MCP Client 调试与问题定位技巧


作者:HOS(安全风信子) 日期:2026-01-01 来源平台:GitHub 摘要: 调试与问题定位是确保 MCP Client 稳定运行的关键技能。本文深入剖析 MCP v2.0 框架下 Client 的调试与问题定位技巧,从日志系统、调试工具到问题分析方法,全面覆盖调试与问题定位的核心技术。通过真实代码示例、Mermaid 流程图和多维度对比表,展示 MCP v2.0 如何实现智能日志、交互式调试和故障分析,为构建稳定、可靠的 AI 工具调用系统提供实战指南。
一、背景动机与当前热点
1.1 为什么调试与问题定位如此重要?
在 AI 工具调用场景中,调试与问题定位具有以下关键优势:
- 提高系统稳定性:及时发现和解决问题,确保系统稳定运行
- 降低维护成本:快速定位问题,减少调试时间和人力成本
- 提升开发效率:加速开发迭代,提高开发效率
- 增强用户体验:减少因系统问题导致的用户体验下降
- 促进系统优化:通过问题分析,发现系统瓶颈,促进优化
随着 MCP v2.0 的发布,调试与问题定位成为构建稳定 AI 工具调用系统的重要基础。
1.2 当前调试与问题定位的发展趋势
根据 GitHub 最新趋势和 AI 工具生态的发展,MCP Client 的调试与问题定位正朝着以下方向发展:
- 智能日志系统:基于 AI 的日志分析和异常检测,自动识别问题
- 交互式调试工具:支持实时调试和动态调整,提高调试效率
- 分布式追踪:实现端到端的分布式追踪,便于分析复杂调用链
- 可视化调试界面:提供直观的可视化调试界面,降低调试难度
- 自动化问题定位:自动定位问题根源,减少人工干预
这些趋势反映了调试与问题定位从传统的手动调试向更智能、更高效的自动化调试演进。
1.3 MCP v2.0 调试与问题定位的核心价值
MCP v2.0 重新定义了 Client 的调试与问题定位方式,其核心价值体现在:
- 智能日志系统:提供详细的日志记录和智能分析,便于问题定位
- 交互式调试支持:支持实时调试和动态调整,提高调试效率
- 分布式追踪集成:支持与分布式追踪系统集成,便于分析复杂调用链
- 可视化调试工具:提供直观的可视化调试界面,降低调试难度
- 自动化问题定位:自动识别异常和问题,减少人工干预
- 可扩展性:支持自定义调试工具和插件,便于扩展
理解 MCP Client 的调试与问题定位技巧,对于构建稳定、可靠的 AI 工具调用系统至关重要。
二、核心更新亮点与新要素
2.1 智能日志系统
MCP v2.0 实现了智能日志系统,提供详细的日志记录和智能分析。
新要素 1:结构化日志
- 采用结构化日志格式,便于机器解析和分析
- 支持 JSON、YAML 等多种格式
- 包含丰富的上下文信息,如请求 ID、时间戳、错误类型等
新要素 2:多级别日志
- 支持多种日志级别,如 DEBUG、INFO、WARNING、ERROR、CRITICAL
- 支持动态调整日志级别,无需重启服务
- 支持基于模块和组件的日志级别配置
新要素 3:智能日志分析
- 基于 AI 的日志分析,自动识别异常和问题
- 支持日志模式匹配和异常检测
- 提供日志聚合和可视化分析
2.2 交互式调试支持
MCP v2.0 实现了交互式调试支持,提高调试效率。
新要素 4:实时调试
- 支持实时调试,可动态调整系统状态和参数
- 支持断点调试和单步执行
- 支持查看和修改运行时变量
新要素 5:远程调试
- 支持远程调试,便于调试分布式系统
- 支持安全的远程连接,保护系统安全
- 支持多客户端同时调试
新要素 6:调试 API
- 提供调试 API,便于集成到各种调试工具
- 支持查询系统状态、查看日志、调整参数等
- 支持与 CI/CD 系统集成,自动化调试
2.3 分布式追踪与可视化
MCP v2.0 实现了分布式追踪与可视化,便于分析复杂调用链。
新要素 7:分布式追踪集成
- 支持与分布式追踪系统集成,如 Jaeger、Zipkin 和 OpenTelemetry
- 实现端到端的调用链追踪
- 支持跨服务和跨组件的追踪
新要素 8:可视化调试界面
- 提供直观的可视化调试界面
- 支持调用链可视化、时序图和火焰图
- 支持实时监控和告警
新要素 9:自动化问题定位
- 自动定位问题根源,减少人工干预
- 支持基于机器学习的异常检测和根因分析
- 提供问题修复建议,加速问题解决
三、技术深度拆解与实现分析
3.1 MCP Client 调试与问题定位架构设计
MCP Client 的调试与问题定位架构包括以下核心组件:
- 日志系统:负责记录和管理系统日志
- 调试接口:提供调试 API 和命令行接口
- 分布式追踪:实现端到端的调用链追踪
- 可视化界面:提供直观的可视化调试界面
- 智能分析引擎:负责日志分析和异常检测
- 调试工具集成:支持与各种调试工具集成
Mermaid 架构图:MCP Client 调试与问题定位架构
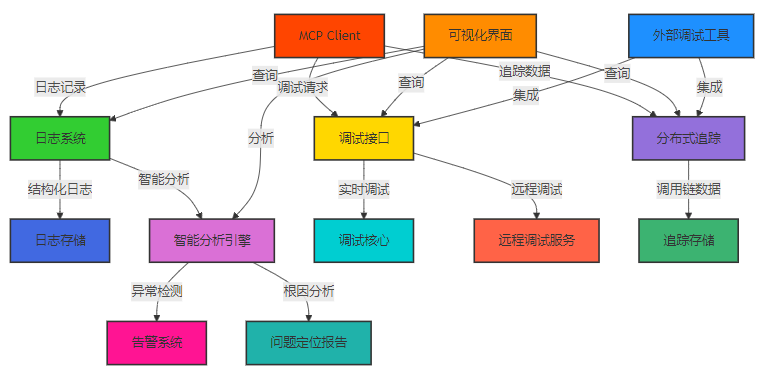
3.2 核心实现细节
3.2.1 智能日志系统实现
智能日志系统负责记录和管理系统日志。
代码示例 1:智能日志系统实现
import logging
import json
import time
import os
from typing import Dict, Any, Optional
from dataclasses import dataclass
@dataclass
class LogEntry:
"""日志条目"""
level: str
message: str
timestamp: float
request_id: Optional[str] = None
module: Optional[str] = None
component: Optional[str] = None
context: Optional[Dict[str, Any]] = None
error: Optional[str] = None
class SmartLogger:
"""智能日志系统"""
def __init__(self, name: str, log_level: str = "INFO"):
"""
初始化智能日志系统
Args:
name: 日志名称
log_level: 日志级别
"""
self.name = name
self.log_level = log_level
# 创建日志记录器
self.logger = logging.getLogger(name)
self.logger.setLevel(getattr(logging, log_level.upper()))
# 创建控制台处理器
console_handler = logging.StreamHandler()
