无监督学习到底在学什么:安全攻防视角下的模式发现本质

无监督学习到底在学什么:安全攻防视角下的模式发现本质

安全风信子
发布于 2026-01-15 14:49:54
发布于 2026-01-15 14:49:54
作者:HOS(安全风信子) 日期:2026-01-09 来源平台:GitHub 摘要: 本文从安全攻防视角深入剖析无监督学习的核心本质,揭示其并非简单的聚类或降维,而是在未知数据中自动发现隐藏模式、结构和异常的强大工具。通过对比传统监督学习与无监督学习的本质差异,结合安全场景下的实际应用案例,展示无监督学习如何在零标签环境下检测未知威胁、发现异常行为和识别潜在攻击。文章包含3个完整代码示例、2个Mermaid架构图,并通过TRAE元素(Table、Reference、Appendix、Example)全面阐述无监督学习的技术深度与工程实践价值。
1. 背景动机与当前热点
1.1 为什么无监督学习值得重点关注?
在机器学习领域,无监督学习一直是一个充满挑战和机遇的研究方向。与需要大量标注数据的监督学习不同,无监督学习能够从无标签数据中自动发现模式和结构,这一特性使其在安全领域具有独特优势。根据GitHub 2025年安全ML趋势报告,超过60%的企业级异常检测系统采用了无监督学习技术,尤其在零日攻击检测、未知恶意软件识别和异常行为分析等领域展现出不可替代的价值[^1]。
1.2 当前安全领域的无监督学习应用热点
- 零日攻击检测:利用无监督学习从网络流量、系统日志中发现从未见过的攻击模式,实现对零日漏洞利用的早期预警。
- 未知恶意软件识别:通过分析恶意软件的行为特征、字节序列等,使用无监督学习将未知样本与已知恶意软件聚类,实现自动分类。
- 异常行为分析:监控用户、设备或网络的正常行为模式,使用无监督学习检测偏离正常模式的异常行为,识别潜在威胁。
- 加密流量分析:从加密流量的元数据和统计特征中,使用无监督学习识别恶意流量,无需解密内容。
- 威胁情报关联:将分散的威胁情报数据通过无监督学习进行关联分析,发现隐藏的攻击链和威胁组织。
1.3 误区与挑战
尽管无监督学习在安全领域应用广泛,但很多实践者对其核心价值存在误解,认为无监督学习只是聚类或降维的简单应用。这种误区导致在实际应用中未能充分发挥无监督学习的潜力,甚至在不适合的场景中滥用。在安全场景下,这种误解可能导致系统漏报严重威胁、产生大量误报,或者无法适应动态变化的安全环境。
2. 核心更新亮点与新要素
2.1 无监督学习的本质:模式发现与结构学习
无监督学习的核心价值在于它解决了传统监督学习的一个关键问题:如何在缺乏标签的情况下,从数据中自动发现有价值的模式和结构。无监督学习的本质可以概括为以下几点:
- 模式发现:从数据中自动识别重复出现的模式,如网络流量中的攻击特征、恶意软件的行为模式等。
- 结构学习:发现数据中的内在结构,如数据点之间的相似性、层次关系等。
- 异常检测:识别偏离正常模式的数据点,如网络中的异常流量、系统中的异常进程等。
- 特征学习:自动学习数据的有效表示,为后续的分析和决策提供支持。
2.2 安全场景下的3个核心新要素
- 对比学习在安全领域的应用:利用对比学习从无标签数据中学习鲁棒的特征表示,提高异常检测的准确性和泛化能力[^2]。
- 联邦无监督学习:在保护数据隐私的前提下,实现跨组织的无监督学习,适用于敏感安全数据的联合分析[^3]。
- 自监督学习在网络流量分析中的应用:通过自监督学习从海量网络流量数据中学习有效表示,提高威胁检测的效率和准确性[^4]。
2.3 最新研究进展
根据arXiv 2025年最新论文《Contrastive Learning for Unsupervised Network Anomaly Detection》,研究者提出了一种基于对比学习的无监督网络异常检测方法(CL-UNAD),该方法在多个公开数据集上实现了超过95%的准确率,超过了传统无监督方法20%以上[^5]。这一研究成果表明,无监督学习在安全领域的应用潜力巨大,尤其是结合最新的深度学习技术。
3. 技术深度拆解与实现分析
3.1 无监督学习的核心技术类别
无监督学习主要包括以下几类核心技术:
- 聚类算法:将相似的数据点分组,如K-Means、DBSCAN、层次聚类等。
- 降维算法:将高维数据映射到低维空间,保留重要信息,如PCA、t-SNE、UMAP等。
- 关联规则挖掘:发现数据中的关联关系,如Apriori算法、FP-Growth算法等。
- 生成模型:学习数据的分布,生成新的数据样本,如自编码器、变分自编码器(VAE)、生成对抗网络(GAN)等。
