本文档将手把手的指引您完成 MySQL 实时同步至 TChouse-D 的流程操作,包括整库迁移和单表同步。大体的流程如下:
一、数据源兼容情况。
二、MySQL 环境准备。
三、TChouse-D 环境准备。
四、项目配置及资源组准备。
五、实时整库:MySQL 同步至 TChouse-D 配置步骤。
六、实时单表:MySQL 同步至 TChouse-D 配置步骤。
七、实时节点高级参数。
八、常见问题。
一、数据源兼容情况
MySQL 数据源
如果您想使用 MySQL 进行实时数据同步操作,需要先确认 MySQL 数据源版本支持情况、使用限制及支持的数据类型转换。
支持版本
目前数据集成已支持 MySQL 单表及整库级实时读取,使用实时读取能力需遵循以下版本限制:
类型 | 版本 | Driver |
MySQL | 5.6,5.7,8.0.x | JDBC Driver:8.0.21 |
RDS MySQL | 5.6,5.7, 8.0.x | |
PolarDB MySQL | 5.6,5.7,8.0.x | |
Aurora MySQL | 5.6,5.7,8.0.x | |
MariaDB | 10.x | |
PolarDB X | 2.0.1 | |
使用限制
需要开启 Binlog 日志,仅支持同步 MySQL 服务器 Binlog 配置格式为 ROW。
无主键的表由于无法保证 exactly once 可能会有数据重复,因此实时同步任务要保证有主键。
不支持 XA ROLLBACK,实时同步的任务不会针对 XA PREPARE 的数据进行回滚的操作,若要处理 XA ROLLBACK 场景,需要手动将 XA ROLLBACK 的表从实时同步任务中移除,再添加表后重新进行同步。
设置 MySQL 会话超时:
当为大型数据库制作初始一致快照时,您建立的连接可能会在读取表时超时。您可以通过在 MySQL 配置文件中配置 interactive_timeout 和 wait_timeout 来防止这种行为。
interactive_timeout:服务器在关闭交互式连接之前等待其活动的秒数。请参阅 MySQL :: MySQL 8.0 Reference Manual :: 7.1.8 Server System Variables。
wait_timeout:服务器在关闭非交互式连接之前等待其活动的秒数。请参阅 MySQL :: MySQL 8.0 Reference Manual :: 7.1.8 Server System Variables。
MySQL 读取数据类型转换
MySQL 读取支持的数据类型以及内部映射字段如下所示(在处理 MySQL 时,会先将 MySQL 数据源的数据类型和数据处理引擎的数据类型做映射):
字段类型 | 是否支持 | 内部映射字段 | 备注 |
TINYINT | 是 | TINYINT | TINYINT(1) 映射到 BOOLEAN 需要增加选项支持 TINYINT(1) 可以映射到 bool 或者 tinyint |
SMALLINT | 是 | SMALLINT | - |
TINYINT_UNSIGNED | 是 | SMALLINT | - |
TINYINT_UNSIGNED_ZEROFILL | 是 | SMALLINT | - |
INT | 是 | INT | - |
INTEGER | 是 | INT | - |
YEAR | 是 | INT | - |
MEDIUMINT | 是 | INT | - |
SMALLINT_UNSIGNED | 是 | INT | - |
SMALLINT_UNSIGNED_ZEROFILL | 是 | INT | - |
BIGINT | 是 | LONG | - |
INT_UNSIGNED | 是 | LONG | - |
MEDIUMINT_UNSIGNED | 是 | LONG | - |
MEDIUMINT_UNSIGNED_ZEROFILL | 是 | LONG | - |
INT_UNSIGNED_ZEROFILL | 是 | LONG | - |
