别再只知道 UUID 了!分布式 ID 生成方案大盘点与 Java 实现

别再只知道 UUID 了!分布式 ID 生成方案大盘点与 Java 实现

予枫
发布于 2026-01-12 14:48:15
发布于 2026-01-12 14:48:15
最近在深入学习 Java 后端和 Redis 中间件时,遇到了一个非常经典且重要的问题:在分布式场景下,如何生成一个全局唯一的 ID?
在单体架构时代,我们习惯使用数据库的自增 ID(Auto Increment),但在分库分表、微服务的高并发场景下,这种方式由于性能瓶颈和单点问题,显然已经力不从心。
今天这篇博客就来总结一下目前业界最主流的 4 种全局唯一 ID 生成策略,分析它们的原理、优缺点以及适用场景。
什么样的 ID 才是好 ID?
在设计 ID 生成器之前,我们需要明确“好 ID”的标准。通常有以下几个核心要求:
- 全局唯一性:这是最基本的要求,不能出现重复。
- 高可用 & 高性能:生成 ID 的动作非常频繁,不能成为系统的瓶颈,且服务要足够稳定。
- 递增性(趋势有序):这一点常被忽略。对于使用 MySQL(InnoDB 引擎)的系统,主键建议保持递增,因为 InnoDB 使用 B+ 树索引,有序的主键写入能避免频繁的“页分裂”,极大提升写入性能。
- 安全性:某些业务场景下(如订单号),ID 不应过于明显地暴露业务量(比如不能让人轻易猜出你一天有多少单)。
方案一:UUID (Universally Unique Identifier)

UUID 是最简单、最暴力的方案。JDK 原生支持,一行代码搞定。
代码实现
public static void main(String[] args) {
// 生成一个 UUID,并去掉中间的横线
String id = UUID.randomUUID().toString().replace("-", "");
System.out.println("UUID: " + id);
}优缺点分析
- 优点:
- 性能极高:完全在本地生成,没有网络消耗。
- 使用简单:不依赖任何外部组件(DB、Redis 等)。
- 缺点:
- 无序性(致命伤):UUID 是无序的字符串。如果作为 MySQL 主键,会导致大量的数据页分裂和移动,严重拖慢插入速度。
- 存储成本高:32 个字符(或 16 字节),相比 Long 类型特别占空间,也会导致索引变大。
- 信息不安全:完全随机,无法携带时间或业务含义。
👉 结论:适合生成 Token、Session ID 或非数据库主键的场景。坚决不建议用作 MySQL 的主键。
方案二:数据库自增 (Database Auto-Increment)
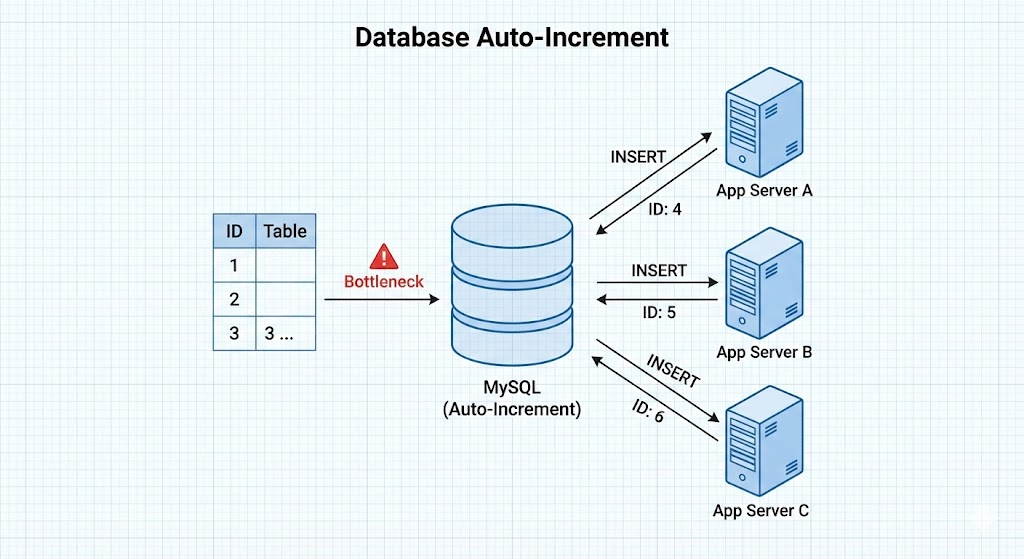
