产品特性
1. 什么是智能顾问-混沌演练?
智能顾问是提供可视化云架构 IDE 和多个 ITOM 领域垂直应用的云上治理平台,以“一个平台,多个应用”为产品理念,依托腾讯云海量运维专家经验,助您打造卓越架构,实现便捷、灵活的一站式云上治理。智能顾问-混沌演练(Chaotic Fault Generator)是智能顾问产品家族的产品之一,基于可视化云架构,为您提供高效便捷、安全可靠的故障演习服务,帮助您及时发现业务容灾隐患、验证高可用预案的有效性,从而提高系统的可用性和韧性。
2. 什么是云架构可视化演练?
通过智能顾问-云架构的混沌演练插件,对云架构进行可视化混沌演练。
添加演练对象时,支持直接从云架构中点击图元并选择对应实例资源,爆炸半径更加清晰可控;执行演练时,实例所在私有网络、可用区、实例类型和数量、上下游依赖关系等信息一目了然,您可以更好地观测故障蔓延范围,实时查看各个实例当前的动作执行状态、监控指标等。
3. 智能顾问-混沌演练支持对哪些对象类型进行故障注入?
智能顾问-混沌演练支持对腾讯云 CVM、TKE、MySQL、Redis 、NAT、CLB 和专线、音视频等对象类型进行故障注入,以检验系统可用性。
4. 什么是行业经验库?
为了帮助用户快速复用成熟的演练方案,智能顾问-混沌演练提供了电商、游戏、多媒体等多个行业的演练经验模板,内容覆盖跨可用区容灾、混合云容灾演练、服务压力演练、网络故障演练等多个典型应用场景。登录 智能顾问 > 云上治理,首先通过目录进入业务架构图。在页面上方选择治理模式,进入混沌演练,点击下方菜单中的演练经验库,单击打开模板即可浏览行业经验库模板信息,点击一键创建演练,系统将自动把动作编排方案等自动带入创建表单中,用户只需选择实例资源,即可快速创建一个演练,提高演练效率。