console_handler.setLevel(getattr(logging, log_level.upper()))
# 创建文件处理器
log_file = f"{name}_{time.strftime('%Y-%m-%d')}.log"
file_handler = logging.FileHandler(log_file)
file_handler.setLevel(logging.DEBUG) # 文件日志记录所有级别
# 创建格式化器
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
# 设置格式化器
console_handler.setFormatter(formatter)
file_handler.setFormatter(formatter)
# 添加处理器
self.logger.addHandler(console_handler)
self.logger.addHandler(file_handler)
# 结构化日志存储
self.logs = []
def set_level(self, level: str):
"""
设置日志级别
Args:
level: 日志级别
"""
self.log_level = level
log_level = getattr(logging, level.upper())
self.logger.setLevel(log_level)
for handler in self.logger.handlers:
if isinstance(handler, logging.StreamHandler):
handler.setLevel(log_level)
def log(self, level: str, message: str, request_id: Optional[str] = None,
module: Optional[str] = None, component: Optional[str] = None,
context: Optional[Dict[str, Any]] = None, error: Optional[str] = None):
"""
"""
记录日志
Args:
level: 日志级别
message: 日志消息
request_id: 请求 ID
module: 模块名称
component: 组件名称
context: 上下文信息
error: 错误信息
"""
# 创建日志条目
log_entry = LogEntry(
level=level,
message=message,
timestamp=time.time(),
request_id=request_id,
module=module,
component=component,
context=context,
error=error
)
# 添加到日志列表
self.logs.append(log_entry)
# 限制日志列表大小
if len(self.logs) > 10000:
self.logs = self.logs[-10000:]
# 记录到日志系统
log_func = getattr(self.logger, level.lower())
# 格式化日志消息
log_message = message
if request_id:
log_message = f"[{request_id}] {log_message}"
if module:
log_message = f"[{module}] {log_message}"
if component:
log_message = f"[{component}] {log_message}"
if context:
log_message = f"{log_message} | Context: {json.dumps(context, ensure_ascii=False)}"
if error:
log_message = f"{log_message} | Error: {error}"
log_func(log_message)
def debug(self, message: str, **kwargs):
"""记录 DEBUG 级别日志"""
self.log("DEBUG", message, **kwargs)
def info(self, message: str, **kwargs):
"""记录 INFO 级别日志"""
self.log("INFO", message, **kwargs)
def warning(self, message: str, **kwargs):
"""记录 WARNING 级别日志"""
self.log("WARNING", message, **kwargs)
def error(self, message: str, **kwargs):
"""记录 ERROR 级别日志"""
self.log("ERROR", message, **kwargs)
def critical(self, message: str, **kwargs):
"""记录 CRITICAL 级别日志"""
self.log("CRITICAL", message, **kwargs)
def get_logs(self, level: Optional[str] = None,
request_id: Optional[str] = None,
module: Optional[str] = None,
component: Optional[str] = None,
start_time: Optional[float] = None,
end_time: Optional[float] = None) -> list:
"""
获取日志列表
Args:
level: 日志级别过滤
request_id: 请求 ID 过滤
module: 模块过滤
component: 组件过滤
start_time: 开始时间
end_time: 结束时间
Returns:
过滤后的日志列表
"""
filtered_logs = self.logs.copy()
# 按级别过滤
if level:
filtered_logs = [log for log in filtered_logs if log.level.upper() == level.upper()]
# 按请求 ID 过滤
if request_id:
filtered_logs = [log for log in filtered_logs if log.request_id == request_id]
