数据集成提供了 Iceberg 的实时写入能力,本文为您介绍使用 Iceberg 进行实时数据同步的当前能力支持情况。
支持版本
目前数据集成已支持 Iceberg 单表及整库实时写入,使用实时同步能力需遵循以下版本限制:
类型 | 版本 |
Iceberg | 0.13.1+ |
使用限制
Upsert 写入只支持 Iceberg V2 表。
Iceberg 写入后,为提高查询性能,一般要求下游通过定时 Spark Action 进行小文件合并,并合理配置 Checkpoint 周期。
Iceberg 列类型变更仅支持将 int 改成 long,float 改为 double,以及 Decimal 类型在相同 Scale 时增加精度。
实时整库同步写入配置
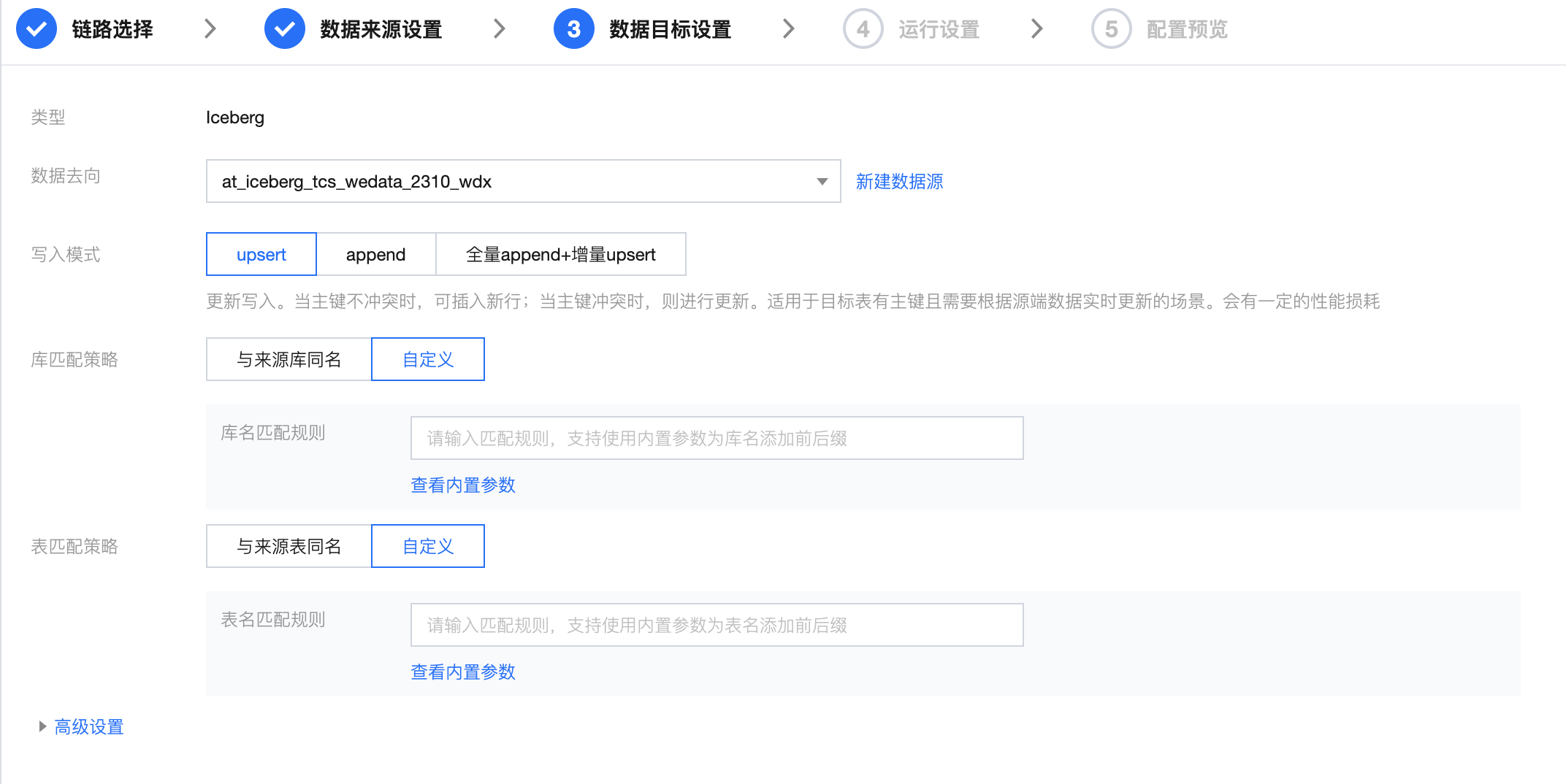
参数 | 说明 |
数据去向 | 选择需要同步的目标数据源。 |
写入模式 | Upsert:更新写入。当主键不冲突时,可插入新行;当主键冲突时,则进行更新。适用于目标表有主键且需要根据源端数据实时更新的场景。会有一定的性能损耗 。Upsert 写入模式仅支持 Iceberg V2 表,且必须有唯一键。 Append:追加写入。无论是否有主键,以插入新行的方式追加写入数据,是否存在主键冲突取决于目标端。适用于无主键且允许数据重复的场景。无性能损耗。 全量 Append + 增量 Upsert:根据源端数据同步阶段自动切换数据写入方式,全量阶段采用 Append 写入提高性能,增量阶段采用 Upsert 写入进行数据实时更新 |
库表匹配策略 | Iceberg 中数据库以及数据表对象的名称匹配规则: 默认与来源库/来源表同名。 自定义:支持使用内置参数和字符串组合生成目标库表名称。 说明: 示例:如来源表名称为 table1,映射规则为 ${table_name_di_src}_inlong,则 table1 的数据将被最终映射写入至 table1_inlong 中。 系统将按匹配规则进行目标库/表匹配: 若 Iceberg 目标端不存在匹配到的库/表,则进行自动建库/建表。 若 Iceberg 目标端已存在匹配到的库/表,则不自动建库/建表,默认用已存在的库/表。 |
