算法基础_数据结构【KMP + Trie 树 + 并查集】

算法基础_数据结构【KMP + Trie 树 + 并查集】

序属秋秋秋
发布于 2025-12-18 15:22:10
发布于 2025-12-18 15:22:10
算法基础_数据结构【KMP + Trie 树 + 并查集
往期《算法基础》回顾:算法基础_基础算法【快速排序 + 归并排序 + 二分查找】 算法基础_基础算法【高精度 + 前缀和 + 差分 + 双指针】 算法基础_基础算法【位运算 + 离散化 + 区间合并】 算法基础_基础算法【算法基础_数据结构【单链表 + 双链表 + 栈 + 队列 + 单调栈 + 单调队列】往期《算法精讲》回顾:算法精讲【整数二分】(实战教学)
---------------KMP---------------
831.KMP字符串
题目介绍

在这里插入图片描述
方法一:
#include <iostream>
using namespace std;
const int N = 100010, M = 1000010; // 定义数组的最大长度
int n, m; // n 是模式串 p 的长度,m 是主串 s 的长度
char p[N], s[M]; // p 是模式串,s 是主串
int ne[N]; // next 数组,用于 KMP 算法
int main()
{
cin >> n >> p + 1 >> m >> s + 1;
//构建 next 数组
for (int i = 2, j = 0; i <= n; i++)
{
while (j && p[i] != p[j + 1]) j = ne[j];
if (p[i] == p[j + 1]) j++;
ne[i] = j;
}
//KMP 匹配过程
for (int i = 1, j = 0; i <= m; i++)
{
while (j && s[i] != p[j + 1]) j = ne[j];
if (s[i] == p[j + 1]) j++;
if (j == n)// 如果 j == n,说明模式串 p 完全匹配
{
printf("%d ", i - n);// 输出匹配的起始位置(从 0 开始计数)
j = ne[j];// 回退 j,继续寻找下一个可能的匹配
}
}
return 0;
}程序执行过程

在这里插入图片描述

在这里插入图片描述
代码片段解释
片段一:
cin >> n >> p + 1 >> m >> s + 1;
cin >> p + 1
- 从输入中读取一个字符串,并将其存储到字符数组
p中。 p + 1表示从p数组的第二个位置(即p[1])开始存储字符串。- 这种写法是为了让字符串的下标从
1开始,而不是从0开始。这样可以更方便地处理字符串匹配问题。
示例:如果输入是 "ababc",则:
p[1] = 'a'p[2] = 'b'p[3] = 'a'p[4] = 'b'p[5] = 'c'
注意:
如果你使用上面的方式为字符数组进行赋值的话,那么在定义字符数组的时候不可以将其定义vector<char> p(N), s(M);这种形式。
因为 vector 不支持直接通过指针偏移的方式输入数据
p + 1 和 s + 1 是 C 风格字符数组的用法,而 vector 是 C++ 的容器,不支持这种操作。
解题思路分析
KMP算法的思路总结: 第一部分:构建 next 数组 第一步:使用双指针遍历整个模式串(指针i=2,指针j=0)
- 第二步:使用while循环判断:
如果指针i指向的模式串的字符与指针j+1指向的模式串的字符不相等的话—>指针j根据next数组进行回退 - 第三步:使用if语句判断:
如果指针i指向的模式串的字符与指针j+1指向的模式串的字符相等的话—>指针j++ - 第四步:不管指针i指向的模式串的字符与指针j+1指向的模式串的字符是否相等,都需要将当前的指针j添加到next数组