BIGINT_UNSIGNED | 是 | DECIMAL | DECIMAL(20,0) |
BIGINT_UNSIGNED_ZEROFILL | 是 | DECIMAL | DECIMAL(20,0) |
SERIAL | 是 | DECIMAL | DECIMAL(20,0) |
FLOAT | 是 | FLOAT | - |
FLOAT_UNSIGNED | 是 | FLOAT | - |
FLOAT_UNSIGNED_ZEROFILL | 是 | FLOAT | - |
DOUBLE | 是 | DOUBLE | - |
DOUBLE_UNSIGNED | 是 | DOUBLE | - |
DOUBLE_UNSIGNED_ZEROFILL | 是 | DOUBLE | - |
DOUBLE_PRECISION | 是 | DOUBLE | - |
DOUBLE_PRECISION_UNSIGNED | 是 | DOUBLE | - |
ZEROFILL | 是 | DOUBLE | - |
REAL | 是 | DOUBLE | - |
REAL_UNSIGNED | 是 | DOUBLE | - |
REAL_UNSIGNED_ZEROFILL | 是 | DOUBLE | - |
NUMERIC | 是 | DECIMAL | 采用用户数据库实际的精度 p<=38 映射到 DECIMAL 38 < p <= 65 时映射到 String |
NUMERIC_UNSIGNED | 是 | DECIMAL | 采用用户数据库实际的精度 p<=38 映射到 DECIMAL 38 < p <= 65 时映射到 String |
NUMERIC_UNSIGNED_ZEROFILL | 是 | DECIMAL | 采用用户数据库实际的精度 p<=38 映射到 DECIMAL 38 < p <= 65 时映射到 String |
DECIMAL | 是 | DECIMAL | 采用用户数据库实际的精度 p<=38 映射到 DECIMAL 38 < p <= 65 时映射到 String |
DECIMAL_UNSIGNED | 是 | DECIMAL | 采用用户数据库实际的精度 p<=38 映射到 DECIMAL 38 < p <= 65 时映射到 String |
DECIMAL_UNSIGNED_ZEROFILL | 是 | DECIMAL | 采用用户数据库实际的精度 p<=38 映射到 DECIMAL 38 < p <= 65 时映射到 String |
FIXED | 是 | DECIMAL | 采用用户数据库实际的精度 p<=38 映射到 DECIMAL 38 < p <= 65 时映射到 String |
FIXED_UNSIGNED | 是 | DECIMAL | 采用用户数据库实际的精度 p<=38 映射到 DECIMAL 38 < p <= 65 时映射到 String |
FIXED_UNSIGNED_ZEROFILL | 是 | DECIMAL | 采用用户数据库实际的精度 p<=38 映射到 DECIMAL 38 < p <= 65 时映射到 String |
BOOLEAN | 是 | BOOLEAN | - |
DATE | 是 | DATE | - |
TIME | 是 | TIME | - |
DATETIME | 是 | TIMESTAMP | - |
TIMESTAMP | 是 | TIMESTAMP | - |
CHAR | 是 | STRING | - |
JSON | 是 | STRING | - |
BIT | 是 | STRING | BIT(1) 映射到 BOOLEAN |
VARCHAR | 是 | STRING | - |
TEXT | 是 | STRING | - |
BLOB | 是 | STRING | - |
TINYBLOB | 是 | STRING | - |
TINYTEXT | 是 | STRING | - |
