出码率90%却没提效?AI研发的真正瓶颈与 Harness + SDD 实战解法

出码率90%却没提效?AI研发的真正瓶颈与 Harness + SDD 实战解法

老周聊架构
发布于 2026-05-15 10:33:54
发布于 2026-05-15 10:33:54
出码率翻倍,提效却没跟上——这个反直觉的现象背后,藏着 AI 研发的真正瓶颈。
今天这篇文章,老周会从这个问题出发,拆解三个深层原因,然后给出一个经过实战验证的解法:SDD(规范驱动开发)+ Harness(驾驭工程),以及如何用它们将 AI 出码率从不到 25% 拉升到 90%+,同时实现真正的全链路提效。
瓶颈一:出码率 ≠ 交付率
先看一张图——AI 研发提效面临的三大瓶颈:

一个需求从提出到上线的完整链路中,编码只占整个链路的 20%-30%。 你把编码环节的 AI 渗透率从 0% 拉到 90%,整体提效也不过 18%-27%。更糟糕的是,AI 生成的代码可能带来更多的 Review 时间、更多的调试时间、更多的返工时间。
这不是假设。高德大模型应用平台的团队在 2025 年 9 月云栖大会上分享过一组数据:出码率从 53% 提升到 80%-90%,但项目交付周期没有明显缩短。编码快了,但 Review 慢了;出码多了,但返工也多了。
真正的提效,必须打通全链路,而不仅仅是优化编码这一个环节。
瓶颈二:Vibe Coding 在存量应用中是定时炸弹
什么是 Vibe Coding?就是"氛围编程"——随口给 AI 几句提示词,让它几秒钟生成几千行代码。这种方式在新项目、小脚本上可能还行,但在存量应用中,风险极高。
存量应用有什么特点?它有历史包袱,有隐式依赖,有业务知识沉淀在代码里。你让 AI 去"氛围编程",它可能给你生成一个看起来完美、但和现有系统完全不兼容的方案。更可怕的是,这些问题可能在上线后才暴露。
真实案例:AI 生成的代码修改了一个核心接口的参数顺序,单元测试全过了,但上线后导致三个下游服务报错。排查了整整一天。
为什么?因为 AI 不知道某条链路是高频变更区,不知道某个全局配置类在项目中有近百处引用,不知道价格字段必须用 long 类型且单位为分——这些隐性知识(Tacit Knowledge) 散落在团队成员的经验中、群聊的历史消息中、未入库的会议纪要中。
OpenAI 在百万行代码实践中总结过一句话:
Agent 的知识边界等于代码库的文件边界。 如果某条架构约定不在代码库中以机器可读的形式存在,对 Agent 来说它就不存在。
瓶颈三:大任务超出单次 AI 对话的能力边界
涉及前后端十几个模块的重构任务,你不可能在一个对话里完成。AI 的上下文窗口有限,注意力也会分散。任务太大,AI 就会顾此失彼——开头说的架构要求,到后面就消失了。
Anthropic 在其工程博客中系统总结了 Agent 在复杂项目中的四种典型失败模式:
Failure Mode 1:One-shot Syndrome(试图一步到位)。 Agent 拿到复杂需求后,倾向于在单个上下文窗口内完成全部工作。上下文消耗大半后,开始出现幻觉、循环输出、格式错误的 Tool Call。Anthropic 的经验数据表明,上下文窗口填充率超过 40% 时,输出质量快速衰退。
Failure Mode 2:Premature Victory Declaration(过早宣布胜利)。 Agent 完成部分工作就宣布任务结束,实际上编译都无法通过。
Failure Mode 3:Premature Feature Completion(过早标记功能完成)。 Agent 认为功能已实现但未做端到端测试验证,部署后才发现关键路径不通。