第二部分:KMP 匹配过程 第一步:使用双指针遍历整个主串(指针i=1,指针j=0)
- 第二步:使用while循环判断:
如果指针i指向的主串的字符与指针j+1指向的模式串的字符不相等的话—>指针j根据next数组进行回退 - 第三步:使用if语句判断:
如果指针i指向的主串的字符与指针j+1指向的模式串的字符相等的话—>指针j++ - 第四步:使用if语句判断:
如果指针j指向了模式串的末尾---->输出匹配的起始位置 + 指针j根据next数组进行回退
---------------Trie 树---------------
835.Trie字符串统计
题目介绍
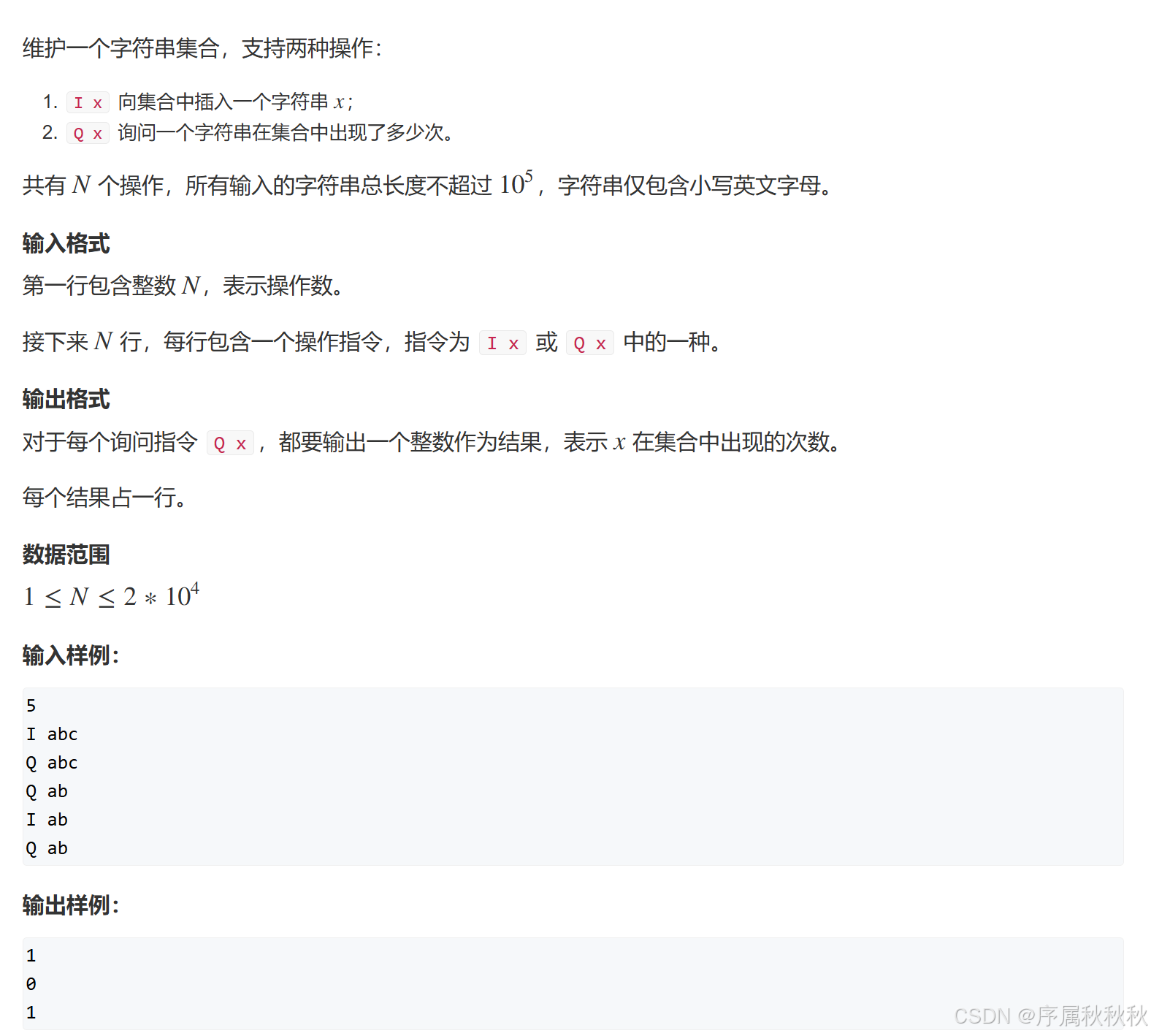
在这里插入图片描述
方法一:
#include <iostream>
using namespace std;
const int N = 100010; // Trie 树的最大节点数
int son[N][26]; // Trie 树的存储结构,son[p][u] 表示节点 p 的第 u 个子节点
int cnt[N]; // 记录以每个节点结尾的字符串的个数
int idx = 0; // 当前 Trie 树中节点的编号,从 1 开始分配
char str[N]; // 用于存储输入的字符串
// 插入操作:将字符串 str 插入到 Trie 树中
void insert(char* str)
{
int p = 0; // 从根节点开始
for (int i = 0; str[i]; i++)
{
int u = str[i] - 'a'; // 将字符转换为索引(0~25)
if (!son[p][u]) son[p][u] = ++idx; // 如果子节点不存在,则创建新节点
p = son[p][u]; // 移动到子节点
}
cnt[p]++; // 以当前节点结尾的字符串计数加 1
}
// 查询操作:查询字符串 str 在 Trie 树中出现的次数
int query(char* str)
{
int p = 0;
for (int i = 0; str[i]; i++)
{
int u = str[i] - 'a';
if (!son[p][u]) return 0; // 如果子节点不存在,说明字符串不存在
p = son[p][u]; // 移动到子节点
}
return cnt[p]; // 返回以当前节点结尾的字符串的计数
}
int main()
{
int n;
scanf("%d", &n);
while (n--)
{
char op[2]; // 用于存储操作类型
scanf("%s%s", op, str); // 输入操作类型和字符串
if (*op == 'I') insert(str);
else printf("%d\n", query(str));
}
return 0;
}程序执行流程

在这里插入图片描述
代码片段解释
解题思路分析
Trie 树(字典树):用于高效地存储和查询字符串。 支持两种操作:
- 插入操作:将一个字符串插入到 Trie 树中。
- 查询操作:查询一个字符串在 Trie 树中出现的次数。
插入操作的思路步骤: 第一步:定义一个int变量p初始化为0(意义:从根节点开始) 第二步:使用for循环遍历要添到Trie树中的字符串中的每一个字符
- 第三步:将遍历到字符的转换为索引(0~25)并存入变量u中
- 第四步:使用if语句判断节点 p 的第 u 个子节点是否为存在(即:是否为0)
- 第五步:如果为0,则创建该节点(即:将其赋值为++idx)
- 第六步: 移动到子节点(即:更新p为其值)
第七步:以当前节点结尾的字符串计数加 1(即:p为索引的cnt数组++)
