【深度学习】手把手教你玩转YOLOv8:训练自己的目标检测模型

【深度学习】手把手教你玩转YOLOv8:训练自己的目标检测模型

程序员三明治
发布于 2025-12-18 20:42:17
发布于 2025-12-18 20:42:17
🤞先做到 再看见!
第一步
安装环境
- 通用环境:PyTorch,CUDA、PyCharm
- 专用环境:ultralytics
第二步
下载yolov8项目,资源获取
第三步
下载数据集
我这里下载的是人脸识别数据集

可以看到就一种类别

如果说你下载的是VOC数据集,需要转换为YOLO,该如何转换?
执行以下脚本将VOC格式数据集转换为YOLO格式数据集。
但是需要注意的是:
- 转换之后的数据集只有Images和labels两个文件。还需要执行第二节中的脚本进行数据集划分,将总的数据集划分为训练、验证、测试数据集;
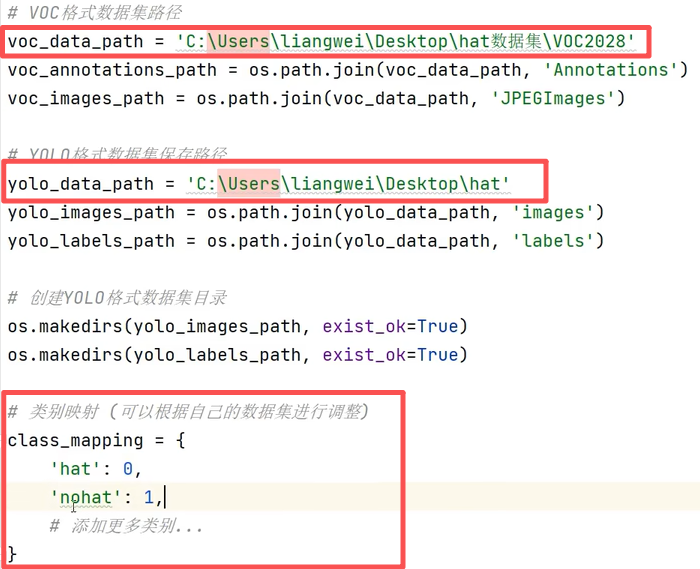
- 使用的话,需要修改 class_mapping 中类别名和对应标签,还有VOC数据集路径、YOLO数据集路径。
import os
import shutil
import xml.etree.ElementTree as ET
# VOC格式数据集路径
voc_data_path = 'E:\\DataSet\\helmet-VOC'
voc_annotations_path = os.path.join(voc_data_path, 'Annotations')
voc_images_path = os.path.join(voc_data_path, 'JPEGImages')
# YOLO格式数据集保存路径
yolo_data_path = 'E:\\DataSet\\helmet-YOLO'
yolo_images_path = os.path.join(yolo_data_path, 'images')
yolo_labels_path = os.path.join(yolo_data_path, 'labels')
# 创建YOLO格式数据集目录
os.makedirs(yolo_images_path, exist_ok=True)
os.makedirs(yolo_labels_path, exist_ok=True)