MEDIUMBLOB | 是 | STRING | - |
MEDIUMTEXT | 是 | STRING | - |
LONGBLOB | 是 | STRING | - |
LONGTEXT | 是 | STRING | - |
VARBINARY | 是 | STRING | - |
GEOMETRY | 是 | STRING | - |
POINT | 是 | STRING | - |
LINESTRING | 是 | STRING | - |
POLYGON | 是 | STRING | - |
MULTIPOINT | 是 | STRING | - |
MULTILINESTRING | 是 | STRING | - |
MULTIPOLYGON | 是 | STRING | - |
GEOMETRYCOLLECTION | 是 | STRING | - |
ENUM | 是 | STRING | - |
BINARY | 是 | BINARY | BINARY(1) |
SET | 否 | - |
Doris/TChouse-D 环境准备与数据库配置
支持版本
目前数据集成已支持 Doris 单表及整库实时写入,使用实时同步能力需遵循以下版本限制:
类型 | 版本 |
Doris | 0.15、1.x |
使用限制
Doris 支持 [DUPLICATE KEY|UNIQUE KEY|AGGREGATE KEY] 三种数据模型,若需以 Upsert 方式写入 Doris,需要确保数据模型为 UNIQUE KEY,详情请参见 数据模型 - Apache Doris。
来源表有主键时自动创建的 Doris 目标表为 UNIQUE KEY;来源表无主键时自动创建的 Doris 目标表为 DUPLICATE KEY。
二、MySQL 环境准备
确认 MySQL 版本
数据集成对 MySQL 版本有要求,查看当前待同步的 MySQL 是否符合版本要求。您可以在 MySQL 数据库通过如下语句查看当前 MySQL 数据库版本。
select version();
设置 MySQL 服务器权限
您必须定义一个对 Debezium MySQL 连接器监控的所有数据库具有适当权限的 MySQL 用户。
1. 创建 MySQL 用户(可选)
mysql> CREATE USER 'user'@'localhost' IDENTIFIED BY 'password';
2. 向用户授予所需的权限:
在实时数据同步的情况下,该账号必须拥有数据库的 SELECT、REPLICATION SLAVE 和 REPLICATION CLIENT 权限。执行命令可以参考下面:
mysql> GRANT SELECT, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'user'@'localhost' IDENTIFIED BY 'password';
说明:
启用 scan.incremental.snapshot.enabled 时不再需要 RELOAD 权限(默认启用)。
3. 刷新用户的权限:
mysql>FLUSH PRIVILEGES;
开启 MySQL Binlog
1. 检查 binlog 是否开启
show variables like "log_bin"
返回结果为 ON 时,表示已经开启 Binlog, 如果为备库,使用如下语句:
show variables like "log_slave_updates";
如果返回为 ON 时,表示已经开启 Binlog,如果已经开启 Binlog,可跳过下面流程。
2. 开启 Binlog
如果确认没有开启 Binlog,则需要进行以下操作。
对于腾讯云实例 MySQL / TDSQL-C MySQL,默认开启了 binlog。
对于开源 MySQL,参考官方文档开启 binlog。
3. binlog_row_image
实时同步仅支持同步 MySQL 服务器 binlog_row_image 配置格式为 FULL or full。