查询操作的思路步骤:(基本上和插入操作类似)
- 判断节点 p 的第 u 个子节点是否为0后做出的操作不同
- 插入操作:
son[p][u] = ++idx; // 如果子节点不存在,则创建新节点 - 查询操作:
return 0; // 如果子节点不存在,说明字符串不存在
- 插入操作:
- 遍历完字符串中的所有字符后做出的操作不同:
- 插入操作:
cnt[p]++; // 以当前节点结尾的字符串计数加 1 - 查询操作:
return cnt[p]; // 返回以当前节点结尾的字符串的计数
- 插入操作:
143.最大异或对
题目介绍
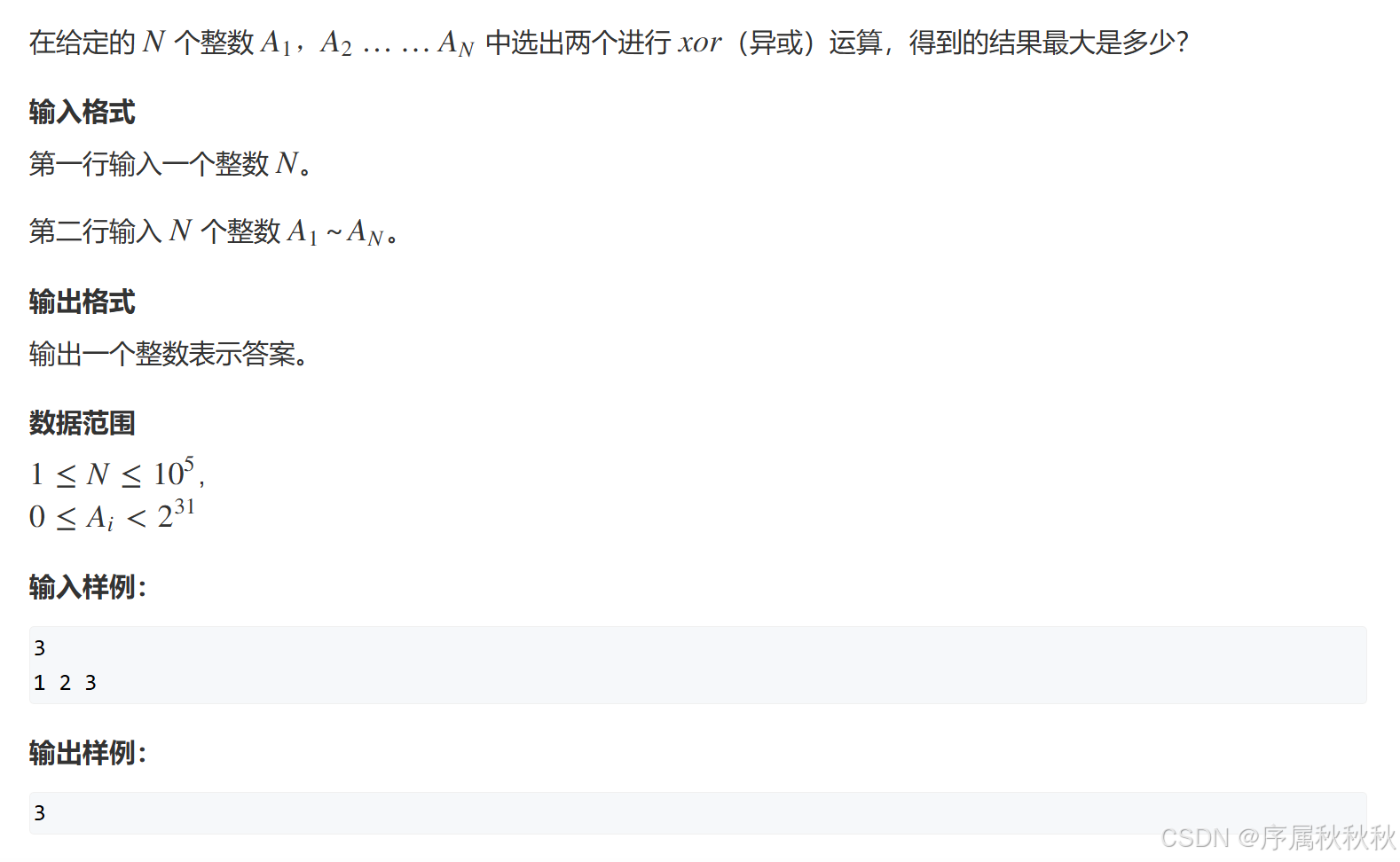
在这里插入图片描述
方法一:
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 100010; // 数组的最大长度
const int M = 3100010; // Trie 树的最大节点数
int n; // 数组的长度
int a[N]; // 存储输入的数组
int son[M][2]; // Trie 树的存储结构,son[p][0/1] 表示节点 p 的 0/1 子节点
int idx; // 当前 Trie 树中节点的编号,从 1 开始分配
// 插入操作:将整数 x 的二进制表示插入到 Trie 树中
void insert(int x)
{
int p = 0; // 从根节点开始
for (int i = 30; i >= 0; i--) // 从最高位到最低位遍历 x 的二进制位
{
int& s = son[p][x >> i & 1]; // 获取当前二进制位(0 或 1)对应的子节点
if (!s) s = ++idx; // 如果子节点不存在,则创建新节点
p = s; // 移动到子节点
}
}
// 查询操作:在 Trie 树中查找与 x 异或结果最大的值
int search(int x)
{
int p = 0, res = 0; // 从根节点开始,res 用于存储异或结果
for (int i = 30; i >= 0; i--) // 从最高位到最低位遍历 x 的二进制位
{
int s = x >> i & 1; // 获取当前二进制位(0 或 1)
if (son[p][!s]) // 如果存在与当前位相反的节点
{
res += 1 << i; // 将当前位的值加到结果中
p = son[p][!s]; // 移动到相反的节点
}
else p = son[p][s]; // 否则,移动到相同的节点
}
return res; // 返回最大异或结果
}
int main()
{
scanf("%d", &n); // 输入数组的长度
for (int i = 0; i < n; i++)
{
scanf("%d", &a[i]); // 输入数组的每个元素
insert(a[i]); // 将当前元素插入到 Trie 树中
}
int res = 0; // 用于存储最大异或结果
for (int i = 0; i < n; i++) res = max(res, search(a[i])); // 对每个元素查询最大异或结果
printf("%d\n", res); // 输出最大异或结果
return 0;
}代码片段解释
片段一:
const int N = 100010; // 数组的最大长度
const int M = 3100010; // Trie 树的最大节点数N = 100010:是为了确保数组能够容纳最多
个整数。
M = 3100010:是为了确保 Trie 树能够容纳最多
个节点。
1. N = 100010 的含义:N 表示数组的最大长度。
- 根据题目描述,
,即数组的长度最多为
