支持版本
支持 Hive 2.x、3.x 版本。
使用限制
1. 目前仅支持读取 TextFile、ORCFile 和 ParquetFile 三种格式的文件,建议为 ORC 或者 Parquet;目前仅支持写入 TextFile、ORCFile 和 ParquetFile 格式的文件,暂不支持 RCFile 格式的文件。
2. Hive 读取利用 JDBC 连接 HiveServer2 获取数据,需要在数据源正确配置 HiveServer2 的 JDBC URL。
3. Hive 表底层存储为 TXT 格式时,JDBC、HDFS 读取方式均不建议文件数据项中包含作为分隔符的字符,否则会导致数据解析错误。
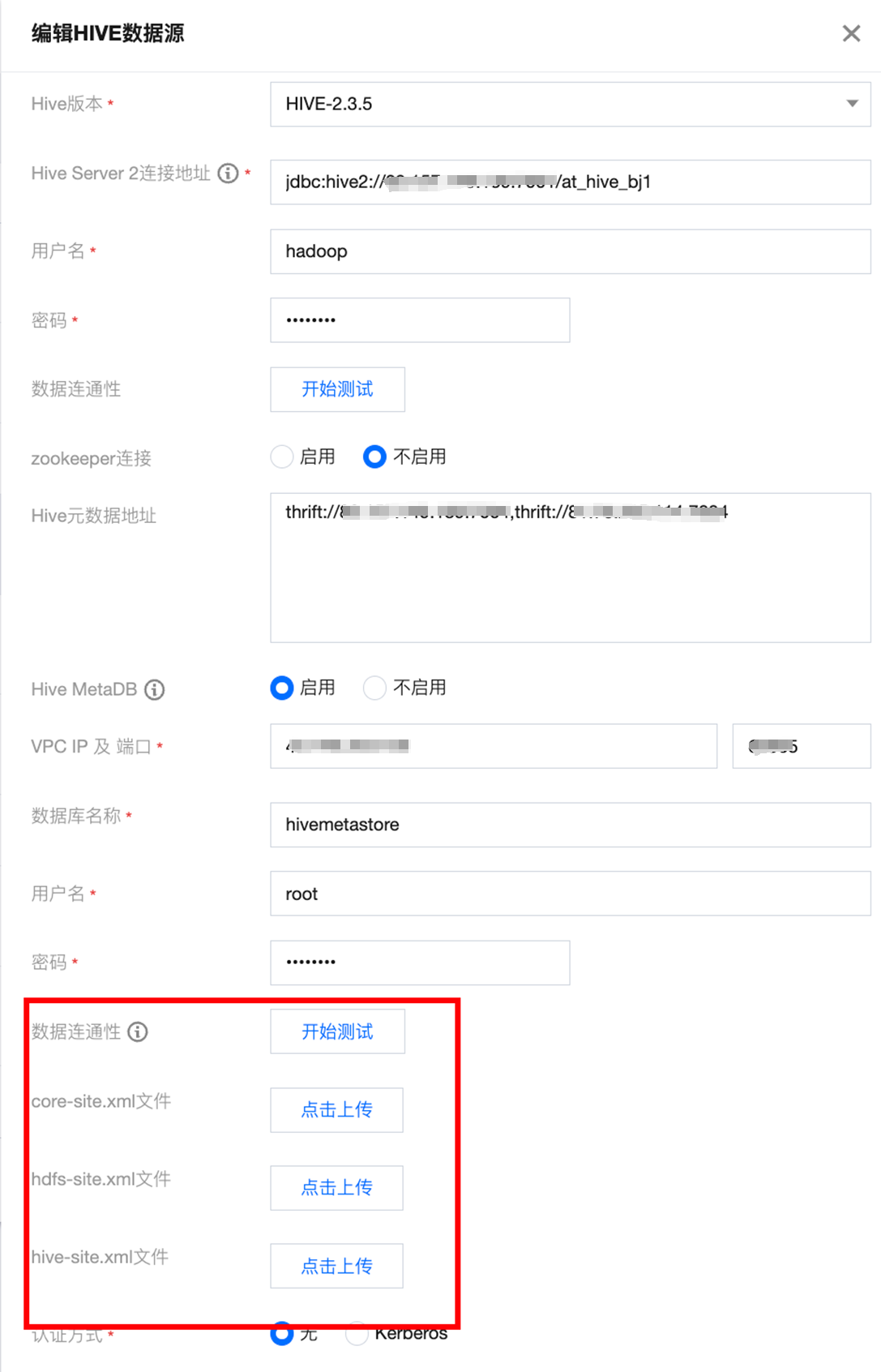
4. Hive 写入需要连接 Hive Metastore 服务,请在数据源正确配置 Metastore Thrift 协议的 IP 和端口。如果是自定义 Hive 数据源,还需要上传 hive-site.xml、core-site.xml 和 hdfs-site.xml 。
5. 重建 Hive 表时如需增加列字段,需要加上 cascade 关键字。防止 Partition Metadata 没有更新,影响数据查询。
6. 使用数据集成向 Hive 集群进行离线同步的过程中,会在服务端侧产生临时文件,在同步任务执行完成时,会自动删除。您需要留意服务端 HDFS 目录文件数限制,避免非预期的文件数达到上限导致 HDFS 文件系统不可用,无法保障文件数在 HDFS 目录允许范围内。
7. Hive 的 JDBC、HDFS 读取方式均不支持 Brotli 压缩格式。
8. 字段类型相关使用限制:
Hive 对于不支持字段类型在读取时会将其转换为 STRING 类型向目标端同步。
Hive 的 JDBC、HDFS 读取方式均不支持读取 UNION 类型。
Hive 的 JDBC 读取方式支持读取 ARRAY、MAP、STRUCT 类型。
Hive 的 HDFS 读取方式:
源端为 Parquet 格式时,支持读 ARRAY、MAP、STRUCT 类型。
源端为 ORCFile 格式时,支持读 ARRAY、MAP 类型。