# 按模块过滤
if module:
filtered_logs = [log for log in filtered_logs if log.module == module]
# 按组件过滤
if component:
filtered_logs = [log for log in filtered_logs if log.component == component]
# 按时间范围过滤
if start_time:
filtered_logs = [log for log in filtered_logs if log.timestamp >= start_time]
if end_time:
filtered_logs = [log for log in filtered_logs if log.timestamp <= end_time]
return filtered_logs
def clear_logs(self):
"""清空日志列表"""
self.logs.clear()代码解析:
- 实现了结构化日志系统,支持多种日志级别和格式
- 支持动态调整日志级别,无需重启服务
- 提供日志过滤和查询功能,便于问题定位
- 支持控制台和文件日志记录
- 便于扩展和定制
3.2.2 交互式调试接口实现
交互式调试接口提供调试 API 和命令行接口,便于调试和问题定位。
代码示例 2:交互式调试接口实现
import asyncio
import json
from typing import Dict, Any, Optional
from fastapi import FastAPI, HTTPException, Query
from pydantic import BaseModel
app = FastAPI(title="MCP Client 调试 API")
# 模拟 MCP Client 实例
class MockMCPClient:
"""模拟 MCP Client 实例"""
def __init__(self):
self.config = {
"server_url": "http://localhost:8000/mcp",
"timeout": 30.0,
"retry_count": 3,
"log_level": "INFO",
"debug_enabled": False
}
self.status = {
"is_connected": True,
"active_requests": 0,
"total_requests": 100,
"successful_requests": 95,
"error_count": 5,
"uptime": 3600
}
def get_config(self) -> Dict[str, Any]:
"""获取配置"""
return self.config.copy()
def update_config(self, updates: Dict[str, Any]) -> Dict[str, Any]:
"""更新配置"""
self.config.update(updates)
return self.config.copy()
def get_status(self) -> Dict[str, Any]:
"""获取状态"""
return self.status.copy()
def set_debug_mode(self, enabled: bool) -> bool:
"""设置调试模式"""
self.config["debug_enabled"] = enabled
return enabled
def get_debug_info(self) -> Dict[str, Any]:
"""获取调试信息"""
return {
"config": self.config,
"status": self.status,
"debug_data": {
"active_calls": [],
"recent_errors": [],
"performance_metrics": {}
}
}
# 创建模拟实例
mcp_client = MockMCPClient()
# 调试 API 模型
class ConfigUpdate(BaseModel):
"""配置更新模型"""
updates: Dict[str, Any]
class DebugMode(BaseModel):
"""调试模式模型"""
enabled: bool
# API 端点
@app.get("/api/debug/config", response_model=Dict[str, Any])
def get_config():
"""获取 MCP Client 配置"""
return mcp_client.get_config()
@app.put("/api/debug/config", response_model=Dict[str, Any])
def update_config(config_update: ConfigUpdate):
"""更新 MCP Client 配置"""
return mcp_client.update_config(config_update.updates)
@app.get("/api/debug/status", response_model=Dict[str, Any])
def get_status():
"""获取 MCP Client 状态"""
return mcp_client.get_status()
@app.get("/api/debug/info", response_model=Dict[str, Any])
def get_debug_info():
"""获取详细调试信息"""
return mcp_client.get_debug_info()
@app.post("/api/debug/debug_mode", response_model=Dict[str, bool])
def set_debug_mode(debug_mode: DebugMode):
"""设置调试模式"""
result = mcp_client.set_debug_mode(debug_mode.enabled)
return {"enabled": result}
@app.post("/api/debug/restart", response_model=Dict[str, str])
def restart_client():
"""重启 MCP Client"""
# 模拟重启
return {"message": "MCP Client 已重启"}