# 类别映射 (可以根据自己的数据集进行调整)
class_mapping = {
'head': 0,
'helmet': 1,
'person': 2,
# 添加更多类别...
}
def convert_voc_to_yolo(voc_annotation_file, yolo_label_file):
tree = ET.parse(voc_annotation_file)
root = tree.getroot()
size = root.find('size')
width = float(size.find('width').text)
height = float(size.find('height').text)
with open(yolo_label_file, 'w') as f:
for obj in root.findall('object'):
cls = obj.find('name').text
if cls not in class_mapping:
continue
cls_id = class_mapping[cls]
xmlbox = obj.find('bndbox')
xmin = float(xmlbox.find('xmin').text)
ymin = float(xmlbox.find('ymin').text)
xmax = float(xmlbox.find('xmax').text)
ymax = float(xmlbox.find('ymax').text)
x_center = (xmin + xmax) / 2.0 / width
y_center = (ymin + ymax) / 2.0 / height
w = (xmax - xmin) / width
h = (ymax - ymin) / height
f.write(f"{cls_id} {x_center} {y_center} {w} {h}\n")
# 遍历VOC数据集的Annotations目录,进行转换
for voc_annotation in os.listdir(voc_annotations_path):
if voc_annotation.endswith('.xml'):
voc_annotation_file = os.path.join(voc_annotations_path, voc_annotation)
image_id = os.path.splitext(voc_annotation)[0]
voc_image_file = os.path.join(voc_images_path, f"{image_id}.jpg")
yolo_label_file = os.path.join(yolo_labels_path, f"{image_id}.txt")
yolo_image_file = os.path.join(yolo_images_path, f"{image_id}.jpg")
convert_voc_to_yolo(voc_annotation_file, yolo_label_file)
if os.path.exists(voc_image_file):
