分库分表之实战-sharding-JDBC广播表

分库分表之实战-sharding-JDBC广播表

工藤学编程
发布于 2025-12-22 09:04:23
发布于 2025-12-22 09:04:23
大家好,我是工藤学编程 🦉 | 一个正在努力学习的小博主,期待你的关注 |
|---|---|
实战代码系列最新文章😉 | C++实现图书管理系统(Qt C++ GUI界面版) |
SpringBoot实战系列🐷 | 【SpringBoot实战系列】Sharding-Jdbc实现分库分表到分布式ID生成器Snowflake自定义wrokId实战 |
环境搭建大集合 | 环境搭建大集合(持续更新) |
分库分表 | 分库分表之实战-sharding-JDBC |
前情摘要:
1、数据库性能优化 2、分库分表之优缺点分析 3、分库分表之数据库分片分类 4、分库分表之策略 5、分库分表技术栈讲解-Sharding-JDBC 6、分库分表下的 ID 冲突问题与雪花算法讲解 7、分库分表之实战-sharding-JDBC
【亲测宝藏推荐】发现一个让 AI 学习秒变轻松的神站!不用啃高数、不用怕编程,高中生都能看懂的人工智能教程来啦!
👉点击跳转,和 thousands of 小伙伴一起用快乐学习法征服 AI,说不定下一个开发出爆款 AI 程序的就是你!
Sharding-JDBC广播表深度解析与实战配置指南
一、广播表核心概念与设计思想
在分布式分库分表场景中,当我们需要处理海量数据时,通常会将大表按规则拆分到多个数据库/表中。但对于一类特殊的表——广播表(Broadcast Table),它有着完全不同的设计逻辑: 定义: 所有分片数据源中都存在的表,其表结构和数据在每个数据库实例中完全一致。就像“广播”一样,数据会同步到所有分片节点,确保任何数据源访问时都能获取到相同的表结构和数据。
核心特性:
- 数据一致性:所有分片库的表结构、数据完全相同
- 无分片逻辑:不参与分库分表规则,直接全库复制
- 关联查询优化:避免跨库关联,提升多表join性能
二、适用场景与典型案例
为什么需要广播表?当我们遇到以下场景时,广播表能发挥关键作用: 典型场景:
- 字典表/配置表:如性别字典、状态码表、系统参数表等(数据量小但高频访问)
- 基础信息表:如行政区划表、部门表(数据稳定且需要与业务表频繁关联)
- 维度表:在数据仓库场景中作为维度表存在
优势对比: 假设订单表按用户分库,若商品表作为普通分片表,订单与商品的关联查询需要跨库路由;而商品表作为广播表时,每个分片库都有完整商品数据,可直接在本地库完成join,省去复杂的跨库关联逻辑。
注意!这些场景不适用:
- 数据量大且频繁更新的表(全库同步成本高)
- 业务上需要独立分片的表(如用户表、订单表)
三、Sharding-JDBC配置实战(以Spring Boot为例)
我们需要在数据库ccc_shop_order_0、ccc_shop_order_1中分表新建下表:
CREATE TABLE `ad_config` (
`id` bigint unsigned NOT NULL COMMENT '主键id',
`config_key` varchar(1024) COLLATE utf8mb4_bin
DEFAULT NULL COMMENT '配置key',
`config_value` varchar(1024) COLLATE utf8mb4_bin
DEFAULT NULL COMMENT '配置value',
`type` varchar(128) COLLATE utf8mb4_bin DEFAULT
NULL COMMENT '类型',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
COLLATE=utf8mb4_bin;然后新建pojo类:
@Data
@EqualsAndHashCode(callSuper = false)
@TableName("ad_config")
public class AdConfigDO {
private Long id;
private String configKey;
private String configValue;
private String type;
}然后在application.properties中添加广播包配置:
spring.shardingsphere.sharding.broadcast-tables=ad_config
spring.shardingsphere.sharding.tables.ad_config.key-generator.column=id
spring.shardingsphere.sharding.tables.ad_config.key-generator.type=SNOWFLAKE然后再新建对应的Mapper
public interface AdConfigMapper extends
BaseMapper<AdConfigDO> {
}最后在单元测试类,DbTest中新增单元测试函数
@Test
public void testSaveAdConfig(){
AdConfigDO adConfigDO = new AdConfigDO();
adConfigDO.setConfigKey("ad_config_key");
adConfigDO.setConfigValue("编程接单找CCC");
adConfigDO.setType("ad");
adConfigMapper.insert(adConfigDO);
}当前项目目录如下,大家可以对比:

在这里插入图片描述
然后运行该单元函数,查看结果
2025-07-01 15:53:52.221 INFO 5636 --- [ main] ShardingSphere-SQL : Actual SQL: ds0 ::: INSERT INTO ad_config ( id,
config_key,
config_value,
type ) VALUES (?, ?, ?, ?) ::: [1939955597112029186, ad_config_key, 编程接单找CCC, ad]
2025-07-01 15:53:52.221 INFO 5636 --- [ main] ShardingSphere-SQL : Actual SQL: ds1 ::: INSERT INTO ad_config ( id,
config_key,
config_value,
type ) VALUES (?, ?, ?, ?) ::: [1939955597112029186, ad_config_key, 编程接单找CCC, ad]可以看到我们的两个库中的两个表数据都被插入的是相同的数据
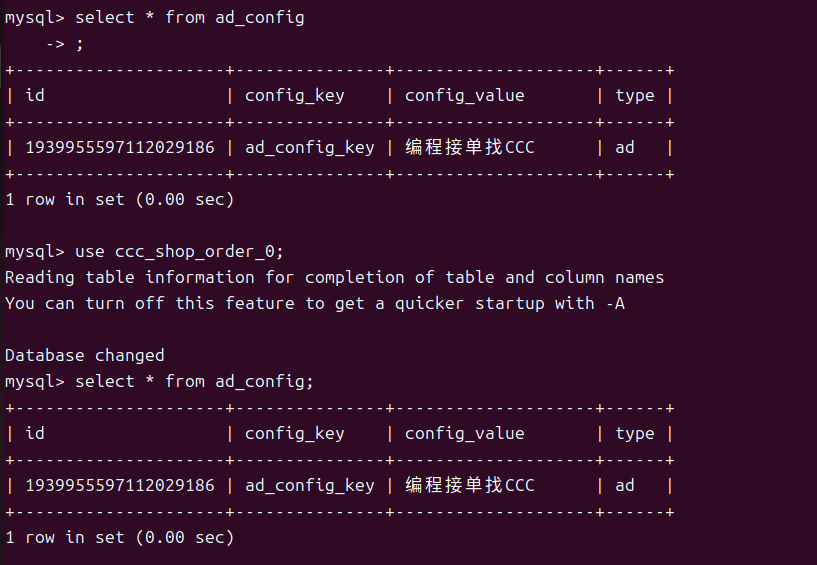
在这里插入图片描述
四、避坑指南与最佳实践
- 字段命名规范
- 严格避免使用SQL关键字(如
desc、order、limit),Sharding-JDBC对关键字的兼容性较弱,报错信息可能不明确 - 示例:字段名
desc会导致SQL解析错误,应改为description
- 严格避免使用SQL关键字(如
- 表结构变更注意事项
- 任何表结构变更(如新增字段)必须同步执行到所有分片库
- 推荐使用版本控制工具(如Liquibase)管理多库DDL变更
- 性能优化技巧
- 广播表本身无需分片键,建表时可移除分片键相关索引
- 对于极小表(如100条以内),可关闭Sharding-JDBC的优化器逻辑(通过
props.sql.optimizer.enable配置)
- 监控与治理
- 通过ShardingSphere的治理中心(如ZooKeeper)监控广播表同步状态
- 结合APM工具(如SkyWalking)追踪跨库关联性能变化
五、总结与适用建议
广播表的核心价值在于消除跨库关联复杂性,提升高频小表的查询效率。但使用时需权衡:
- 优势:简化关联逻辑、避免跨库join性能损耗、数据强一致性
- 代价:存储成本增加(N个分片库存储N份数据)、DDL/DML操作需要多库同步
适用决策参考: 当表满足以下条件时,优先考虑作为广播表: ✅ 数据量小(建议单表数据量<10万) ✅ 更新频率低(日均更新量<1000次) ✅ 跨分片关联频繁 ✅ 数据一致性要求高(如基础字典信息)
通过合理使用广播表,我们能在分布式数据库设计中找到性能与复杂度的平衡点,让核心业务逻辑更简洁高效。
觉得有用请点赞收藏! 如果有相关问题,欢迎评论区留言讨论~
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-07-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号