TCHouse-D 数据源与 Doris 配置方式相同,本文以 Doris 数据源为例进行讲解。
支持版本
支持 Doris 0.x、1.1.x、1.2.x、2.x 版本。
使用限制
1. Doris 写入是通过 Stream load HTTP 接口,需要保证数据源中 FE 或 BE 的 IP 或端口填写正确。
2. 由于 Stream load 的原理是由 BE 发起的导入并分发数据,建议导入数据量在1G到10G之间。由于默认的最大 Stream load 导入数据量为10G。
要导入超过10G的文件需要修改 BE 的配置
streaming_load_max_mb。例如:待导入文件大小为15G,修改 BE 配置
streaming_load_max_mb 为16000即可。3. Stream load 的默认超时为600秒,按照 Doris 目前最大的导入限速来看,约超过3G的文件就需要修改导入任务默认超时时间了。
导入任务超时时间 = 导入数据量 / 10M/s(具体的平均导入速度需要用户根据自己的集群情况计算)。
例如:导入一个10G的文件,timeout = 1000s(即:10G 处理10M/s)
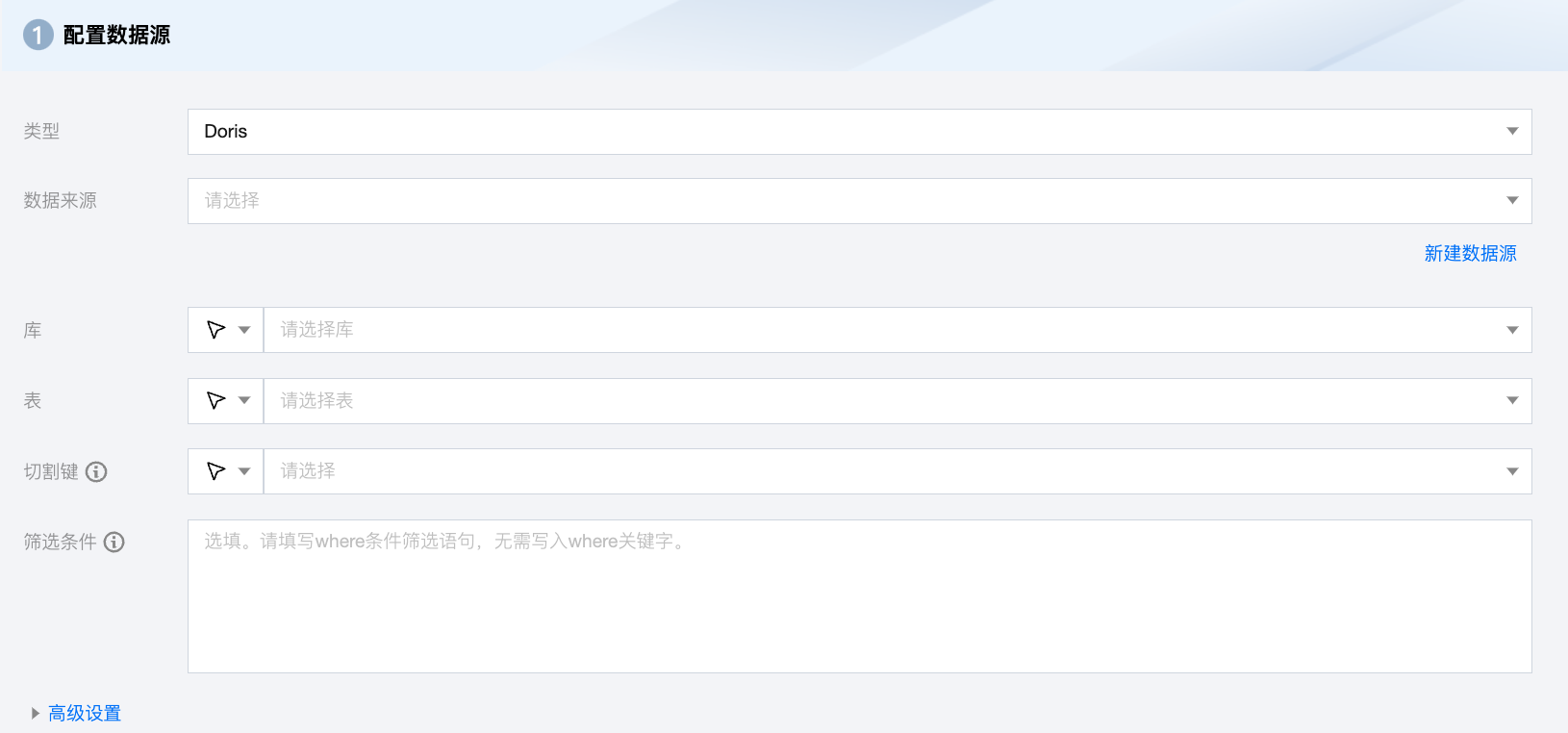
Doris 离线单表读取节点配置
参数 | 说明 |
数据来源 | 需要同步的可用 Doris 数据源。 |
库 | 支持选择、或者手动输入需读取的库名称。默认将数据源绑定的数据库作为默认库,其他数据库需手动输入库名称。 |
表 | 支持选择、或者手动输入需读取的表名称。 |
切割键 | 指定用于数据分片的字段,指定后将启动并发任务进行数据同步。您可以将源数据表中某一列作为切分键,建议使用主键或有索引的列作为切分键。 |
筛选条件(选填) | 在实际业务场景中,通常会选择当天的数据进行同步,将 where 条件指定为 gmt_create>$bizdate。where 条件可以有效地进行业务增量同步。如果不填写 where 语句,视作同步全量数据。 |