3.1 使用如下语句查询 binlog_row_image 的使用格式。
show variables like "binlog_row_image";
3.2 如果返回非 FULL/full 请修改 binlog_row_image:
对于开源 MySQL 参考官方文档:MySQL :: MySQL 8.0 Reference Manual :: 19.1.6.4 Binary Logging Options and Variables。
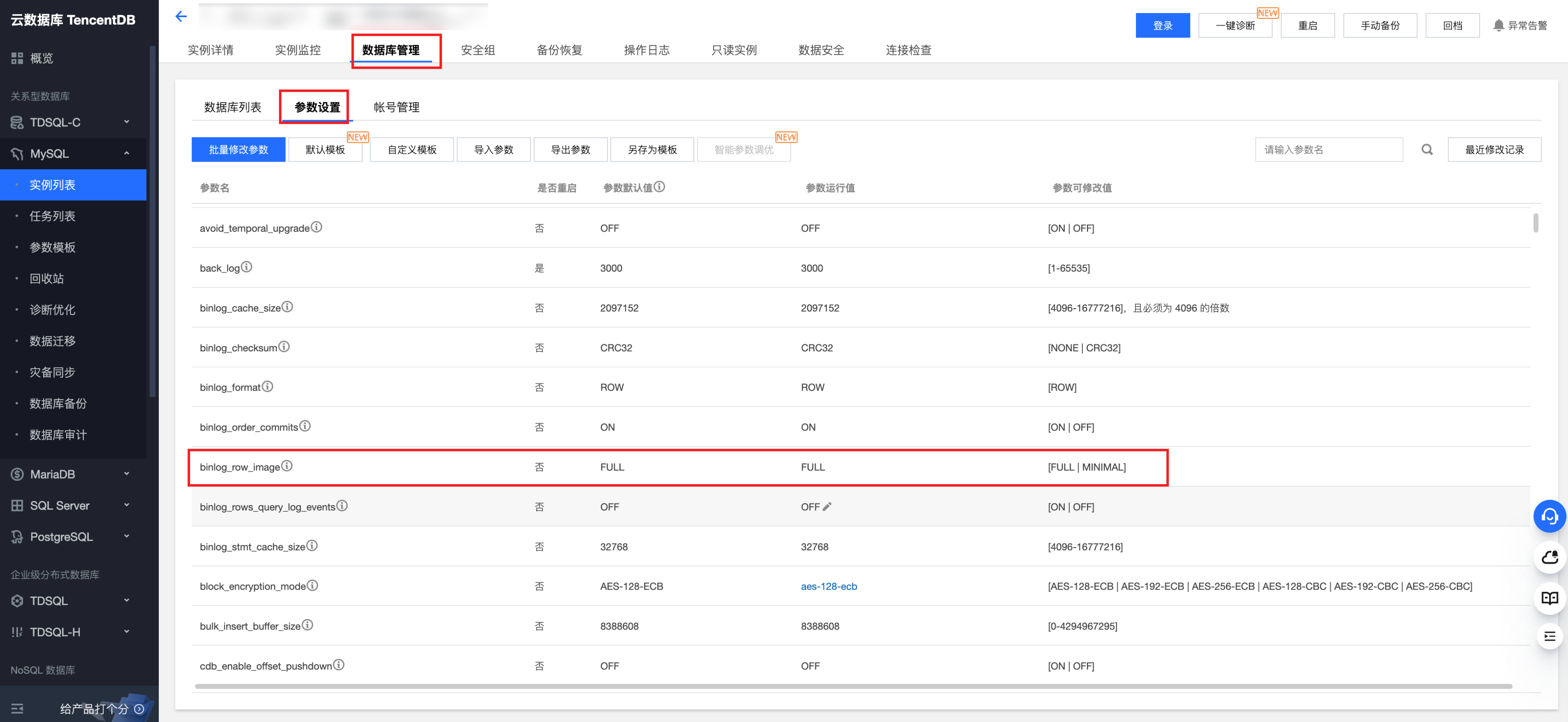
对于腾讯云实例 MySQL / TDSQL-C MySQL:
登录腾讯云 MySQL / TDSQL-C MySQL 控制台,找到要开启 Binlog 的实例,单击进入该实例的详细信息页面。
在上面选项卡中选择数据库管理,找到参数设置选项卡。
在参数设置选项卡中,找到 binlog_row_image 参数,将其设置为“FULL”。
开启 GTIDs(可选)
GTID(Global Transaction Identifier, 全局事务标识),用于在 binlog 中唯一标识一个事务,使用 GTID 可以避免事务重复执行导致数据混乱或者主从不一致。
1. 检查是否开启了 GTID
show global variables like '%GTID%';
返回结果类似如下,证明已经开启 GTID。
+--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | enforce_gtid_consistency | ON | | gtid_mode | ON | +--------------------------+-------+
2. 开启 GTID
对于开源 MySQL,参考官方文档 MySQL :: MySQL 8.0 Reference Manual :: 19.1.4.2 Enabling GTID Transactions Online。
对于腾讯云实例 MySQL / TDSQL-C MySQL,默认为开启,不支持关闭。
添加腾讯云 MySQL 数据库安全组
安全组是一种有状态的包含过滤功能的虚拟防火墙,用于设置单台或多台云数据库的网络访问控制,是腾讯云提供的重要的网络安全隔离手段。如果您不配置安全组,在 WeData 中配置 MySQL 数据源的时候可能会出现连通性测试失败的情况。具体操作可参见 管理云数据库安全组。
118.89.220.0/24, 139.199.116.0/24, 140.143.68.0/24, 152.136.131.0/24, 81.70.150.0/24, 81.70.161.0/24, 81.70.195.0/24, 81.70.198.0/24, 82.156.22.0/24, 82.156.221.0/24, 82.156.23.0/24, 82.156.24.0/24, 82.156.27.0/24, 82.156.82.0/24, 82.156.84.0/24, 82.157.119.0/24
三、TChouse-D 环境准备
数据库环境配置
1. 检查 Doris/TChouse-D 数据库网络和数据集成资源组网络连通性。
参考数据源配置中的连通性测试,确保数据集成资源组可正常访问 Doris/TChouse-D 数据库。
2. 检查待写入 Doris/TChouse-D 表的数据模型。
Doris/TChouse-D 写入支持 Append/Upsert 两种模式,若想以 Upsert 模式写入,需要确保 Doris/TChouse-D 数据模型为 Unique key。具体可在 SQL 客户端执行如下 SQL :
show create table example_db.table_hash;// 执行上述 SQL 后的结果CREATE TABLE example_db.table_hash(k1 BIGINT,k2 LARGEINT,v1 VARCHAR(2048),v2 SMALLINT DEFAULT "10")UNIQUE KEY(k1, k2)DISTRIBUTED BY HASH (k1, k2)// 若为 Unique key 模型,会在结果中出现关键词:UNIQUE KEY