2. M = 3100010 的含义:M 表示 Trie 树的最大节点数。
- Trie 树的节点数取决于插入的二进制数的位数和数量。
- 在本题中,每个整数是 32 位有符号整数(最高位是符号位,实际数值部分为 31 位)
- 每个整数的二进制表示最多需要 31 个节点(从第 0 位到第 30 位)
- 如果插入
个整数,每个整数最多需要 31 个节点,那么 Trie 树的总节点数最多为:
因此:M = 3100010 是一个比
稍大的值,确保 Trie 树的节点数不会超过限制。
片段二:
for (int i = 30; i >= 0; i--) // 从最高位到最低位遍历 x 的二进制位疑问:在代码中,为什么将 for (int i = 30; i >= 0; i--) 的 i 初始化为 30?
整数的二进制表示:
在 C++ 中,int 类型通常是 32 位有符号整数
- 最高位(第 31 位)是符号位,表示正负。
- 剩下的 31 位(第 0 位到第 30 位)表示数值部分。
i = 30表示处理最高位(第 30 位)i = 0表示处理最低位(第 0 位)
例如:整数 5 的二进制表示为:
00000000 00000000 00000000 00000101其中,第 0 位是 1,第 1 位是 0,第 2 位是 1,其余位都是 0
疑问:为什么从最高位开始处理?
- Trie 树的性质:Trie 树是一种前缀树,从最高位开始处理可以保证在查询时优先匹配高位,从而快速找到最大异或值。
- 异或运算的性质:异或运算的结果在高位为
1时,对最终结果的贡献更大。1000(二进制)的值为80111(二进制)的值为7
- 显然,
1000比0111大,因为高位1的贡献更大。
通过从最高位(第 30 位)开始处理,可以确保在 Trie 树中优先匹配高位的相反值,从而快速找到最大异或结果。
片段三:
res += 1 << i; // 将当前位的值加到结果中
res += 1 << i;这行代码的作用是 将当前二进制位的值加到结果中,具体来说,它是在计算最大异或结果时,逐位构建最终的结果。
1 << i 的含义:表示将数字 1 左移 i 位。
- 在二进制中,左移操作相当于乘以
res += 1 << i 的作用
res用于存储当前计算的最大异或结果。- 当发现当前二进制位可以取到相反的值时(即:
son[p][!s]存在),说明这一位的异或结果为1 - 为了将这一位的贡献加到结果中,使用
res += 1 << i
疑问:为什么需要
res += 1 << i?
- 异或运算的结果是一个整数,它的值由各个二进制位的贡献累加而成。
- 例如:二进制数
1010的值是:
- 在
search函数中,res是逐位构建的,每次找到一个可以取到相反值的二进制位时,就将这一位的贡献加到res中。
示例:假设 x = 5(二进制为 0101),Trie 树中已经插入了 2(二进制为 0010)
- 处理第 2 位(
i = 2):x >> 2 & 1得到1- 如果存在与
1相反的节点(即0),则将 (2^2 = 4) 加到res中。 res += 1 << 2,即res += 4
- 处理第 1 位(
i = 1):x >> 1 & 1得到0- 如果存在与
0相反的节点(即1),则将 (2^1 = 2) 加到res中。 res += 1 << 1,即res += 2
- 处理第 0 位(
i = 0):x >> 0 & 1得到1- 如果存在与
1相反的节点(即0),则将 (2^0 = 1) 加到res中。 res += 1 << 0,即res += 1
最终:res 的值为 4 + 2 + 1 = 7,即 5 ^ 2 = 7
疑问:是为什么只有在
if (son[p][!s])这种情况下才将当前位的值加到结果中加到res中? 或者疑问为什么只在if (son[p][!s])时更新res?