源端为 TextFile 格式时,不支持读取 ARRAY、MAP、STRUCT 和 UNION 类型。
Hive 离线单表读取节点配置
1. 查询模式选择表。
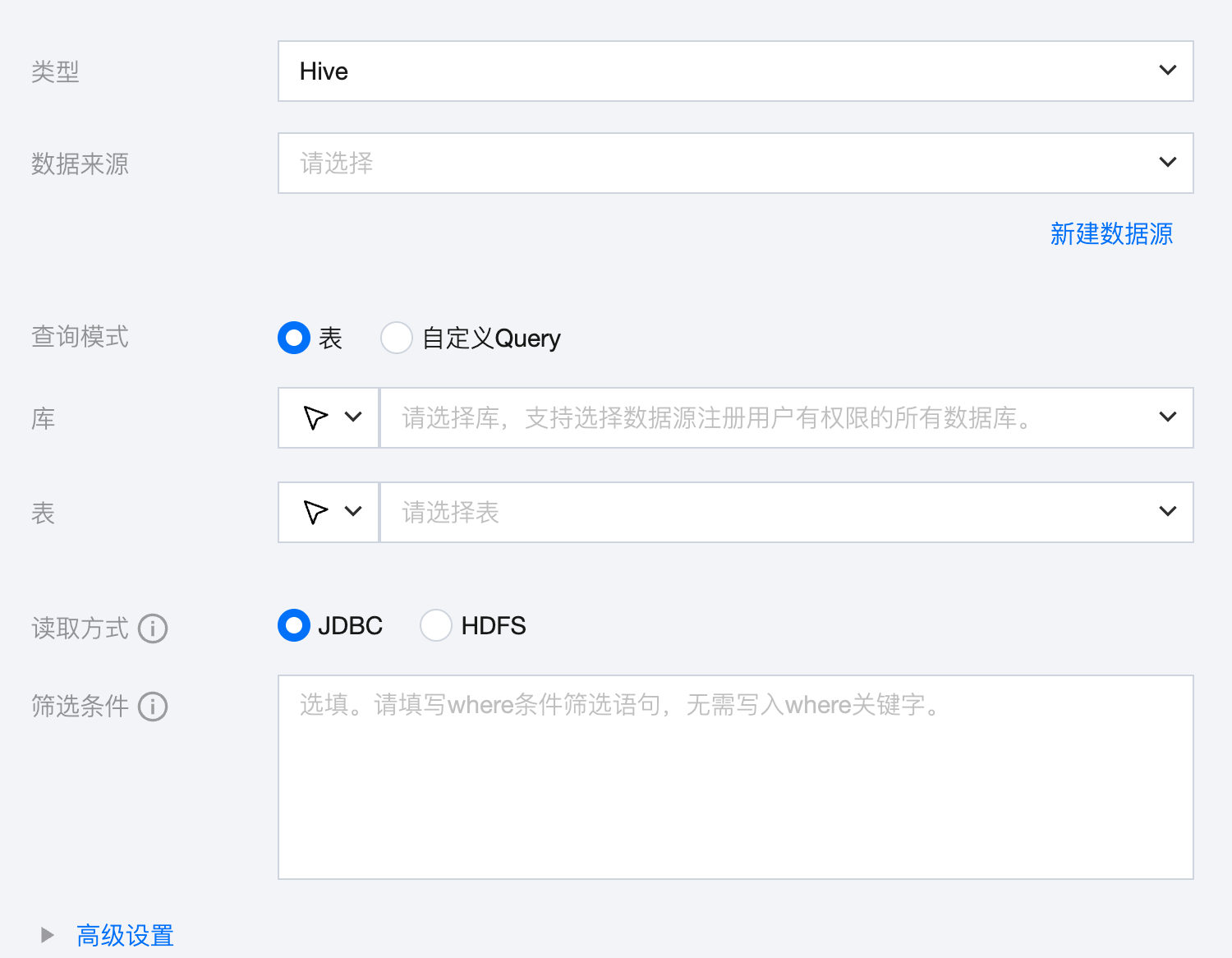
参数 | 说明 |
数据来源 | 可用的 Hive 数据源。 |
查询模式 | 表:按照来源端选择的库、表进行数据同步,该模式需要配置字段映射。 自定义 Query:按照来源端填写的自定义 Quey 语句查询数据,默认按照同名映射的方式进行数据同步,无需配置字段映射.该模式当前支持目标端为 MySQL、Kafka、Oceanbase、COS、DLC。 注意: 1. 自定义 Query 模式下默认以同名映射规则将数据查询结果同步至目标端表的对应同名字段。针对区分大小写的数据源,字段名称相同但大、小写状态不同时将被认为是不同字段。 2. 自定义 Query 语句要求明确表所属的库或 Schema,例如,Hive 数据源语句中需要写明库.表。 3. 自定义 Query 模式下目标端为COS、Kafka 时字段类型默认为 String。 4. 若自定义 Query 语句中含有 union all,则取语句中第一个表的字段作为同步映射的字段。 5. 自定义 Query 模式不支持查询来源端数据库的系统表或虚拟表,例如,Oracle 数据库的 DUAL 表。 6. 自定义 Query 语句中存在 case when 语句时,需要使用别名,例如,select id,vehicleid,case when driverid >115 then 0 else driverid end as driverid,startlocation from test.ods_vehicle。 7. 自定义 Query 模式下暂不支持画布转换、数据对账。 |
库 | 支持选择、或者手动输入需读取的库名称 默认将数据源绑定的数据库作为默认库,其他数据库需手动输入库名称 当数据源网络不联通导致无法直接拉取库信息时,可手动数据库名称。在数据集成网络连通的情况下,仍可进行数据同步 |
表 | 支持选择、或者手动输入需读取的表名称 |