shutil.copy(voc_image_file, yolo_image_file)
print("转换完成!")然后把yolov8压缩包解压,得到一个yolov8的项目,用PyCharm打开

打开后是这样
把上面代码粘贴在此py中,进行路径的相应修改
跑一下看看是否运行成功!
如果已经是yolov8格式的话,直接进行下面
YOLO格式数据集划分(训练、验证、测试)
训练自己的yolov8检测模型,数据集需要划分为训练集、验证集和测试集,这里提供一个参考代码,划分比例为8:1:1,也可以按照自己的比例划分
划分代码:
import os
import shutil
import random
# random.seed(0) #随机种子,可自选开启
def split_data(file_path, label_path, new_file_path, train_rate, val_rate, test_rate):
images = os.listdir(file_path)
labels = os.listdir(label_path)
images_no_ext = {os.path.splitext(image)[0]: image for image in images}
labels_no_ext = {os.path.splitext(label)[0]: label for label in labels}
matched_data = [(img, images_no_ext[img], labels_no_ext[img]) for img in images_no_ext if img in labels_no_ext]
unmatched_images = [img for img in images_no_ext if img not in labels_no_ext]
unmatched_labels = [label for label in labels_no_ext if label not in images_no_ext]
if unmatched_images:
print("未匹配的图片文件:")
for img in unmatched_images:
print(images_no_ext[img])
if unmatched_labels:
print("未匹配的标签文件:")
for label in unmatched_labels:
print(labels_no_ext[label])
random.shuffle(matched_data)
total = len(matched_data)
train_data = matched_data[:int(train_rate * total)]
val_data = matched_data[int(train_rate * total):int((train_rate + val_rate) * total)]
test_data = matched_data[int((train_rate + val_rate) * total):]
# 处理训练集
for img_name, img_file, label_file in train_data:
old_img_path = os.path.join(file_path, img_file)
old_label_path = os.path.join(label_path, label_file)
new_img_dir = os.path.join(new_file_path, 'train', 'images')
new_label_dir = os.path.join(new_file_path, 'train', 'labels')
os.makedirs(new_img_dir, exist_ok=True)
os.makedirs(new_label_dir, exist_ok=True)
shutil.copy(old_img_path, os.path.join(new_img_dir, img_file))
shutil.copy(old_label_path, os.path.join(new_label_dir, label_file))
# 处理验证集
for img_name, img_file, label_file in val_data:
old_img_path = os.path.join(file_path, img_file)
old_label_path = os.path.join(label_path, label_file)
new_img_dir = os.path.join(new_file_path, 'val', 'images')
new_label_dir = os.path.join(new_file_path, 'val', 'labels')
os.makedirs(new_img_dir, exist_ok=True)
os.makedirs(new_label_dir, exist_ok=True)
shutil.copy(old_img_path, os.path.join(new_img_dir, img_file))
shutil.copy(old_label_path, os.path.join(new_label_dir, label_file))
# 处理测试集
for img_name, img_file, label_file in test_data:
old_img_path = os.path.join(file_path, img_file)
old_label_path = os.path.join(label_path, label_file)
new_img_dir = os.path.join(new_file_path, 'test', 'images')
new_label_dir = os.path.join(new_file_path, 'test', 'labels')
os.makedirs(new_img_dir, exist_ok=True)
os.makedirs(new_label_dir, exist_ok=True)
shutil.copy(old_img_path, os.path.join(new_img_dir, img_file))
shutil.copy(old_label_path, os.path.join(new_label_dir, label_file))