高级设置(选填) | 可根据业务需求配置参数。 |
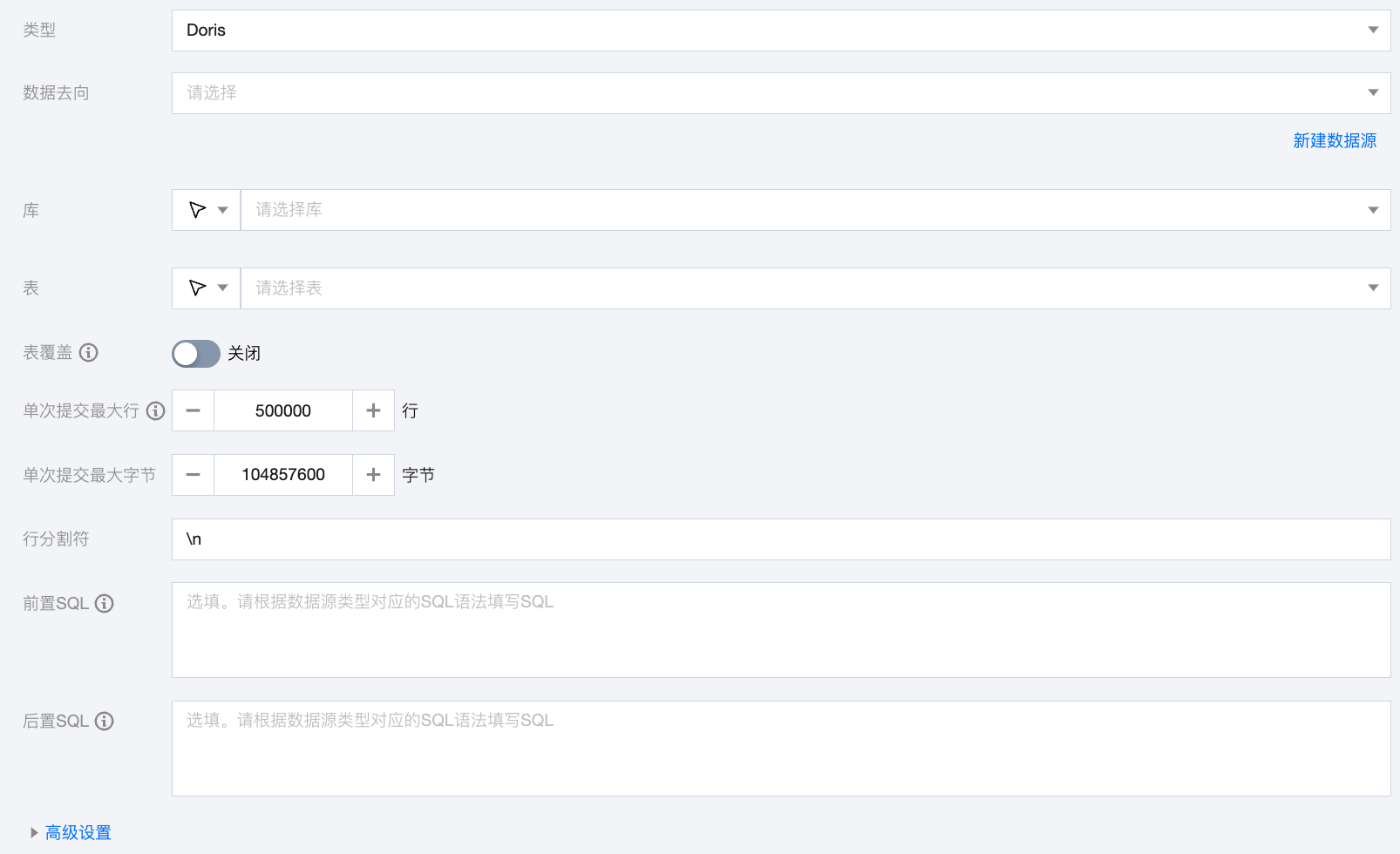
Doris 离线单表写入节点配置
参数 | 说明 |
数据去向 | 需要写入的 Doris 数据源。 |
库 | 支持选择、或者手动输入需读取的库名称。默认将数据源绑定的数据库作为默认库,其他数据库需手动输入库名称。 |
表 | 支持选择、或者手动输入需写入的表名称。 |
表覆盖 | 开启后,doris 将支持表级别的原子覆盖写操作。写入数据前会先使用 CREATE TABLE LIKE 语句创建一个相同结构的新表,将新的数据导入到新表后,通过 swap 方式原子的替换旧表,以达到表覆盖目的。 |
单次提交最大行 | 一次性批量提交的记录数大小。 |
单次提交最大字节 | 一次性批量提交的最大数据量。 |
行分割符(选填) | Doris 写入的键分隔符,默认 \\n ,支持手动输入需要您保证与创建的 Doris 表的字段分隔符一致,否则无法在 Doris 表中查到数据。 |
前置 SQL | 执行同步任务之前执行的 SQL 语句,根据数据源类型对应的正确 SQL 语法填写 SQL,例如,执行前清空表中的旧数据(truncate table tablename)。 |
后置 SQL | 执行同步任务之后执行的 SQL 语句,根据数据源类型对应的正确 SQL 语法填写 SQL,例如,加上某一个时间戳 alter table tablename add colname timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP。 |
高级参数 | 可根据业务需求配置参数。 |
数据类型转换支持
读取端
Doris 数据类型 | 内部类型 |
TINYINT、SMALLINT、INT、BIGINT | Long |
FLOAT、DOUBLE、DECIMAL | Double |