3. 创建 Doris/TChouse-D 表。
创建明细模型表。
CREATE TABLE example_db.table_hash(k1 TINYINT,k2 DECIMAL(10, 2) DEFAULT "10.5",k3 CHAR(10) COMMENT "string column",k4 INT NOT NULL DEFAULT "1" COMMENT "int column")COMMENT "my first table"DISTRIBUTED BY HASH(k1)
创建主键唯一模型表。
CREATE TABLE example_db.table_hash(k1 BIGINT,k2 LARGEINT,v1 VARCHAR(2048),v2 SMALLINT DEFAULT "10")UNIQUE KEY(k1, k2)DISTRIBUTED BY HASH (k1, k2)
四、项目配置及资源组准备
在正式配置同步任务之前,需要创建一个项目。如下基于一个全新的环境讲解相关步骤,如果您已经创建了项目成员或完成了项目创建可以跳过。
项目创建
如果您还没有在数据开发治理平台 WeData 创建过项目空间,在进行数据同步任务之前需完成项目创建。
1. 主账号人员进入 CAM 控制台添加子账号,可以参考 准备 CAM 子账号,创建后,该成员便可以使用设置的子账号登录 WeData 大数据平台。
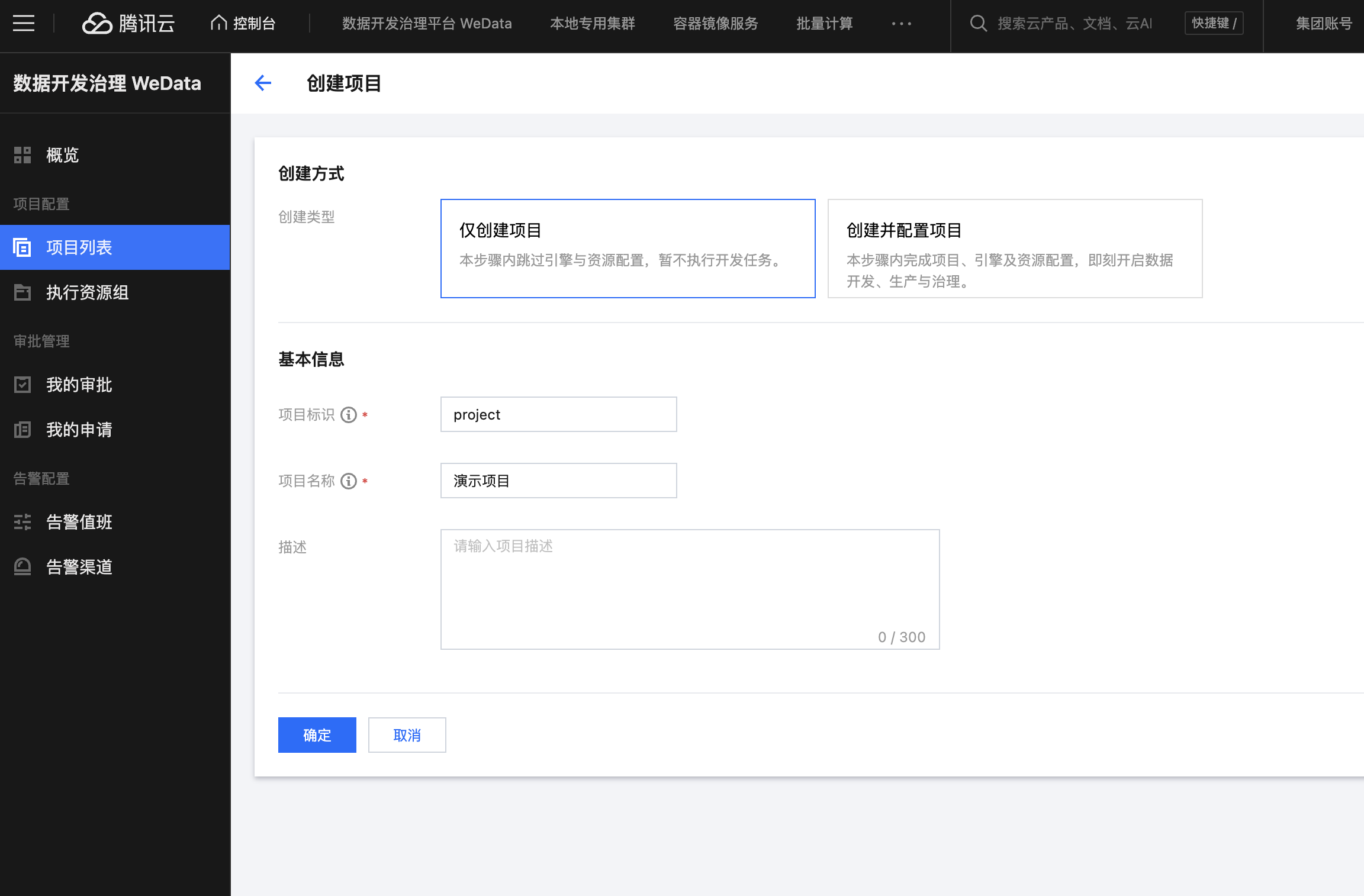
2. 创建项目空间,需要进入 WeData 首页,单击项目列表 > 创建项目。 如果只是做数据集成,此处可以选择仅创建项目,输入项目标识和名称即可。
添加成员
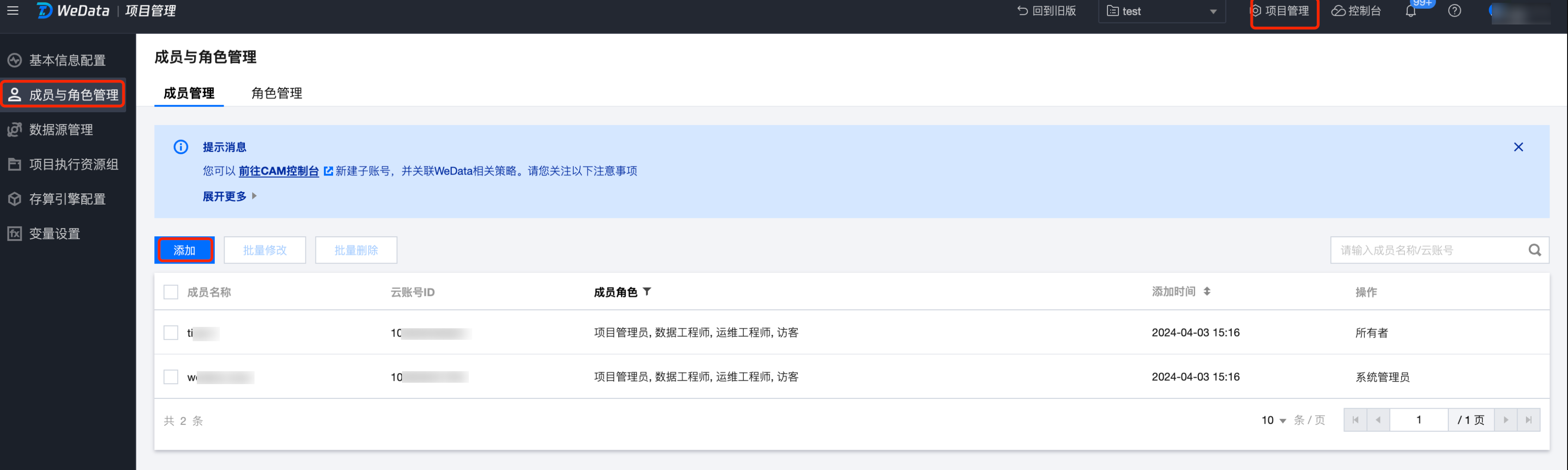
1. 单击项目管理 > 成员与角色管理,进入成员与角色管理界面,单击添加按钮。
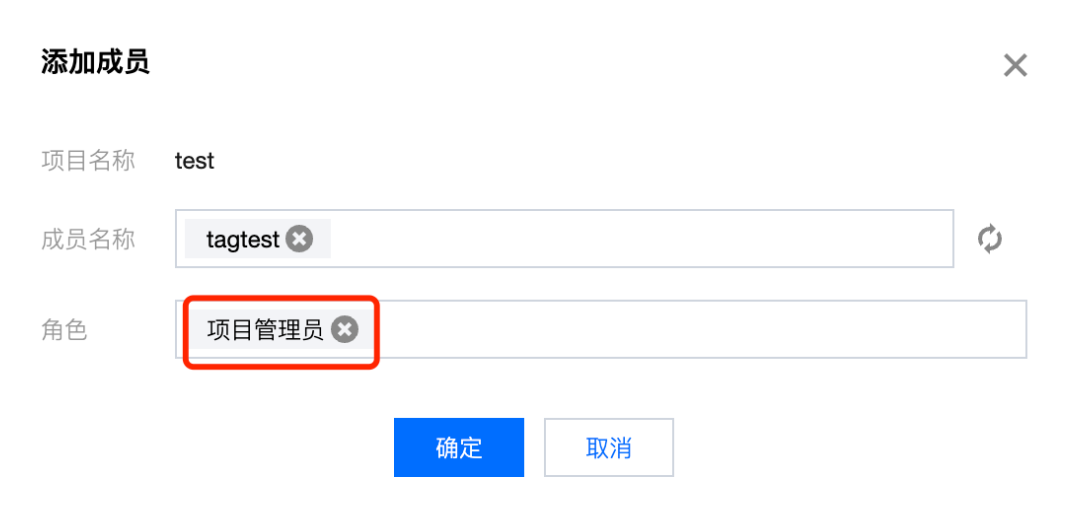
2. 在添加成员界面,为新创建的成员设置所需角色,设置完成后,该成员便可以进入项目了。
资源组准备
确认资源组是否配置
在正式进行数据集成任务之前,请确认您所在的项目是否已配备集成资源。
如果提示未配置集成资源,则无法正常运行数据集成任务。
当您创建完新项目,在执行资源组这一列会显示集成资源未配置,只需要前往 WeData 首页执行资源组 > 集成资源组为新项目关联资源即可。
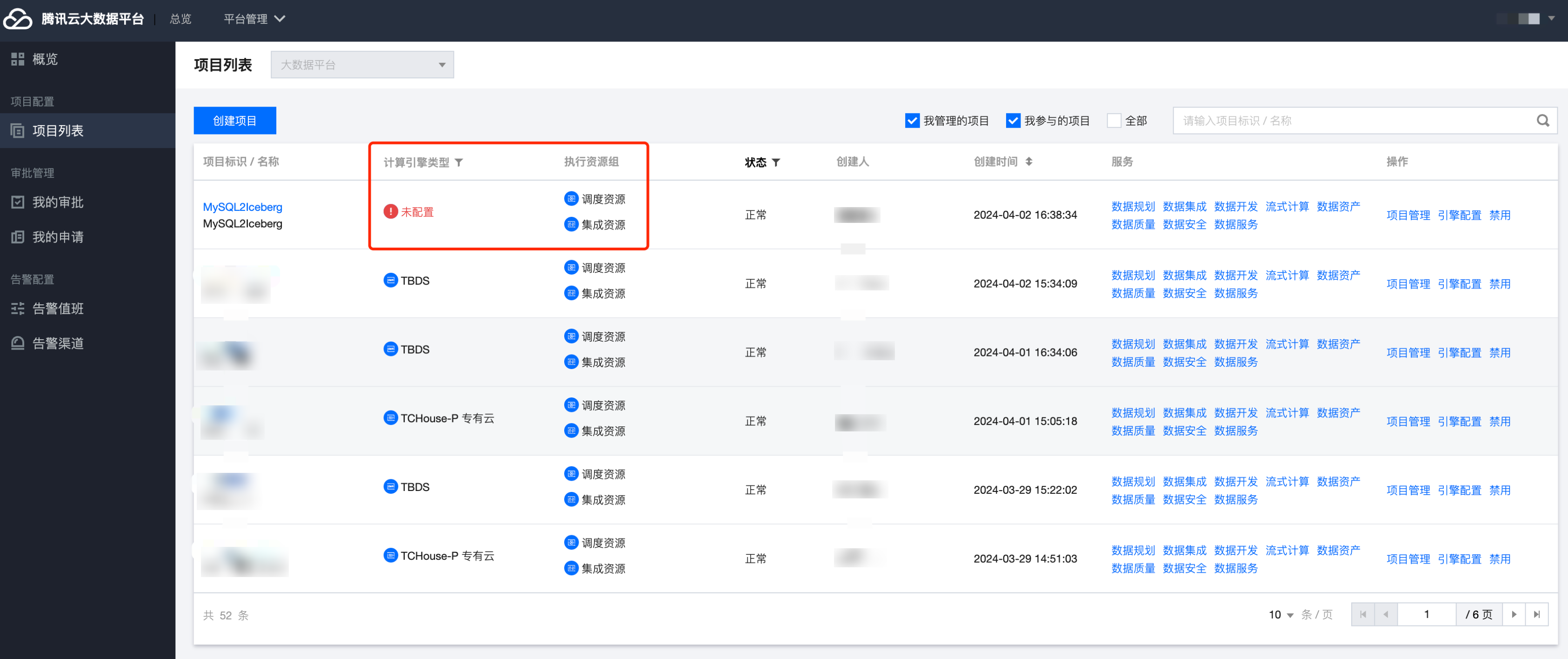
进入集成资源组界面,点击对应资源组后的关联项目。
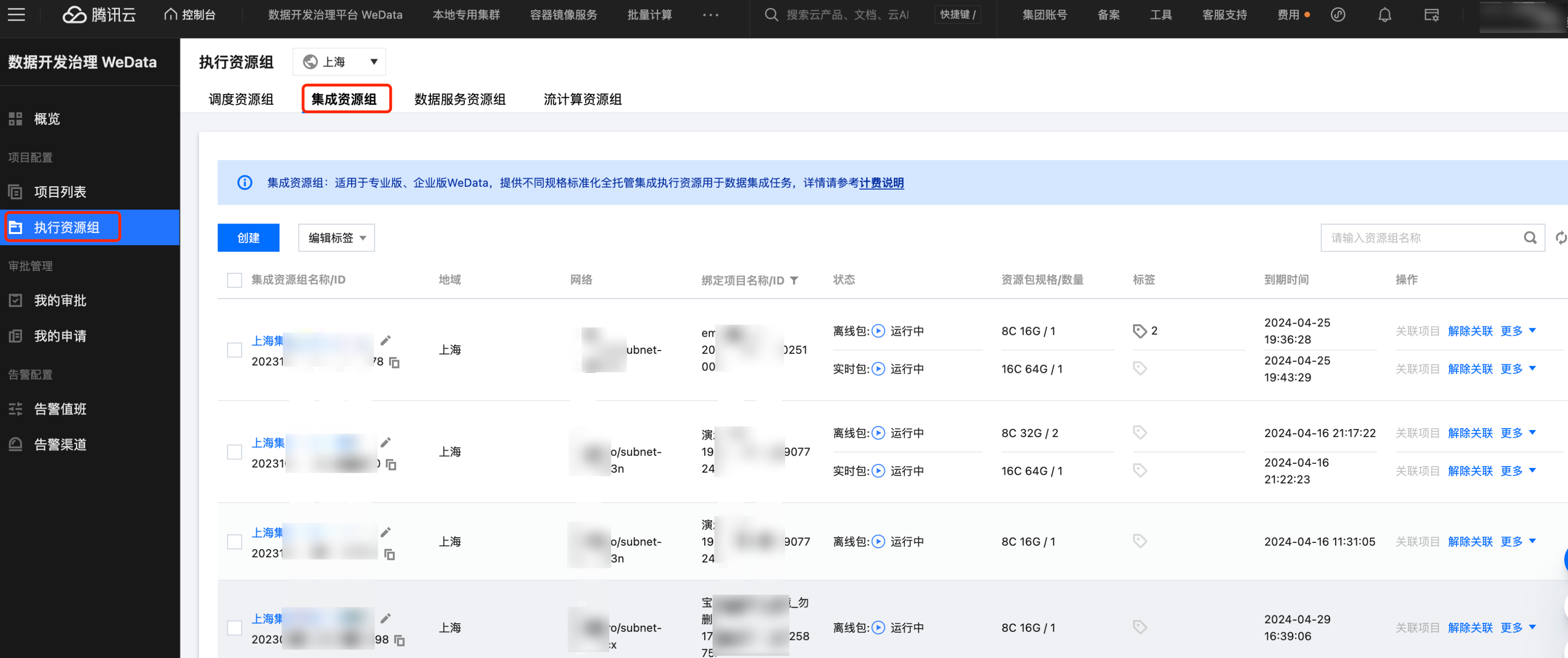
集成资源组购买
如果发现目前没有集成资源组,需要前往购买。集成资源组是在运行数据集成任务时专享使用到的计算资源,本资源主要以资源组形式展现。在配置同步任务之前需要确认是否购买了数据集成资源组。详情请参见 配置集成资源组。
网络连通性确认
需要保证数据源网络(包括读端、写端)与数据集成资源组之间网络互通,且资源不可因为白名单限制等原因被拒绝访问,否则无法完成数据传输同步。
数据集成资源组内包含的机器资源默认需处于同一 VPC 网络环境下:
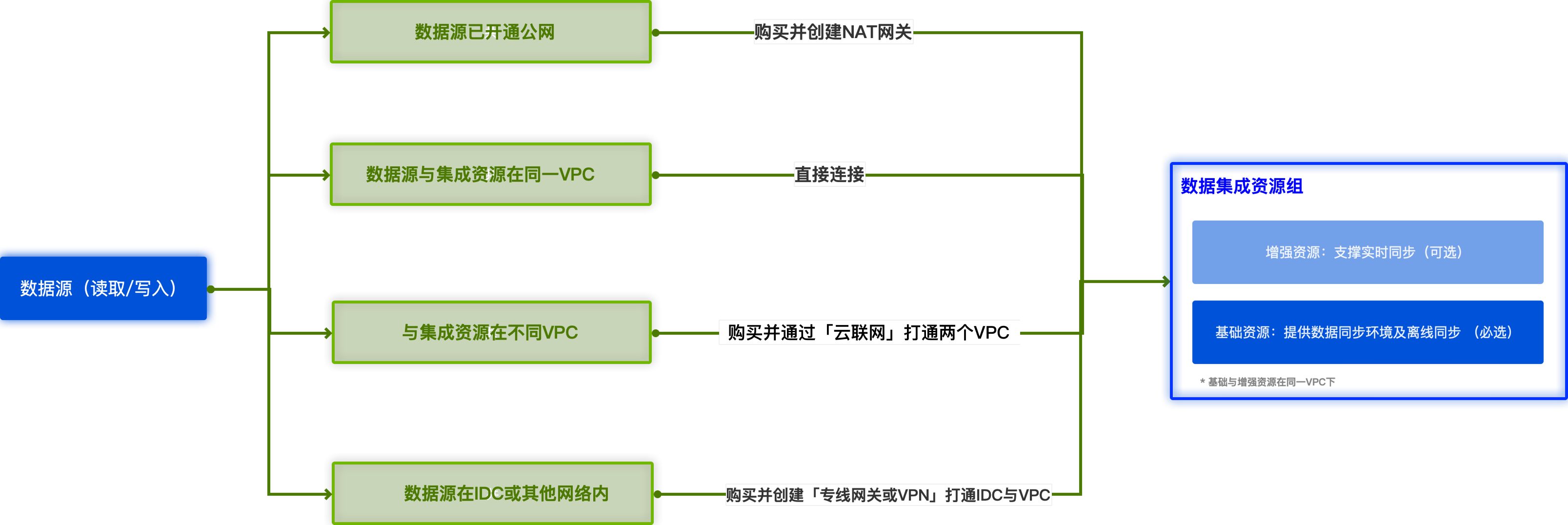
若数据源处于 VPC 内:
若与集成资源位于同一 VPC:可直接使用。
若与集成资源位于不同 VPC:需购买云联网打通集成与数据源所在 VPC。
说明:
数据源配置
MySQL 数据源配置
进入配置数据源界面,MySQL 数据源支持云实例和连接串两种连接方式。
单击项目管理 > 数据源管理 > 新建数据源 > 选择 MySQL 数据源。(也可以直接选择腾讯云MySQL数据源类型)
通过连接串创建数据源。
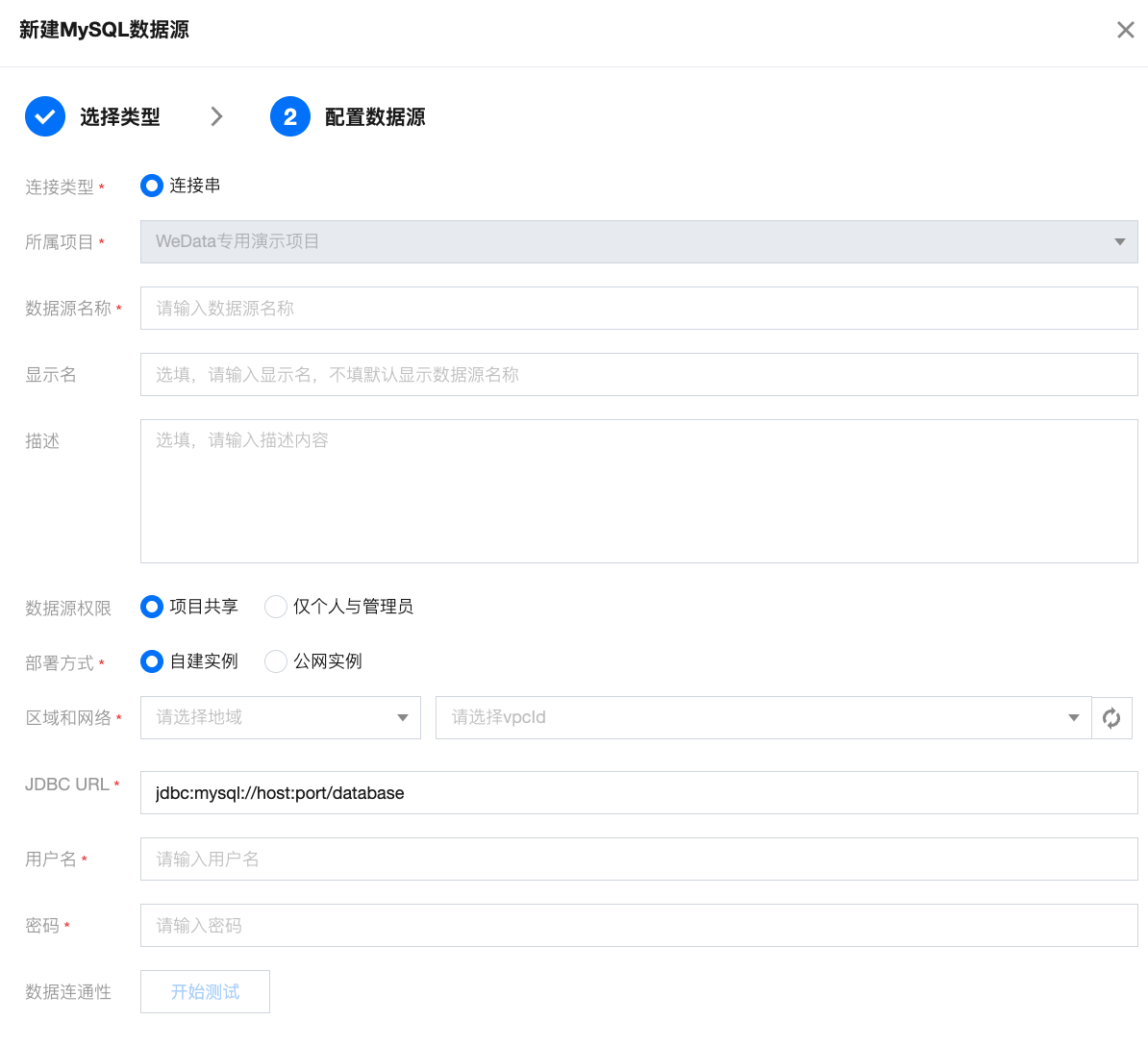