print("数据集已划分完成")
if __name__ == '__main__':
file_path = r"f:\data\JPEGImages" # 图片文件夹
label_path = r'f:\data\labels' # 标签文件夹
new_file_path = r"f:\VOCdevkit" # 新数据存放位置
split_data(file_path, label_path, new_file_path, train_rate=0.8, val_rate=0.1, test_rate=0.1)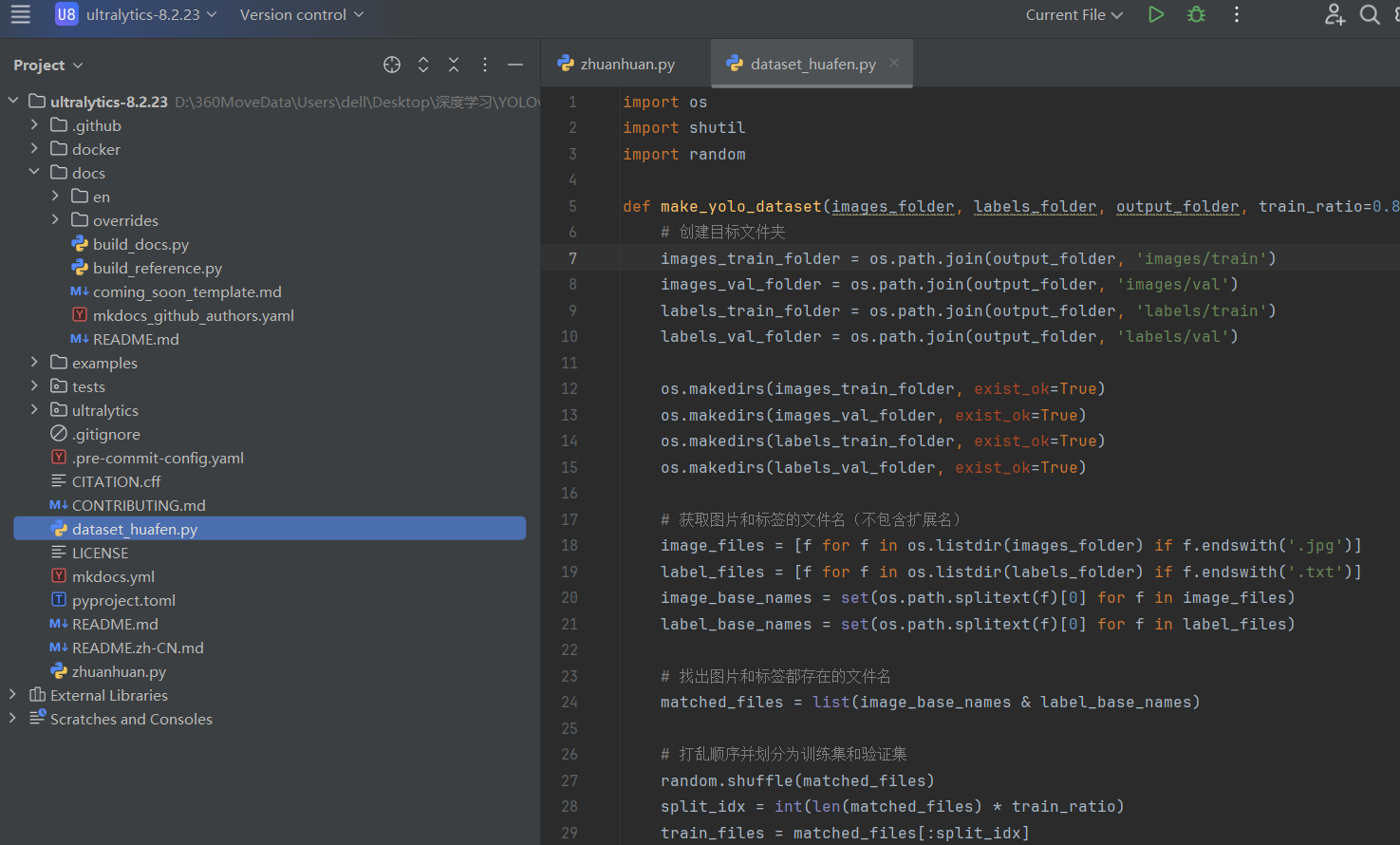
粘贴上去要注意修改图片文件夹和标签文件夹的路径

运行代码可以看到划分完成
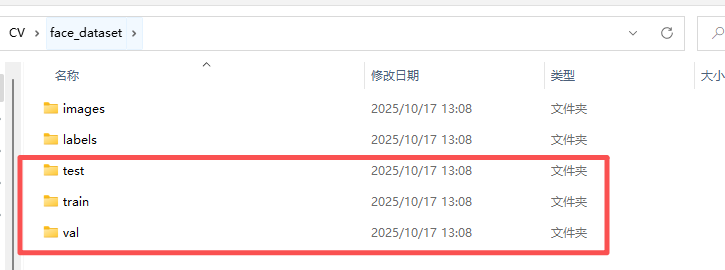
把划分好的数据集丢到项目中
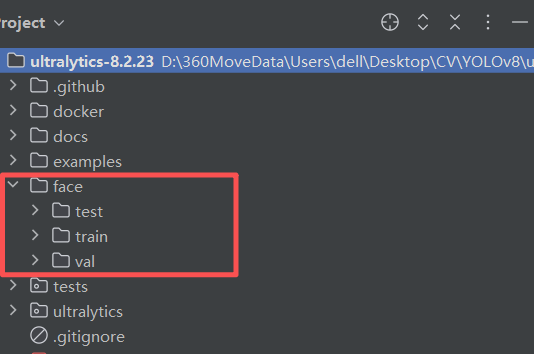
先检查虚拟环境中是否有ultralytics包,没有的话需要安装
在项目根目录创建一个 setup.py 文件:
from setuptools import setup, find_packages
setup(
name="ultralytics",
version="8.2.23",
packages=find_packages(),
install_requires=[
"torch>=1.7.0",
"opencv-python",
"numpy",
"matplotlib",
"pillow",
"pyyaml",
"requests",
"scipy",
"tqdm",
],
python_requires=">=3.7",
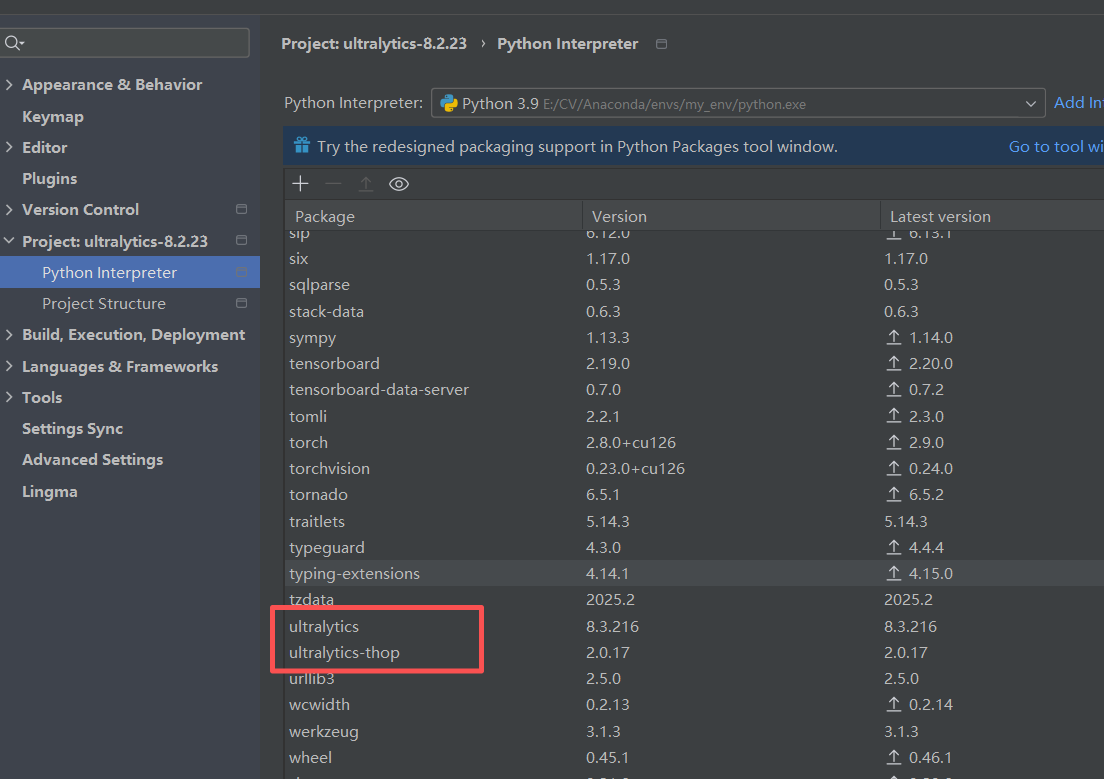
)然后就可以使用可编辑安装:
pip install -e .安装成功可以看到
第四步
训练模型
创建data.yaml
在yolov8根目录下(也就是本文所用的ultralytics-8.2.0目录下)创建一个新的data.yaml文件,也可以是其他名字的例如hat.yaml文件,文件名可以变但是后缀需要为.yaml,内容如下,test可有可无
训练模型
这是使用官方提供的预训练权重进行训练,使用yolov8n.pt,也可以使用yolov8s.pt,模型大小n<s<m<l<x,训练时长成倍增加。

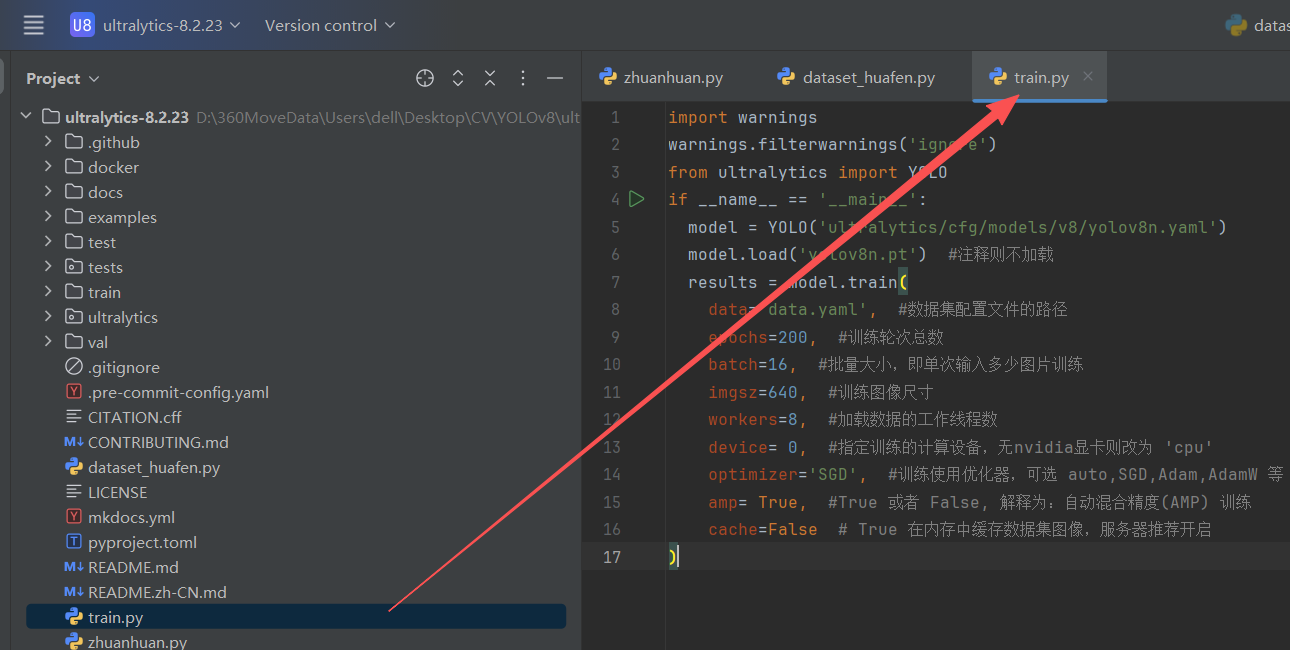
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('ultralytics/cfg/models/v8/yolov8n.yaml')
model.load('yolov8n.pt') #注释则不加载
results = model.train(
data='data.yaml', #数据集配置文件的路径
epochs=200, #训练轮次总数
batch=16, #批量大小,即单次输入多少图片训练
imgsz=640, #训练图像尺寸
workers=8, #加载数据的工作线程数
device= 0, #指定训练的计算设备,无nvidia显卡则改为 'cpu'