在 search 函数中,s 是当前数字 x 的第 i 位的值(0 或 1)
son[p][!s] 表示是否存在与当前位 相反 的节点
1. 如果 son[p][!s] 存在
- 说明 Trie 树中存在一个数字,其第
i位与x的第i位 相反 - 根据异或运算的性质,这一位的异或结果为
1 - 由于这一位的权重是
,因此我们需要将
加到 res 中
2. 如果 son[p][!s] 不存在
- 说明 Trie 树中不存在一个数字,其第
i位与x的第i位 相反 - 根据异或运算的性质,这一位的异或结果为
0 - 由于这一位的贡献是
0,因此不需要更新res
解题思路分析
第一部分:将整数 x 的二进制表示插入到 Trie 树中 第一步:定义根节点变量p=0 第二步:使用for循环让i=30从最高位到最低位遍历 x 的二进制位
- 第三步:获取当前二进制位(0 或 1)并存入变量u中
- 第四步:使用if语句判断节点 p 的 u 子节点是否为存在
- 第五步:如果不存在,则将当前位的值加到结果中 + 移动到子节点
- 第六步: 如果不存在,移动到子节点(即:更新p为其值)
第二部分:在 Trie 树中查找与 x 异或结果最大的值 第一步:定义根节点变量p=0 + 定义存储结果的变量res=0 第二步:使用for循环让i=30从最高位到最低位遍历 x 的二进制位
- 第三步:获取当前二进制位(0 或 1)并存入变量u中
- 第四步:使用if语句判断节点 p 的 !u 子节点是否为存在
- 第五步:如果不存在,则创建该节点(即:将其赋值为++idx)
- 第六步:移动到子节点(即:更新p为其值)
第七步:返回存储结果的变量res
Trie树的插入函数和查询函数有什么不同?
- 对于节点 p 的第 u 个子节点是否存在做出的操作不同
- 插入操作:不存在:
son[p][u] = ++idx;存在:无 - 查询操作:不存在:
p = son[p][u];存在:res += 1 << i; p = son[p][!u];
- 插入操作:不存在:
- 函数结束时所作的操作不同:
- 插入操作:
无 - 查询操作:
return res; // 返回最大异或结果(根据题目的具体要求返回需要的值)
- 插入操作:
---------------并查集---------------
836.合并集合
题目介绍
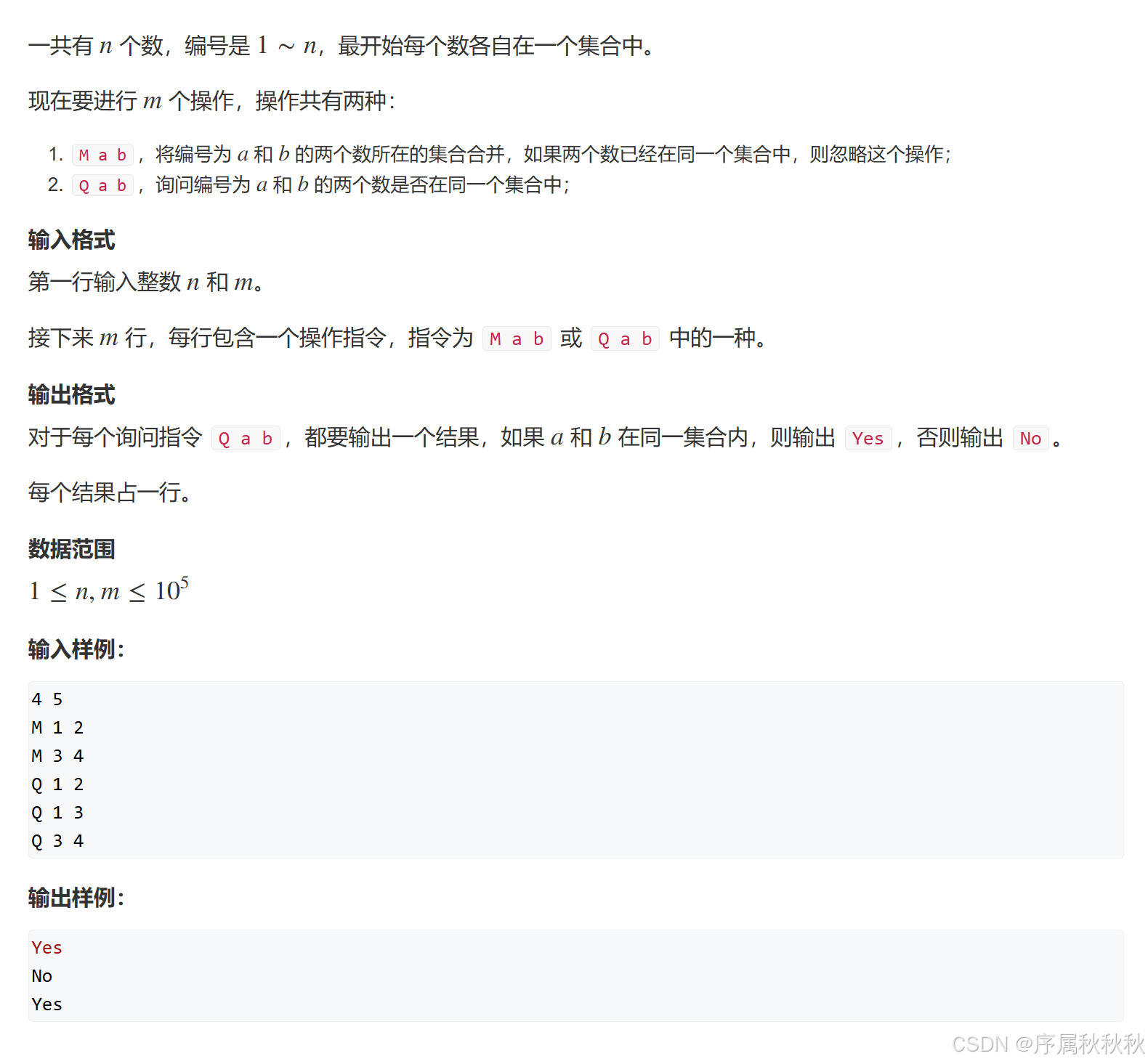
在这里插入图片描述
方法一:
#include <iostream>
using namespace std;
const int N = 100010; // 定义数组的最大长度
int p[N]; // 并查集的父节点数组,p[x] 表示 x 的父节点
int n, m; // n 表示元素的数量,m 表示操作的数量
// 查找操作:找到 x 的根节点,并进行路径压缩
int find(int x)
{
if (p[x] != x) p[x] = find(p[x]); // 如果 x 不是根节点,递归找到根节点,并进行路径压缩
return p[x]; // 返回 x 的根节点
}
int main()
{
scanf("%d%d", &n, &m);
// 初始化并查集,每个元素的父节点指向自己
for (int i = 1; i <= n; i++) p[i] = i;
while (m--)
{
char op[2]; // 用于存储操作类型
int a, b; // 操作涉及的两个元素
scanf("%s%d%d", op, &a, &b); // 输入操作类型和元素
if (*op == 'M') // 如果是合并操作
{
p[find(a)] = find(b); // 将 a 的根节点的父节点设置为 b 的根节点
}
else // 如果是查询操作
{
if (find(a) == find(b)) puts("Yes"); // 如果 a 和 b 的根节点相同,输出 "Yes"
else puts("No"); // 否则,输出 "No"
}
}
return 0;
}代码片段解释
片段一:
for (int i = 1; i <= n; i++) p[i] = i;这行代码的作用是 初始化并查集,具体来说,它为每个元素设置其父节点为自身。
并查集(Disjoint Set Union,DSU):用于管理元素的分组。
它支持两种操作:
- 查找:确定某个元素属于哪个集合。
- 合并:将两个集合合并为一个集合。
在并查集中,每个集合用一棵树表示,树的根节点代表集合的标识。
p[i] 的含义:是一个数组,表示元素 i 的父节点。
- 如果
p[i] == i,说明i是它所在集合的根节点。 - 如果
p[i] != i,说明i的父节点是p[i],需要继续向上查找根节点。
for (int i = 1; i <= n; i++) p[i] = i; 的作用:用于初始化并查集