参数说明如下:
参数 | 说明 |
数据源名称 | 新建的数据源的名称,由用户自定义且不可为空。命名以字母开头,可包含字母、数字、下划线。长度在20字符以内。 |
描述 | 选填,对本数据源的描述。 |
数据源权限 | 项目共享表示当前数据源项目所有成员均可使用 ,仅个人和管理员表示改数据源仅创建人和项目管理员可用。 |
部署方式 | 支持自建实例、公网实例两种部署方式,其中自建实例为在腾讯云服务器上部署的数据源实例,公网实例为在客户本地IDC或其他云上资源实例,支持通过公网进行访问连接。 |
区域与网络 | 当选择自建实例时,需要选择数据源实例所在地域与 vpcID。 |
JDBC URL | 用于连接 MySQL 数据源实例的连接串信息,包含 host ip、port、数据库名称等信息。 |
数据库名称 | 需要连接的数据库名称。 |
用户名 | 连接数据库的用户名称。 |
密码 | 连接数据库的密码。 |
数据连通性(旧) | 测试是否能够连通所配置的数据库。 说明: 若连通性测试不通过,数据源仍可保存。连通性测试未通过而保存但数据源不可使用。 如果连通性测试不通过,可能是因为 WeData 被数据库所在网络防火墙禁止,需要添加腾讯云 MySQL 数据库安全组,可以参考章节二 添加腾讯云 MySQL 数据库安全组。 2024年春节后新购买的 WeData 默认无此功能,该功能已升级为资源组连通性。 |
资源组连通性(新) | 支持具体资源组与数据源的连通性测试。用户只需保证自身数据源和集成资源组所在VPC网络能通即可,无需做额外的网络打通。 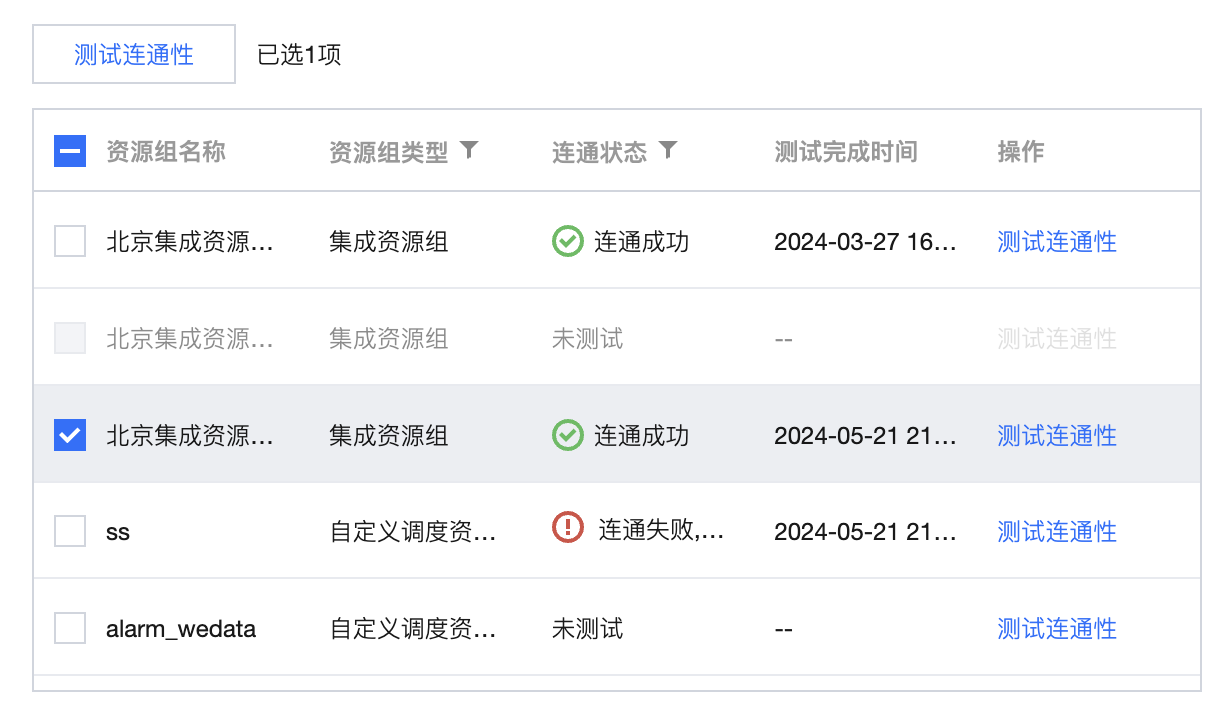 说明: 2024年春节前购买 WeData 的用户无此功能,若需要使用,请联系腾讯侧运维人员处理。 |
TChouse-D数据源配置
WeData 目前支持通过云实例方式引入TChouse-D数据源。
单击项目管理 > 数据源管理 > 新建数据源 > 选择 TChouse-D 数据源。
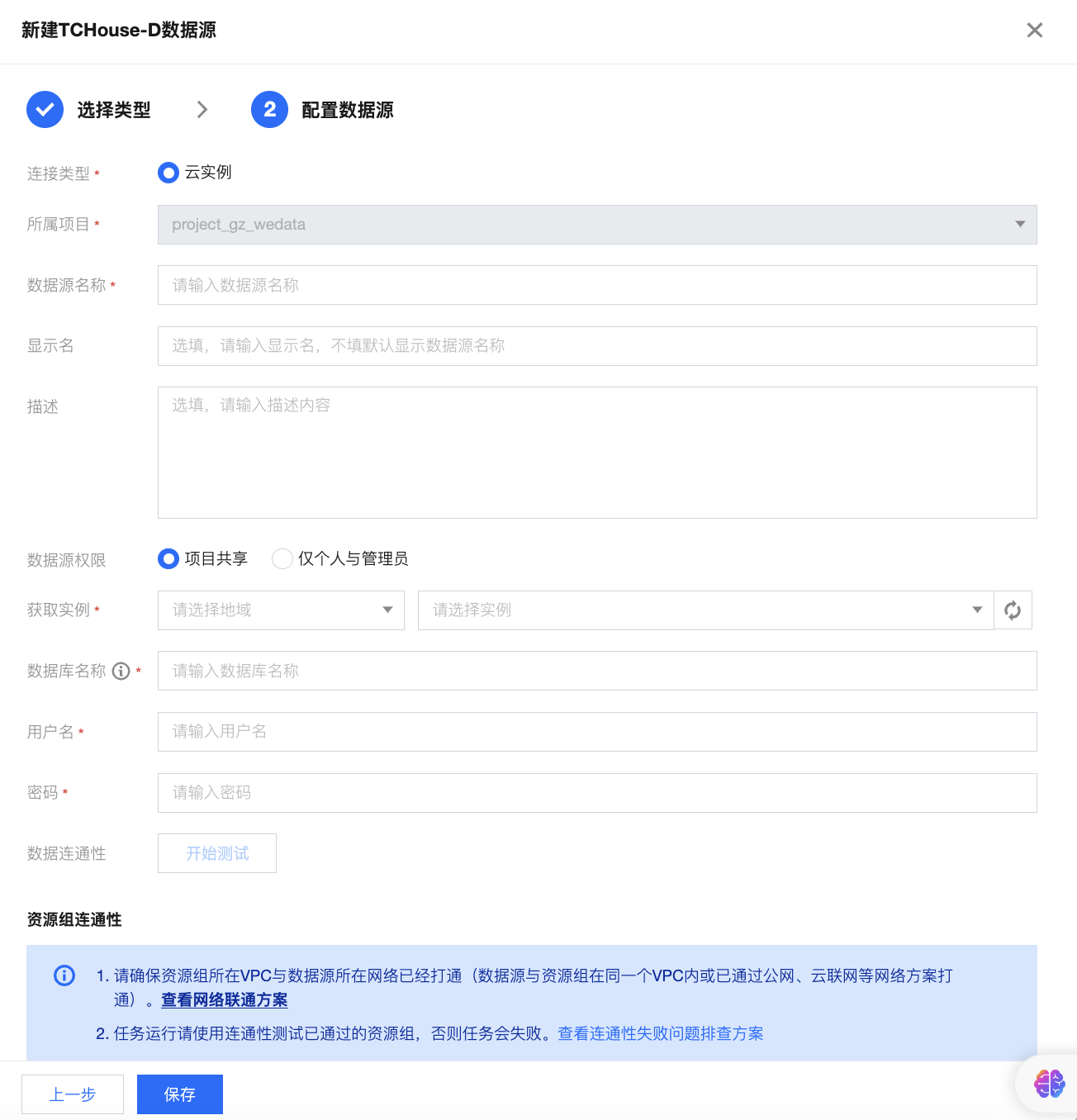
参数说明如下:
参数 | 说明 |
所属项目 | 数据源所属项目名称。 |
数据源名称 | 新建的数据源的名称,由用户自定义且不可为空。命名以字母开头,可包含字母、数字、下划线。长度在20字符以内。 |
显示名 | 选填,数据源显示名,不填默认为数据源名称。 |
描述 | 选填,对本数据源的描述。 |
数据源权限 | 项目共享表示当前数据源项目所有成员均可使用 ,仅个人和管理员表示改数据源仅创建人和项目管理员可用。 |
获取实例 | 先选择地域,再选择该地域下的 EMR 实例,单击右侧刷新按钮可以重新获取该地域下的实例 |
数据库名称 | 需要连接的数据库名称。 |
用户名 | 连接数据库的用户名称。 |
密码 | 连接数据库的密码。 |
数据连通性(旧) | 测试是否能够连通所配置的数据库。 说明: 若连通性测试不通过,数据源仍可保存。连通性测试未通过而保存但数据源不可使用。 如果连通性测试不通过,可能是因为 WeData 被数据库所在网络防火墙禁止,需要添加腾讯云 MySQL 数据库安全组,可以参考章节二 添加腾讯云 MySQL 数据库安全组。 2024年春节后新购买的 WeData 默认无此功能,该功能已升级为资源组连通性。 |
资源组连通性(新) | 支持具体资源组与数据源的连通性测试。用户只需保证自身数据源和集成资源组所在VPC网络能通即可,无需做额外的网络打通。 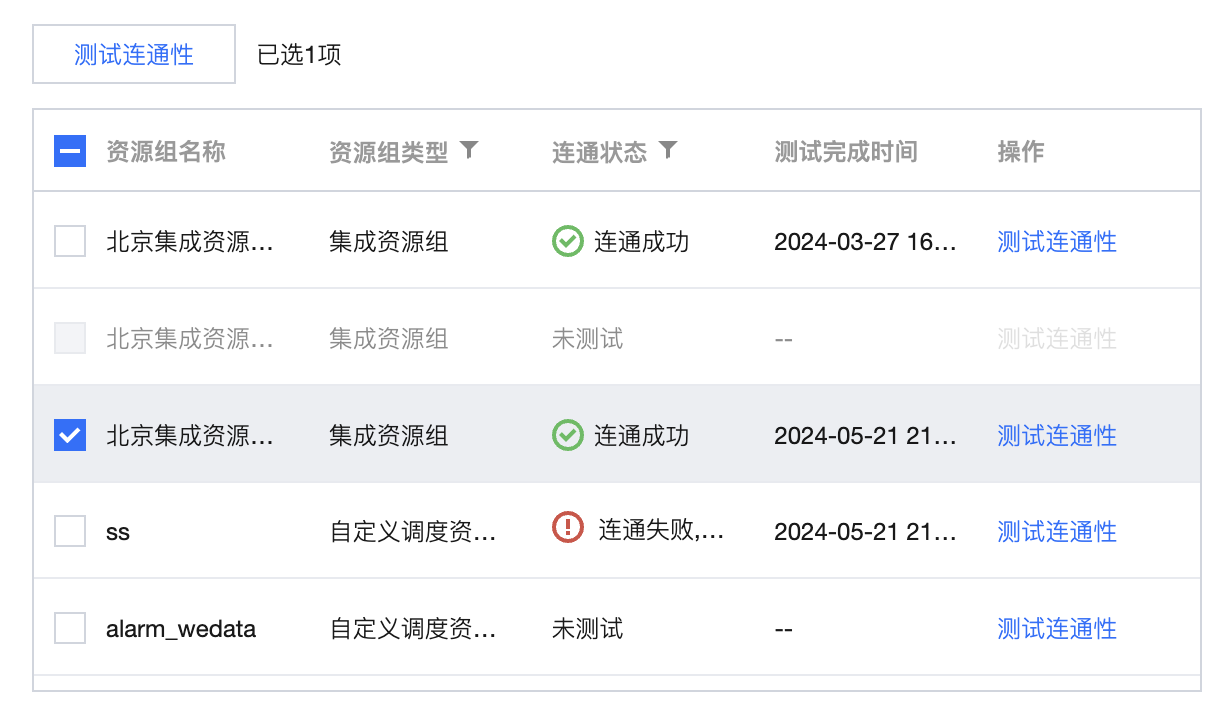 说明: 2024年春节前购买 WeData 的用户无此功能,若需要使用,请联系腾讯侧运维人员处理。 |
五、实时整库:MySQL 同步至 TChouse-D
步骤一:创建整库迁移任务
登录打开 WeData 后,进入数据集成模块,然后单击配置中心 > 实时同步任务页面后,单击新建整库迁移任务。

步骤二:链路选择
在链路选择界面,选择 MySQL > Doris链路,选择完成后,单击下一步。