VARCHAR、CHAR、ARRAY、STRUCT、STRING | String |
DATE、DATETIME | Date |
BOOLEAN | Boolean |
写入端
内部类型 | Doris 数据类型 |
Long | TINYINT、SMALLINT、INT、BIGINT |
Double | DOUBLE、FLOAT、DECIMAL |
String | STRING、VARCHAR、CHAR、ARRAY、STRUCT |
Date | DATETIME、DATE |
Boolean | BOOLEAN |
常见问题
1. 分区不存在报错:"no partition for this tuple"
问题原因 :Doris 缺少相应的分区。
解决方案 :如果以时间分区,建议开启动态分区。
表 tbl1 分区列 k1 类型为 DATE,创建一个动态分区规则。按天分区,只保留最近7天的分区,并且预先创建未来3天的分区。CREATE TABLE tbl1(k1 DATE,...)PARTITION BY RANGE(k1) ()DISTRIBUTED BY HASH(k1)PROPERTIES("dynamic_partition.enable" = "true","dynamic_partition.time_unit" = "DAY","dynamic_partition.start" = "-7","dynamic_partition.end" = "3","dynamic_partition.prefix" = "p","dynamic_partition.buckets" = "32");假设当前日期为 2020-05-29。则根据以上规则,tbl1 会产生以下分区:p20200529: ["2020-05-29", "2020-05-30")p20200530: ["2020-05-30", "2020-05-31")p20200531: ["2020-05-31", "2020-06-01")p20200601: ["2020-06-01", "2020-06-02")在第二天,即 2020-05-30,会创建新的分区 p20200602: ["2020-06-02", "2020-06-03")在 2020-06-06 时,因为 dynamic_partition.start 设置为 7,则将删除7天前的分区,即删除分区 p20200529。
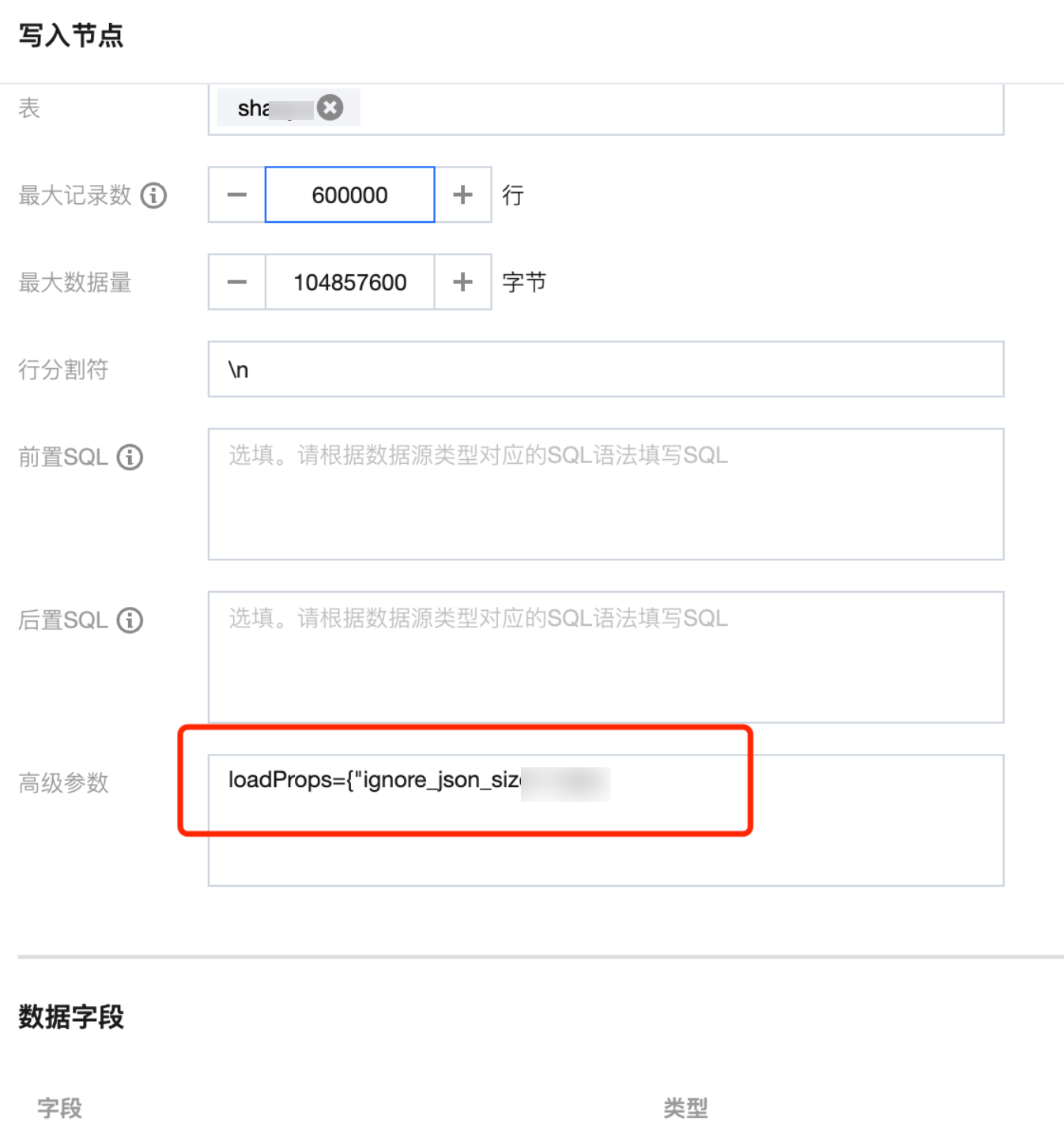
2. 同步数据量过大导致:"The size of this batch exceed the max size of json type data"
问题原因 :批次提交的数据量太大,建议忽略 JSON 数据量的检测。
3. 导入频次太快导致:"tablet writer write failed, err=-235"
问题原因 :导入频次太快导致 VersionCount 超过设置的大小(默认500,由 BE 参数 max_tablet_version_num 控制),建议调整 VersionCount。
解决方案:
1. 找到报错的 tablet_id。
show tablet 28750963;
2. 执行 DetailCmd 显示命令。
SHOW PROC '/dbs/40637/16934967/partitions/28750944/16934968/28750963';
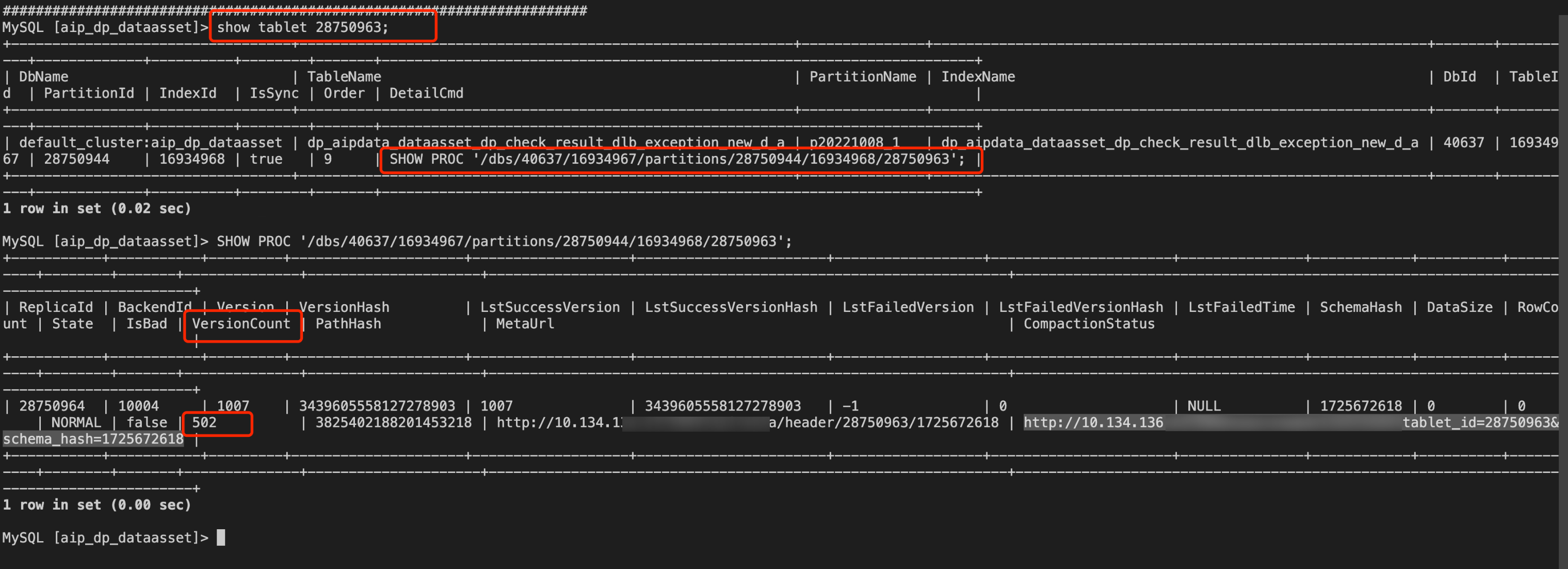
3. 结果中的 versionCount 即表示版本数量。如果发现某个副本的版本数量过多,则需要降低导入频率或停止导入。如果停止导入后,版本数依然没有下降,则需要去对应的 BE 节点查看 be.INFO 日志,搜索 tablet id 以及 compaction 关键词,检查 compaction 是否正常运行。