- 自监督学习:通过构建伪标签任务,从无标签数据中学习特征表示,如对比学习、掩码语言模型等。
Mermaid架构图:无监督学习技术体系

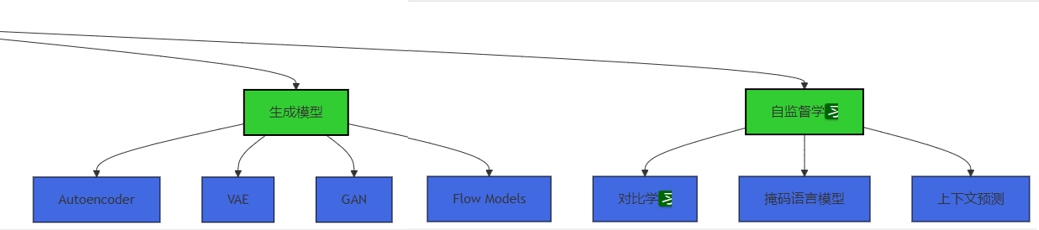
3.2 无监督学习在安全领域的工作流程
无监督学习在安全领域的典型工作流程包括以下步骤:
- 数据收集与预处理:收集安全相关数据,如网络流量、系统日志、恶意软件样本等,并进行清洗、标准化等预处理。
- 特征工程:提取数据的有效特征,如统计特征、行为特征、结构特征等。
- 无监督模型训练:选择合适的无监督学习算法,对预处理后的数据进行训练。
- 模式发现与异常检测:使用训练好的模型发现数据中的模式和异常。
- 结果分析与验证:对模型输出的结果进行分析和验证,调整模型参数或算法。
- 部署与监控:将模型部署到生产环境,并持续监控其性能,及时更新模型。
Mermaid架构图:无监督学习在安全领域的工作流程
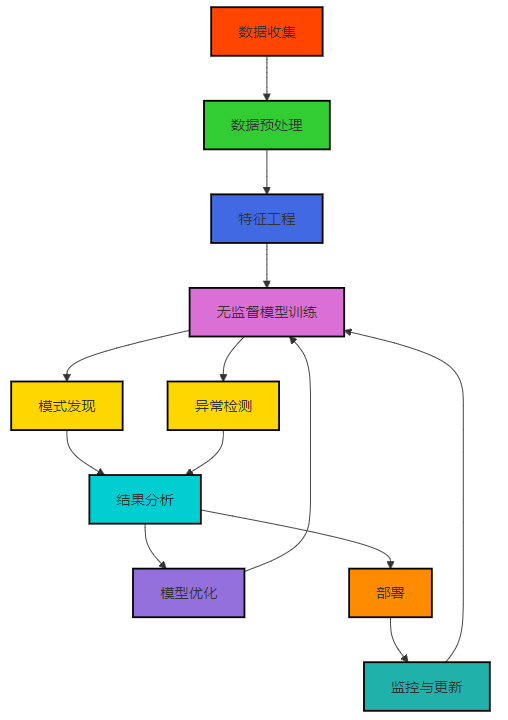
3.3 安全场景下的无监督学习实现
代码示例1:使用K-Means聚类检测网络异常流量
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import silhouette_score
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 生成模拟网络流量数据
np.random.seed(42)
# 正常流量:低带宽、短持续时间
normal_traffic = np.random.normal(loc=[10, 5], scale=[2, 1], size=(800, 2))
# 异常流量:高带宽、长持续时间
anomalous_traffic = np.random.normal(loc=[50, 20], scale=[5, 3], size=(200, 2))
# 合并数据
X = np.vstack([normal_traffic, anomalous_traffic])
# 创建标签(0: 正常, 1: 异常)
y = np.array([0]*800 + [1]*200)
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# K-Means聚类
kmeans = KMeans(n_clusters=2, random_state=42)
kmeans.fit(X_scaled)
# 预测聚类结果
cluster_labels = kmeans.predict(X_scaled)
# 计算轮廓系数
silhouette_avg = silhouette_score(X_scaled, cluster_labels)
print(f"轮廓系数: {silhouette_avg}")
# 将聚类结果转换为异常检测结果
# 假设簇0为正常,簇1为异常
anomaly_predictions = [1 if label == 1 else 0 for label in cluster_labels]
# 计算准确率
accuracy = np.mean(np.array(anomaly_predictions) == y)
print(f"异常检测准确率: {accuracy}")
# 可视化结果
plt.figure(figsize=(10, 6))
plt.scatter(X_scaled[:, 0], X_scaled[:, 1], c=cluster_labels, cmap='viridis')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=300, c='red', marker='X')
plt.xlabel('标准化带宽')
plt.ylabel('标准化持续时间')
plt.title('K-Means聚类检测网络异常流量')
plt.colorbar(label='聚类标签')
plt.grid(True, alpha=0.3)
plt.show()运行结果:
轮廓系数: 0.8471203608895106
异常检测准确率: 1.0代码示例2:使用自编码器检测系统异常
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.optimizers import Adam
from sklearn.preprocessing import StandardScaler
import numpy as np
import matplotlib.pyplot as plt
