零基础学AI大模型之Milvus部署架构选型+Linux实战:Docker一键部署+WebUI使用

零基础学AI大模型之Milvus部署架构选型+Linux实战:Docker一键部署+WebUI使用

工藤学编程
发布于 2025-12-22 10:03:52
发布于 2025-12-22 10:03:52
大家好,我是工藤学编程 🦉 | 一个正在努力学习的小博主,期待你的关注 |
|---|---|
实战代码系列最新文章😉 | C++实现图书管理系统(Qt C++ GUI界面版) |
SpringBoot实战系列🐷 | 【SpringBoot实战系列】SpringBoot3.X 整合 MinIO 存储原生方案 |
分库分表 | 分库分表之实战-sharding-JDBC分库分表执行流程原理剖析 |
消息队列 | 深入浅出 RabbitMQ-RabbitMQ消息确认机制(ACK) |
AI大模型 | 零基础学AI大模型之Milvus核心:分区-分片-段结构全解+最佳实践 |
前情摘要
前情摘要 1、零基础学AI大模型之读懂AI大模型 2、零基础学AI大模型之从0到1调用大模型API 3、零基础学AI大模型之SpringAI 4、零基础学AI大模型之AI大模型常见概念 5、零基础学AI大模型之大模型私有化部署全指南 6、零基础学AI大模型之AI大模型可视化界面 7、零基础学AI大模型之LangChain 8、零基础学AI大模型之LangChain六大核心模块与大模型IO交互链路 9、零基础学AI大模型之Prompt提示词工程 10、零基础学AI大模型之LangChain-PromptTemplate 11、零基础学AI大模型之ChatModel聊天模型与ChatPromptTemplate实战 12、零基础学AI大模型之LangChain链 13、零基础学AI大模型之Stream流式输出实战 14、零基础学AI大模型之LangChain Output Parser 15、零基础学AI大模型之解析器PydanticOutputParser 16、零基础学AI大模型之大模型的“幻觉” 17、零基础学AI大模型之RAG技术 18、零基础学AI大模型之RAG系统链路解析与Document Loaders多案例实战 19、零基础学AI大模型之LangChain PyPDFLoader实战与PDF图片提取全解析 20、零基础学AI大模型之LangChain WebBaseLoader与Docx2txtLoader实战 21、零基础学AI大模型之RAG系统链路构建:文档切割转换全解析 22、零基础学AI大模型之LangChain 文本分割器实战:CharacterTextSplitter 与 RecursiveCharacterTextSplitter 全解析 23、零基础学AI大模型之Embedding与LLM大模型对比全解析 24、零基础学AI大模型之LangChain Embedding框架全解析 25、零基础学AI大模型之嵌入模型性能优化 26、零基础学AI大模型之向量数据库介绍与技术选型思考 27、零基础学AI大模型之Milvus向量数据库全解析 28、零基础学AI大模型之Milvus核心:分区-分片-段结构全解+最佳实践
零基础学AI大模型之Milvus部署架构选型+Linux实战:Docker一键部署+WebUI使用
上一篇我们吃透了Milvus的“分区-分⽚-段”核心结构,知道了它如何高效组织海量数据。但理论再好,落地才是关键——到底该选哪种部署方式?Linux服务器上怎么快速部署?部署后怎么验证是否成功?今天就来解决这些“落地问题”,从部署架构选型到Linux Docker实战,再到WebUI使用,一步步带你搞定Milvus部署,新手也能跟着做!