optimizer='SGD', #训练使用优化器,可选 auto,SGD,Adam,AdamW 等
amp= True, #True 或者 False, 解释为:自动混合精度(AMP) 训练
cache=False # True 在内存中缓存数据集图像,服务器推荐开启
)
将数据集中的yaml文件放在项目中

数据集路径
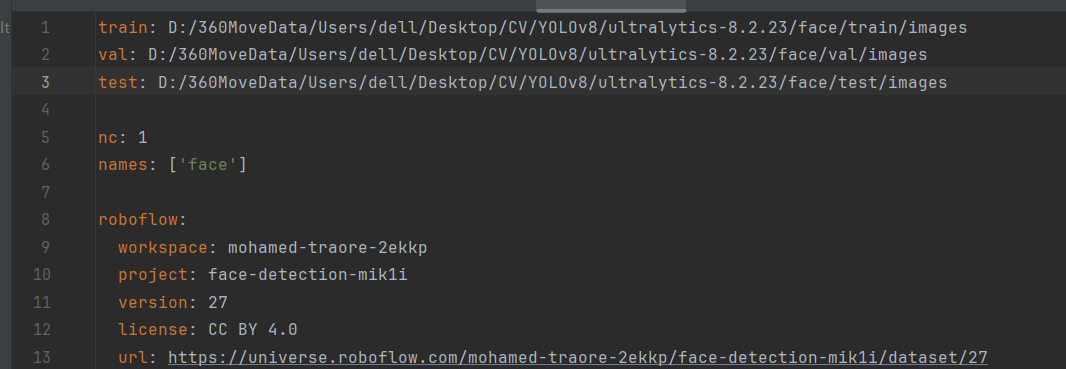
执行train.py文件
报错一:页面文件太小,无法完成

那我们就把workers改为0
报错二
Traceback (most recent call last): File “D:\Anaconda3\yolo8\ultralytics-8.1.35\yolov8_train.py”, line 6, in model.load(‘yolov8n.pt’) #注释则不加载 ^^^^^^^^^^^^^^^^^^^^^^^^ File “D:\Anaconda3\yolo8\ultralytics-8.1.35\ultralytics\engine\model.py”, line 296, in load weights, self.ckpt = attempt_load_one_weight(weights) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File “D:\Anaconda3\yolo8\ultralytics-8.1.35\ultralytics\nn\tasks.py”, line 790, in attempt_load_one_weight ckpt, weight = torch_safe_load(weight) # load ckpt ^^^^^^^^^^^^^^^^^^^^^^^ File “D:\Anaconda3\yolo8\ultralytics-8.1.35\ultralytics\nn\tasks.py”, line 716, in torch_safe_load ckpt = torch.load(file, map_location=“cpu”) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File “D:\Anaconda3\Lib\site-packages\torch\serialization.py”, line 1524, in load raise pickle.UnpicklingError(_get_wo_message(str(e))) from None _pickle.UnpicklingError: Weights only load faile
解决方案:
找到 <font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">D:\Anaconda3\yolo8\ultralytics-8.1.35\ultralytics\nn\tasks.py</font> 文件,在第716行左右:
# 找到这行代码:
ckpt = torch.load(file, map_location="cpu")