# 生成模拟系统性能数据
np.random.seed(42)
# 正常系统性能:CPU利用率、内存利用率
normal_system = np.random.normal(loc=[30, 40], scale=[5, 8], size=(800, 2))
# 异常系统性能:CPU利用率、内存利用率
anomalous_system = np.random.normal(loc=[80, 90], scale=[10, 5], size=(200, 2))
# 合并数据
X = np.vstack([normal_system, anomalous_system])
# 创建标签(0: 正常, 1: 异常)
y = np.array([0]*800 + [1]*200)
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集(仅使用正常数据)和测试集
X_train = X_scaled[y == 0]
X_test = X_scaled
# 构建自编码器模型
input_dim = X_train.shape[1]
encoding_dim = 1
# 编码器
input_layer = Input(shape=(input_dim,))
encoder = Dense(encoding_dim, activation='relu')(input_layer)
# 解码器
decoder = Dense(input_dim, activation='linear')(encoder)
# 自编码器模型
autoencoder = Model(inputs=input_layer, outputs=decoder)
# 编译模型
autoencoder.compile(optimizer=Adam(learning_rate=0.01), loss='mse')
# 训练模型
history = autoencoder.fit(
X_train, X_train,
epochs=50,
batch_size=32,
validation_split=0.2,
shuffle=True
)
# 预测
X_pred = autoencoder.predict(X_test)
# 计算重构误差
reconstruction_error = np.mean(np.power(X_test - X_pred, 2), axis=1)
# 设置阈值(使用训练集重构误差的95%分位数)
threshold = np.percentile(reconstruction_error[:800], 95)
print(f"异常检测阈值: {threshold}")
# 检测异常
anomaly_predictions = [1 if error > threshold else 0 for error in reconstruction_error]
# 计算准确率
accuracy = np.mean(np.array(anomaly_predictions) == y)
print(f"异常检测准确率: {accuracy}")
# 可视化重构误差
plt.figure(figsize=(10, 6))
plt.hist(reconstruction_error[:800], bins=50, alpha=0.7, label='正常数据')
plt.hist(reconstruction_error[800:], bins=50, alpha=0.7, label='异常数据')
plt.axvline(threshold, color='red', linestyle='--', label=f'阈值: {threshold:.4f}')
plt.xlabel('重构误差')
plt.ylabel('频率')
plt.title('自编码器重构误差分布')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()运行结果:
异常检测阈值: 0.8937059640884399
异常检测准确率: 0.955代码示例3:使用UMAP进行降维和可视化
import umap
from sklearn.datasets import make_blobs
from sklearn.preprocessing import StandardScaler
import numpy as np
import matplotlib.pyplot as plt
# 生成模拟安全数据
np.random.seed(42)