- 对于每个元素
i(从1到n),将其父节点设置为自身,即:p[i] = i - 这意味着初始时,每个元素都是一个独立的集合,自己是自己的根节点
示例:假设 n = 5,初始化后:
p = [1, 2, 3, 4, 5]p[1] = 1:元素1的父节点是1,表示1是一个独立的集合p[2] = 2:元素2的父节点是2,表示2是一个独立的集合- 以此类推,直到
p[5] = 5
片段二:
// 查找操作:找到 x 的根节点,并进行路径压缩
int find(int x)
{
if (p[x] != x) p[x] = find(p[x]); // 如果 x 不是根节点,递归找到根节点,并进行路径压缩
return p[x]; // 返回 x 的根节点
}find 函数中的路径压缩是通过递归实现的,目的是在查找某个元素的根节点时,将路径上的所有节点直接连接到根节点,从而减少后续查找操作的时间复杂度。
路径压缩 :是一种优化技术,用于减少并查集中查找操作的时间复杂度。
- 在普通的查找操作中,每次查找都需要从当前节点一直向上遍历到根节点,时间复杂度为
,其中
是树的高度。
- 通过路径压缩,可以将路径上的所有节点直接连接到根节点,使得后续查找操作的时间复杂度接近
1. 递归过程
- 如果
p[x] != x,说明x不是根节点,需要继续向上查找根节点。 - 递归调用
find(p[x]),找到x的根节点。 - 在递归返回的过程中,将
x的父节点直接设置为根节点,即:p[x] = find(p[x])
2. 路径压缩
在递归过程中,路径上的所有节点都会被直接连接到根节点。
例如,假设有以下树结构:
p[1] = 1
p[2] = 1
p[3] = 2
p[4] = 3
调用 find(4) 时:
p[4] != 4,递归调用 find(3)
p[3] != 3,递归调用 find(2)
p[2] != 2,递归调用 find(1)
p[1] == 1,返回 1
在递归返回的过程中,将 p[2]、p[3] 和 p[4] 直接设置为 1,最终树结构变为:
p[1] = 1
p[2] = 1
p[3] = 1
p[4] = 13. 返回值
- 返回
x的根节点p[x]
解题思路分析
使用并查集解题思路步骤: 第一步:使用for循环初始化并查集,每个元素的父节点指向自己 第二步:实现并查集的核心find函数
- 1.使用if语句判断节点x的父节点是不是祖宗节点p[x]
- 2.如果不是则传递自己的父节点递归调用find函数 + 并用自己的父节点来接受祖宗节点find(p[x])
- 3.返回父节点(这是的父节点其实存的时祖宗节点)
837.连通块中点的数量
题目介绍

在这里插入图片描述
方法一:
#include <iostream>
using namespace std;
const int N = 100010; // 定义数组的最大长度
int n, m; // n 表示元素的数量,m 表示操作的数量
int p[N]; // 并查集的父节点数组,p[x] 表示 x 的父节点
int cnt[N]; // 记录每个集合的大小,cnt[x] 表示以 x 为根节点的集合的大小
// 查找操作:找到 x 的根节点,并进行路径压缩
int find(int x)
{
if (p[x] != x) p[x] = find(p[x]); // 如果 x 不是根节点,递归找到根节点,并进行路径压缩
return p[x]; // 返回 x 的根节点
}
int main()
{
cin >> n >> m; // 输入元素的数量和操作的数量
// 初始化并查集
for (int i = 1; i <= n; i++)
{
p[i] = i; // 每个元素的父节点指向自己
cnt[i] = 1; // 每个集合的大小初始化为 1
}
while (m--)
{
string op; // 用于存储操作类型
int a, b; // 操作涉及的元素
cin >> op; // 输入操作类型
if (op == "C") // 如果是合并操作
{
cin >> a >> b; // 输入要合并的两个元素
a = find(a), b = find(b); // 找到 a 和 b 的根节点
if (a != b) // 如果 a 和 b 不在同一个集合中
{
p[a] = b; // 将 a 的根节点的父节点设置为 b 的根节点
cnt[b] += cnt[a]; // 更新集合的大小
}
}
else if (op == "Q1") // 如果是查询是否在同一集合中的操作
{
cin >> a >> b;
if (find(a) == find(b)) puts("Yes");
else puts("No");
}
else // 如果是查询集合大小的操作
{
cin >> a;
cout << cnt[find(a)] << endl;
