问题现象
集群所有节点 CPU 都很高,但读写都不是很高。具体表现可以从 kibana 端 Stack Monitoring 监控页面进行查看: 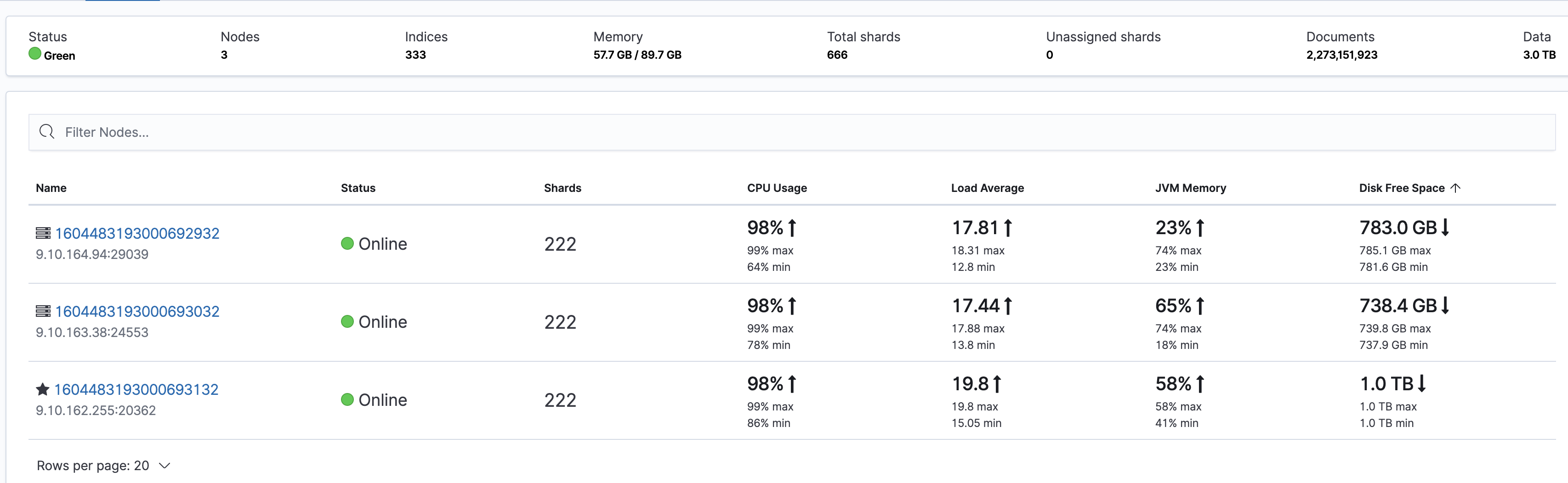
说明
问题定位和解决方案
查询请求较大导致 CPU 飙高
这种情况比较常见,可以从监控上找到线索。通过监控可以发现,查询请求量的波动与集群最大 CPU 使用率是基本吻合的。
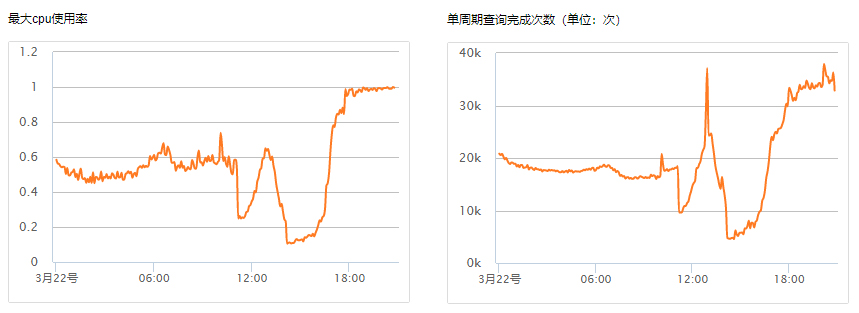
解决方案
尽量避免大段文本搜索,优化查询。
通过慢日志确认查询慢的索引,对于一些数据量不大的索引,设置少量分片多副本,例如1分片多副本,以此来提高查询性能。
写入请求导致 CPU 飙高
通过监控来观察到 CPU 飙高与写入相关,然后开启集群的慢日志收集,确认写入慢的请求,进行优化。也可以通过获取
hot_threads信息来确认什么线程在消耗 CPU:curl http://9.15.49.78:9200/_nodes/hot_threads
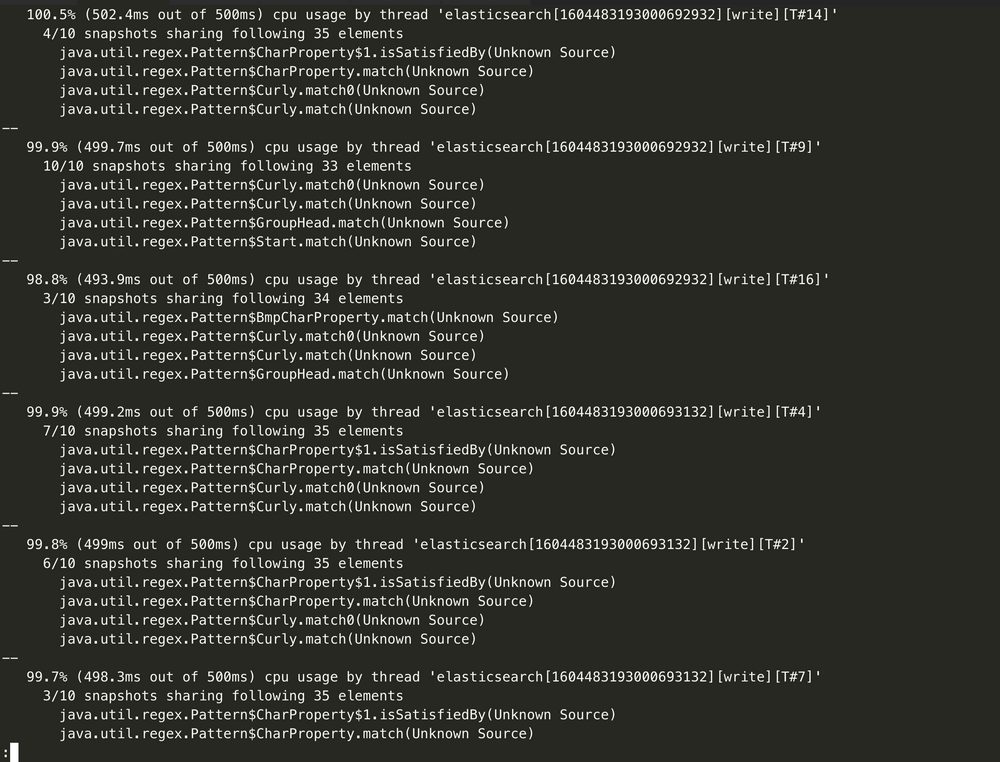

解决方案
如遇到上面这种问题,则需要业务方根据实际情况来优化。排查该类问题的关键点,在于善用集群的监控指标来快速判断问题的方向,再配合集群日志来定位问题的根因,才能快速地解决问题。