4. 可以通过增大 max_tablet_version_num 或者优化 tablet 的 compaction 提高压缩效率来减少版本数量。
4. Header 临时分区长度超过限制:"Bad Message 431"
问题原因 :temporary_partition 太大,减少 temporary_partition 数量。


5. DLC 同步 Doris 时,Doris 端报错:字段超过 schema 长度
问题信息:
uuid 长度设置为200,同步记录中 uuid 长度为232。
Reason: column_name[uuid], the length of input is too long than schema. first 32 bytes of input str: [0000000000000BB4E595527BE******] schema length: 200; actual length: 232; . src line [];
问题原因:
DLC 的 Spark 引擎在计算字符长度时,中文字符占一个字符长度,而 Doris 计算长度时,将中文当成 UTF-8 编译,占3个字符长度。两端计算长度不统一可能导致临界长度的字符串触发预警。
解决方案:
在 DLC 源端修改脏数据。
增大 Doris 表对 uuid 长度的限制。
6. 写入报错:字段 xxx 不允许写入空值
问题信息:
Reason: column(xxx) values is null while columns is not nullable
问题原因: 目标表字段设置为不允许为空,但同步写入的数据为空值。
解决方案:
在源端修改脏数据。
修改目标表该字段属性允许为空。
Doris/TCHouse-D 脚本 Demo
如果您配置离线任务时,使用脚本模式 的方式进行配置,您需要在任务脚本中按照脚本的统一格式要求编写脚本中的 reader 参数 和 writer 参数 。
{"core": {"transport": {"channel": {"speed": {"byte": -1}}}},"job": {"content": [{"reader": {"parameter": {"password": "******","column": ["id","name"],"connection": [{"jdbcUrl": ["jdbc:mysql://ip:8030/source_database"],"table": ["source_table"]}],"where": "id>10","splitPk": "id","username": "root"},"name": "dorisreader"},"transformer": [],"writer": {"parameter": {"postSql": [""],"swapTableName": "sink_table_timestamp","column": ["id","name"],"swapTable": "true","timeZone": "+08:00","database": "sink_database","password": "******","beLoadUrl": ["ip:9030","ip:9030","ip:9030"],"labelPrefix": "","maxBatchByteSize": 104857600,"lineDelimiter": "\\n","jdbcUrl": "jdbc:mysql://ip:9030/sink_database","connectTimeout": -1,"table": "sink_table","maxBatchRows": 500000,"username": "root","preSql": [""]},"name": "doriswriter"}}],"setting": {"errorLimit": {"record": 0},"speed": {"byte": -1,"channel": 1}}}}