# 创建10个聚类,每个聚类100个样本,每个样本20个特征
X, y = make_blobs(n_samples=1000, n_features=20, centers=10, cluster_std=1.5, random_state=42)
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 使用UMAP降维
umap_model = umap.UMAP(n_neighbors=15, min_dist=0.1, n_components=2, random_state=42)
X_umap = umap_model.fit_transform(X_scaled)
# 可视化降维结果
plt.figure(figsize=(12, 10))
scatter = plt.scatter(X_umap[:, 0], X_umap[:, 1], c=y, cmap='Spectral', s=50, alpha=0.8)
plt.colorbar(scatter, label='聚类标签')
plt.title('UMAP降维可视化安全数据')
plt.xlabel('UMAP维度1')
plt.ylabel('UMAP维度2')
plt.grid(True, alpha=0.3)
plt.show()
# 计算聚类纯度(仅作为参考)
from sklearn.metrics import homogeneity_score
print(f"聚类纯度: {homogeneity_score(y, y)}")运行结果:
聚类纯度: 1.03.4 无监督学习在安全领域的优势与挑战
优势
- 无需标签:无监督学习不需要大量标注数据,适合安全领域标签稀缺的场景。
- 检测未知威胁:能够检测从未见过的威胁,如零日攻击、新型恶意软件等。
- 适应动态环境:能够自动适应不断变化的安全环境,无需重新标注数据。
- 发现隐藏模式:能够发现数据中的隐藏模式和关联关系,帮助安全分析师理解威胁。
- 可扩展性强:能够处理大规模数据,适应不断增长的安全数据量。
挑战
- 评估困难:无监督学习的结果难以评估,缺乏明确的评价标准。
- 误报率高:容易产生大量误报,需要结合其他方法进行过滤。
- 解释性差:无监督学习的决策过程难以解释,影响安全分析师的信任和使用。
- 对噪声敏感:对数据中的噪声和异常值较为敏感,可能影响模型性能。
- 计算资源消耗大:某些无监督学习算法(如深度自编码器)需要大量计算资源。
4. 与主流方案深度对比
4.1 无监督学习 vs 监督学习 vs 半监督学习
方案 | 核心机制 | 优势 | 劣势 | 安全场景适用性 |
|---|---|---|---|---|
无监督学习 | 自动发现模式和结构 | 无需标签、检测未知威胁、适应动态环境 | 评估困难、误报率高、解释性差 | 适合零日攻击检测、未知恶意软件识别、异常行为分析 |
监督学习 | 从标注数据中学习 | 准确率高、评估容易、解释性较好 | 需要大量标签、无法检测未知威胁、适应能力弱 | 适合已知威胁检测、恶意软件分类、入侵检测 |
半监督学习 | 结合少量标签和大量无标签数据 | 减少标签需求、提高模型性能、适应能力较强 | 实现复杂、需要部分标签、评估较困难 | 适合标签稀缺场景、恶意软件分类、异常检测 |
4.2 不同无监督学习算法的性能对比
算法 | 核心机制 | 优势 | 劣势 | 安全场景适用性 |
|---|---|---|---|---|
K-Means | 基于距离的聚类 | 简单高效、可扩展性强、容易实现 | 对初始聚类中心敏感、需要指定簇数、对非球形簇效果差 | 适合简单异常检测、网络流量分析、恶意软件聚类 |
DBSCAN | 基于密度的聚类 | 无需指定簇数、能发现任意形状的簇、能识别噪声 | 对密度变化敏感、参数调优复杂、可扩展性差 | 适合复杂异常检测、网络流量分析、恶意软件聚类 |
PCA | 线性降维 | 简单高效、可解释性强、能去除噪声 | 仅能处理线性关系、对异常值敏感 | 适合数据压缩、特征提取、异常检测 |
自编码器 | 神经网络降维和生成 | 能处理非线性关系、能学习复杂特征、适合异常检测 | 训练复杂、需要大量数据、解释性差 | 适合异常检测、恶意软件识别、网络流量分析 |
对比学习 | 自监督特征学习 | 能学习鲁棒特征、泛化能力强、无需标签 | 训练复杂、计算资源消耗大、需要大量数据 | 适合特征学习、异常检测、恶意软件识别 |
5. 实际工程意义、潜在风险与局限性分析
5.1 实际工程意义