演练动作执行失败问题排查
1. 实例锁机制出现异常如何处理?
动作执行失败,提示当前实例正在被其他动作注入故障。
为避免同类型的故障对同一实例注入故障后无法准确观察实例状态表现,平台增加实例锁机制,保证同一时刻下对同一实例仅有单一故障动作可执行,其他动作将被排斥。但平台额外考虑到有部分动作互不干扰,无需竞争相同的实例锁,故根据动作类型,再次区分锁的类型,如允许 CPU 类故障动作与内存类故障动作同时执行,但同类型动作将无法同时执行。
2. 云服务器类型故障动作执行失败常见原因?
压测动作(如 CPU 利用率高,磁盘分区使用率高等动作)动作执行失败,提示 stress-ng 安装失败。
服务器操作系统不支持安装,请根据动作要求更换操作系统。

网络故障动作执行失败,提示 Error: Exclusivity flag on, cannot modify.
本次故障所下发的 TC 规则与原有规则冲突,无法覆盖已有规则。可检查是否存在之前的演练动作没有及时恢复,或者可修改配置参数,强制覆盖该规则。
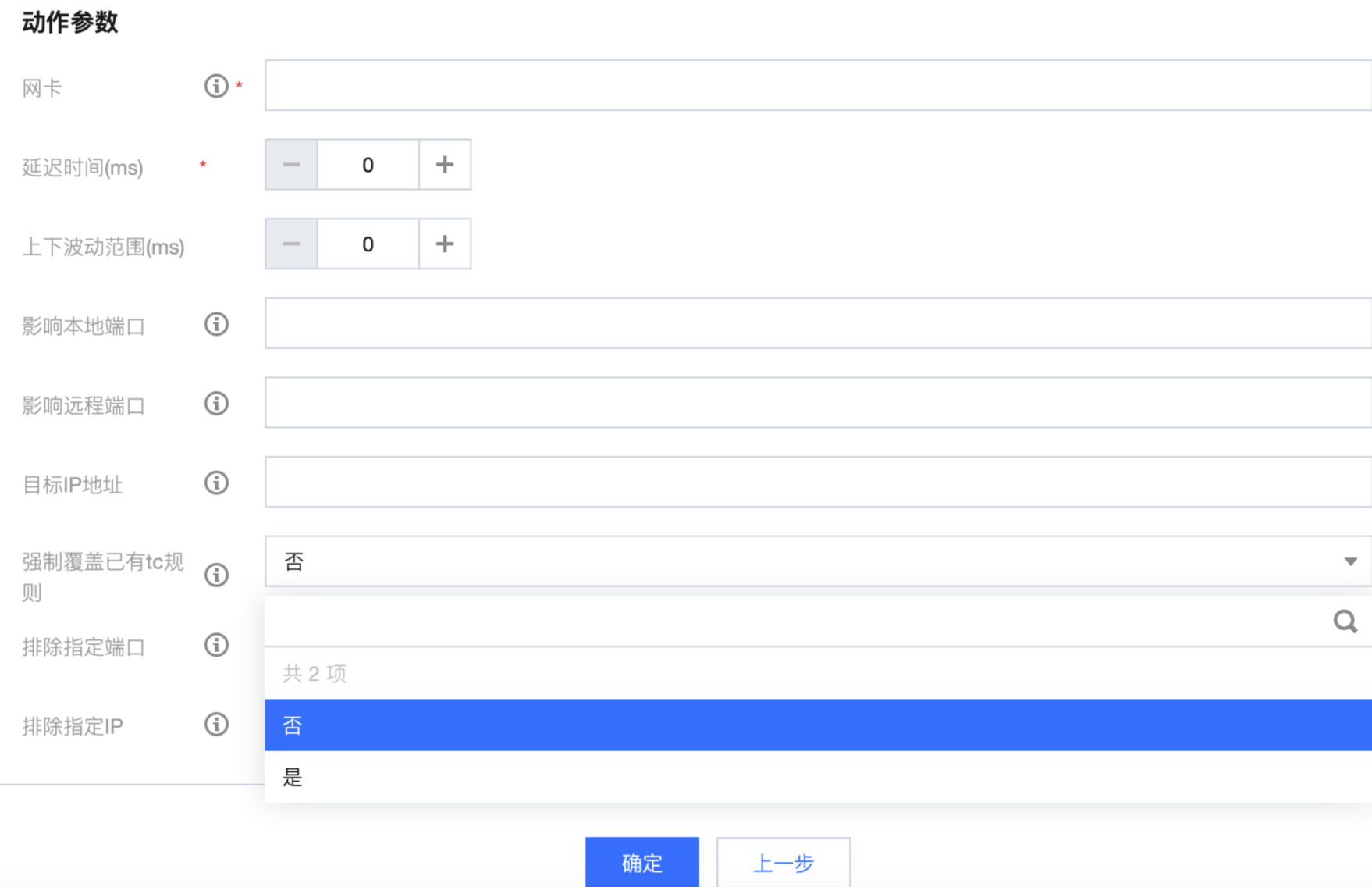
IO Hang 动作执行失败,提示获取操作系统失败。
用户操作系统不支持该动作执行,平台目前支持系统版本为:CentOS 7.2及以上、Debian 8.2及以上、Ubuntu 16.0.4及以上、TencentOS。
3. “Redis”类型故障动作执行失败常见原因?