@app.get("/api/debug/logs", response_model=Dict[str, Any])
def get_logs(
level: Optional[str] = Query(None, description="日志级别过滤"),
request_id: Optional[str] = Query(None, description="请求 ID 过滤"),
limit: int = Query(100, description="日志数量限制")
):
"""获取日志"""
# 模拟日志数据
logs = [
{
"timestamp": "2026-01-01T12:00:00Z",
"level": "INFO",
"message": "MCP Client 启动",
"request_id": None,
"module": "client",
"component": "core"
},
{
"timestamp": "2026-01-01T12:01:00Z",
"level": "DEBUG",
"message": "连接到 MCP Server",
"request_id": "req-123",
"module": "client",
"component": "connector"
},
{
"timestamp": "2026-01-01T12:02:00Z",
"level": "ERROR",
"message": "调用工具失败",
"request_id": "req-456",
"module": "client",
"component": "executor",
"error": "工具执行超时"
}
]
# 过滤日志
filtered_logs = logs
if level:
filtered_logs = [log for log in filtered_logs if log["level"] == level.upper()]
if request_id:
filtered_logs = [log for log in filtered_logs if log["request_id"] == request_id]
# 限制数量
filtered_logs = filtered_logs[:limit]
return {
"logs": filtered_logs,
"total": len(filtered_logs),
"limit": limit
}
@app.get("/health")
def health_check():
"""健康检查"""
return {"status": "healthy"}
# 运行调试服务器
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8080)代码解析:
- 实现了基于 FastAPI 的调试 API
- 支持获取和更新配置、获取状态、设置调试模式等功能
- 支持日志查询和过滤
- 提供健康检查端点
- 便于扩展和集成
3.2.3 分布式追踪集成实现
分布式追踪集成实现了端到端的调用链追踪,便于分析复杂调用链。
代码示例 3:分布式追踪集成实现
import os
from opentelemetry import trace
from opentelemetry.exporter.jaeger.thrift import JaegerExporter
from opentelemetry.sdk.resources import SERVICE_NAME, Resource
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.instrumentation.requests import RequestsInstrumentor
from opentelemetry.instrumentation.aiohttp_client import AioHttpClientInstrumentor
# 初始化分布式追踪
def init_tracing(service_name: str = "mcp-client"):
"""
初始化分布式追踪
Args:
service_name: 服务名称
"""
# 创建资源
resource = Resource(
attributes={
SERVICE_NAME: service_name
}
)
# 创建追踪提供程序
tracer_provider = TracerProvider(resource=resource)
trace.set_tracer_provider(tracer_provider)
# 创建 Jaeger 导出器
jaeger_exporter = JaegerExporter(
agent_host_name="localhost",
agent_port=6831,
)
# 创建批处理 span 处理器
span_processor = BatchSpanProcessor(jaeger_exporter)
tracer_provider.add_span_processor(span_processor)
# 初始化请求工具的自动追踪
RequestsInstrumentor().instrument()
AioHttpClientInstrumentor().instrument()
print(f"分布式追踪已初始化,服务名称: {service_name}")
# 获取追踪器
def get_tracer(name: str) -> trace.Tracer:
"""
获取追踪器
Args:
name: 追踪器名称
Returns:
追踪器实例
"""
return trace.get_tracer(name)
# 示例:使用追踪器
async def example_with_tracing():
"""使用追踪器的示例"""
tracer = get_tracer("mcp-client-example")
# 创建根 span
with tracer.start_as_current_span("mcp-client-request") as root_span:
root_span.set_attribute("request.type", "tool_call")
root_span.set_attribute("client.version", "2.0")
# 模拟工具调用
with tracer.start_as_current_span("tool-selection") as selection_span:
selection_span.set_attribute("tool.count", 5)
selection_span.set_attribute("selected.tool", "weather_api")
# 模拟工具选择逻辑
await asyncio.sleep(0.1)
# 模拟工具执行
with tracer.start_as_current_span("tool-execution") as execution_span:
execution_span.set_attribute("tool.name", "weather_api")
execution_span.set_attribute("tool.params.city", "beijing")
# 模拟工具执行逻辑
await asyncio.sleep(0.2)
# 模拟结果处理
with tracer.start_as_current_span("result-processing") as processing_span:
processing_span.set_attribute("result.status", "success")
# 模拟结果处理逻辑
await asyncio.sleep(0.05)
root_span.set_attribute("request.status", "success")
print("带有追踪的请求处理完成")
# 运行示例
if __name__ == "__main__":
# 初始化追踪
init_tracing()
# 运行示例
import asyncio
asyncio.run(example_with_tracing())代码解析:
- 实现了基于 OpenTelemetry 和 Jaeger 的分布式追踪集成
- 支持自动追踪 HTTP 请求
- 提供了创建和使用追踪器的示例
- 支持设置 span 属性和嵌套 span
- 便于集成到现有的分布式追踪系统
3.2.4 调试与问题定位示例
代码示例 4:调试与问题定位示例
# 示例:MCP Client 调试与问题定位示例
import asyncio
import json
from smart_logger import SmartLogger
from distributed_tracing import init_tracing, get_tracer
async def example_debugging():
"""调试与问题定位示例"""
print("=== MCP Client 调试与问题定位示例 ===")
# 1. 初始化日志系统
logger = SmartLogger("mcp-client", log_level="DEBUG")
logger.info("初始化 MCP Client 调试系统")
# 2. 初始化分布式追踪
init_tracing()
tracer = get_tracer("mcp-client-debug")
# 3. 模拟 MCP Client 请求处理
request_id = "debug-req-001"
with tracer.start_as_current_span("mcp-client-debug-request") as root_span:
root_span.set_attribute("request_id", request_id)
root_span.set_attribute("debug_mode", True)
# 记录请求开始
logger.info("处理 MCP 请求", request_id=request_id, module="client", component="core")
try:
# 模拟工具调用流程
logger.debug("开始工具选择", request_id=request_id, module="client", component="tool-selector")
with tracer.start_as_current_span("tool-selection") as selection_span:
selection_span.set_attribute("request_id", request_id)
selection_span.set_attribute("tool_count", 3)
# 模拟工具选择
await asyncio.sleep(0.1)
selected_tool = "weather_api"
logger.debug(f"选择工具: {selected_tool}", request_id=request_id,
module="client", component="tool-selector")
selection_span.set_attribute("selected_tool", selected_tool)
# 模拟工具执行
logger.debug(f"开始执行工具: {selected_tool}", request_id=request_id,
module="client", component="tool-executor")
with tracer.start_as_current_span("tool-execution") as execution_span:
execution_span.set_attribute("request_id", request_id)
execution_span.set_attribute("tool_name", selected_tool)
# 模拟工具执行错误
raise Exception("工具执行超时")
except Exception as e:
# 记录错误
logger.error(f"工具调用失败: {e}", request_id=request_id,
module="client", component="core", error=str(e))
# 设置错误属性
root_span.set_attribute("request_status", "error")
root_span.set_attribute("error_type", type(e).__name__)
root_span.set_attribute("error_message", str(e))
# 模拟错误处理
logger.debug("开始错误处理", request_id=request_id, module="client", component="error-handler")
with tracer.start_as_current_span("error-handling") as error_span:
error_span.set_attribute("request_id", request_id)
error_span.set_attribute("error_type", type(e).__name__)
# 模拟错误处理逻辑
await asyncio.sleep(0.1)
# 记录错误处理结果
logger.info("错误处理完成,返回默认结果", request_id=request_id,
module="client", component="error-handler")
# 记录请求结束
logger.info("MCP 请求处理完成", request_id=request_id, module="client", component="core")
# 4. 展示日志查询功能
print("\n=== 日志查询示例 ===")
# 查询 ERROR 级别日志
error_logs = logger.get_logs(level="ERROR")
print(f"ERROR 级别日志数量: {len(error_logs)}")
for log in error_logs:
print(f"- [{log.level}] {log.message} | {log.timestamp}")
# 根据请求 ID 查询日志
req_logs = logger.get_logs(request_id=request_id)
print(f"\n请求 {request_id} 的日志数量: {len(req_logs)}")
for log in req_logs[:3]: # 只显示前 3 条
print(f"- [{log.level}] {log.message} | {log.module} | {log.component}")
# 5. 模拟调试 API 调用
print("\n=== 调试 API 调用示例 ===")
print("调试 API 提供以下功能:")
print("- GET /api/debug/config - 获取配置")
print("- PUT /api/debug/config - 更新配置")
print("- GET /api/debug/status - 获取状态")
print("- GET /api/debug/info - 获取调试信息")
print("- POST /api/debug/debug_mode - 设置调试模式")
print("- GET /api/debug/logs - 查询日志")
print("- POST /api/debug/restart - 重启客户端")
async def main():
"""主函数"""
await example_debugging()
if __name__ == "__main__":
asyncio.run(main())代码解析:
- 展示了 MCP Client 调试与问题定位的完整流程
- 包含了日志记录、分布式追踪、错误处理等功能
- 演示了日志查询和调试 API 的使用
- 提供了详细的日志输出,便于理解和调试
三、技术深度拆解与实现分析(续)
3.3 调试与问题定位的关键技术点
3.3.1 智能日志设计
MCP v2.0 的智能日志设计包括以下关键技术点:
- 结构化日志格式:采用结构化日志格式,便于机器解析和分析
- 丰富的上下文信息:包含请求 ID、时间戳、错误类型等上下文信息
- 多级别日志:支持多种日志级别,便于过滤和调试
- 动态日志级别调整:支持动态调整日志级别,无需重启服务
- 日志聚合和分析:支持日志聚合和智能分析,便于问题定位
Mermaid 流程图:智能日志流程
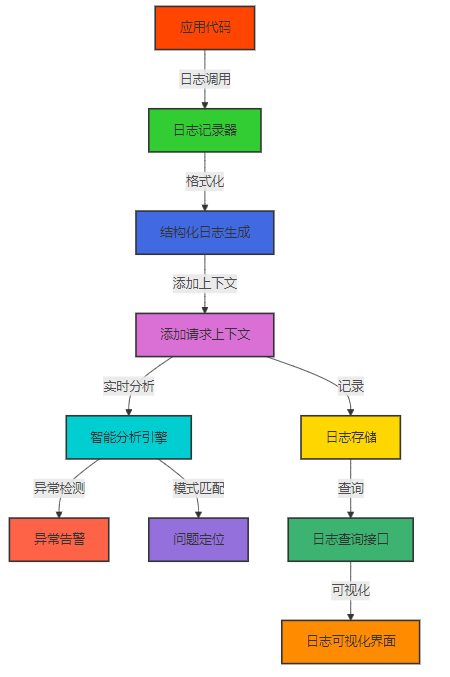
3.3.2 交互式调试技术
MCP v2.0 的交互式调试技术包括以下关键技术点:
- 实时调试:支持实时调试,可动态调整系统状态和参数
- 断点调试:支持断点调试和单步执行,便于分析代码流程
- 远程调试:支持远程调试,便于调试分布式系统
- 调试 API:提供调试 API,便于集成到各种调试工具
- 可视化调试界面:提供直观的可视化调试界面,降低调试难度
3.3.3 分布式追踪技术
MCP v2.0 的分布式追踪技术包括以下关键技术点:
- 端到端追踪:实现端到端的调用链追踪,便于分析复杂调用关系
- 跨服务追踪:支持跨服务和跨组件的追踪,便于分析分布式系统
- 可视化调用链:提供直观的可视化调用链,便于理解系统行为
- 性能分析:支持性能分析,便于识别系统瓶颈
- 与现有系统集成:支持与现有分布式追踪系统集成,如 Jaeger、Zipkin 等
3.3.4 自动化问题定位
MCP v2.0 的自动化问题定位包括以下关键技术点:
- 异常检测:自动检测系统异常和错误
- 根因分析:基于机器学习的根因分析,自动定位问题根源
- 问题修复建议:提供问题修复建议,加速问题解决
- 自动化测试:支持自动化测试,便于验证问题修复
- 持续监控:持续监控系统状态,及时发现问题
四、与主流方案深度对比
4.1 MCP v2.0 与其他调试与问题定位方案的对比
对比维度 | MCP v2.0 | 传统日志系统 | 基于控制台的调试 | 商业 APM 工具 |
|---|---|---|---|---|
日志系统 | 智能日志系统,支持结构化日志和多级别日志 | 基本日志记录,缺乏智能分析 | 简单控制台输出,缺乏持久化 | 强大的日志系统,支持智能分析 |
调试支持 | 交互式调试,支持实时和远程调试 | 基本调试支持,缺乏交互式功能 | 简单的控制台调试,功能有限 | 强大的调试功能,支持多种调试方式 |
分布式追踪 | 内置分布式追踪支持,与主流系统集成 | 缺乏分布式追踪支持 | 不支持分布式追踪 | 强大的分布式追踪功能 |
可视化界面 | 提供直观的可视化调试界面 | 缺乏可视化界面 | 简单的控制台输出 | 丰富的可视化界面和仪表盘 |
自动化问题定位 | 支持自动化问题定位和根因分析 | 不支持自动化问题定位 | 不支持自动化问题定位 | 支持自动化问题定位和根因分析 |
可扩展性 | 高,支持自定义调试工具和插件 | 低,难以扩展 | 低,难以扩展 | 中,支持插件和扩展 |
成本 | 开源免费,成本低 | 低,基本免费 | 低,基本免费 | 高,商业许可费用 |
学习曲线 | 中,需要理解调试概念和工具 | 低,使用简单但功能有限 | 低,使用简单但功能有限 | 高,需要学习复杂的 APM 系统 |
适用场景 | 复杂分布式系统,需要高级调试功能 | 简单系统,仅需要基本日志 | 小型系统,简单调试需求 | 企业级系统,需要全面的 APM 功能 |