高级设置 | 可根据业务需求配置参数。 |
实时分库分表同步写入配置
与实时整库同步写入配置项一致。
实时单表同步写入配置
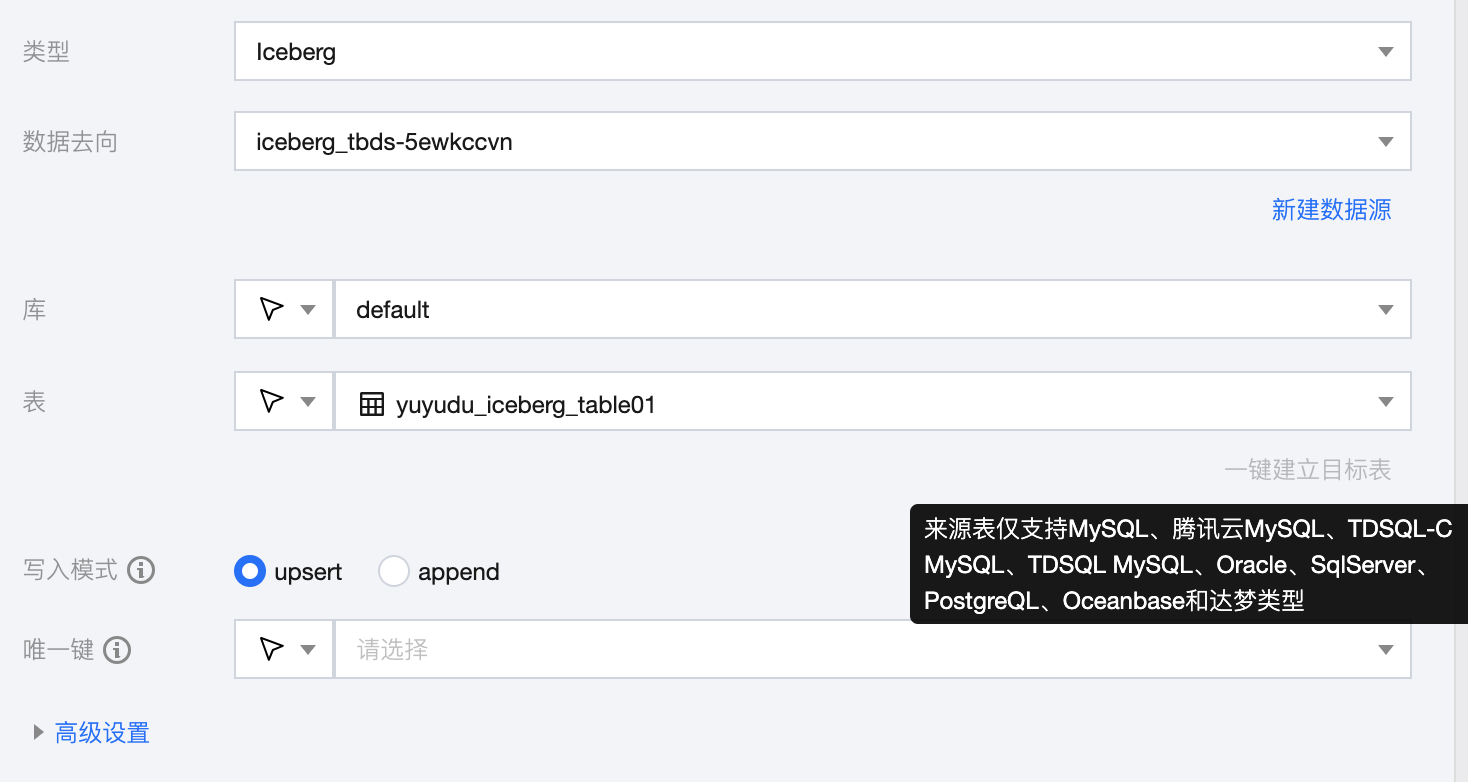
参数 | 说明 |
数据去向 | 需要写入的 Iceberg 数据源。 |
库 | 支持选择、或者手动输入需写入的库名称。 默认将数据源绑定的数据库作为默认库,其他数据库需手动输入库名称。 当数据源网络不连通导致无法直接拉取库信息时,可手动输入数据库名称。在数据集成网络连通的情况下,仍可进行数据同步。 |
表 | 支持选择、或者手动输入需写入的表名称。 当数据源网络不连通导致无法直接拉取表信息时,可手动输入表名称。在数据集成网络连通的情况下,仍可进行数据同步。 |
一键建立目标表 | 来源端为 MySQL、TDSQL-C MySQL、TDSQL MySQL、Oracle、PostgreSQL、Oceanbase、达梦时,支持根据源表结构一键创建 Iceberg 目标表。 |
写入模式 | Upsert:更新写入。当主键不冲突时,可插入新行;当主键冲突时,则进行更新。适用于目标表有主键且需要根据源端数据实时更新的场景。会有一定的性能损耗。仅支持 Iceberg V2 表,且必须有唯一键。 Append:追加写入。无论是否有主键,以插入新行的方式追加写入数据,是否存在主键冲突取决于目标端。适用于无主键且允许数据重复的场景。无性能损耗。 |
唯一键 | Upsert 写入模式下,需设置唯一键保证数据有序性,支持多选。 |
高级设置 | 可根据业务需求配置参数。 |
支持的字段类型
内部类型 | Iceberg 类型 |
CHAR | STRING |
VARCHAR | STRING |
STRING | STRING |
BOOLEAN | BOOLEAN |
BINARY | FIXED(L) |