# 修改为:
ckpt = torch.load(file, map_location="cpu", weights_only=False)把原来的代码加上允许不安全加载
import warnings
import torch
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 使用上下文管理器允许不安全加载
with torch.serialization.safe_globals([torch.nn.modules.container.Sequential]):
model = YOLO('ultralytics/cfg/models/v8/yolov8n.yaml')
model.load('yolov8n.pt') #注释则不加载
results = model.train(
data='data.yaml', #数据集配置文件的路径
epochs=200, #训练轮次总数
batch=16, #批量大小,即单次输入多少图片训练
imgsz=640, #训练图像尺寸
workers=0, #加载数据的工作线程数
device= 0, #指定训练的计算设备,无nvidia显卡则改为 'cpu'
optimizer='SGD', #训练使用优化器,可选 auto,SGD,Adam,AdamW 等
amp= True, #True 或者 False, 解释为:自动混合精度(AMP) 训练
cache=False # True 在内存中缓存数据集图像,服务器推荐开启
)跑成功了!虽然没内存了

第五步
跑几轮就有几轮的权重

那权重好了我们下面就要进行验证
测试集上推理模型精度代码如下,可新增v8_val.py,输入下方代码,更改模型路径及数据集路径即可。
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('runs/detect/train/weights/best.pt') #修改为自己训练的模型路径
model.val(data='hat.yaml', #修改为自己的数据集yaml文件
split='test',
imgsz=640,
batch=16,
iou=0.6, #阈值可以改,mAP50为0.5的情况下
conf=0.001,
workers=8,
)因为第4轮才跑出来best和last,所以路径上要做相应的修改,还有yaml改为自己的

运行一下

第六步
进行预测
找到之前训练的结果保存路径,创建一个yolov8_predict.py文件,内容如下
from ultralytics import YOLO
# 加载训练好的模型,改为自己的路径
model = YOLO('runs/detect/train/weights/best.pt')
# 修改为自己的图像或者文件夹的路径
source = 'test1.jpg' #修改为自己的图片路径及文件名
# 运行推理,并附加参数
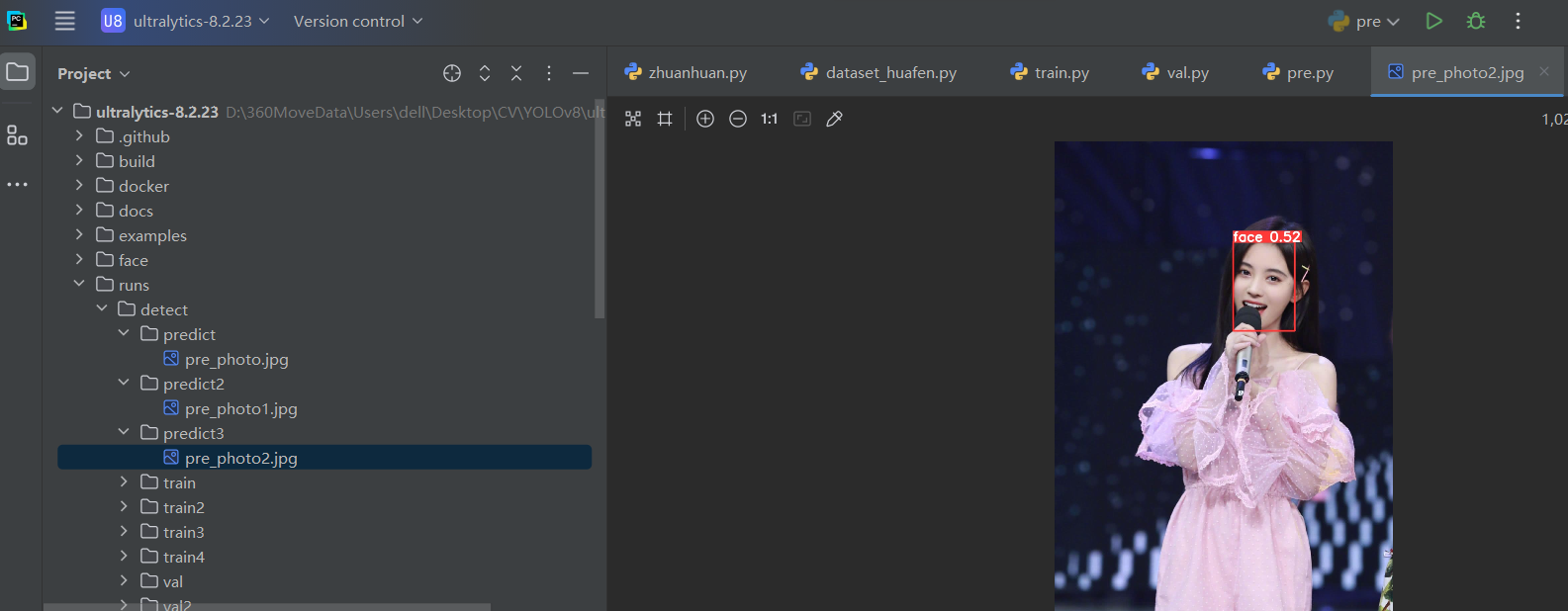
model.predict(source, save=True)新增一个预测的图片,我的是pre_photo1.jpg
可以看到效果
假设我们要换个数据集怎么搞呢?
