【C++】内存管理(上)


一、初识内存管理
内存管理是操作系统(OS)和编程语言运行时核心功能之一,本质是高效、安全地分配、使用、回收计算机内存资源,避免内存泄漏、野指针、内存碎片等问题,确保程序稳定运行且资源利用率最大化。
我们为什么需要内存管理?
一、解决物理限制问题
- 内存稀缺:物理内存有限,但程序需求很大
- 多任务需求:需要同时运行多个程序
二、提供关键功能
- 隔离保护:防止程序互相干扰或攻击
- 地址抽象:让程序以为自己独占整个内存空间
- 内存共享:安全地共享代码库和公共数据
三、提升系统能力
- 扩展内存:虚拟内存让程序能用比物理内存更大的空间
- 效率优化:通过缓存、预取等技术加速访问
- 动态管理:按需分配,避免浪费
一句话总结:内存管理让有限的内存资源能被多个程序安全、高效地共享使用,是现代计算系统能够工作的基础。
二、内存管理的核心维度
2.1、内存划分
我们以进程的角度来进行内存划分:
一、代码段(Text Segment / 常量区) 作用:
- 存储程序的执行代码:机器指令、函数体等
- 包含只读的常量:字符串常量、const修饰的全局变量
特点:
- 只读性:防止程序意外修改自身代码
- 可共享:多个进程可以共享同一份代码副本(如多个实例运行同一程序)
- 大小固定:编译链接后确定,运行时不变
- 位于内存低地址区域
二、数据段(Data Segment / 静态区)
作用:
- 存储全局变量和静态变量
- 初始化的全局变量(全局区)- 未初始化的全局变量(BSS段)- 静态局部变量和静态全局变量特点:
- 生命周期最长:从程序启动到结束一直存在
- 自动初始化:
- 显式初始化的变量:初始值在编译时确定- 未显式初始化的变量:系统自动初始化为0(或NULL)- 位于代码段之上
- 大小在编译时确定
三、堆(Heap)
作用:
- 动态内存分配区域
- 存储
malloc、new、calloc、realloc等分配的内存
特点:
- 动态性:大小在运行时动态变化
- 手动管理:
- 程序员负责申请和释放内存- 可能产生内存泄漏(未释放)或悬空指针- 向上增长:向高地址方向扩展
- 碎片化风险:频繁分配释放可能导致内存碎片
- 分配速度相对较慢:需要寻找合适大小的空闲块
四、栈(Stack)
作用:
- 存储函数调用上下文和局部变量
- 函数参数- 返回地址- 局部变量- 函数调用的寄存器保存区特点:
- 自动管理:编译器自动分配和释放
- 后进先出(LIFO):函数调用和返回符合栈的特性
- 向下增长:向低地址方向扩展
- 速度快:只需移动栈指针即可分配内存
- 大小有限:通常较小(Linux默认8MB),可能发生栈溢出
- 生命周期短:随函数调用开始,随函数返回结束
对比表格
特性 | 栈 | 堆 | 数据段 | 代码段 |
|---|---|---|---|---|
存储内容 | 局部变量、函数参数、返回地址 | 动态分配的内存 | 全局/静态变量 | 程序代码、常量 |
管理方式 | 自动(编译器) | 手动(程序员) | 自动(系统) | 自动(系统) |
生命周期 | 函数调用期间 | 直到显式释放 | 整个程序运行期间 | 整个程序运行期间 |
大小 | 固定且较小 | 动态变化,理论上受限于系统 | 编译时确定 | 编译时确定 |
生长方向 | 向下(低地址) | 向上(高地址) | - | - |
访问速度 | 最快 | 较慢 | 快 | 快 |
线程共享 | 每个线程独立 | 进程内共享 | 进程内共享 | 进程内共享 |
2.2、实际内存布局示例(Linux x86-64)
text
高地址
┌─────────────────┐
│ 内核空间 │
├─────────────────┤