请添加图片描述
一、部署架构选型:按项目阶段选对方案
Milvus提供多种部署选项,核心是“按需选择”——不同项目规模、不同阶段,对应不同部署方式,不用盲目追求复杂架构。
1. 三大核心部署方案对比
部署方案 | 适用场景 | 支持数据量 | 核心优势 | 限制 |
|---|---|---|---|---|
Milvus Lite | 快速原型开发、Jupyter Notebook测试、边缘设备 | 最多几百万向量 | 轻量(Python库)、无需复杂部署、一键启动 | 不支持Windows系统、无高可用 |
Milvus Standalone(单机版) | 个人学习、小团队测试、中型项目(非核心业务) | 最高1亿向量 | Docker一键部署、组件集成、支持主从复制高可用 | 横向扩展能力有限 |
Milvus Distributed(分布式版) | 企业级生产、核心业务、大规模数据 | 1亿-千亿向量 | 云原生架构、水平扩展、冗余备份、高性能 | 部署复杂、需K8S集群、运维成本高 |
2. 额外选择:云服务版(懒人首选)
如果不想自己搭建和运维,直接选择云厂商提供的Milvus服务(如阿里云Milvus),开箱即用,支持弹性扩容,适合企业快速落地。 官方链接:阿里云Milvus文档
3. 选型建议
- 新手/学习者:优先选Milvus Standalone,部署简单,能覆盖大部分学习和测试场景;
- 原型开发:用Milvus Lite,直接集成到Python代码,快速验证想法;
- 生产环境:数据量1亿以下且预算有限,用Standalone+主从复制;数据量超1亿或核心业务,用Distributed(K8S部署)或云服务。
二、Milvus分层架构:看懂部署的核心组件
不管哪种部署方案(Docker版),核心分层架构都一致,只是分布式版会将组件拆分到不同节点,单机版打包在一个容器中。
1. 分层架构图解(简化版)
┌───────────────────────────────┐
│ Coordinator(协调层) │ → 管理元数据、调度任务、负载均衡
├───────────────┬───────────────┤
│ Query Node │ Data Node │ → 业务层:Query Node处理查询,Data Node处理数据存储
├───────────────┴───────────────┤
│ Object Storage(存储层) │ → 持久化存储:支持MinIO、AWS S3等
└───────────────────────────────┘ 2. 核心组件作用(新手无需深入,了解即可)
- Coordinator:整个系统的“大脑”,管理集群元数据(如Collection、分区信息),分配任务给其他节点;
- Query Node:“查询执行者”,处理向量搜索、标量过滤,支持内存索引和GPU加速;