读取方式 | JDBC 读取:支持使用 Where 条件做数据过滤,但读取效率可能较慢。 HDFS 读取:不支持使用 Where 条件做数据过滤,但会直接访问 Hive 表底层的数据文件进行读取,读取效率相对更高。 注意: 该方式不支持读取视图(VIEW)表。 |
筛选条件(选填) | 查询模式为表时: 基于 Hive JDBC 方式读取数据时,支持使用 Where 条件做数据过滤,但是此场景下,Hive 引擎底层可能会生成 MapReduce 任务,效率较慢 |
高级设置(选填) | 可根据业务需求配置参数。 |
2. 查询模式选择自定义 Query。
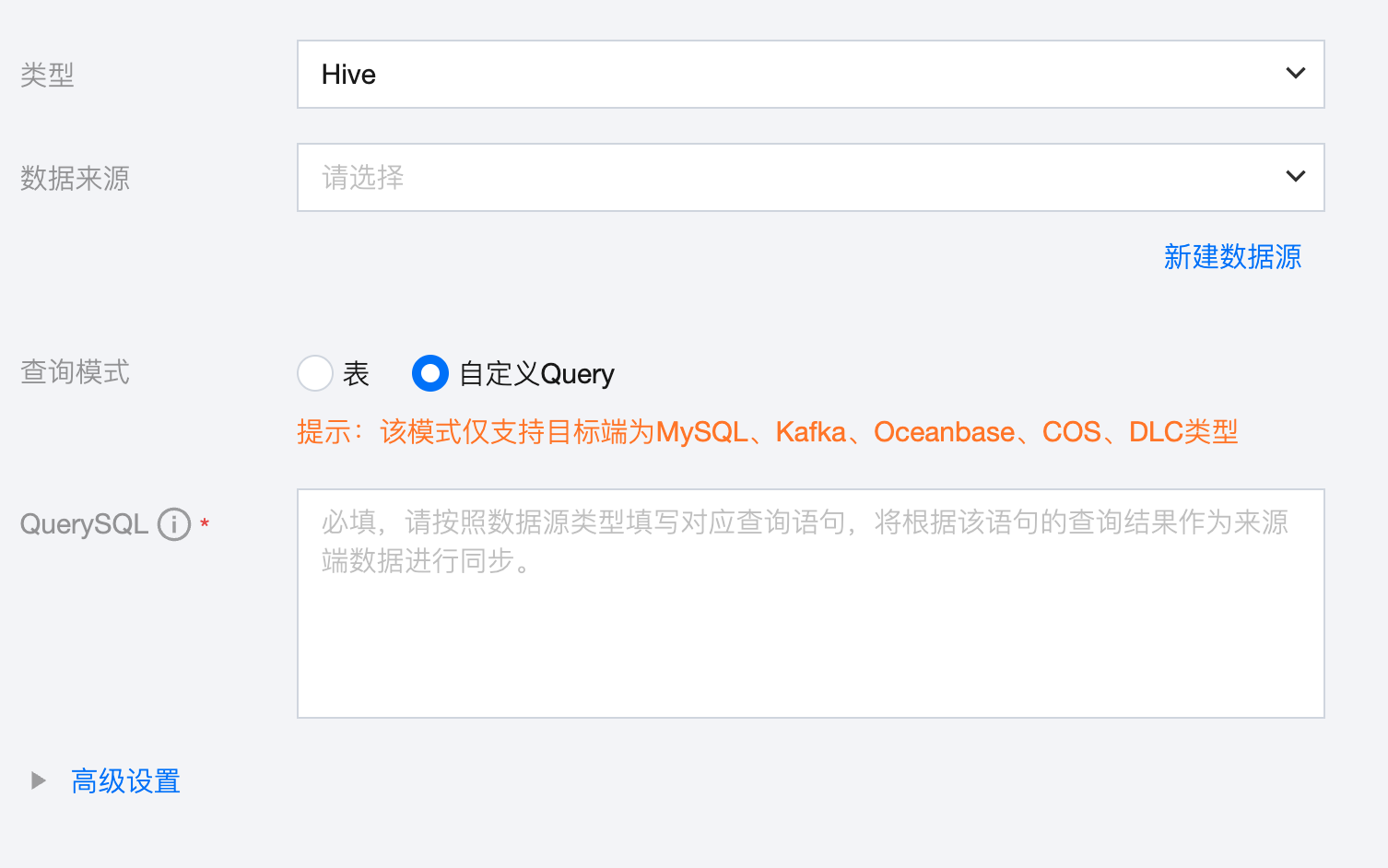
参数 | 说明 |
数据来源 | 可用的 Hive 数据源。 |
查询模式 | 表:按照来源端选择的库、表进行数据同步,该模式需要配置字段映射。 自定义 Query:按照来源端填写的自定义 Quey 语句查询数据,默认按照同名映射的方式进行数据同步,无需配置字段映射。该模式当前支持目标端为 MySQL、Kafka、Oceanbase、COS、DLC。 注意: 1. 自定义 Query 模式下默认以同名映射规则将数据查询结果同步至目标端表的对应同名字段。针对区分大小写的数据源,字段名称相同但大、小写状态不同时将被认为是不同字段。 2. 自定义 Query 语句要求明确表所属的库或 Schema,例如,Hive 数据源语句中需要写明库.表。 3. 自定义 Query 模式下目标端为 COS、Kafka 时字段类型默认为 String。 4. 若自定义 Query 语句中含有 union all,则取语句中第一个表的字段作为同步映射的字段。 5. 自定义 Query 模式不支持查询来源端数据库的系统表或虚拟表,例如,Oracle 数据库的 DUAL 表。 6. 自定义 Query 语句中存在 case when 语句时,需要使用别名,例如,select id,vehicleid,case when driverid >115 then 0 else driverid end as driverid,startlocation from test.ods_vehicle。 7. 自定义 Query 模式下暂不支持画布转换、数据对账。 |