以lizi数据集为例
拷贝到我们项目下
修改data.yaml
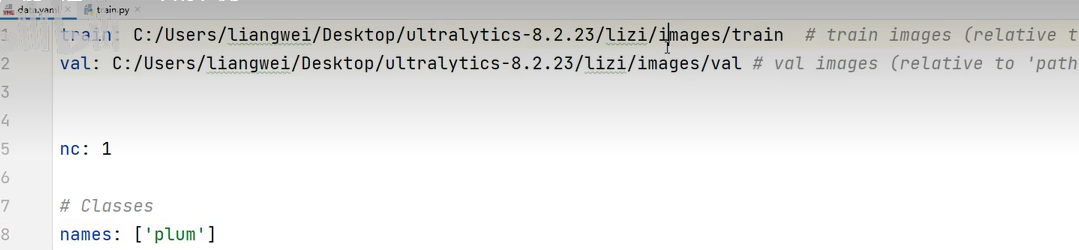
然后训练模型,跑完之后去predict看看效果
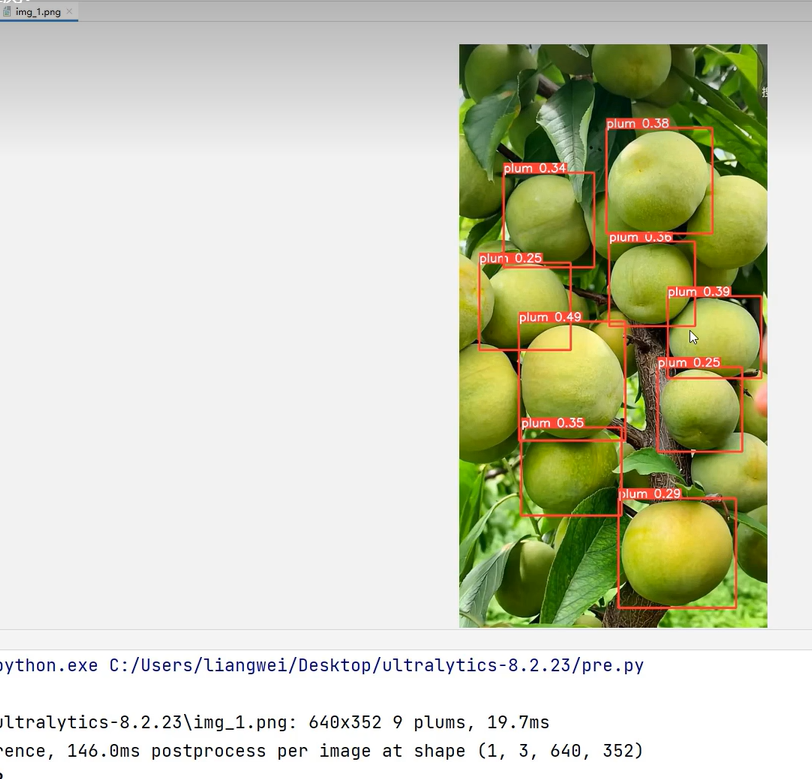
在这里插入图片描述
大功告成!以上就是yolov8目标检测的全部流程!
如果我的内容对你有帮助,请辛苦动动您的手指为我点赞,评论,收藏。感谢大家!!
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-12-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号