- Data Node:“数据管理者”,处理数据插入、日志持久化,保障数据一致性;
- Object Storage:“数据仓库”,存储持久化数据,避免容器重启后数据丢失。
三、Linux实战:Docker一键部署Milvus Standalone
这是最适合新手的部署方式,全程用脚本操作,无需手动配置组件,以阿里云Linux服务器为例(其他Linux发行版通用)。
1. 部署前准备
- 服务器要求:Linux系统(CentOS、Ubuntu均可),建议2核4G以上配置(学习测试足够);
- 开放端口:云服务器(如阿里云)需在安全组开放3个端口——2379(etcd端口)、9091(WebUI端口)、19530(Milvus服务端口);
- 依赖检查:服务器已安装Docker(若未安装,脚本会自动处理,无需手动操作);
- 版本注意:必须和课程保持一致,避免兼容性问题,下文脚本已适配稳定版本。
2. 部署步骤(全程命令行操作)
步骤1:下载部署脚本
下载官方整合脚本
curl -sfL https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh -o standalone_embed.sh步骤2:执行脚本启动Milvus
下载完成后,执行以下命令启动服务(无需修改,直接复制):
# 给脚本执行权限(若提示权限不足时执行)
chmod +x standalone_embed.sh
# 启动Milvus服务
bash standalone_embed.sh start- 执行过程:脚本会自动拉取镜像、创建容器,耐心等待3-5分钟(取决于服务器带宽);
- 成功标识:命令行输出“Milvus standalone started successfully”,表示启动成功。
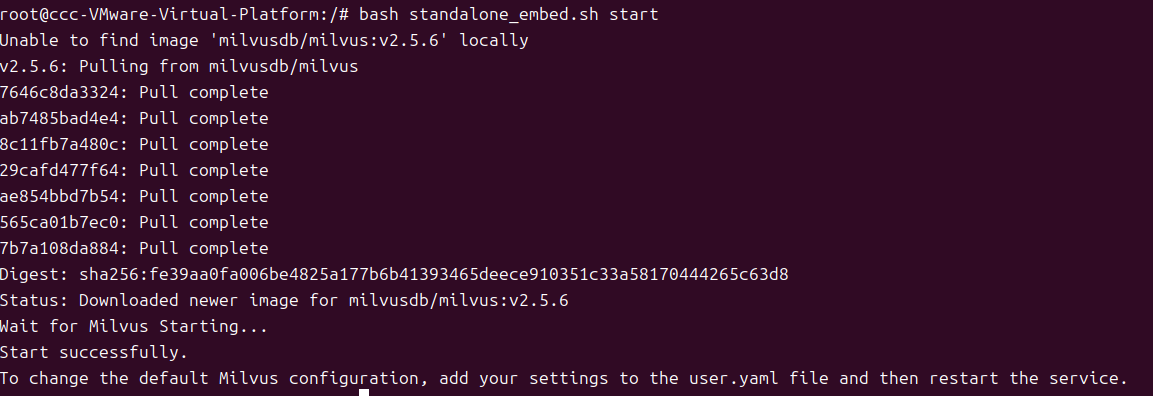
在这里插入图片描述
步骤3:验证部署是否成功
# 查看Docker容器状态
docker ps | grep milvus- 若输出包含“milvusdb/milvus-standalone”,且状态为“Up”,说明服务正常运行;
- 核心端口验证:用
netstat -tuln | grep 19530,若能看到端口监听,说明服务端口已开放。

在这里插入图片描述
3. 常用脚本命令(后续管理用)
# 停止Milvus服务
bash standalone_embed.sh stop
# 重启Milvus服务
bash standalone_embed.sh restart
# 删除Milvus服务(含数据,谨慎使用)
bash standalone_embed.sh delete
# 升级Milvus版本(需群内提供新版本脚本)
bash standalone_embed.sh upgrade4. 数据存储说明
- 数据卷路径:Milvus数据默认映射到当前目录的