利用 MySQL 的 auto_increment 特性,或者 Oracle 的 Sequence。
原理
应用服务向数据库插入数据,数据库自动累计 ID。
优缺点分析
- 优点:
- 简单:利用现有数据库功能,成本低。
- 单调递增:对索引非常友好,查询效率高。
- 缺点:
- 并发瓶颈:在高并发下,数据库往往是最大的瓶颈。
- 分库分表麻烦:如果未来需要分库,不同库的自增 ID 会重复。虽然可以通过设置不同的“步长”(Step)来解决(如 DB1 生成 1,3,5... DB2 生成 2,4,6...),但这增加了扩容和维护的难度。
- 单点故障:数据库挂了,整个 ID 生成服务就不可用了。
👉 结论:适合并发量不高的中小项目,或者不需要分库分表的数据表。
方案三:Redis 自增策略
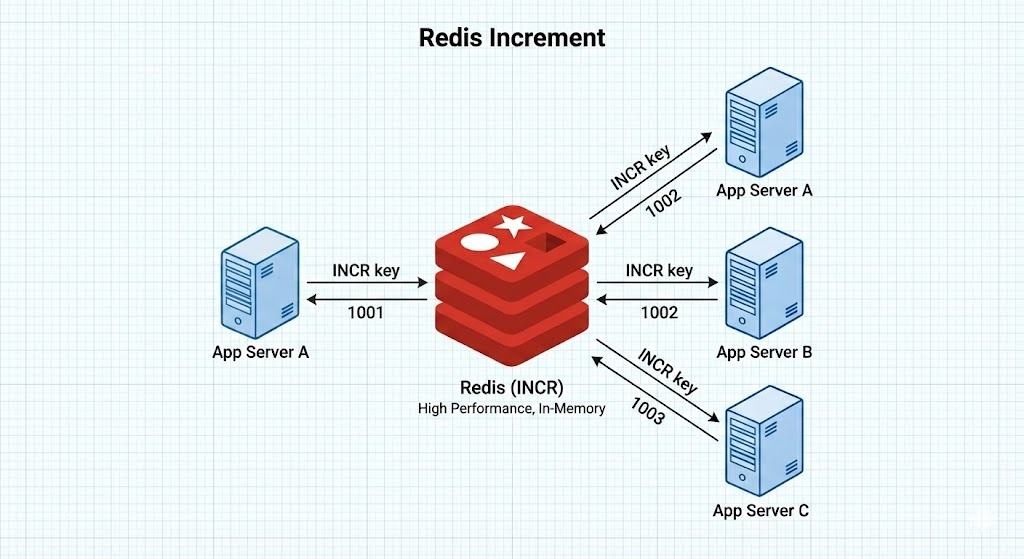
Redis 是单线程处理命令的,其 INCR 命令是原子的,天生适合做计数器。这是我最近在学 Redis 时觉得非常有意思的一个应用点。
代码思路 (Java + RedisTemplate)
为了避免 ID 被推测出业务量,通常会结合“时间戳”使用。
格式示例:yyyyMMdd + Redis自增值。
// 伪代码示例
public long generateId(String keyPrefix) {
// 1. 生成时间戳部分
String dateStr = DateTimeFormatter.ofPattern("yyyyMMdd").format(LocalDate.now());
// 2. 利用 Redis 原子递增
// key 举例: icr:order:20251216
Long increment = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + dateStr);
// 3. 拼接 ID (实际生产中通常需要通过位运算或字符串填充补齐位数)
return Long.parseLong(dateStr + String.format("%06d", increment));
}优缺点分析
- 优点:
- 高性能:基于内存操作,吞吐量远高于数据库。
- 有序递增:对数据库索引友好。
- 灵活:可以方便地把日期、业务类型编排进 ID 中。
- 缺点:
- 强依赖组件:如果 Redis 挂了,ID 生成服务就断了(需要配置 Sentinel 或 Cluster 高可用)。
- 运维成本:引入了额外的中间件维护成本。
👉 结论:非常适合高并发的业务场景(如秒杀、订单生成),且生成的 ID 具有业务含义。
方案四:雪花算法 (Snowflake)
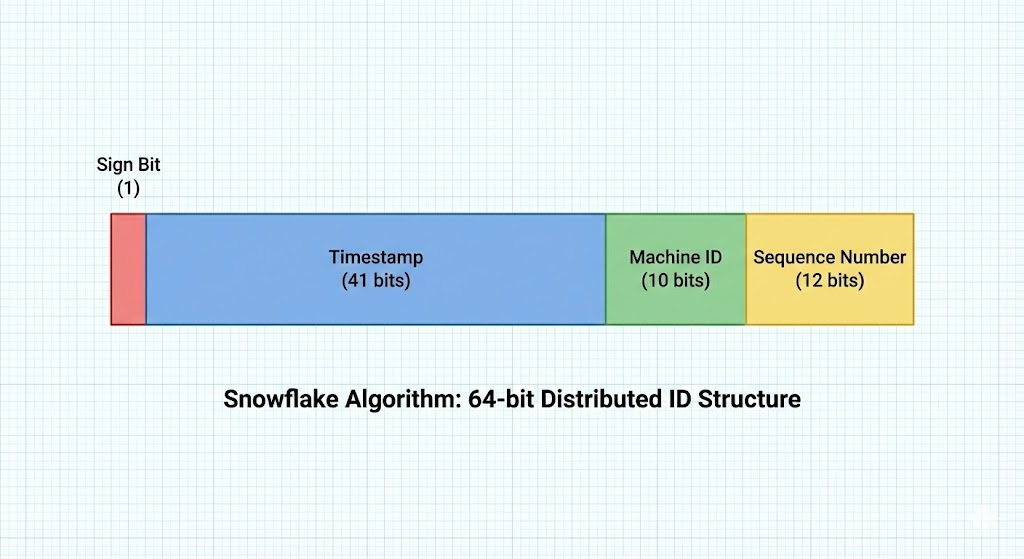