自定义Query | 需按照数据源类型填写对应查询语句,将根据该语句的查询结果作为来源端数据进行同步。 |
高级设置(选填) | 可根据业务需求配置参数。 |
Hive 离线单表写入节点配置
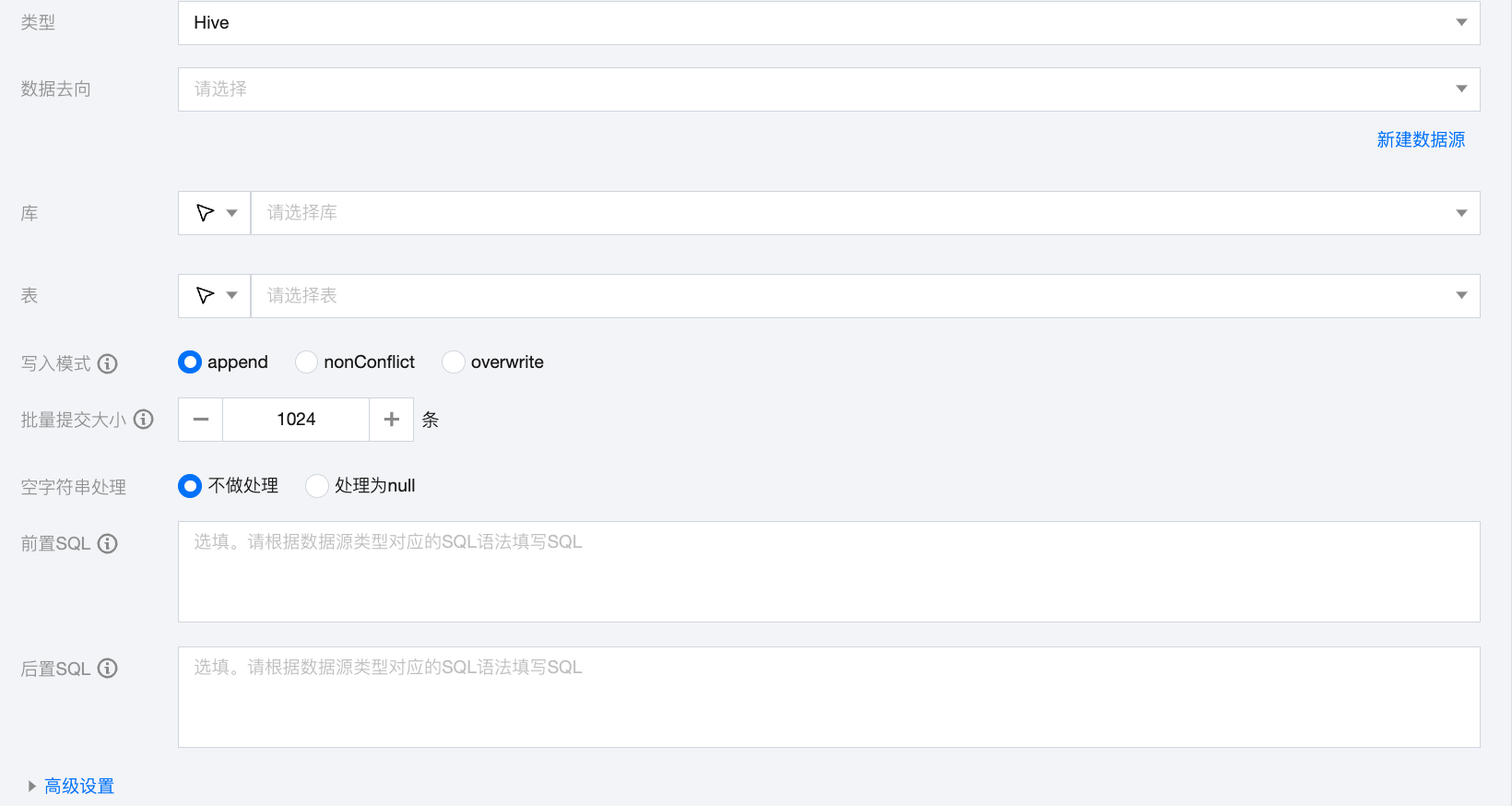
参数 | 说明 |
数据去向 | 需要写入的 Hive 数据源。 |
库 | 支持选择、或者手动输入需写入的库名称 默认将数据源绑定的数据库作为默认库,其他数据库需手动输入库名称。 当数据源网络不联通导致无法直接拉取库信息时,可手动输入数据库名称。在数据集成网络连通的情况下,仍可进行数据同步。 |
表 | 支持选择、或者手动输入需写入的表名称 当数据源网络不联通导致无法直接拉取表信息时,可手动输入表名称。在数据集成网络连通的情况下,仍可进行数据同步。 |
写入模式 | Hive 写入支持三种模式: Append:保留原始数据, 新行追加写入 nonConflict:数据冲突时报错 Overwrite:删除原有数据重新写入 writeMode 是高危参数,请您注意数据的写出目录和写入模式,避免误删数据。加载数据行为需要配合 hiveConfig 使用,请注意您的配置。 |
批量提交大小 | 一次性批量提交的记录数大小,该值可以极大减少数据同步系统与 Hive 的网络交互次数,并提升整体吞吐量。如果该值设置过大,会导致数据同步运行进程 OOM 异常。 |
空字符串处理 | 不做处理:写入时,不处理空字符串。 处理为 null:写入时,将空字符串处理为 null。 |
前置 SQL(选填) | 执行同步任务之前执行的 SQL 语句,根据数据源类型对应的正确 SQL 语法填写 SQL,例如,执行前清空表中的旧数据(truncate table tablename)。 |
后置 SQL(选填) | 执行同步任务之后执行的 SQL 语句,根据数据源类型对应的正确 SQL 语法填写 SQL,例如,加上某一个时间戳 alter table tablename add colname timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP。 |