Failure Mode 4:Cold Start Problem(环境启动困难)。 多次会话间缺乏持久化记忆,每次新会话需花大量 Token 重新理解项目结构,真正用于编码的 Token Budget 被严重挤压。
这四种失败模式的共同根源:Agent 缺乏外部的结构化约束和反馈机制。 Agent 存在一个根本性缺陷——它们无法准确评估自身产出的质量。
解法:SDD + Harness 双轮驱动
三个瓶颈指向同一个结论:AI 编程要从"个人技能"升级为"团队级工程能力",要从"氛围编程"进化为"规范驱动、工程治理"的研发范式。
答案就是 SDD + Harness:
- SDD(Specification-Driven Development,规范驱动开发) 解决"做什么"——在 AI 写代码之前,先将人类模糊的想法转化为清晰、无歧义的结构化规范
- Harness Engineering(驾驭工程) 解决"如何可控地做"——为 AI 设计一整套约束、验证、反馈、纠错系统
SDD:规范即代码
SDD 的核心思想是颠覆性的:规范不再是写给人类看的散文,而是结构化的、可被 AI Agent 精确理解和执行的"意图代码"。
传统开发中,PRD 或设计文档只是"指导书",代码才是唯一的"真理之源"。文档很快过期、与代码脱节。SDD 颠覆了这个结构:规范成了唯一的真实来源。 当需求变更时,开发者首先修改的是"规范",随后由 AI 工具根据规范重新生成、验证并更新底层代码。
SDD 的工作流包含四个阶段:
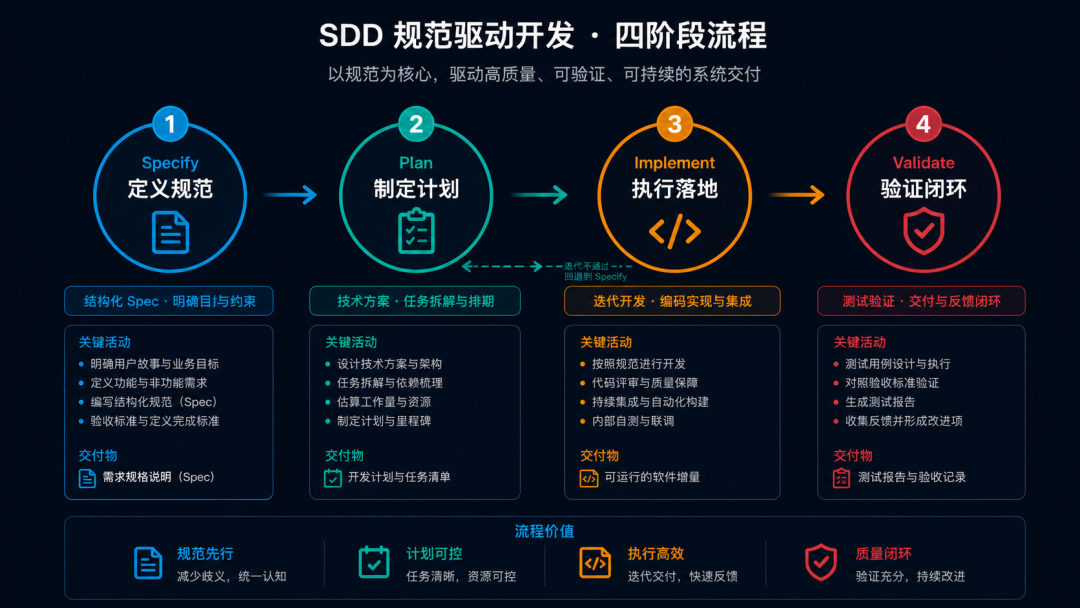
验收标准是 SDD 的灵魂。 它必须是可测试的、无歧义的。比如"用户登录成功后跳转到首页"是模糊描述,而"用户登录成功后,3 秒内跳转到首页,并在首页显示用户昵称"才是可测试的验收标准。
Harness:为野马设计缰绳
如果说 SDD 解决的是"做什么",Harness 解决的就是"如何可控地做"。
一个成熟的 Harness 系统包含四个核心支柱:

支柱一:上下文架构(Context Architecture)。 Agent 应当恰好获得当前任务所需的上下文——不多不少。OpenAI 团队早期犯过一个典型错误:将 AGENTS.md 写成了百科全书,结果"所有内容都重要 = 没有内容重要"。后来他们改为将 AGENTS.md 控制在 ~100 行,作为索引和地图,指向更深层的 Design Docs 和 Architecture Specs。上下文分层加载、按需获取,是 Harness 性能的基石。
支柱二:Agent 专业化(Agent Specialization)。 拥有受限工具集的专业 Agent,优于拥有全部权限的通用 Agent。Anthropic 明确分离了三种角色:Planner 负责规划、Generator 负责实现、Evaluator 负责验证。核心发现:"将做事的 Agent 和评判的 Agent 分开,是一个强有力的杠杆。"
支柱三:持久化记忆(Persistent Memory)。 进度持久化在文件系统上,而非上下文窗口中。标准化启动序列:检查当前工作目录 → 读取 Git Log 和进度文件 → 定位优先级最高的未完成任务 → 开始工作。这使得跨越数十个会话的长时间任务成为可能。
支柱四:结构化执行(Structured Execution)。 永远不让 Agent 在未经审查和批准书面计划之前写代码。理想执行流:理解 → 规划 → 执行 → 验证,每个阶段之间有明确的质量门禁。