│ 栈 (向下增长) │ ← 栈指针(SP)
│ ... │
├─────────────────┤
│ ... │
├─────────────────┤
│ 堆 (向上增长) │ ← 堆指针(brk)
│ ... │
├─────────────────┤
│ 未初始化数据段(BSS)│
├─────────────────┤
│ 已初始化数据段 │
├─────────────────┤
│ 代码段 │
└─────────────────┘
低地址编程注意事项
- 栈溢出:避免大局部变量或深度递归
- 堆管理:确保配对使用
malloc/free、new/delete - 数据段:过度使用全局变量会增加内存占用
- 代码段:常量字符串在此区域,不可修改
三、C/C++内存分布
我们先来看下面的一段代码和相关问题
int globalVar = 1;
static int staticGlobalVar = 1;
void Test()
{
static int staticVar = 1;
int localVar = 1;
int num1[10] = { 1, 2, 3, 4 };
char char2[] = "abcd";
const char* pChar3 = "abcd";
int* ptr1 = (int*)malloc(sizeof(int) * 4);
int* ptr2 = (int*)calloc(4, sizeof(int));
int* ptr3 = (int*)realloc(ptr2, sizeof(int) * 4);
free(ptr1);
free(ptr3);
}选择题: 选项:A.栈 B.堆 C.数据段(静态区) D.代码段(常量区) globalVar在哪里?____ staticGlobalVar在哪里?____ staticVar在哪里?____ localVar在哪里?____ num1 在哪里?____ 答案:C、C、C、A、A 解析:
我们根据表格可以看出,也可以看下面这个表格:
分区作用特点栈(Stack)存储局部变量、函数调用上下文自动分配 / 释放(栈帧)、连续内存、大小固定(几 MB)堆(Heap)动态分配内存(如 new/malloc)手动 / 自动回收、非连续、大小灵活(可达 GB 级)全局 / 静态区存储全局变量、静态变量程序启动分配、退出释放常量区存储字符串常量、const 变量只读、程序退出释放代码区存储程序指令(二进制)只读、可共享
char2在哪里?____
*char2在哪里?___
pChar3在哪里?____
*pChar3在哪里?____
ptr1在哪里?____
*ptr1在哪里?____
答案:A、A、A、D、A、B
解析:
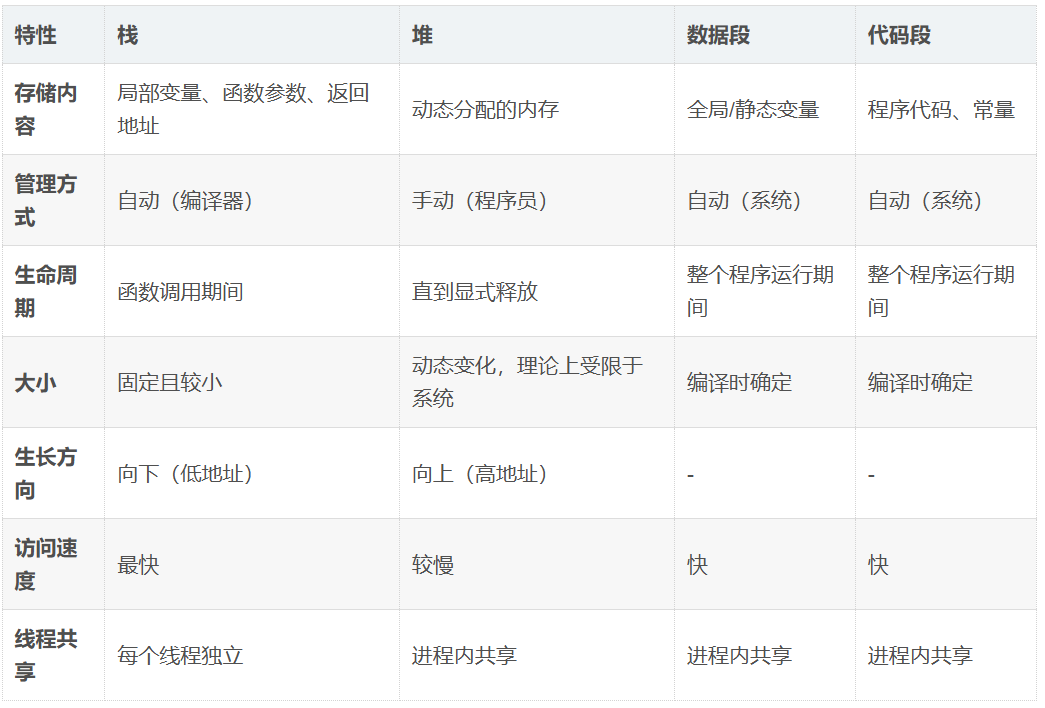
我们首先来看char2,他是一个数组,我们知道数组名代表整个数组那他就是在栈上;pchar3大家可能都觉得他有个const修饰那他应该在常量区,这个const修饰的是指向内容,并不修饰本身,所以他也在栈上;数组名代表整个数组,这里char2解引用就代表首元素的地址解引用(实际就是a),这个数组在栈上,所以解引用也是在栈上;pChar3也在栈上,解引用找他的指向内容,他指向这个常量字符串,这个常量字符串在常量区,所以*pChar也在常量区;我们来总结一下其实就是在常量区有个"abcd\0",我们在栈上定义一个数组char2,我们将常量区的"abcd\0"拷贝一份给他,在栈上再定义一个局部的指针变量,这个局部的指针变量指向这个字符串首元素的地址,当我们解引用就是常量区的"abcd\0"的a,给出图解如下:
常量区的数据不可以修改!