集成难度 | 中,需要集成到现有系统 | 低,易于集成 | 低,易于使用 | 高,需要复杂的集成和配置 |
4.2 不同调试工具的对比
工具类型 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|
日志分析工具 | 提供详细的日志记录和分析,便于问题定位 | 缺乏实时调试功能,难以分析复杂问题 | 日志密集型应用,需要分析历史日志 |
调试器 | 支持实时调试和断点执行,便于分析代码流程 | 难以调试分布式系统,影响系统性能 | 开发环境,需要详细的代码分析 |
分布式追踪系统 | 支持端到端的调用链追踪,便于分析复杂调用关系 | 配置复杂,需要集成到所有服务 | 分布式系统,需要分析复杂调用链 |
APM 工具 | 提供全面的性能监控和问题定位,支持多种调试方式 | 成本高,配置复杂 | 企业级系统,需要全面的 APM 功能 |
可视化调试工具 | 提供直观的可视化界面,降低调试难度 | 功能相对有限,难以处理复杂问题 | 初学者,需要直观的调试界面 |
4.3 不同分布式追踪系统的对比
系统名称 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|
Jaeger | 开源免费,易于部署和使用,支持多种语言 | 功能相对简单,缺乏高级分析功能 | 中小型分布式系统,需要基本的分布式追踪 |
Zipkin | 开源免费,轻量级,易于集成 | 缺乏高级可视化和分析功能 | 小型分布式系统,需要简单的分布式追踪 |
OpenTelemetry | 开源免费,支持多种语言和框架,与多种后端集成 | 配置相对复杂,生态仍在发展中 | 需要灵活的分布式追踪系统,支持多种后端 |
Datadog APM | 强大的可视化和分析功能,支持多种语言和框架 | 商业产品,成本高 | 企业级系统,需要全面的 APM 功能 |
New Relic APM | 强大的性能监控和问题定位功能,易于使用 | 商业产品,成本高 | 企业级系统,需要全面的 APM 功能 |
五、实际工程意义、潜在风险与局限性分析
5.1 MCP Client 调试与问题定位的工程实践
在实际工程实践中,MCP Client 的调试与问题定位需要考虑以下几个方面:
- 日志系统设计:
- 设计合理的日志格式和级别,便于问题定位
- 包含丰富的上下文信息,如请求 ID、时间戳、错误类型等
- 支持动态调整日志级别,无需重启服务
- 实现日志的持久化和归档,便于历史日志分析
- 调试工具选择:
- 根据系统规模和需求选择合适的调试工具
- 考虑工具的易用性、功能和成本
- 确保工具的兼容性和可扩展性
- 培训开发团队使用调试工具,提高调试效率
- 分布式追踪集成:
- 选择合适的分布式追踪系统,如 Jaeger 或 OpenTelemetry
- 确保所有服务都集成了追踪功能,实现端到端的调用链追踪
- 设计合理的 span 结构,包含必要的属性和上下文信息
- 定期分析追踪数据,识别系统瓶颈和问题
- 自动化问题定位:
- 实现自动化异常检测和告警,及时发现问题
- 基于机器学习的根因分析,自动定位问题根源
- 提供问题修复建议,加速问题解决
- 自动化测试,验证问题修复效果
- 监控与告警:
- 实现全面的监控,包括性能指标、日志和追踪数据
- 设计合理的告警规则,及时通知相关人员
- 提供直观的监控仪表盘,便于查看系统状态
- 定期分析监控数据,优化系统性能
5.2 潜在风险与挑战
MCP Client 的调试与问题定位也面临一些潜在风险和挑战:
- 性能影响:
- 详细的日志记录和追踪可能影响系统性能
- 实时调试可能导致系统响应变慢
- 需要在调试功能和系统性能之间平衡
- 安全风险:
- 远程调试可能带来安全风险,如未授权访问
- 调试信息可能包含敏感数据,需要保护
- 需要实现安全的调试访问控制和数据加密
- 复杂性增加:
- 调试工具和系统的集成可能增加系统复杂性
- 学习和使用高级调试工具需要一定的学习成本
- 需要维护和管理复杂的调试基础设施
- 数据量爆炸:
- 详细的日志和追踪可能产生大量数据,增加存储和处理成本
- 需要实现数据压缩和归档策略,优化存储成本
- 需要设计合理的数据保留策略,平衡数据可用性和成本
- 工具兼容性:
- 不同调试工具之间可能存在兼容性问题
- 与现有系统的集成可能遇到困难
- 需要选择兼容现有系统的调试工具
5.3 局限性分析
MCP v2.0 的调试与问题定位目前仍存在一些局限性:
- 分布式系统调试复杂度:对于大规模分布式系统,调试和问题定位仍然复杂
- 自动化程度有限:自动化问题定位和根因分析仍需进一步改进
- 可视化界面完善度:可视化调试界面和仪表盘仍需进一步完善
- 与商业工具的差距:与商业 APM 工具相比,功能和易用性仍有差距
- 生态成熟度:相关的工具和库仍在发展中,生态不够成熟
- 学习曲线:高级调试功能需要一定的学习成本,对开发人员要求较高
六、未来趋势展望与个人前瞻性预测
6.1 MCP Client 调试与问题定位的未来发展趋势
基于当前技术发展和社区动态,我预测 MCP Client 的调试与问题定位将朝着以下方向发展:
- AI 驱动的智能调试:
- 使用生成式 AI 辅助调试,自动生成调试代码和修复建议
- 基于大语言模型的日志分析,自动识别异常和问题
- 实现自然语言调试,使用自然语言描述问题和获取调试建议
- 增强的可视化调试:
- 3D 可视化调试界面,提供更直观的系统视图
- 增强现实(AR)调试,在真实环境中可视化系统状态
- 交互式可视化,支持直接在可视化界面中调整系统状态
- 分布式调试协调:
- 支持分布式系统中的调试协调,确保多个服务的调试操作一致
- 实现分布式调试事务,确保调试操作的原子性
- 支持跨服务的断点调试和单步执行
- 自动化调试流程:
- 自动化调试流程,从问题检测到修复验证的全流程自动化
- 实现自修复系统,自动检测和修复某些类型的问题
- 支持调试即代码,使用代码定义调试流程和规则
- 边缘计算调试支持:
- 增强的边缘计算调试支持,便于调试边缘设备和服务
- 支持离线调试,在网络不可用的情况下进行调试
- 实现边缘设备的远程调试和管理
- 隐私保护的调试:
- 实现隐私保护的调试,保护敏感数据
- 支持数据脱敏和加密,确保调试过程中的数据安全
- 实现零信任调试,确保调试访问的安全性
6.2 对 AI 工具生态的影响
MCP Client 调试与问题定位的发展将对 AI 工具生态产生深远影响:
- 提高 AI 工具的可靠性:通过高级调试和问题定位功能,提高 AI 工具的可靠性和稳定性
- 加速 AI 工具的开发:通过智能调试和自动化问题定位,加速 AI 工具的开发和迭代
- 降低 AI 工具的使用门槛:通过直观的可视化调试界面,降低 AI 工具的使用门槛