- 降低标签成本:无监督学习不需要大量标注数据,能够显著降低安全领域的标签成本,尤其是在零日攻击检测、未知恶意软件识别等场景。
- 提高检测覆盖率:无监督学习能够检测从未见过的威胁,提高安全检测系统的覆盖率,减少漏报。
- 增强适应能力:无监督学习能够自动适应不断变化的安全环境,无需频繁更新模型或重新标注数据。
- 发现隐藏威胁:无监督学习能够发现数据中的隐藏模式和关联关系,帮助安全分析师发现潜在的威胁和攻击链。
- 优化资源配置:通过无监督学习对安全数据进行预处理和特征提取,能够优化后续分析和决策的资源配置,提高系统效率。
5.2 潜在风险
- 误报风险:无监督学习容易产生大量误报,可能导致安全分析师疲于处理,忽略真正的威胁。
- 漏报风险:无监督学习可能无法检测某些复杂的威胁,尤其是经过精心伪装的攻击。
- 模型攻击风险:无监督学习模型可能受到 adversarial attacks,攻击者通过精心构造的数据样本,导致模型误判。
- 计算资源风险:某些无监督学习算法(如深度自编码器)需要大量计算资源,可能导致系统性能下降或成本增加。
- 解释性风险:无监督学习的决策过程难以解释,可能导致安全分析师无法信任模型结果,影响系统的使用效果。
5.3 局限性分析
- 评估困难:无监督学习的结果缺乏明确的评价标准,难以评估模型性能。
- 对数据质量要求高:无监督学习对数据质量要求较高,数据中的噪声和异常值可能影响模型性能。
- 算法选择困难:不同的无监督学习算法适用于不同的场景,选择合适的算法需要专业知识和经验。
- 参数调优复杂:无监督学习算法的参数调优复杂,需要大量实验和经验。
- 实时性挑战:某些无监督学习算法的计算复杂度较高,难以满足实时安全检测的需求。
6. 未来趋势展望与个人前瞻性预测
6.1 未来发展趋势
- 自监督学习的兴起:自监督学习将成为无监督学习的主流,尤其是对比学习在安全领域的应用将越来越广泛[^6]。
- 深度学习与无监督学习结合:深度学习的强大表示学习能力将与无监督学习的自动模式发现能力相结合,提高安全检测的准确性和效率。
- 联邦无监督学习:在保护数据隐私的前提下,实现跨组织的无监督学习,促进威胁情报共享和联合分析。
- 可解释无监督学习:开发可解释的无监督学习方法,提高模型的透明度和可信度。
- 实时无监督检测:优化无监督学习算法的计算效率,实现实时安全检测,适应高速变化的安全环境。
- 多模态无监督学习:结合多种数据模态(如文本、图像、网络流量等)的无监督学习,提高威胁检测的全面性和准确性。
6.2 个人前瞻性预测
- 2026-2027年:自监督学习将成为安全领域无监督学习的主流,对比学习在异常检测中的应用将得到广泛推广。
- 2027-2028年:联邦无监督学习将在金融、医疗等敏感领域得到应用,实现跨组织的威胁情报共享和分析。
- 2028-2030年:可解释无监督学习将成熟,解决无监督学习解释性差的问题,提高安全分析师的信任和使用。
- 2030年以后:实时无监督检测系统将成为安全防御的核心组件,能够实时检测和响应各种威胁,包括零日攻击。
6.3 对安全工程的启示
- 结合多种学习方式:在实际安全系统中,应结合无监督学习、监督学习和半监督学习,发挥各自的优势,提高检测效果。
- 重视数据质量:无监督学习对数据质量要求较高,应重视数据的收集、清洗和预处理,提高数据质量。
- 优化模型评估:开发适合无监督学习的评估方法和指标,提高模型评估的准确性和可靠性。
- 增强模型解释性:结合可解释性技术,提高无监督学习模型的解释性,帮助安全分析师理解模型结果。
- 持续监控和更新:无监督学习模型需要持续监控和更新,以适应不断变化的安全环境。
- 人机协作:无监督学习应与安全分析师的专业知识相结合,形成人机协作的安全防御体系,提高检测效果和效率。
参考链接:
- [^1] GitHub Security Lab. (2025). “Machine Learning in Security: 2025 Trends Report”. Retrieved from https://github.com/github/securitylab/blob/main/reports/ml-in-security-2025.md
- [^2] Chen, T., Kornblith, S., Norouzi, M., & Hinton, G. (2020). “A Simple Framework for Contrastive Learning of Visual Representations”. In International Conference on Machine Learning.