高级设置(选填) | 可根据业务需求配置参数。 |
数据类型转换支持
读取
Hive 读取支持的数据类型及转换对应关系如下(在处理 Hive 时,会先将 Hive 数据源的数据类型和数据处理引擎的数据类型做映射):
Hive 数据类型 | 内部类型 |
TINYINT,SMALLINT,INT,BIGINT | LONG |
FLOAT,DOUBLE | DOUBLE |
STRING,CHAR,VARCHAR,STRUCT,MAP,ARRAY,UNION,BINARY | STRING |
BOOLEAN | BOOLEAN |
DATE,TIMESTAMP | DATE |
写入
Hive 读取支持的数据类型及转换对应关系如下:
内部类型 | Hive 数据类型 |
LONG | TINYINT,SMALLINT,INT,BIGINT |
DOUBLE | FLOAT,DOUBLE |
STRING | STRING,CHAR,VARCHAR,STRUCT,MAP,ARRAY,UNION,BINARY |
BOOLEAN | BOOLEAN |
DATE | DATE,TIMESTAMP |
常见问题
1. Hive On CHDFS表写入报错:Permission denied: No access rules matched
问题信息:
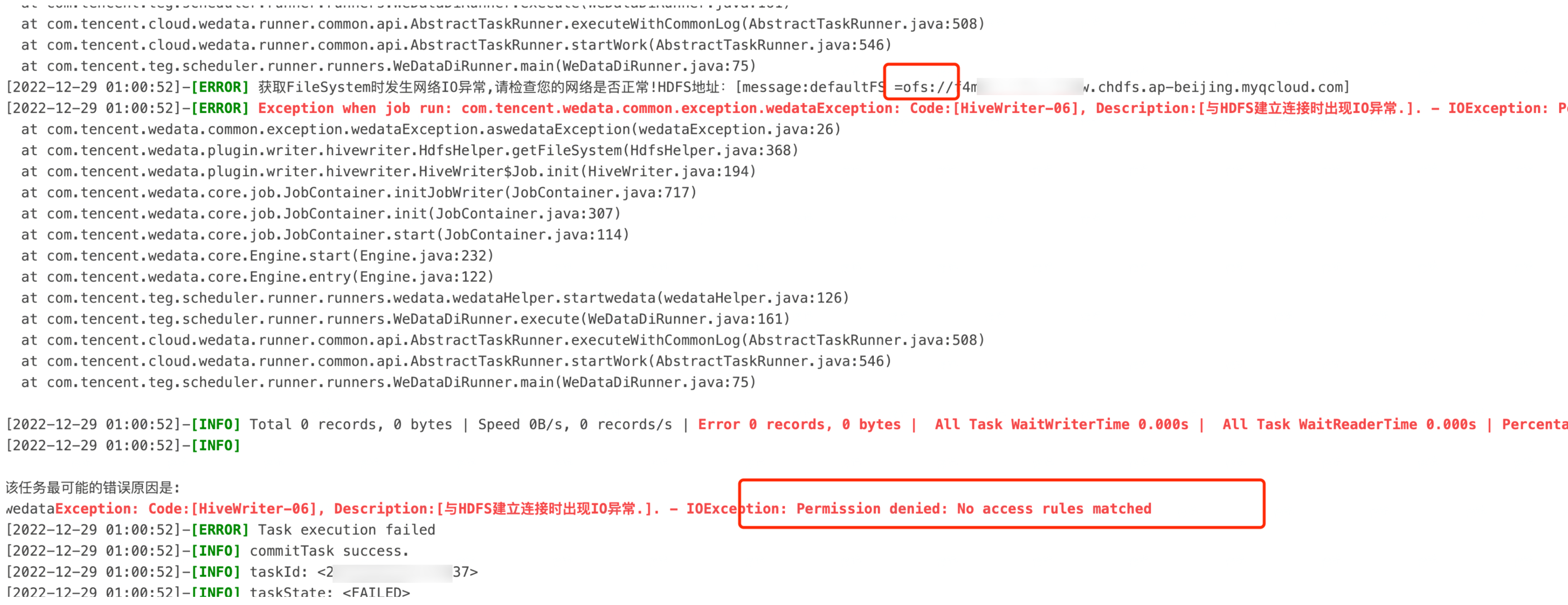
问题原因:
数据集成资源组是全托管资源组,资源组的出口网段非客户的 VPC 内网网段,需要对数据集成资源组放开安全组。
请在 CHDFS 挂载点,对集成资源组的 CHDFS 权限 id 进行授权。

解决方案:
打开页面:API 3.0 Explorer 填入参数,其中 MountPointId 为客户 CHDFS 挂载点,AccessGroupIds.N 为 数据集成资源组的 CHDFS 权限 id(注意,不同区域的权限 id 不同)。

数据集成资源组 CHDFS 权限 id 和区域对照表:
区域 | 数据集成资源组 CHDFS 权限 id |
北京 | ag-wgbku4no |