volumes/milvus文件夹; - 数据安全性:容器重启或重建时,数据不会丢失(存储在宿主机文件夹);
- 备份建议:重要数据定期备份
volumes/milvus文件夹,避免服务器故障导致数据丢失。
四、Milvus WebUI使用:验证服务与查看信息
部署成功后,通过WebUI可快速查看服务状态,无需命令行操作。
1. 访问WebUI
打开浏览器,输入地址:http://服务器IP:9091/webui(示例:http://127.0.0.1:9091/webui/)
- 注意:服务器IP需是公网IP(云服务器),若为内网服务器,需在同一内网访问;
- 无需登录:默认无权限校验,直接访问即可。
在这里插入图片描述
2. WebUI核心功能(新手重点关注)
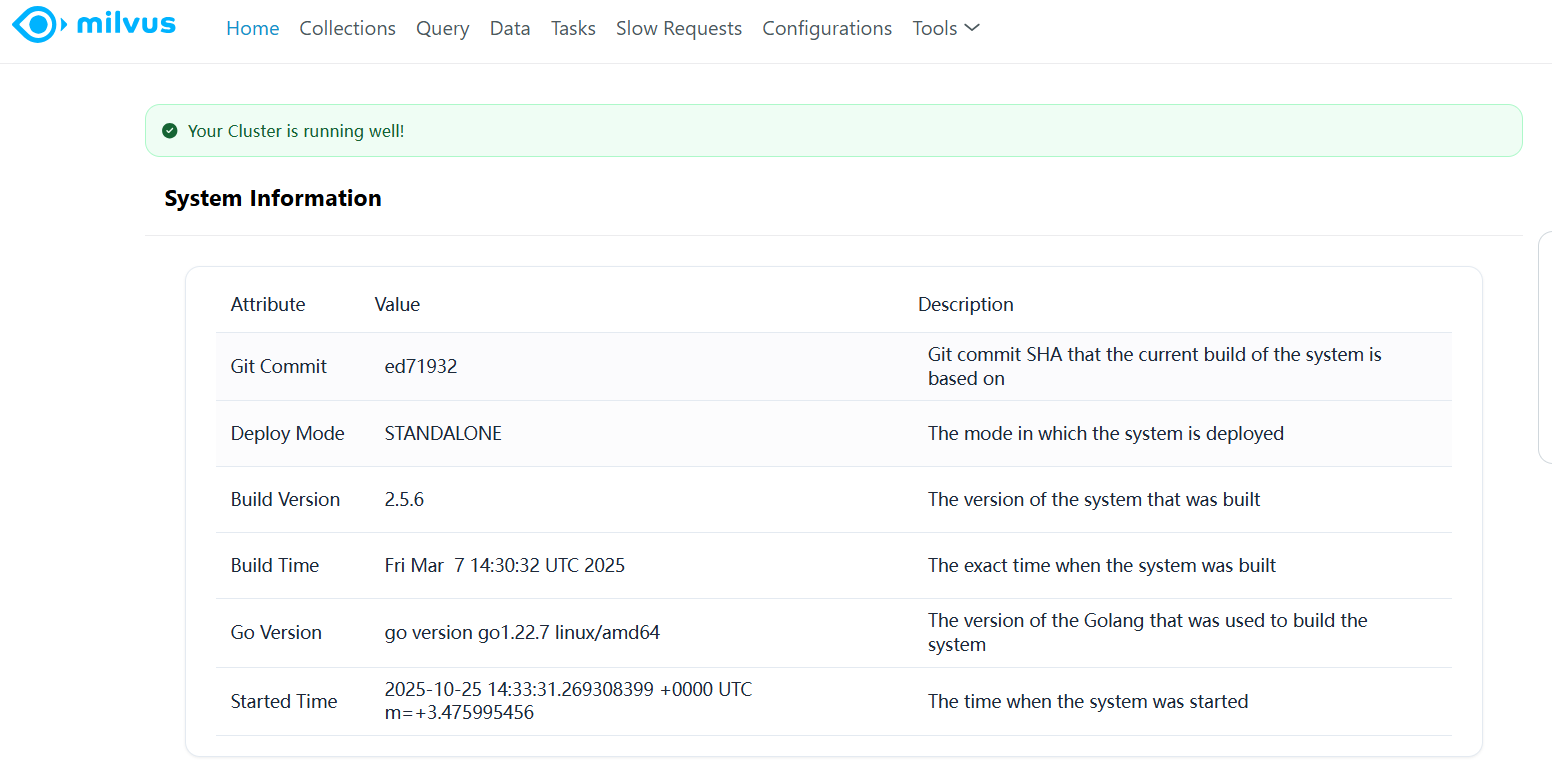
Milvus WebUI是内置工具,功能简洁,主要用于“验证服务”和“查看基础信息”,不支持数据操作(如创建Collection、插入数据):
- 运行环境:查看Milvus版本、服务器配置、组件状态(Coordinator、Query Node等是否正常);
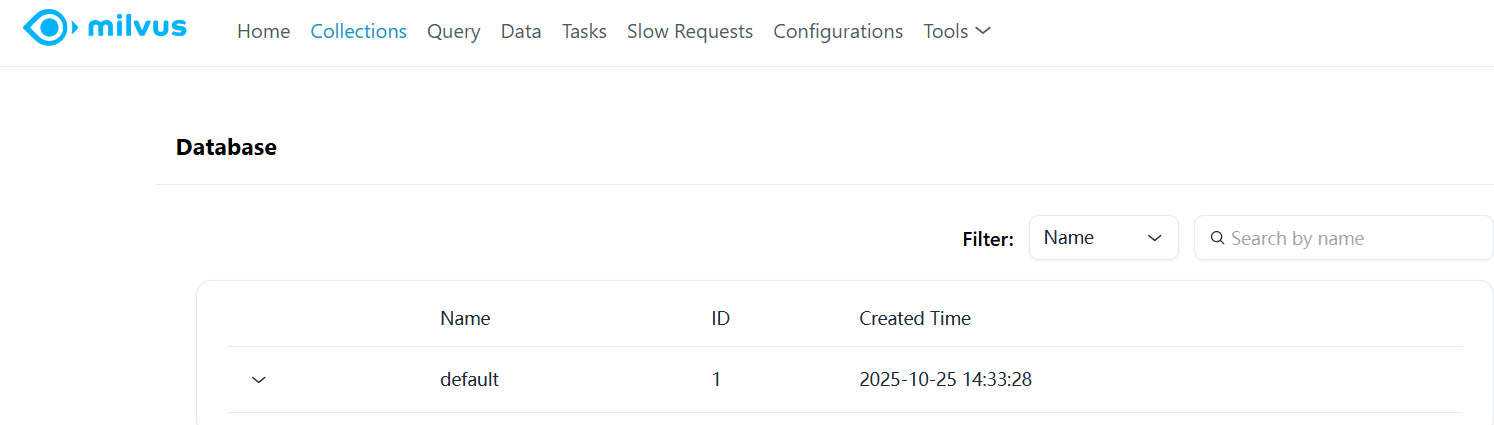
- 数据详情:查看已创建的Collection、分区、分片信息;
- 任务监控:查看查询任务、插入任务的执行状态,以及慢查询记录(便于排查性能问题)。
在这里插入图片描述
3. 补充:数据操作工具推荐
若需可视化操作数据(创建Collection、插入向量、执行查询),推荐使用Attu工具(Milvus官方可视化客户端),支持Windows/Mac/Linux,后续会单独出实战教程。
五、部署关键注意事项(避坑指南)
- 权限校验:默认部署无权限校验,生产环境务必部署在内网,或配置IP白名单,避免公网暴露;
- 端口开放:云服务器必须在安全组开放3个端口(2379、9091、19530),否则无法访问服务和WebUI;
- 版本兼容:必须使用课程指定版本的脚本,不同版本的API和配置可能不兼容,导致后续实战报错;
- 资源配置:学习测试建议2核4G以上,若数据量超过1000万,建议升级到4核8G,避免内存不足;
六、核心总结
- 部署选型:新手优先Milvus Standalone(Docker一键部署),原型开发用Milvus Lite,生产环境选分布式版或云服务;
- 实战关键:下载正确脚本、开放端口、验证容器状态,三步搞定部署;
- WebUI作用:仅用于查看服务状态和基础信息,数据操作需用Attu或代码调用API;
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-12-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号