VARBINARY | BINARY |
DECIMAL | DECIMAL(P,S) |
TINYINT | INT |
SMALLINT | INT |
INTEGER | INT |
BIGINT | LONG |
FLOAT | FLOAT |
DOUBLE | DOUBLE |
DATE | DATE |
TIME | TIME |
TIMESTAMP | TIMESTAMP |
TIMESTAMP_LTZ | TIMESTAMPTZ |
INTERVAL | - |
ARRAY | LIST |
MULTISET | MAP |
MAP | MAP |
ROW | STRUCT |
RAW | - |
Iceberg 分区设置
分区说明
1. 整库迁移、分库分表任务,需开启自动建表,并在数据目标设置高级参数,进行如下格式的分区设置:
分区表1:分区字段1:分区策略1|分区表2:分区字段1,分区字段2:分区策略1,分区策略2
示例:sink.partition.rules=test1:age:bucket[8]|test2:date:year|test3:ts_wedata_di:day
上面表示对表名为test1的表按age字段进行bucket[8]分区,对表名为test2的表按date字段进行按年分区;对表名为test3的表按ts_wedata_di系统元数据字段进行按天分区。
2. 多个表按“|”分隔,按先后顺序对表进行分区匹配,对同一个表设置多次分区仅第一次生效。
3. 同一个表一次可以设置多个分区字段,结果成功与否按 Iceberg 的返回结果处理。
4. 当前 bucket 及 truncate 后面的长度设置不可省略,暂时未做字段存在性及类型兼容性校验,表名的匹配规则按 sink 表名的匹配规则进行处理,即无论 source 表是什么,只要对应的 sink 表的表名满足分区规则的表名设置就表示匹配上,进而进行分区。
5. 如果第一项匹配成功,但类型不合适,后续仍不再匹配。
支持的分区函数
注意:
暂未对分区字段类型进行校验,如不成功,则会创建表失败。