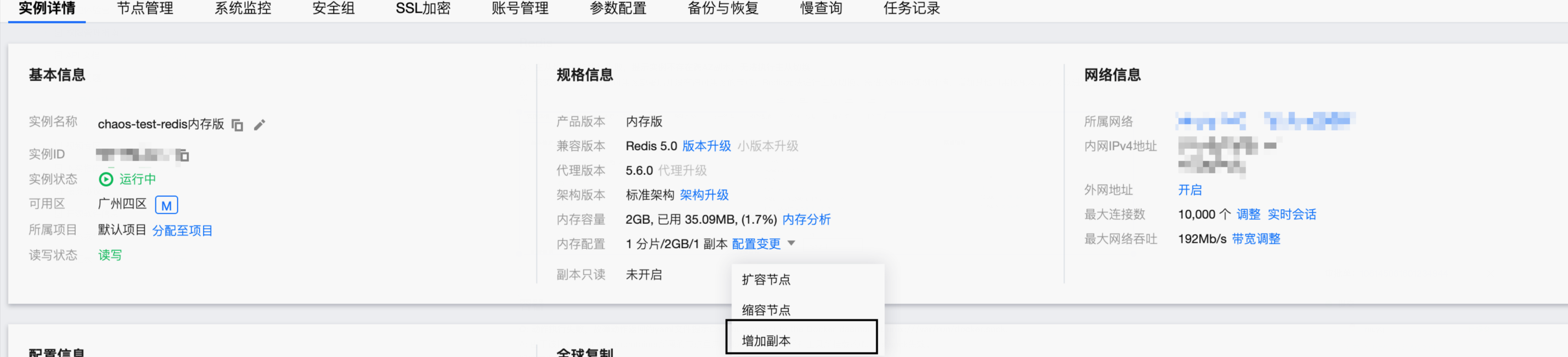
主从切换动作执行失败,提示实例不存在跨 AZ 副本,无法执行主从切换。
该实例升级为支持跨可用区部署后并没有跨可用区的节点,Redis 无法进行主从切换。需进入 Redis 实例详情,增加其他可用区副本后才可以进行主从切换模拟。
4. 容器类型故障动作执行失败常见原因?
动作执行失败,故障动作返回的 yaml 文件提示 Cannot connect to the Docker daemon at unix:///var/run/docker.sock.
由于该执行动作的 pod/container 所属的节点重启了 dockerd,导致探针工具所挂载的 docker.sock 失效。
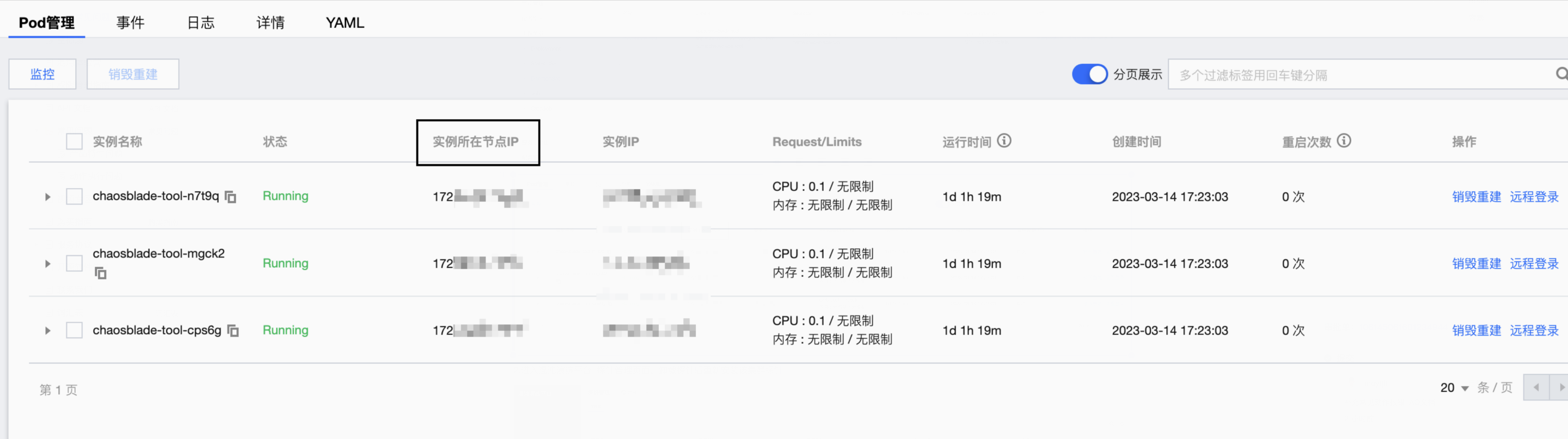
解决方案:
选择指定 IP 节点下的 chaosblade-tool 容器组销毁重建。
进入智能顾问-混沌演练,探针管理页面,卸载探针后重新安装该集群探针。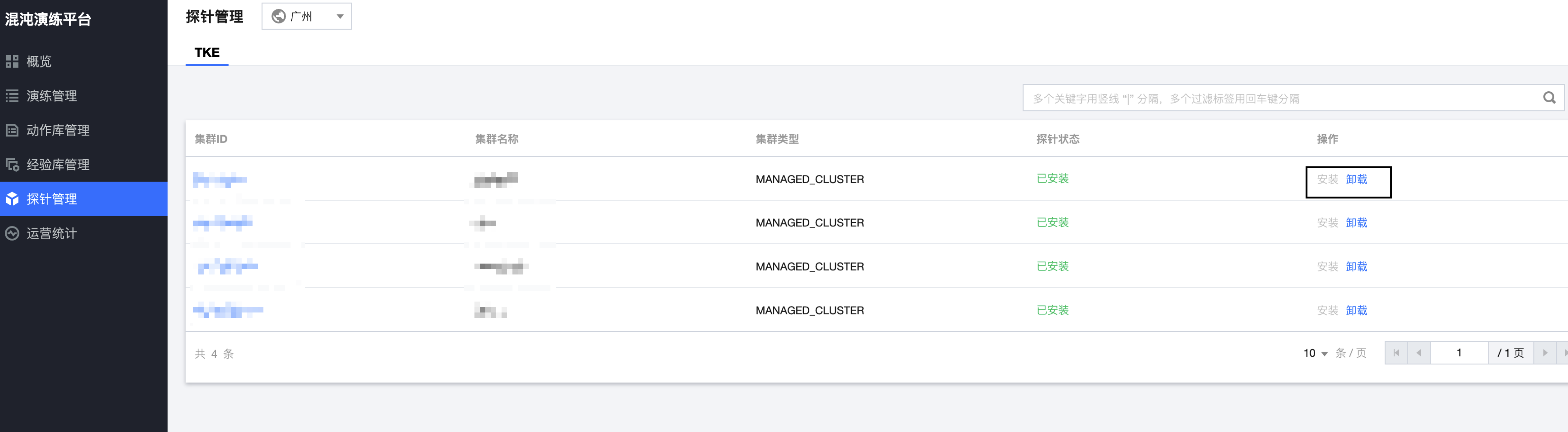
磁盘高负载动作执行成功,恢复动作返回的 yaml 文件提示 error: '`pods/exec`: k8s exec failed, err: command terminated with exit code 137。
节点锁使用的磁盘容量达到一定程度,触发容器销毁重建,故障动作所造成的影响在重建后自行恢复,无需重复执行恢复动作。
Node 内存高负载动作执行失败,提示object is being deleted: chaosblades.chaosblade.io "mem-load.5262.cls-xxx" already exists。
Node 内存达到一定阈值后,节点的 kubelet 进程会被阻塞,而恢复动作只是下发删除实验的命令,返回恢复成功,但是实际执行会依赖于 node 的 kubelet,而此时 kubelet 因为内存资源不足被阻塞,因此实验删除任务一直未被执行。在该状况下,若用户再次执行故障注入,则会出现 mem-load.5262.cls-xxx already exists 错误。该过程中 node 监控,容器平台节点健康检查均呈现异常,需等待节点将第一次执行的被阻塞的恢复动作真正执行完成后,状态才会恢复,此过程大约需要30分钟。