我们在栈上定义了一指针变量ptr1,然后malloc一块空间,指针指向那快空间,然后那块空间在堆区上,所以解引用*ptr1就在堆区上;
ptr1是Test()函数内的局部指针变量,局部变量会存储在栈区(函数调用时分配栈帧,函数结束后自动释放)。ptr1是通过malloc动态分配内存得到的指针,malloc会从堆区申请内存空间;*ptr1是ptr1指向的内存空间,因此存储在堆区(需手动调用free释放)。
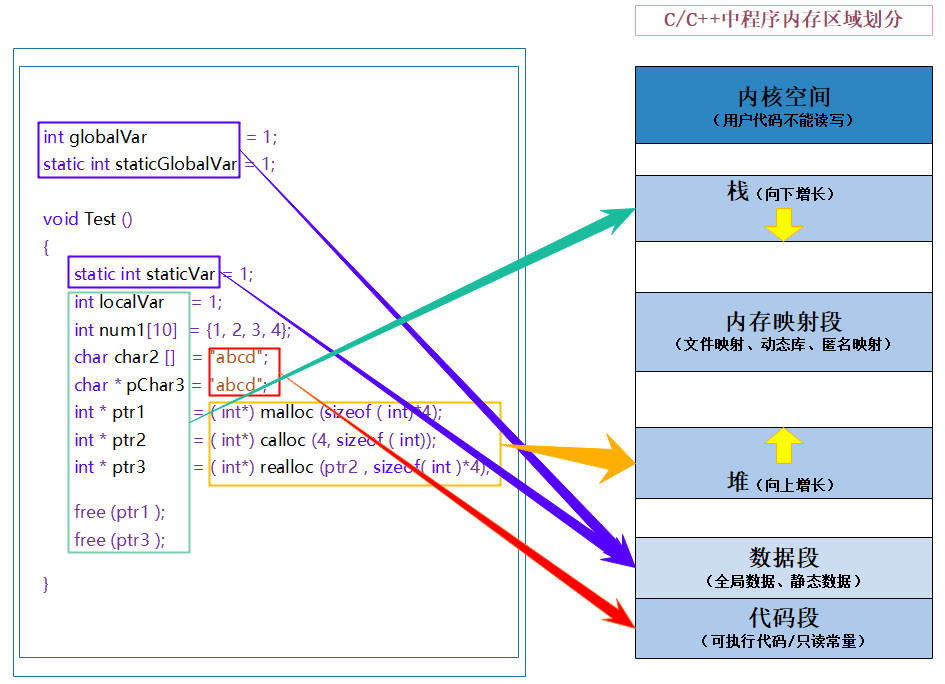
【说明】
- 栈又叫堆栈 -- 非静态局部变量 / 函数参数 / 返回值等等,栈是向下增长的。
- 内存映射段是高效的 I/O 映射方式,用于装载一个共享的动态内存库。用户可使用系统接口创建共享共享内存,做进程间通信。(Linux 课程如果没学到这块,现在只需要了解一下)
- 堆用于程序运行时动态内存分配,堆是可以上增长的。
- 数据段 -- 存储全局数据和静态数据。
- 代码段 -- 可执行的代码 / 只读常量。
四、C语言中动态内存管理方式:malloc / calloc / realloc / free
4.1、malloc / calloc / realloc的区别
大家要是想详细了解可以移步我以前写过的一篇博客:【C语言】C 动态内存管理全解析:malloc/calloc/realloc 与柔性数组实战-CSDN博客

https://blog.csdn.net/2501_91731683/article/details/150438447这里我们简单为大家讲解一下大致的区别:
malloc是动态内存开辟但是不会初始化;calloc是动态内存开辟并且初始化为0;realloc是在原有的动态内存空间上去扩容(如果原有空间后没有足够连续内存,会重新分配一块更大的内存,把原数据拷贝过去,再释放原内存)
void Test()
{
int* p2 = (int*)calloc(4, sizeof(int));
int* p3 = (int*)realloc(p2, sizeof(int) * 10);
cout << p2 << endl;
cout << p3 << endl;
// 这里需要free(p2)吗?
free(p3);
}这里的p2不需要free,这里的realloc可能原地扩容也可能异地扩容,原地扩容他们俩地址是一样的,释放一次就可以了,要是异地扩容也不需要我们去释放p2,因为realloc申请一块新的空间然后进行拷贝原空间,结束后会释放原空间,再把新空间返回给p3。
4.2、malloc的实现原理(了解)
这部分现阶段我们并不做重点去了解,大家要是感兴趣可以自行去学习了解,等我们学的多了再回头来看这些,这里有个b站的视频链接,大家感兴趣可以去学习:
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-01-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号