广州 | ag-x1bhppnr |
上海 | ag-xnjfr9d3 |
新加坡 | ag-phxtv0ah |
美国硅谷 | ag-tgwl8bca |
弗吉尼亚 | ag-esxpwxjn |
2. 同步过程中部分字段查询为 NULL
问题原因:
Hive 分区表创建后,后续 ALTER 添加新字段并没有添加 cascade 关键字导致 Partition Metadata 没有更新,影响数据查询。
解决方案:
alter table table_name add columns (time_interval TIMESTAMP) cascade;
3. 写 Hive 报 [fs.defaultFS] 是必填参数错误
问题信息:

问题原因:
数据源设置时没有上传配置文件,fs.defaultFS 是 core-site.xml 里面的内容。
解决方案:

Hive 脚本 Demo
如果您配置离线任务时,使用脚本模式的方式进行配置,您需要在任务脚本中,按照脚本的统一格式要求编写脚本中的 reader 参数和 writer 参数。
"job": {"content": [{"reader": {"parameter": {"password": "******","hadoopConfig": { //如果hadoop为高可用集群,需要配置NameNode高可用配置信息"dfs.namenode.https-address.mycluster.nn2": "ip:4009","dfs.namenode.https-address.mycluster.nn1": "ip:4009","dfs.ha.namenodes.mycluster": "nn1,nn2","dfs.namenode.servicerpc-address.mycluster.nn2": "ip:4010","dfs.namenode.servicerpc-address.mycluster.nn1": "ip:4010","dfs.namenode.rpc-address.mycluster.nn2": "ip:4007","dfs.namenode.rpc-address.mycluster.nn1": "ip:4007","dfs.namenode.http-address.mycluster.nn2": "ip:4008","dfs.namenode.http-address.mycluster.nn1": "ip:4008","dfs.client.failover.proxy.provider.mycluster": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider","dfs.nameservices": "mycluster","fs.defaultFS": "hdfs://mycluster","spark.eventLog.dir": "hdfs://mycluster/spark-history",},"column": ["id","name"],"where": "id>10", //筛选条件"connection": [{"jdbcUrl": [ //支持多hive源"jdbc:hive2://ip:2181,ip:2181,ip:2181/database;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2;?mapred.job.name=null_null"],"table": [ //源表"source_table"]}],"username": "hadoop"},"name": "hivereader"},"transformer": [],"writer": {"parameter": {"postSql": [ //后置sql""],"database": "database","fetchSize": 1024, //批量提交大小"hadoopConfig": { //如果hadoop为高可用集群,需要配置NameNode高可用配置信息"dfs.namenode.https-address.mycluster.nn2": "ip:4009","dfs.namenode.https-address.mycluster.nn1": "ip:4009","dfs.ha.namenodes.mycluster": "nn1,nn2","dfs.namenode.servicerpc-address.mycluster.nn2": "ip:4010","dfs.namenode.servicerpc-address.mycluster.nn1": "ip:4010","dfs.namenode.rpc-address.mycluster.nn2": "ip:4007","dfs.namenode.rpc-address.mycluster.nn1": "ip:4007","dfs.namenode.http-address.mycluster.nn2": "ip:4008","dfs.namenode.http-address.mycluster.nn1": "ip:4008","dfs.client.failover.proxy.provider.mycluster": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider","dfs.nameservices": "mycluster","fs.defaultFS": "hdfs://mycluster","spark.eventLog.dir": "hdfs://mycluster/spark-history",},"column": [ //列名{"name": "id","type": "int"},{"name": "name","type": "varchar"}],"emptyAsNull": true, //空字符串处理"writeMode": "overwrite", //写入模式"metastoreUris": "thrift://ip:7004","table": "sink_table", //目标表"preSql": [ //前置sql""]},"name": "hivewriter"}}],"setting": {"errorLimit": { //脏数据阈值"record": 0},"speed": {"byte": -1, //不限制同步速度,正整数表示设置最大传输速度 byte/s"channel": 1 //并发数量}}}