}
}
return 0;
}代码片段解释
片段一:
if (op == "C") // 如果是合并操作
{
cin >> a >> b; // 输入要合并的两个元素
a = find(a), b = find(b); // 找到 a 和 b 的根节点
if (a != b) // 如果 a 和 b 不在同一个集合中
{
p[a] = b; // 将 a 的根节点的父节点设置为 b 的根节点
cnt[b] += cnt[a]; // 更新集合的大小
}
}疑问:为什么不将其写成下面这样?
if (ch == "C")
{
cin >> a >> b;
if (find(a) != find(b))
{
p[find(a)] = find(b);
cnt[find(b)] += cnt[find(a)];
}
}这两段代码的核心逻辑是相同的,都是将两个集合合并,并更新集合的大小。
- 然而,第二段代码的问题在于
find函数的重复调用 - 而第一段代码通过提前存储
find(a)和find(b)的结果,避免了重复调用的问题
if (op == "C")
{
cin >> a >> b;
if (find(a) != find(b)) // 第一次调用 find(a) 和 find(b)
{
p[find(a)] = find(b); // 第二次调用 find(a) 和 find(b)
cnt[find(b)] += cnt[find(a)]; // 第三次调用 find(a) 和 find(b)
}
}问题分析:
- 重复调用
find函数:- 在
if (find(a) != find(b))中,find(a)和find(b)被调用了一次。 - 在
p[find(a)] = find(b)中,find(a)和find(b)又被调用了一次。 - 在
cnt[find(b)] += cnt[find(a)]中,find(a)和find(b)再次被调用。
每次调用
find函数都会进行递归查找和路径压缩,导致性能下降,并且在某些情况下可能导致逻辑错误。 - 在
- 路径压缩的影响:
find函数不仅返回根节点,还会进行路径压缩(将路径上的节点直接连接到根节点)- 如果在
p[find(a)] = find(b)中调用find(a),可能会导致find(a)的结果发生变化,从而影响后续的cnt[find(b)] += cnt[find(a)]逻辑
解题思路分析
使用并查集实现三大操作的思路步骤: 1. 查询两个元素是否在同一个集合中 只需要使用if语句判断
find(a)是否和find(b)相等即可 2. 将两个元素合并在同一个集合中 第一步:先判断两个元素是否在同一个集合中
- 第二步:如果不在同一个集合中,将元素a 的根节点的父节点设置为元素b 的根节点
- 第三步:如果不在同一个集合中,更新元素b 的祖宗节点集合的大小(为了第三步操作做铺垫)
3. 询问某个元素所在的集合中元素的数量
只需要输出cnt[find(某元素)]即可
240.食物链
题目介绍

在这里插入图片描述
方法一:
#include <iostream>
using namespace std;
const int N = 50010; // 定义数组的最大长度
int n, m; // n 表示动物的数量,m 表示操作的数量
int p[N]; // 并查集的父节点数组,p[x] 表示 x 的父节点
int d[N]; // 距离数组,d[x] 表示 x 到其父节点的距离
// 查找操作:找到 x 的根节点,并进行路径压缩和距离更新
int find(int x)
{
if (p[x] != x) // 如果 x 不是根节点
{
int t = find(p[x]); // 递归找到根节点
d[x] += d[p[x]]; // 更新 x 到根节点的距离
p[x] = t; // 路径压缩,将 x 直接连接到根节点
}
return p[x]; // 返回 x 的根节点
}
int main()
{
scanf("%d%d", &n, &m);
// 初始化并查集
for (int i = 1; i <= n; i++)
{
p[i] = i; // 每个动物的父节点指向自己
d[i] = 0; // 初始距离为 0
}
int res = 0; // 记录虚假陈述的数量
while (m--)
{
int t, x, y;
scanf("%d%d%d", &t, &x, &y); // 输入操作类型和两个动物编号
if (x > n || y > n) // 如果 x 或 y 超出范围,则是虚假陈述
{
res++;
}
else
{
int px = find(x), py = find(y); // 找到 x 和 y 的根节点
if (t == 1) // 操作类型 1:x 和 y 是同类
{
