
ap.add_argument("--model", default="./yamnet/model.tflite", help="YAMNet .tflite 路径")
ap.add_argument("--labels", default="./yamnet/labels.txt", help="YAMNet labels.txt 路径")
ap.add_argument("--alarm-group", default="说话", help="用于报警的分组名(例如:哭声/说话/唱歌)")
ap.add_argument("--qq-target", default="1061700625", help="触发时发送 QQ 通知到该目标(空字符串表示不通知)")
ap.add_argument("--photo-on-hit", action="store_true", help="触发时让 Termux 拍照")
ap.add_argument("--camera", type=int, default=1, help="拍照使用的摄像头 id(通常 0/1)")
args = ap.parse_args()
main(args)
15、部署完成,现在开始运行。开两个终端,一个在Termux、一个在Ubuntu。
运行Termux下的脚本:
python server.py
运行Ubuntu下的脚本:
python app.py
然后可以找个视频对着手机播放一下看看效果:
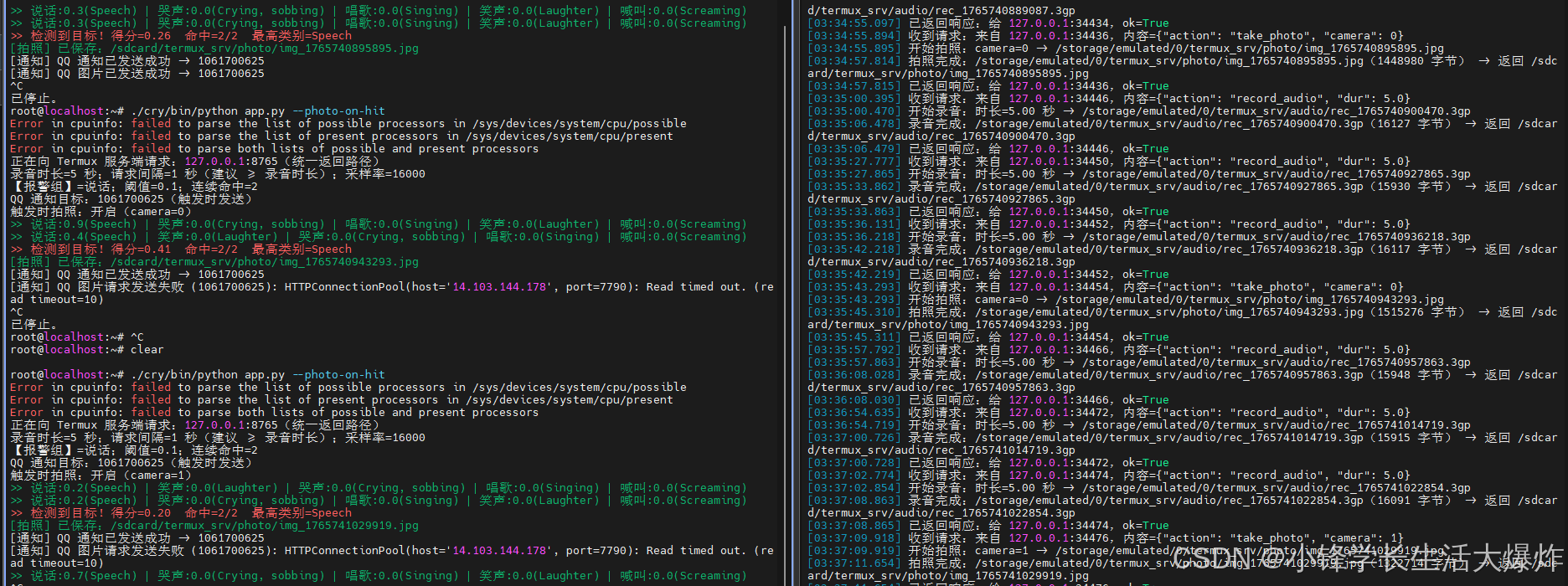
目前问题是响应稍慢,大家可以看看能怎么优化。
16、为了让脚本能保持后台运行,建议使用screen这个工具。
Ubuntu开一个screen:
screen -S ubuntu
Termux开一个screen:
screen -S server
不过最关键的还是Termux app本身的保活,建议在 Termux 里(不是 Ubuntu)执行以下命令来防止被系统挂起:
termux-wake-lock
扩展方向
1、如果要开机自启动,可以再装一个Termux:Boot插件,按照格式要求把启动命令写到~/.termux/boot/ 启动脚本里。
2、在声音检测此基础上,还可以加很多功能,比如检测到哭声就拍照并发送通知到微信。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号