实战:从 25% 到 90% 的完整 Harness 体系
下面是重点——如何在一个真实的企业级 Java 应用(代码量 10 万+行,技术栈:Java 1.8 / Spring Boot / LiteFlow / HSF / Diamond / Tair)中,从零构建起完整的 Harness 体系。
整体架构:.harness/ 目录
.harness/
├── agents/ # Agent 角色定义(应用 Owner)
├── rules/ # 规则体系
│ ├── 工程结构.md # 分层架构约束
│ ├── 开发流程规范.md # 10 阶段流程定义
│ └── 项目编码规范.md # 硬性编码约束
├── skills/ # 技能体系(9 个 Skill)
│ ├── request-analysis/ # 需求分析
│ ├── coding-skill/ # 编码实现(含 8 份分层 Spec)
│ ├── expert-reviewer/ # 专家评审
│ ├── unit-test-write/ # 单元测试编写
│ ├── unit-test-ci/ # CI 流水线验证
│ ├── deploy-verify/ # 部署验证
│ ├── code-review/ # 代码检查
│ ├── project-analysis/ # 项目分析
│ └── aone-ci-generate/ # CI 配置生成
├── changes/ # 变更管理目录(完整 Audit Trail)
├── mcp/ # 外部工具集成配置
└── (wiki/ 位于项目根目录) # 知识库这不是随意堆砌的目录结构。四要素各有明确职责: Rules 告诉 Agent"标准是什么",Skills 告诉 Agent"应该怎么做",Wiki 告诉 Agent"系统是什么样的",Changes 记录 Agent"做了什么"。
Agent 定义:把资深开发者的决策逻辑编码化
Application Owner Agent 是整套体系的编排中枢。它的定义文件约 420 行,承担着"Index & Map"的职责——不是百科全书,而是一张精心设计的地图。
五个核心模块:
模块一:角色与项目背景。 明确 Agent 的身份定位和项目核心背景信息。控制在 20-30 行以内,提供"刚好够用"的项目视野。
模块二:配置中枢索引。 用结构化表格列出 Rules、Skills、Wiki、MCP 四大组件的路径、职责、触发场景。Agent 通过这张索引表,能在任意阶段快速定位到需要加载的知识。
模块三:七项核心职责。 需求理解与澄清、任务拆解、任务分发与协调、任务验收、质量把关、文档管理、知识问答——每项职责都附带具体的行为准则。
模块四:工作流程调度指令。 定义 10 阶段流程中每个阶段的完整调度逻辑,包括:触发条件、Skill 加载指令、产出物路径、质量门禁条件、失败回退路径。
模块五:沟通原则与硬性约束。 "必须做到"和"禁止做的"两张清单定义行为边界。
上下文分层:Just-enough Context

这种分层策略的核心:让 Agent 在任何时刻都拥有"刚好够用"的上下文。对于中间件繁多的企业级应用尤其关键——如果把 RPC 规范、流程引擎组件写法、配置中心规范全部一次性塞给 Agent,信息过载反而会导致注意力分散和幻觉。
十阶段流水线:结构化执行的核心
这是整套 Harness 体系最重要的设计:
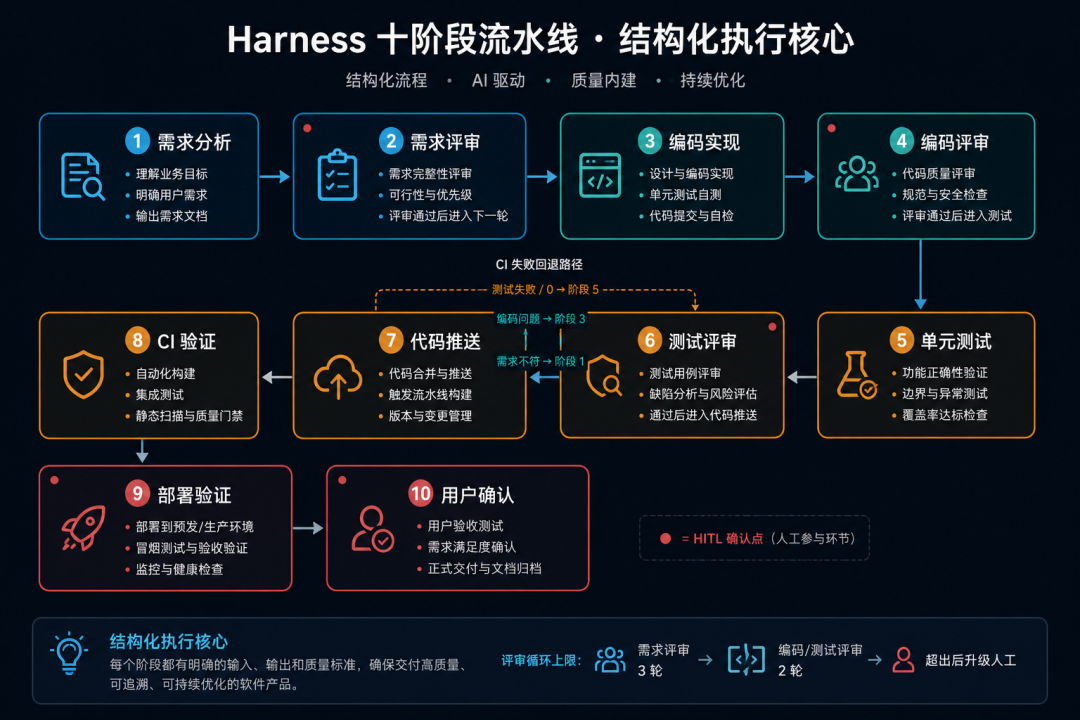
每个阶段都有三要素:触发条件、Skill 加载、质量门禁。 阶段间有精确的回退路径(Rollback Routes):CI 失败时,测试 0/0 回退到阶段 5(测试编写),编译错误回退到阶段 3(编码实现),需求不符回退到阶段 1(需求分析)。
评审环节设置了循环上限(Iteration Cap):需求评审最多 3 轮,编码/测试评审最多 2 轮,超出后升级到人工决策。这防止了 Agent 陷入无限自我修改循环。
流程中嵌入了 5 个 Human-in-the-Loop 确认点:需求待决议确认、计划评审后确认、编码评审后确认、部署环境参数确认、最终交付确认。
Skill 体系:隐性知识的显性化
以 coding-skill 为例,内含 8 份分层编码规范:
层级 | 规范文件 | 核心内容 |
|---|---|---|
表现层 | Controller 实现 Spec | RPC Provider 实现模式、参数校验、异常处理 |
应用层 | 接口定义/实现 Spec | RPC 接口定义规范、DTO 设计原则 |
业务层 | 业务逻辑 Spec | 核心业务逻辑封装、流程编排组件写法 |
数据层 | 建表/持久化 Spec | DDL 设计规范、Mapper 编写方式 |
适配层 | 服务依赖 Spec | 外部 RPC 调用超时设置、降级方案 |
文档层 | 接口文档生成 Spec | 对外接口的协议文档模板 |
Agent 在编码时不是"凭感觉"写,而是按照明确的规范一层一层地实现。硬性约束包括:价格字段必须用 long 类型(单位为分),禁止 double/float;外部服务调用必须设置超时和降级;流程编排组件必须委托 Service 处理。
变更管理:完整的 Audit Trail
每个需求在 .harness/changes/ 下创建独立目录:
{变更类型}-{需求名称}-{YYYYMMDD}/
├── summary.md # 全流程追溯摘要(一页纸总结)
├── request_analysis/
│ ├── spec.md # 需求分析文档
│ ├── tasks.md # 任务拆分清单
│ └── review/ # 需求评审记录(版本递增保留)
├── coding/
│ ├── coding_report_v1.md # 编码报告(版本递增)
│ └── review/
│ └── code_review_v1.md # 代码评审报告
├── unit_test/ # 单元测试报告及评审
├── ci_result/ # CI 验证结果
└── deployment/ # 部署验证报告summary.md 是整个变更的 Single Source of Truth。评审文件采用版本递增策略(v1, v2, v3...),旧版本永远不删,确保完整追溯链。
五条关键经验
1. Harness 本身需要 Dry Run
在拿真实需求使用 Harness 之前,应当用一个虚拟需求完整走一遍全流程。空跑中发现了四个关键缺陷:CI 门禁只检查状态码而忽略测试用例数为 0 的异常;评审报告在简单需求下不生成文件;摘要文件因 Agent 的"追加"倾向出现重复行;部署参数被 Agent 错误推测。
不要期望第一版 Harness 就是完美的,用低成本的方式快速验证、快速修复。
2. 质量门禁必须可程序化验证
"If it can't be mechanically enforced, the agent will drift."
