pod丢包了,你会怎么查?

pod丢包了,你会怎么查?

SRE运维进阶之路
发布于 2026-03-16 16:39:48
发布于 2026-03-16 16:39:48
起因
CAT 发生红盘, 排查问题 查看容器速查大盘,发现某个 Pod 发生丢包。
故障现象
某个 Pod 发生丢包
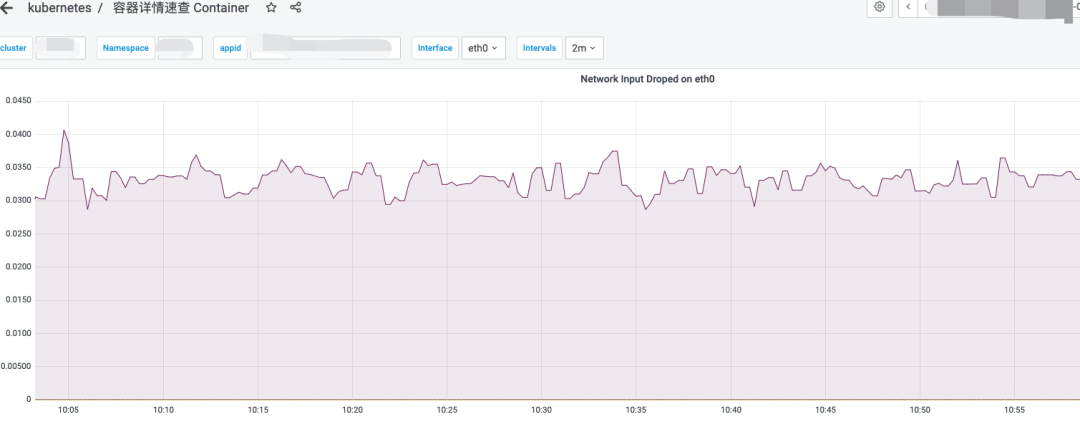
根因定位
1)确定影响面
a) 哪些 Pod 发生丢包, 单个 or 多个 Pod/Node/Cluster , 分布规律: 发现丢包的 Pod ,集中在某个 Node 上面
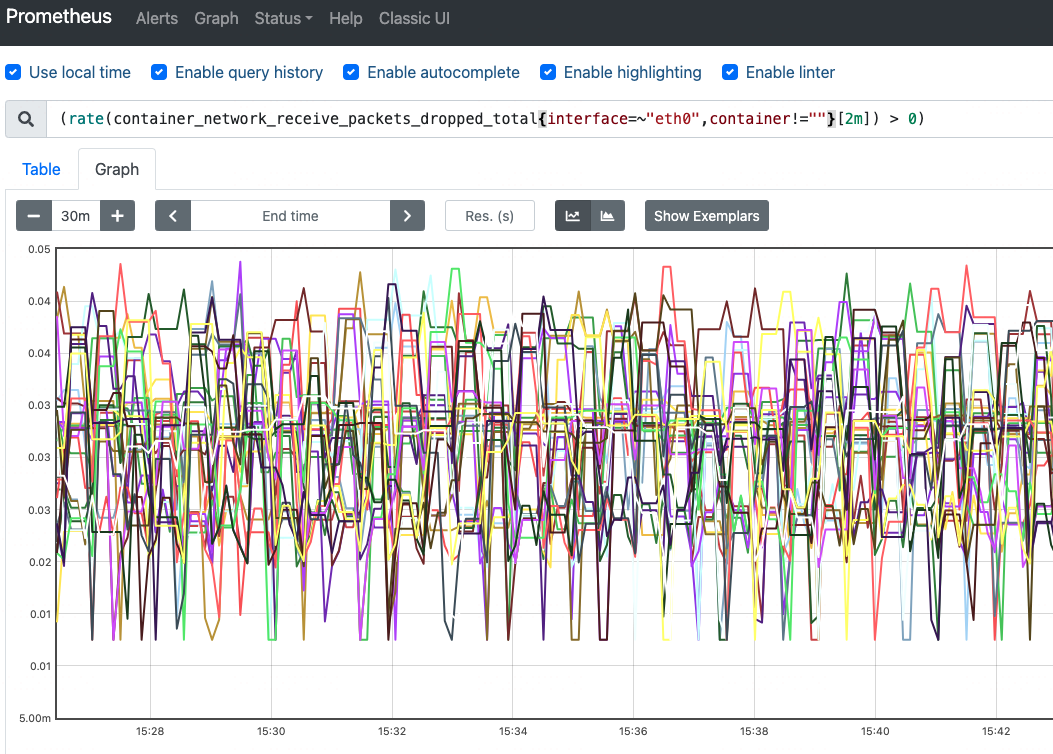
b)丢包的 Pod 上面业务是否受到影响:该 Node 上的 Pod 丢包已经持续了很久,没有业务反馈受到影响,本次红盘与 Pod 丢包无关
2)找共性
- • 摘掉业务流量观察: 丢包未减少
- • 关掉就绪/存活探针观察:丢包未减少
- • 丢包不随业务访问流量变化
3)实时观察,丢包频率
Pod 内执行,发现丢包每30s 加1
watch -n 1 cat /sys/class/net/eth0/statistics/rx_dropped
# 相同的观察丢包的命令
ifconfig eth0 | grep drop
cat /proc/net/dev
netstat -i本环境 CNI 插件为 calico, 找到 Pod eth0 对应宿主机上的 veth pair
方法一:
# pod 内执行,查询 eth0 的对端 index
cat /sys/class/net/eth0/iflink# 宿主机执行,根据 index 号查询 veth pair
ip a | grep ${index}方法二:
# 宿主机执行
route -n | grep ${pod_ip}宿主机,执行相同的丢包查询命令, 网卡名称换一下, 发现 califxxx 没有发生丢包
4)抓包
# 宿主机 tcpdump 抓包, 然后 wireshark 分析
tcpdump -i calif33e3f0e409 -nn -w /tmp/container.pcap根据之前发现的规律 "Pod 内丢包每30s 加1" 进行排查,发现 lldp 探测很可疑

针对 lldpd 协议继续抓包, 观察 丢包时间是否吻合, 确认吻合,找到问题
tcpdump -i calif33e3f0e409 ether proto 0x88cc -vv5)补充印证
排查问题常规命令, dmesg -T 、vim /var/log/messages、history
history 命令排查到,有安装过 lldpd 并启动了,后续巡检发现,仅故障主机安装过 lldpd
解决方案
容器环境用不到 lldpd, 关闭即可
systemctl stop lldpd后续TODO
- • 加 Pod 丢包监控
- • 可选: lldpd 状态监控, 新增巡检项, 堡垒机 拦击 安装 lldpd 的命令等。
其他碎碎念
1) 其实 关不关 lldpd 并不影响应用,lldp 是一个二层的协议。
2)使用 dropwatch 没分析出来, rpm 安装的内核(5.4.xx),addr2line 和 /proc/kallsyms 解析不到函数
3)还是 centos7 和 5.4 的内核, systemtap 依赖的 kernel-debuginfo 没有下载包,无法进一步排查
4)一样, bpftrace 也是, yum 安装不了, 安装很繁琐,最后 docker 起了个 ubuntu privileged 封装了个,使用起来也有些问题, dog:下次还是用 Ubuntu 22.04.4 LTS 吧
5)很怪异, tcpdump 在 Pod 里面抓包时, drop 不再增加
下期预告:Nginx 虚拟机被意外重启, 内存耗尽,如何排查?
我是 Clay,下期见~
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-05-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号