if (px == py && (d[x] - d[y]) % 3 != 0) // 如果 x 和 y 在同一集合中但距离差不为 0,则是虚假陈述
{
res++;
}
else if (px != py) // 如果 x 和 y 不在同一集合中,合并它们
{
p[px] = py; // 将 x 的根节点连接到 y 的根节点
d[px] = d[y] - d[x]; // 更新 x 的根节点到 y 的根节点的距离
}
}
else // 操作类型 2:x 吃 y
{
if (px == py && (d[x] - d[y] - 1) % 3 != 0) // 如果 x 和 y 在同一集合中但距离差不满足 x 吃 y 的条件,则是虚假陈述
{
res++;
}
else if (px != py) // 如果 x 和 y 不在同一集合中,合并它们
{
p[px] = py; // 将 x 的根节点连接到 y 的根节点
d[px] = d[y] + 1 - d[x]; // 更新 x 的根节点到 y 的根节点的距离
}
}
}
}
printf("%d\n", res); // 输出虚假陈述的数量
return 0;
}代码片解释
片段一:
d[px] = d[y] - d[x]; // 更新 x 的根节点到 y 的根节点的距离
d[px] = d[y] + 1 - d[x]; // 更新 x 的根节点到 y 的根节点的距离疑问:为什么在不同操作类型下要将
d[px]更新为d[y] - d[x]以及d[y] + 1 - d[x]? 在这个问题中,我们用并查集来维护动物之间的关系:
p[x]表示x的父节点。d[x]表示x到其根节点的距离。
通过 d[x] % 3 的值来表示 x 相对于根节点的关系:
d[x] % 3 == 0:表示x与根节点是同类。d[x] % 3 == 1:表示x吃根节点。d[x] % 3 == 2:表示x被根节点吃。
操作类型 1:x 和 y 是同类
- 当
t == 1时,表示x和y是同类 - 若
x和y不在同一集合中(即:px != py),需要将它们所在的集合合并
推导更新公式:假设 px 是 x 的根节点,py 是 y 的根节点,现在要将 px 连接到 py 上。
我们希望合并后 x 和 y 是同类,也就是 (d[x] + d[px]) % 3 == d[y] % 3
为了满足这个条件,我们可以对等式进行变形:
移项可得:
所以:在合并时将 d[px] 更新为 d[y] - d[x],这样就能保证合并后 x 和 y 是同类。
操作类型 2:x 吃 y
- 当
t == 2时,表示x吃y - 若
x和y不在同一集合中(即:px != py),同样需要将它们所在的集合合并
推导更新公式
我们希望合并后满足 (d[x] + d[px]) % 3 == (d[y] + 1) % 3
这是因为 x 吃 y,所以 x 相对于根节点的距离要比 y 相对于根节点的距离多 1
对等式进行变形:
移项可得:
所以:在合并时将 d[px] 更新为 d[y] + 1 - d[x],这样就能保证合并后 x 吃 y
解题思路分析
整体的思路流程: 第一部分:初始化并查集
- 每个元素的父节点指向自己:
p[i] = i; - 距离根节点的距离为0:
d[i] = 0;
第二部分:实现find函数 第一步:使用if语句判断节点x如果不是根节点
- 第二步:定义变量存储该节点的根节点
- 第三步:更新 x 到根节点的距离(即:累加其父节点到爷节点之间的距离)
- 第四步:进行路径压缩(即:将节点x的根节点赋给他的所有的父节点)
第五步:返回节点x的根节点
第三部分:根据题意解决本题
第一步:使用if语句 判断 x 或 y 是否超出范围
- 第二步:若超出范围则将虚假陈述的数量+1
- 第三步:若未超出范围
- 定义变量存储元素x,y的根节点
- 使用if条件语句
判断操作类型- 如果是操作类型1(x于y是同类):
- 使用if条件语句
判断如果元素 x 和 y 在同一集合中但距离差不为 0:则将虚假陈述的数量+1 - 使用if条件语句
判断如果元素 x 和 y 不在同一集合中:则将 x 的根节点连接到 y 的根节点 + 更新 x 的根节点到 y 的根节点的距离
- 使用if条件语句
- 如果是操作类型2(x吃y):
- 使用if条件语句
判断如果元素 x 和 y 在同一集合中但距离差不满足 x 吃 y 的条件:则将虚假陈述的数量+1 - 使用if条件语句
判断如果元素 x 和 y 不在同一集合中:则将 x 的根节点连接到 y 的根节点 + 更新 x 的根节点到 y 的根节点的距离
- 使用if条件语句
- 如果是操作类型1(x于y是同类):
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-04-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号