"检查 CI 是否通过"这种自然语言描述不够——Agent 可能认为状态 SUCCESS 即通过,却忽略测试用例数为 0 的异常。将门禁改为三个可程序化验证的条件:
status == SUCCESS && total_tests > 0 && passed == total一切不可被机器验证的约束,在 Agent 执行中都是无效约束。
3. 分离执行与评判是关键杠杆
编码 Agent 和评审 Agent 的分离带来了显著的质量收益——评审 Agent 发现了编码 Agent 遗漏的渠道判断逻辑(一个潜在的线上故障),还在另一个需求中检测到 Agent 试图跳过评审阶段并强制回退。
评审 Agent 不需要"更聪明",它只需要用一套不同的检查视角来审视产出物。
4. 流程一致性优先于流程效率
在一个仅涉及 2 个文件、6 行代码的小需求中,依然走完了完整的 10 阶段流程——1 轮评审即通过,过程非常流畅。好的流程不应该给简单任务增加显著负担。 保持流程一致性是一种廉价的保险。
5. 规范是活文档,需要持续迭代
规范的每一行都对应一个历史失败案例。当你觉得某条规则"多余"或"啰嗦"时,那往往是因为它背后有一个真实踩过的坑。这与 Mitchell Hashimoto 的定义完全一致:每发现一个错误,就工程化地消除它再次发生的可能性。
数据:从 25% 到 90% 的跃迁
3 月基线(Harness 引入前):项目维度 AI 行占比 24.86%,个人维度 14.24%。4 月实测(Harness 运转成熟后):项目维度跃升至 90.54%,个人维度 87.85%。
需要强调:高 AI 代码率本身不是目标——在质量可控前提下的高 AI 代码率才有意义。 这 90% 的 AI 代码经过了完整的需求分析、编码评审、单元测试和 CI 验证流程,每一行都通过了 Harness 体系的质量门禁。
更深层收益:Harness 体系最显著的效率提升不是来自"Agent 写代码更快了",而是来自"返工大幅减少"和"交付质量可预期"。以往裸用 Agent 后人工 Review 发现问题、要求返工的循环可能迭代 3-5 轮;有了 Harness 后,Agent-to-Agent 的评审闭环在内部就完成了大部分质量纠偏,到人工确认时通常只需要 1 轮。
知识库设计:三层结构 + 按需加载
知识库是整个体系的地基,按三层结构组织:

关键设计:维护一个顶层 README.md 文件作为单一事实来源——如果某个信息不在文档里,对 Agent 来说它就不存在。通过分层索引机制,既保证知识的结构化组织,又实现按需加载的灵活性。
同时引入 Memory 体系——解决 AI 的"上下文焦虑"问题。在长周期项目开发中,AI 需要记住之前的决策、当前进度、待办事项。Memory 提供了结构化的存储和管理方式,让 AI 可以在正确的上下文中做出正确的决策,而不是每次都从零开始。
专家团模式:多 Agent 协作
Spec 准备好后,进入执行阶段。专家团模式的核心思想:不同的任务由不同角色的 Agent 来完成。
AI 根据 Spec 生成执行计划,把大型任务拆解成可管理的小任务。每个小任务都有明确的输入、输出和验收标准。系统内置五类专家,每类专家有独立工具集,同时支持自定义专家类型。
用户的角色也随之转变:和 Experts Leader 澄清意图、对齐方向、审核计划、验收结果——更像带一个有经验的研发小组,而不是自己写代码。
总结
回到那个反直觉的问题:为什么出码率 90% 却没提效?
答案已经很清楚了——因为出码率只衡量了"编码"这一个环节,而研发是一个全链路过程。 真正的提效需要:
- SDD 把模糊的需求变成可验证的规范,让 AI 不再"氛围编程"
- Harness 搭建约束、验证、反馈、纠错的完整系统,让 AI 在受控环境中运行
- 全链路打通从需求到部署形成闭环,而不是只在编码环节提效
这三个合在一起,才能实现从"AI 写代码"到"AI 做研发"的跨越。
正如 Anthropic 在《2026 Agentic Coding Trends Report》中所预判的:未来的工程竞争力将不再取决于谁的 Prompt 写得更好,而是取决于谁的 Harness 设计得更精密、更可靠、更具可演化性。
作为开发者,我们的核心竞争力正在从"写代码"转向"设计 Agent 的工作环境"。这个转型才刚刚开始,但方向已经清晰。
— 完 —
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号