探针安装及管理问题
1. 探针资源占用情况
CVM 探针
CVM 的故障注入探针为预装在 CVM 主机上的可执行程序(位于
/data/cfg/chaos-executor 目录下),选择特定故障时,会要求安装故障注入探针。故障注入时会执行该程序,探针占用磁盘资源小于1M,在网络故障注入时 CPU 内存占用不超过系统 1%,内存和 CPU 压力场景下基本等同于当前配置的压测目标值。容器探针
安装容器的故障注入探针后,会在集群创建以下资源:
1. 命名空间:tchaos。
2. ClusterRole: chaosmonkey,角色的 rules 如下,这表示探针 operator 将获得对 K8S API 的相应权限。
rules:- apiGroups:- ""resources:- namespaces- nodesverbs:- get- list- apiGroups:- ""resources:- podsverbs:- get- list- update- delete- create- patch- apiGroups:- ""resources:- pods/execverbs:- create
3. ServiceAccount: chaosmonkey,注意在 tchaos 命名空间下。
4. ClusterRoleBinding:绑定 ClusterRole 和 ServiceAccount。
5. Operator:在 tchaos 命名空间下启动名称为 chaos-operator 的 deployment,副本数为1,pod 使用的 ServiceAccount 为上一步创建的 chaosmonkey,最大资源占用为1核2G(Limit)。探针安装后,chaos-operator 会一直处于运行中,消耗集群资源。当考虑控制成本时,请在故障注入后及时卸载探针。
6. 故障注入时,operator 会在目标节点临时创建一个 helperpod 注入故障,helperpod 对目标 pod 没有侵入性(不是 sidecar),此外,为了达到指定压力场景,helperpod 资源占用未做限制;在故障恢复时,临时创建的 helperpod 会被自动删除。
7. helperpod 的故障注入日志及实验记录将保存在节点
/var/log/chaos 目录下,通常小于10K。注意:
helperpod 的故障注入日志数据不会随探针卸载删除,必要时,请手动删除该日志。