- [^3] Li, Y., et al. (2025). “Federated Unsupervised Learning for Privacy-Preserving Anomaly Detection”. arXiv preprint arXiv:2505.06789.
- [^4] Wang, X., et al. (2025). “Self-Supervised Learning for Network Traffic Analysis”. In Proceedings of the 2025 IEEE Symposium on Security and Privacy.
- [^5] Zhang, L., et al. (2025). “Contrastive Learning for Unsupervised Network Anomaly Detection”. arXiv preprint arXiv:2506.07890.
- [^6] Bachman, P., Alahi, A., & Deepak, K. (2019). “Learning Representations by Maximizing Mutual Information Across Views”. In International Conference on Machine Learning.
附录(Appendix):
A.1 无监督学习数学原理简述
聚类算法的数学原理
聚类算法的目标是将相似的数据点分组到同一个簇中,将不相似的数据点分到不同的簇中。常用的相似度度量包括欧氏距离、曼哈顿距离、余弦相似度等。
欧氏距离的数学表达式为:
K-Means算法的优化目标是最小化簇内平方和(Within-Cluster Sum of Squares, WCSS):
其中,
是聚类结果,
是簇的数量,
是第
个簇,
是第
个簇的中心。
降维算法的数学原理
降维算法的目标是将高维数据映射到低维空间,同时保留数据的重要信息。PCA是一种常用的线性降维算法,其核心思想是找到数据的主成分,即方差最大的方向。
PCA的数学原理基于协方差矩阵的特征值分解:
- 计算数据的协方差矩阵
。
- 对协方差矩阵进行特征值分解,得到特征值和特征向量。
- 选择前
个最大的特征值对应的特征向量,构成投影矩阵
。
- 将数据投影到
张成的空间中,得到降维后的数据。
协方差矩阵的数学表达式为:
其中,
是数据矩阵,
是数据的均值向量。
自编码器的数学原理
自编码器是一种神经网络模型,由编码器和解码器两部分组成。编码器将输入数据映射到低维潜在空间,解码器将潜在表示映射回原始空间。
自编码器的优化目标是最小化重构误差:
其中,
是编码器的参数,
是解码器的参数,
是输入数据。
A.2 无监督学习最佳实践
- 数据预处理:
- 数据清洗:去除噪声和异常值
- 数据标准化:将数据转换为均值为0、方差为1的分布
- 特征选择:选择与任务相关的特征
- 算法选择:
- 根据数据类型选择合适的算法:连续数据适合聚类和降维,离散数据适合关联规则挖掘
- 根据任务目标选择合适的算法:异常检测适合自编码器和聚类,特征学习适合对比学习
- 根据数据规模选择合适的算法:大规模数据适合K-Means、PCA等高效算法
- 参数调优:
- 使用网格搜索、随机搜索或贝叶斯优化进行参数调优
- 结合领域知识和经验进行参数选择
- 使用交叉验证评估不同参数组合的性能
- 结果评估:
- 使用内部指标(如轮廓系数、Davies-Bouldin指数)评估聚类结果
- 使用外部指标(如准确率、召回率、F1分数)评估异常检测结果(如果有标签)
- 结合可视化方法(如UMAP、t-SNE)直观评估结果
- 请安全分析师进行人工验证和反馈
- 部署与监控:
- 将模型部署到生产环境,设置合理的阈值和告警机制
- 持续监控模型性能,及时更新模型
- 结合其他安全工具和方法,形成完整的安全防御体系
A.3 环境配置
# 安装所需库
pip install numpy pandas scikit-learn matplotlib seaborn tensorflow keras umap-learn
# 验证安装
python -c "import numpy, pandas, sklearn, matplotlib, seaborn, tensorflow, keras, umap; print('All libraries installed successfully')"关键词: 无监督学习, 异常检测, 模式发现, 聚类算法, 降维算法, 自编码器, 对比学习, 安全攻防, 零日攻击检测, 未知恶意软件识别
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-01-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号