- 促进 AI 工具的标准化:推动 AI 工具调试和问题定位的标准化,便于跨工具和跨平台的调试
- 优化 AI 工具的性能:通过性能分析和瓶颈识别,优化 AI 工具的性能
6.3 个人建议与行动指南
对于正在或计划使用 MCP Client 调试与问题定位功能的开发人员,我提出以下建议:
- 从基础开始:先实现基本的日志系统和调试支持,再逐步扩展到更高级的功能
- 选择合适的工具:根据系统规模和需求选择合适的调试工具和分布式追踪系统
- 设计合理的日志格式:包含丰富的上下文信息,便于问题定位
- 实现全面的监控:监控系统的性能指标、日志和追踪数据,及时发现问题
- 培训开发团队:培训开发团队使用调试工具和技术,提高调试效率
- 定期分析调试数据:定期分析调试数据,识别系统瓶颈和问题,持续优化系统
- 关注新技术发展:持续关注 AI 驱动的智能调试等新技术,及时应用到系统中
- 平衡调试功能和性能:在调试功能和系统性能之间平衡,避免过度调试影响系统性能
参考链接:
- MCP v2.0 官方规范
- OpenTelemetry 官方文档
- Jaeger 官方文档
- Zipkin 官方文档
- FastAPI 官方文档
- Python logging 模块文档
- 分布式追踪最佳实践
- APM 系统比较
附录(Appendix):
附录 A:调试与问题定位最佳实践
- 日志系统最佳实践:
- 使用结构化日志格式,便于机器解析和分析
- 包含丰富的上下文信息,如请求 ID、时间戳、错误类型等
- 使用多级别日志,便于过滤和调试
- 实现动态日志级别调整,无需重启服务
- 定期归档和清理日志,优化存储成本
- 调试工具最佳实践:
- 根据系统规模和需求选择合适的调试工具
- 实现安全的远程调试访问控制
- 避免在生产环境中启用详细的调试功能,影响系统性能
- 培训开发团队使用调试工具,提高调试效率
- 定期更新调试工具,获取最新功能和安全修复
- 分布式追踪最佳实践:
- 设计合理的 span 结构,包含必要的属性和上下文信息
- 实现采样策略,优化性能和存储成本
- 确保所有服务都集成了追踪功能,实现端到端的调用链追踪
- 定期分析追踪数据,识别系统瓶颈和问题
- 与监控系统集成,提供全面的系统视图
- 问题定位最佳实践:
- 实现全面的监控,及时发现问题
- 使用自动化工具进行问题检测和根因分析
- 记录详细的问题信息,便于后续分析和改进
- 实现问题修复的验证流程,确保问题彻底解决
- 定期回顾和总结问题,持续优化系统
- 性能优化最佳实践:
- 识别系统瓶颈,优先优化关键路径
- 实现性能测试和基准测试,验证优化效果
- 使用缓存和异步处理,优化系统性能
- 定期分析性能数据,持续优化系统
- 考虑系统的可扩展性,设计支持横向扩展的架构
附录 B:常用调试命令和工具
工具/命令 | 用途 | 示例 |
|---|---|---|
logging | Python 标准日志模块,用于记录日志 | import logging; logging.info('message') |
pdb | Python 调试器,支持断点调试和单步执行 | import pdb; pdb.set_trace() |
ipdb | 增强版 Python 调试器,提供更好的交互体验 | import ipdb; ipdb.set_trace() |
gdb | GNU 调试器,用于 C/C++ 程序调试 | gdb ./program |
strace | 跟踪系统调用,用于分析程序行为 | strace -f ./program |
lsof | 列出打开的文件,用于分析资源使用 | lsof -p <pid> |
top | 显示系统进程和资源使用情况 | top |
htop | 增强版 top,提供更好的交互体验 | htop |
netstat | 显示网络连接和状态 | netstat -tuln |
tcpdump | 网络数据包捕获工具,用于网络调试 | tcpdump -i eth0 port 80 |
curl | HTTP 客户端,用于测试 HTTP 服务 | curl -v http://localhost:8000/health |
jaeger-ui | Jaeger 可视化界面,用于查看分布式追踪数据 | 访问 http://localhost:16686 |
zipkin-ui | Zipkin 可视化界面,用于查看分布式追踪数据 | 访问 http://localhost:9411/zipkin |
附录 C:常见问题与解决方案
问题类型 | 症状 | 原因 | 解决方案 |
|---|---|---|---|
日志过多 | 日志量过大,影响系统性能和存储成本 | 日志级别设置过低,记录了过多的调试信息 | 调整日志级别,仅记录必要的日志;实现日志采样策略;定期归档和清理日志 |
调试影响性能 | 启用调试功能后系统性能下降 | 详细的日志记录和追踪影响系统性能 | 仅在开发和测试环境启用详细的调试功能;使用采样策略减少性能影响;优化日志和追踪的实现 |
分布式追踪不完整 | 分布式追踪数据不完整,缺少某些服务的追踪信息 | 部分服务未集成追踪功能;服务间通信未被追踪;采样策略导致数据丢失 | 确保所有服务都集成了追踪功能;确保服务间通信被正确追踪;调整采样策略,确保关键数据不丢失 |
问题定位困难 | 难以定位问题根源,缺乏足够的调试信息 | 日志记录不完整;缺乏上下文信息;调试工具使用不当 | 优化日志格式,包含丰富的上下文信息;使用分布式追踪;学习和使用高级调试工具;实现自动化问题定位 |
调试工具兼容性问题 | 调试工具与现有系统不兼容,无法正常工作 | 调试工具版本不兼容;与现有库冲突;配置错误 | 选择与现有系统兼容的调试工具;更新调试工具版本;检查配置和依赖;寻求社区支持 |
安全风险 | 调试过程中出现安全问题,如未授权访问 | 远程调试未启用访问控制;调试信息包含敏感数据;调试端口暴露在公网 | 实现安全的调试访问控制;对调试信息进行脱敏和加密;避免在公网暴露调试端口;使用 VPN 或私有网络进行调试 |
学习曲线陡峭 | 开发人员难以掌握高级调试工具和技术 | 调试工具复杂;缺乏培训和文档;学习资源不足 | 提供培训和文档;选择易于使用的调试工具;从简单功能开始,逐步学习高级功能;寻求团队和社区支持 |
关键词:
MCP v2.0, 调试与问题定位, 智能日志系统, 交互式调试, 分布式追踪, 可视化调试, 自动化问题定位, 高可用性
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-01-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号