这是目前分布式系统中最流行、最成熟的方案,由 Twitter 开源。它的核心思想是将一个 64 位的 long 型数字切割成不同的部分。
结构图解 (64 bit)
- 1 bit:符号位(固定为0)。
- 41 bits:时间戳(毫秒级,可以使用 69 年)。
- 10 bits:机器 ID(支持 1024 个节点)。
- 12 bits:序列号(同一毫秒内支持生成 4096 个 ID)。
代码实现
通常不需要自己手写位运算,推荐使用成熟的工具包,例如 Hutool。
// 引入 Hutool 依赖后
public class IdTest {
public static void main(String[] args) {
// 参数1: 终端ID, 参数2: 数据中心ID
Snowflake snowflake = IdUtil.getSnowflake(1, 1);
long id = snowflake.nextId();
System.out.println("Snowflake ID: " + id);
}
}优缺点分析
- 优点:
- 极高并发:每秒可生成几百万个 ID。
- 不依赖网络:本地生成(除了启动时校验机器 ID),无单点故障。
- 趋势递增:整体按时间递增,索引性能好。
- 缺点:
- 时钟回拨问题:严重依赖服务器时间。如果服务器时间被回调(比如校准时间),算法可能会生成重复 ID。
👉 结论:几乎所有互联网大厂的主流选择,适合超大规模的分布式系统。
总结对比
最后,用一张表来总结这几种策略:
策略 | 唯一性 | 有序性 | 性能 | 依赖组件 | 核心痛点 |
|---|---|---|---|---|---|
UUID | 高 | 无 | 极高 | 无 | 索引性能差,ID太长 |
DB自增 | 高 | 严格有序 | 低 | 数据库 | 并发瓶颈,扩展麻烦 |
Redis | 高 | 严格有序 | 高 | Redis | 依赖 Redis 高可用 |
Snowflake | 高 | 趋势有序 | 极高 | 无 | 时钟回拨问题 |
个人建议:
如果你是初学者或者项目规模较小,Redis 自增是一个非常好的练手方案,既能满足性能要求,又能加深对 Redis 的理解。而如果是企业级的大型项目,Snowflake(配合 Hutool 等工具库)则是目前的最优解。
希望这篇总结对大家有所帮助!如果你有更好的方案,欢迎在评论区交流。
本文由一名热爱技术的研二学生整理,持续分享 Java 后端与算法学习心得。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-12-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号