2. 检测发现存在探针状态异常
问题示例
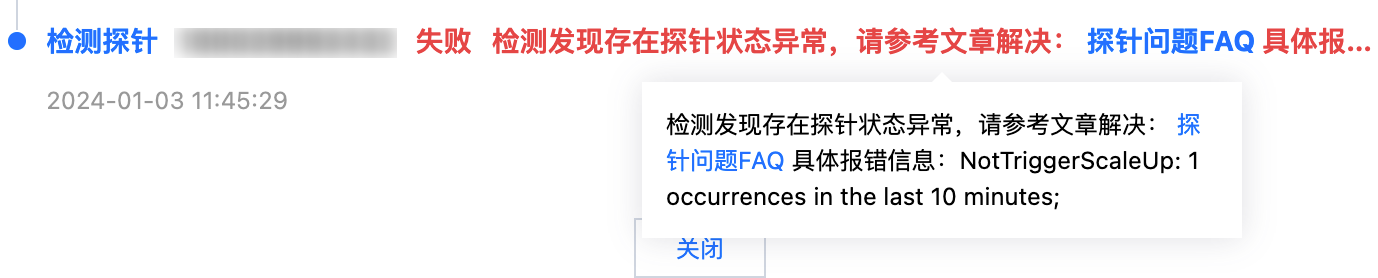
解决方案
请检查命名空间 tchaos 下的 deployment 负载 chaos-operator,查看 Pod 是否启动。如未启动则查看事件中的异常信息。以下是一些可能限制 Pod 启动的事件类型和对应的解决办法:
事件类型 | 解决方法 |
OutOfMemory 或 OutOfCPU | 请检查集群中是否有足够的资源来运行探针。您可能需要增加集群的资源或者调整其他工作负载以释放资源。 |
InsufficientStorage | 请检查集群中是否有足够的存储空间来运行探针。您可能需要增加存储空间或者清理无用的数据以释放存储空间。 |
FailedScheduling | 可能是由于集群中没有节点能满足 Pod 的调度需求。请检查 Pod 的调度约束以及集群中节点的状态和标签。 |
CrashLoopBackOff 或 Error | 可能是由于探针的程序错误或者配置问题。请查看 Pod 的日志以获取更多详细信息,并根据日志中的错误信息进行相应的排查和解决。 |
ImagePullBackOff | 可能是由于无法从镜像仓库拉取镜像。请检查您的镜像仓库地址和凭证是否正确,以及网络连接是否正常。 |
NotTriggerScaleUp | 可能是由于集群的自动扩缩容策略没有触发。请检查您的集群自动扩缩容策略配置,以确保在需要时可以正确触发扩容。 |
3. 检测发现存在无法自动卸载的探针,需要您先手动卸载
问题示例

解决方案
在这种情况下,您需要手动删除以下 Kubernetes 资源:
clusterrole: chaosmonkey
clusterrolebinding: chaosmonkey
serviceaccount: chaosmonkey(位于 tchaos 命名空间下)
namespace: tchaos
deployment: cloudchaos-operator(位于 tchaos 命名空间下)
注意:
在手动卸载探针后,您无需手动安装新的探针。跳转至探针管理页面进行安装即可。
在卸载探针后,请确保您的集群状态正常,以便新的探针能够顺利安装。如果在安装过程中遇到任何问题,请查看相关日志以获取更多详细信息,并根据日志中的错误信息进行相应的排查和解决。