分区函数 | 效果描述 | 支持的原字段数据类型 | 分区字段数据类型 |
identity | 原值 | 任何基础数据类型 | 与原字段数据类型一致 |
bucket[N] | 对原字段数据值按 N 取模进行 Hash | int, long, decimal, date, time, timestamp, timestamptz, string, uuid, fixed, binary | int |
truncate[W] | 对原字段数据值按宽度W 进行截断 | int, long, decimal, string | 和原字段数据类型一样 |
year | 从 date 或 timestamp 类型的原字段,解析出 year | date, timestamp, timestamptz | int |
month | 从 date 或 timestamp 类型的原字段,解析出 month | date, timestamp, timestamptz | int |
day | 从 date 或 timestamp 类型的原字段,解析出 day | date, timestamp, timestamptz | int |
hour | 从 timestamp 类型的原字段,解析出 hour | timestamp, timestamptz | int |
常见问题
表字段长度过长导致的提交失败问题
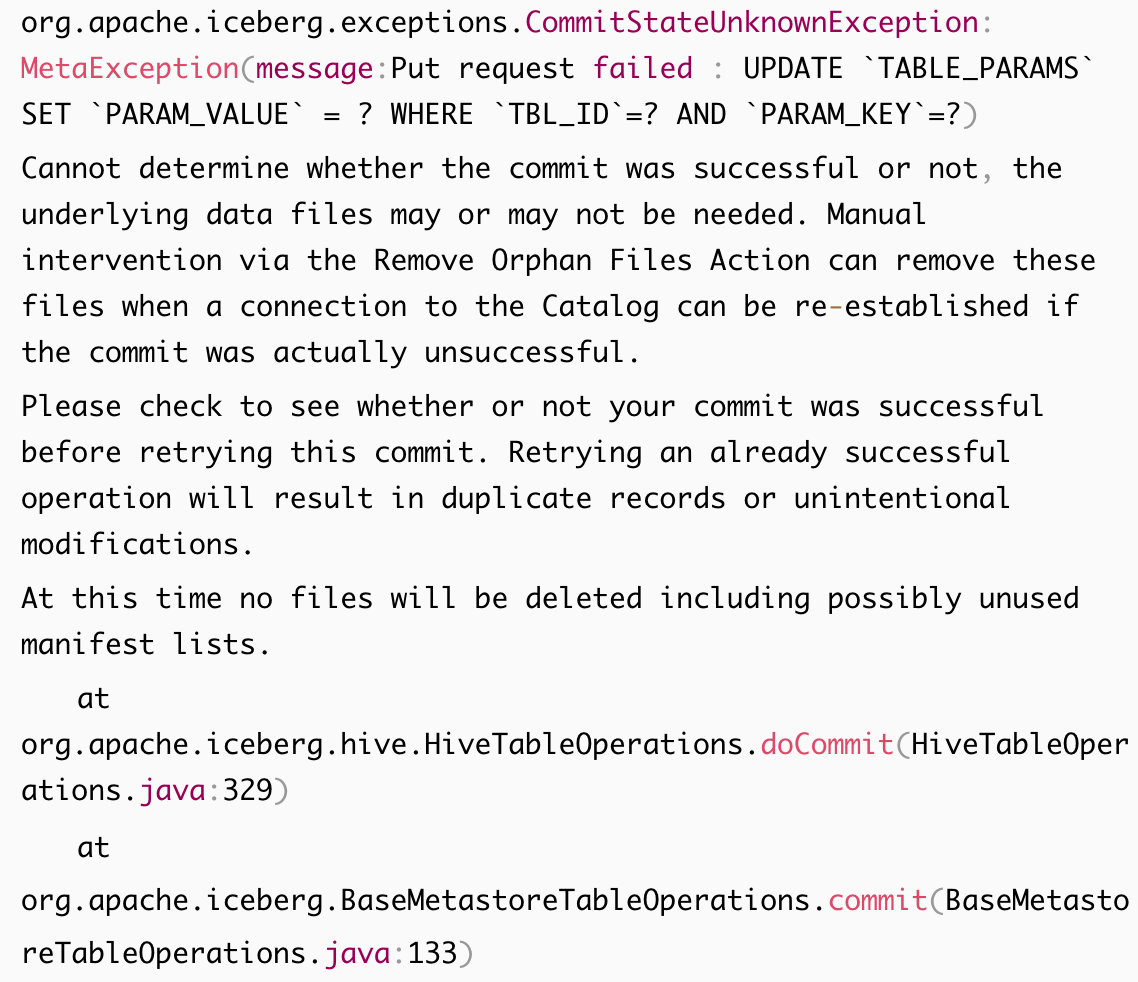
解决方案:
1. 先备份 TABLE_PARAMS 表:
mysqldump -hxxx -uroot -pxxx hivemetastore TABLE_PARAMS > table_params.sql
2. 长度改为40000:
alter table TABLE_PARAMS MODIFY PARAM_VALUE VARCHAR(40000);
说明:
UTF-8 格式时无法支持40000长度,可以改为 text 类型或减小到20000。