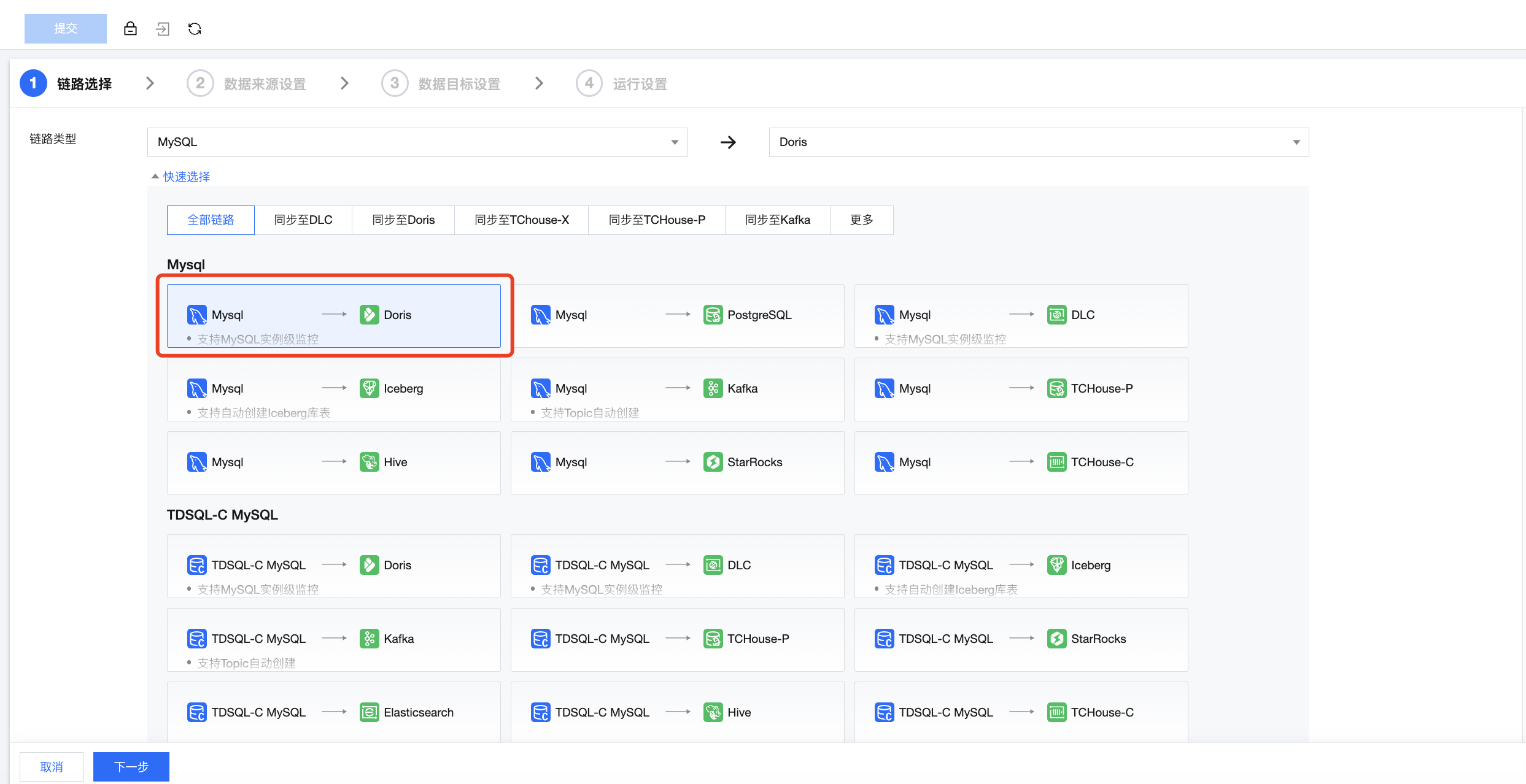
步骤三:数据来源设置
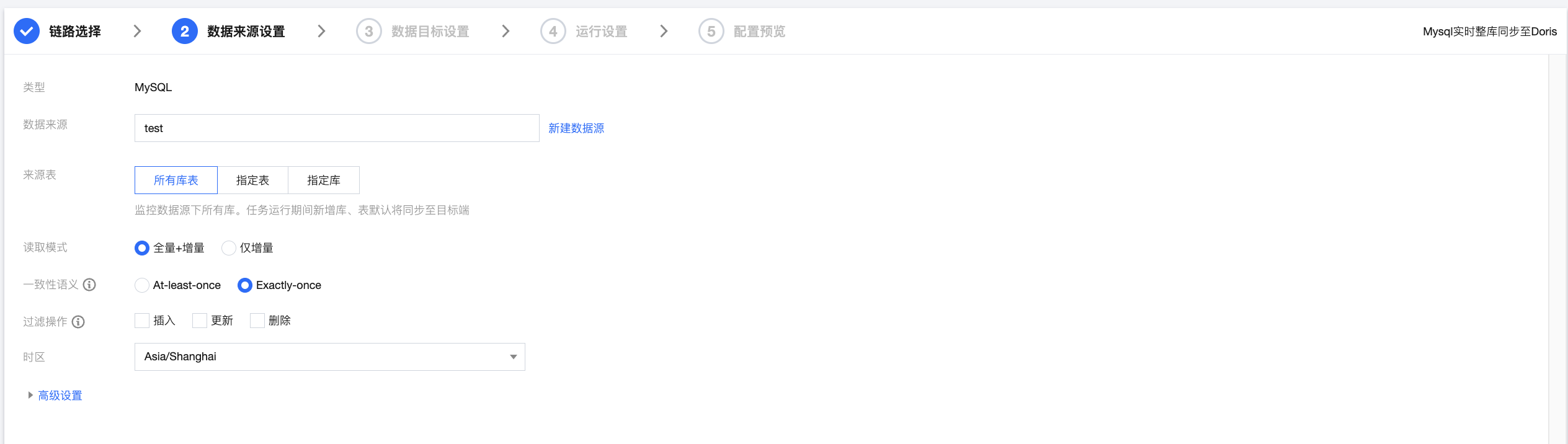
参数 | 说明 |
数据源 | 选择需要同步的 MySQL 数据源。 |
来源表 | 所有库表:监控数据源下所有库。任务运行期间新增库、表默认将同步至目标端。 指定表:此选项下需指定到具体表名称,设置后任务仅同步指定表;若需要新增同步表需停止并重启任务。 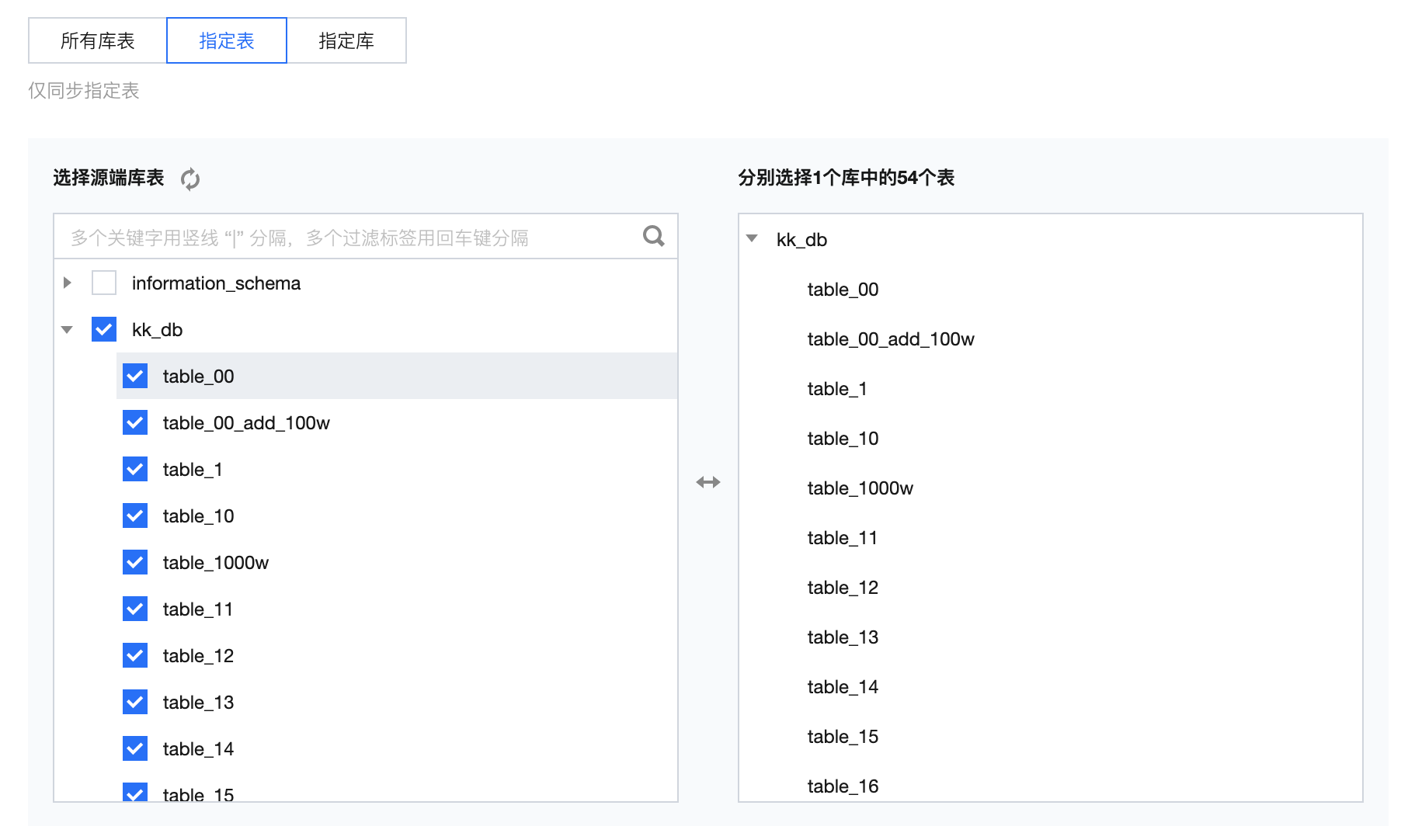 指定库:此选项下需指定具体库名、以表名正则表达式。设置后,任务运行期间符合表名表达式的新增表默认将同步至目标端。 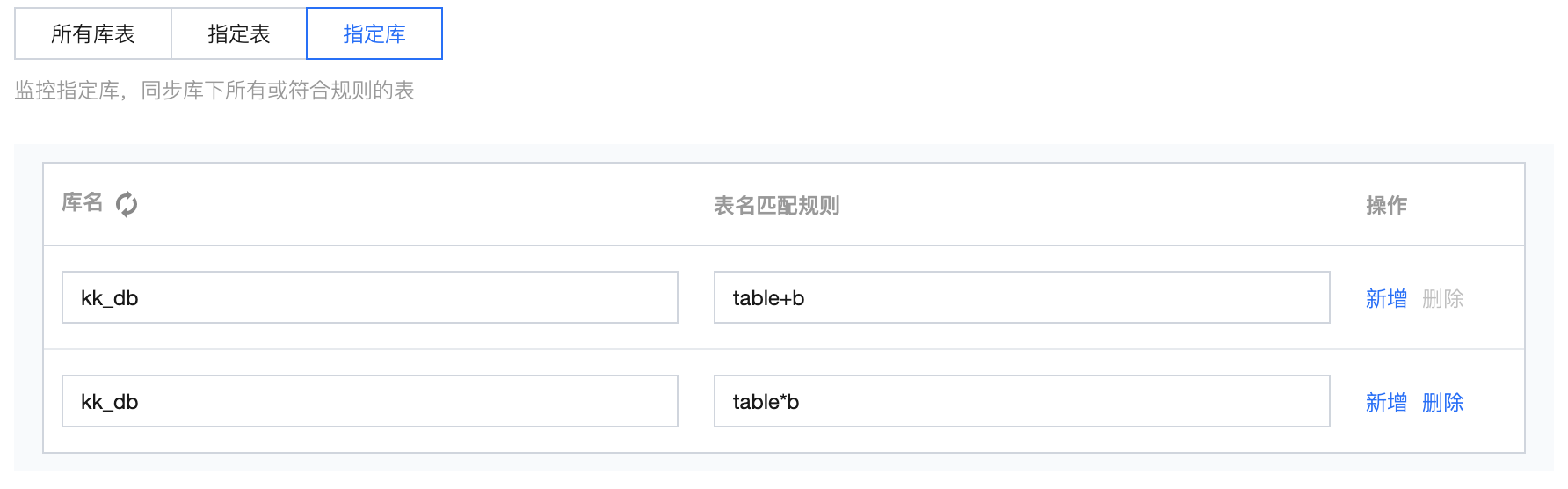 常用表名正则表达式: 单个库的所有表: .* 单个库的部分表: table1|table2|table3 排除某些表的所有表:^(?!(exclude1|exclude2|exclude3)$).*$ 排除某些表但包括以a开头的所有表:^(?!(exclude1|exclude2|exclude3)$)(^a.*)$ |
读取模式 | 全量 + 增量:数据同步分为全量和增量同步阶段,全量阶段完成后任务进入增量阶段。全量阶段将同步库内历史数据,增量阶段从任务启动后 binlog cdc 的位点开始同步。 仅增量:仅从任务启动后的 binlog cdc 位点开始同步数据。 |
过滤操作 | 支持插入、更新和删除三种操作,设置后将不同步指定操作类型的数据。 |
时区 | 设置日志时间所属时区,默认上海。 |
高级设置(可选) | 可根据业务需求配置参数。 |
步骤四:数据目标设置
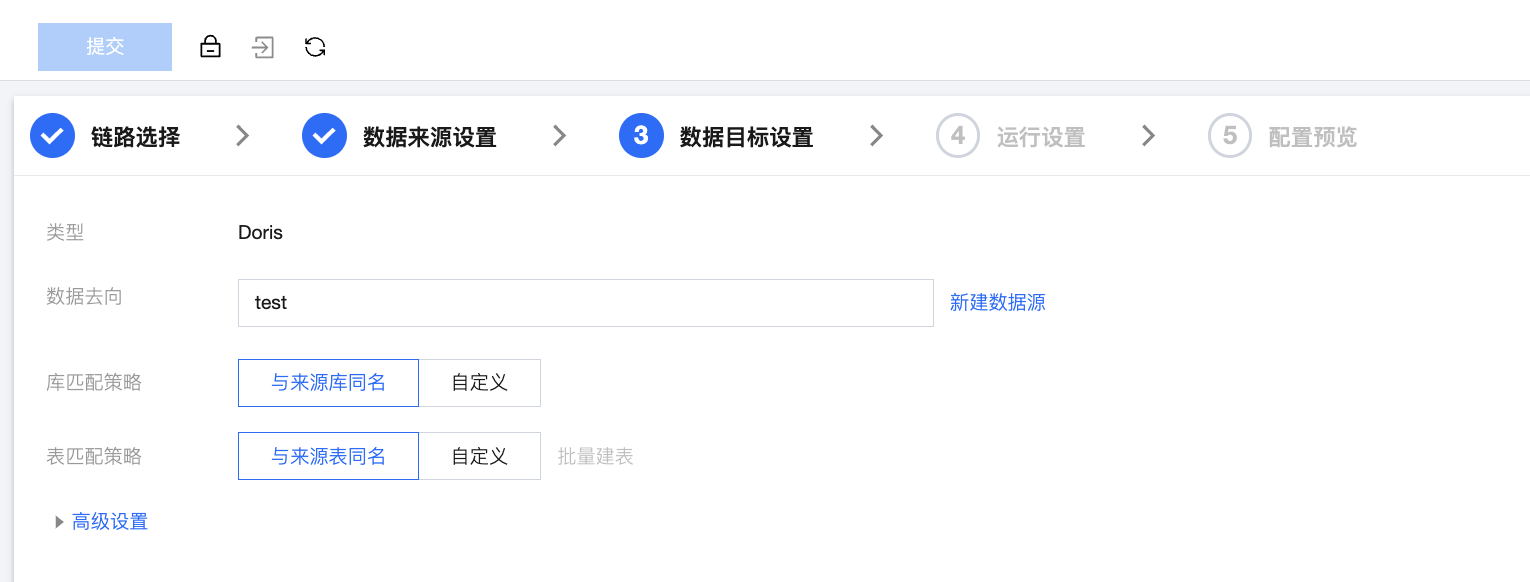
参数 | 说明 |
数据去向 | 选择需要同步的目标数据源。 |
库/表匹配策略 | Doris 中数据库以及数据表对象的名称匹配规则。 |
批量建表 | Doris 目标端支持根据库表匹配策略批量一键建表: 确认键表规则:确认键表信息如数据来源、来源库等,支持预览/编辑表语句。 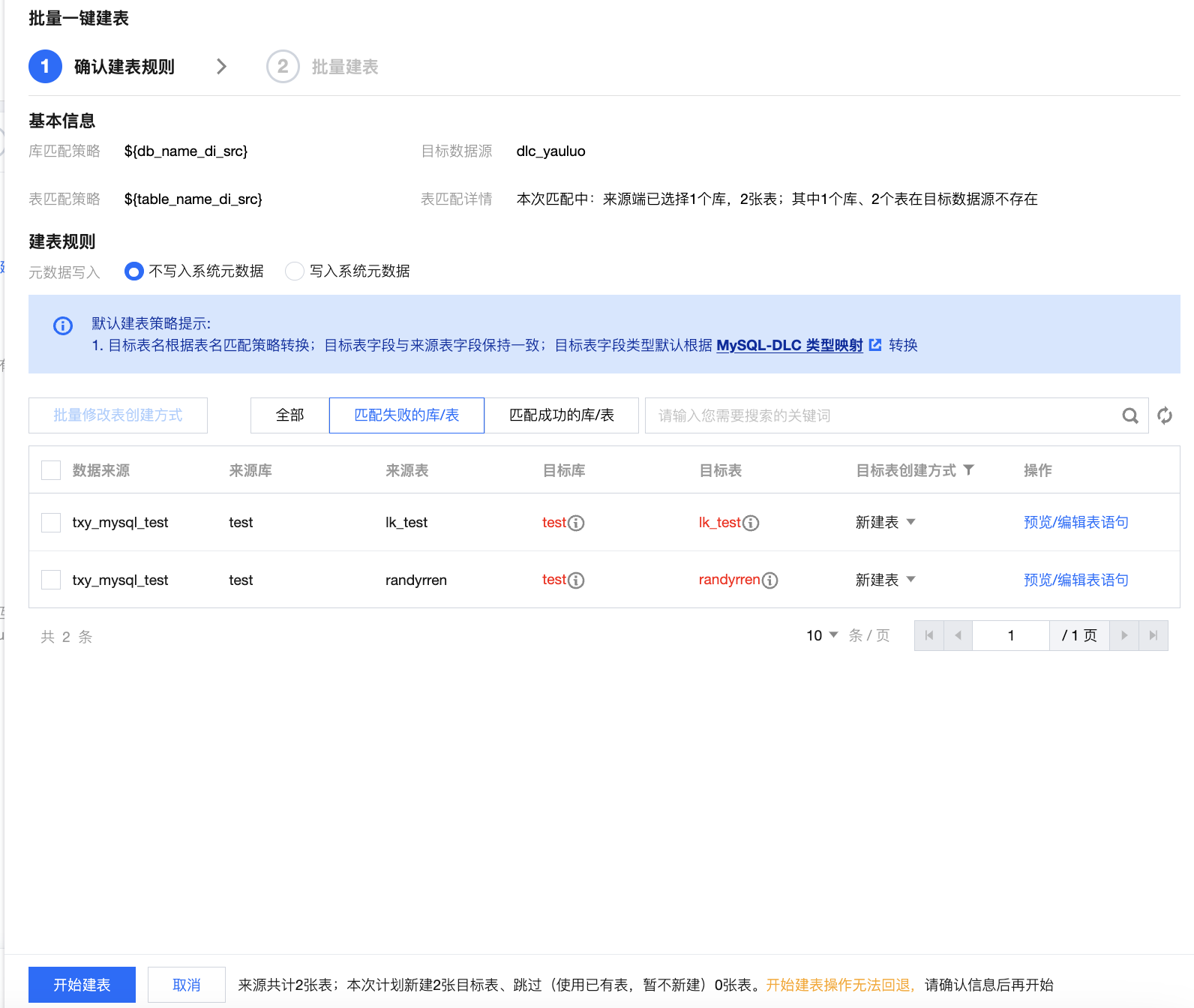 基本信息:展示选择或填写的库匹配策略、表匹配策略、目标数据源、以及表匹配详情。 建表规则: 元数据写入:可以选择是否写入元数据,MySQL > Doris 支持的元数据如下: database_wedata_di (管理参数 database,表示数据库名称) table_wedata_di(管理参数 table,表示数据表名) type_wedata_di (管理参数 type,表示操作类型) ts_wedata_di(管理参数 ts,表示日志时间) processing_time_wedata_di (处理时间,当前系统处理本条记录的机器本地时间) 匹配失败的库/表:展示在目标数据源中根据库表匹配规则未匹配到的库表 匹配成功的库/表:展示在目标数据源中根据库表匹配规则匹配到的库表 预览/编辑表语句:可以通过预览自动生成的建表语句,且能够直接对建表语句进行编辑 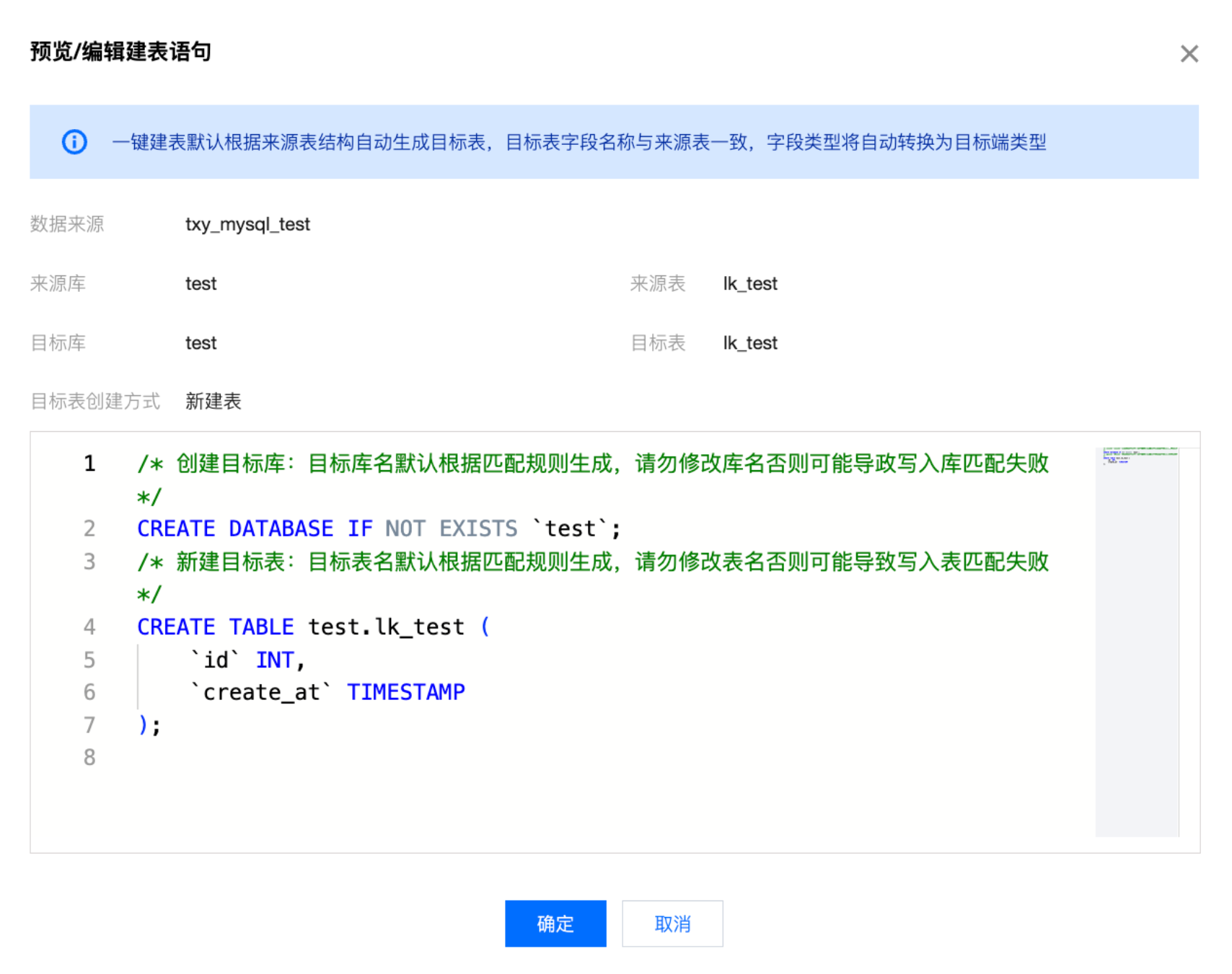 批量修改表创建方式:支持批量对表创建方式进行修改 匹配失败表创建方式: 新建表:支持改为暂不新建 暂不新建:支持改为新建表 匹配成功表创建方式 使用已有表:支持改为删除已有表并新建 删除已有表并新建:支持改为使用已有表 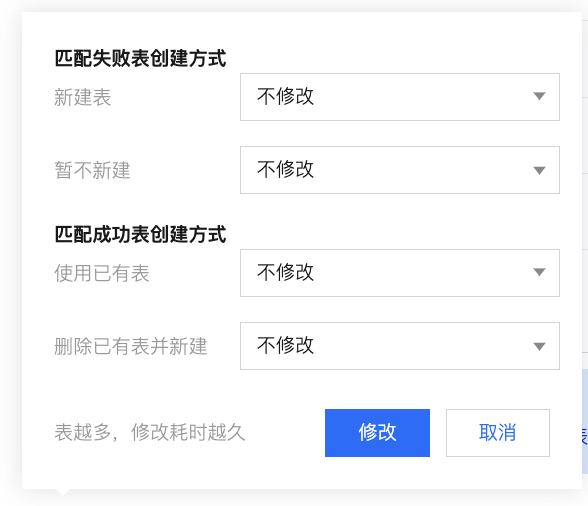 批量键表:展示键表结果,支持查看键表语句、重试。 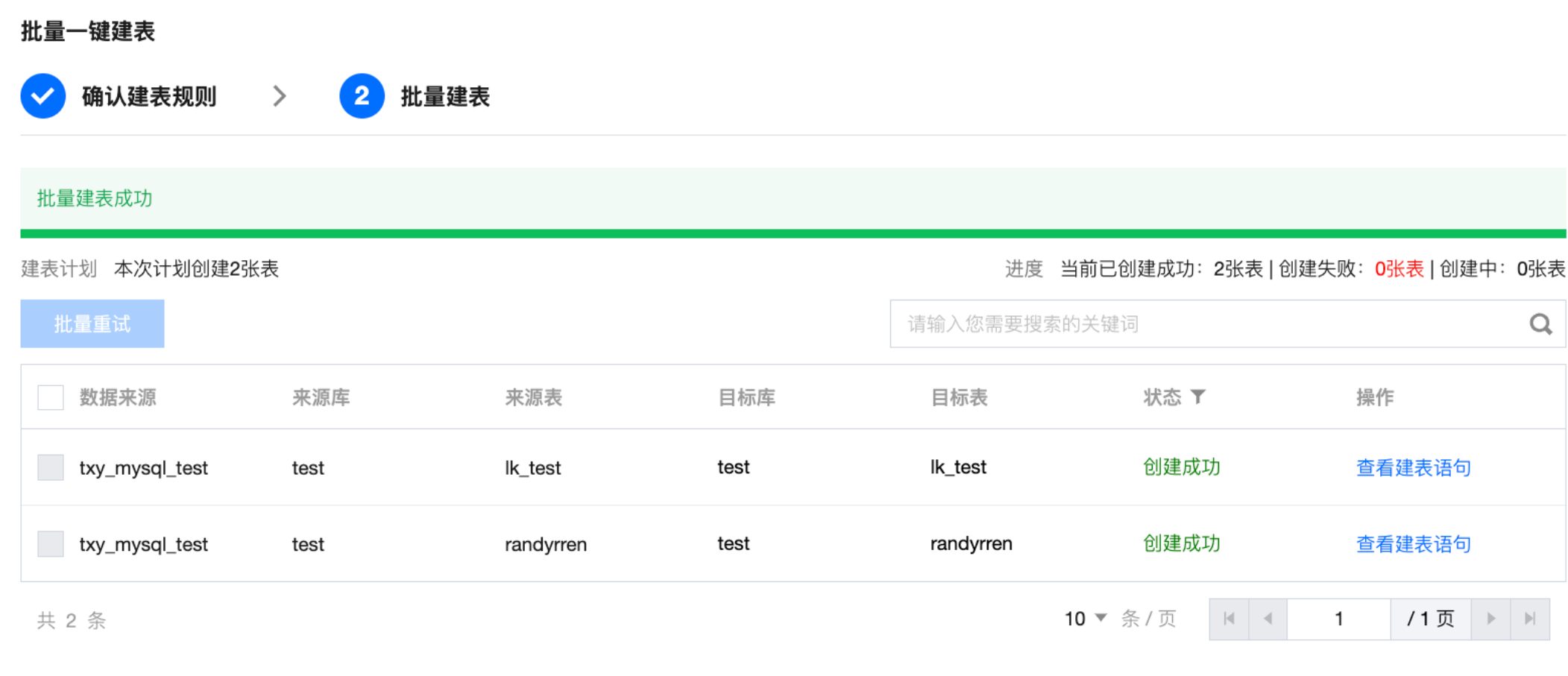 |
高级设置 | 可根据业务需求配置参数。 |
步骤五:运行设置
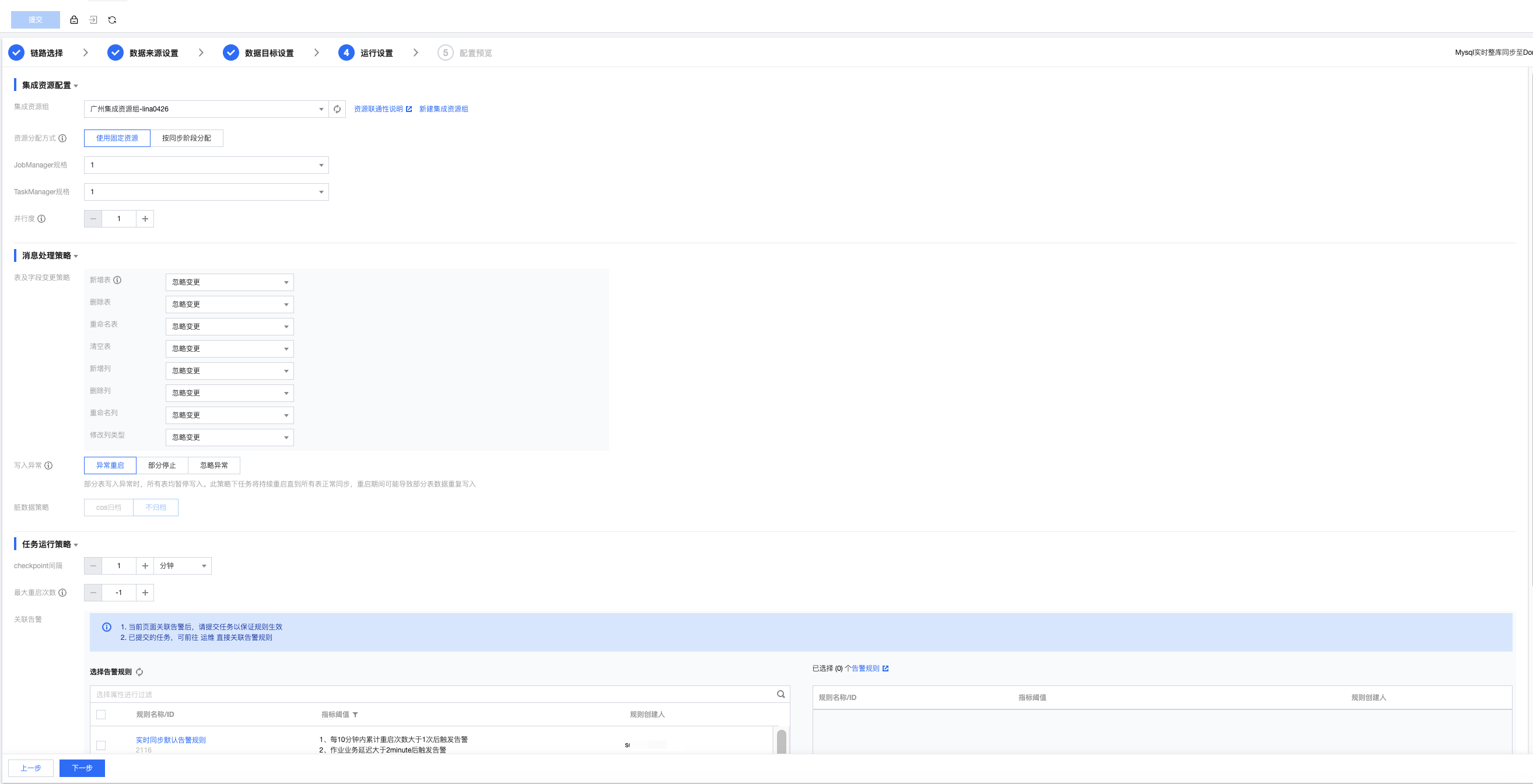
集成资源配置:
为当前任务关联对应的集成资源组,同时设定运行时 JM、TM 规格以及任务运行并行度。其中,当前任务实际运行时实际占用 CU 数 = JobManager 规格 + TaskManager 规格 × 并行度。
资源分配方式:集成资源支持多种分配方式
固定分配:此方式下不区分任务同步阶段,全量及增量同步过程中始终为当前任务分配固定资源量。此方式可避免任务间资源抢占,适用于任务运行过程中数据可能存在较大变动的场景。
按同步阶段分配:按全量和增量不同同步阶段分配计划的资源使用量,以节约整体资源用量。
表及字段变更策略:
表及字段变更类型 | 支持策略 |
新增表 | 忽略变更、自动建表、日志告警、任务出错 |
删除表 | 忽略变更 |
重命名表 | 忽略变更、日志告警 |
清空表 | 忽略变更、日志告警 |
新增列 | 自动新增列、忽略变更、日志告警、任务出错 |
删除列 | 自动变更、忽略变更、日志告警、任务出错 |
重命名列 | 自动变更、忽略变更、日志告警、任务出错 |
修改列类型 | 自动变更、忽略变更、日志告警、任务出错 |
如下是上表中支持的策略和表现效果:
策略名称 | 表现效果 |
忽略变更 | 1. 目标端表/字段不做任何变更 2. 任务正常运行 |
日志告警 | 1. 目标端表/字段不做任何变更 2. 任务正常运行,默认忽略变更 |
任务停止 | 1. 目标端表/字段不做任何变更 2. 任务异常重启 |
自动处理 | 目标端根据来源端自动发生变更,自动创建出目标侧对象。例如,新增表、新增列等。 说明: 为了避免误操作造成结构变化从而影响用户业务,目前仅新增相关变更,如新增表/列,支持自动处理;其余高危操作,如删除列、清空表、删除表等操作仅支持“提醒式”响应策略(例如,告警、停止) |
写入异常策略:
DLC 整库同步任务提供任务级运行资源及数据失败写入处理策略。其中数据写入失败处理策略支持四种:
策略名称 | 策略说明 |
部分停止 | 部分表写入异常时,仅停止该表数据写入,其他表正常同步。已停止的表不可在本次任务运行期间恢复写入。 |
异常重启 | 部分表写入异常时,所有表均暂停写入。此策略下任务将持续重启直到所有表正常同步,重启期间可能导致部分表数据重复写入。 |
忽略异常 | 忽略表内无法写入的异常数据并标记为脏数据。该表的其他数据、以及任务内的其他表正常同步。脏数据提供 COS 归档和不归档两种方案。 COS 归档:将无法写入的脏数据进行归档,需要配置 COS 数据源、存储桶、存储目录、内容分隔符及换行符。 不归档:不需要做其他操作。 |
场景示例:
任务 Task1 下计划同步50张表,任务运行过程中表 A 内出现新增字段或字段类型变更:
部分停止:表 A 任务运行后将字段 "DEMO" 的进行了字段类型变更,并且变更后字段类型与目标端字段类型无法匹配写入。此策略下,任务将在停止源端表 A 的数据读取,后续任务仅同步其余49张表至目标端。
异常重启:表 A 任务运行后将字段 "DEMO "的进行了字段类型变更,并且变更后字段类型与目标端字段类型无法匹配写入。此策略下任务将在持续重启,期间任务内配置的所有50张表将暂停数据写入,直到表A字段纠正。
忽略异常:表 A 任务运行后将字段 "DEMO" 的进行了字段类型变更,并且变更后字段类型与目标端字段类型无法匹配写入。此策略下任务将忽略无法写入的异常数据,并标记为脏数据,表内其他数据正常同步。
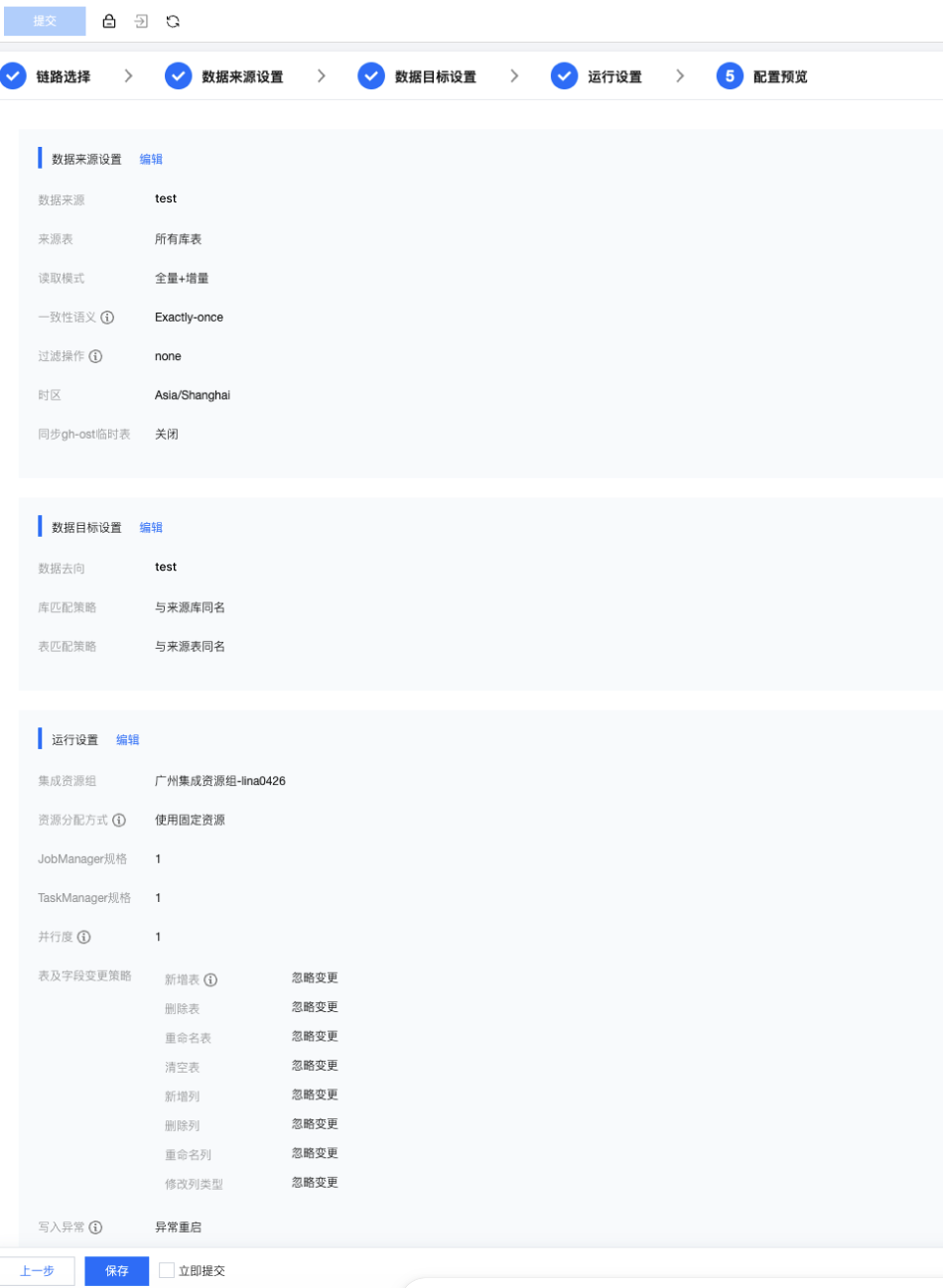
步骤六:配置预览
通过配置预览,您可以一次性查看链路选择、数据来源设置、数据目标设置、运行设置所配置的全部结果,以确保任务配置信息的准确、合理。
步骤七:任务配置检测与提交
当完成上面六个步骤,可以进行任务配置检测和正式提交任务,此时可以单击左上角的提交按钮,进入任务配置检查和提交阶段。
步骤 | 步骤说明 | |
任务配置检测 | 本步骤将针对任务内读端、写端以及资源进行检测: 检测通过:配置无误。 检测失败:配置存在问题,需修复以进行后续配置。 检测告警:此检测为系统建议修改项,修改完成后可单击重试重新检测;或者,您可以单击忽略异常进入下一步骤不阻塞后续配置。 当前支持的检测项见后续表格。 | 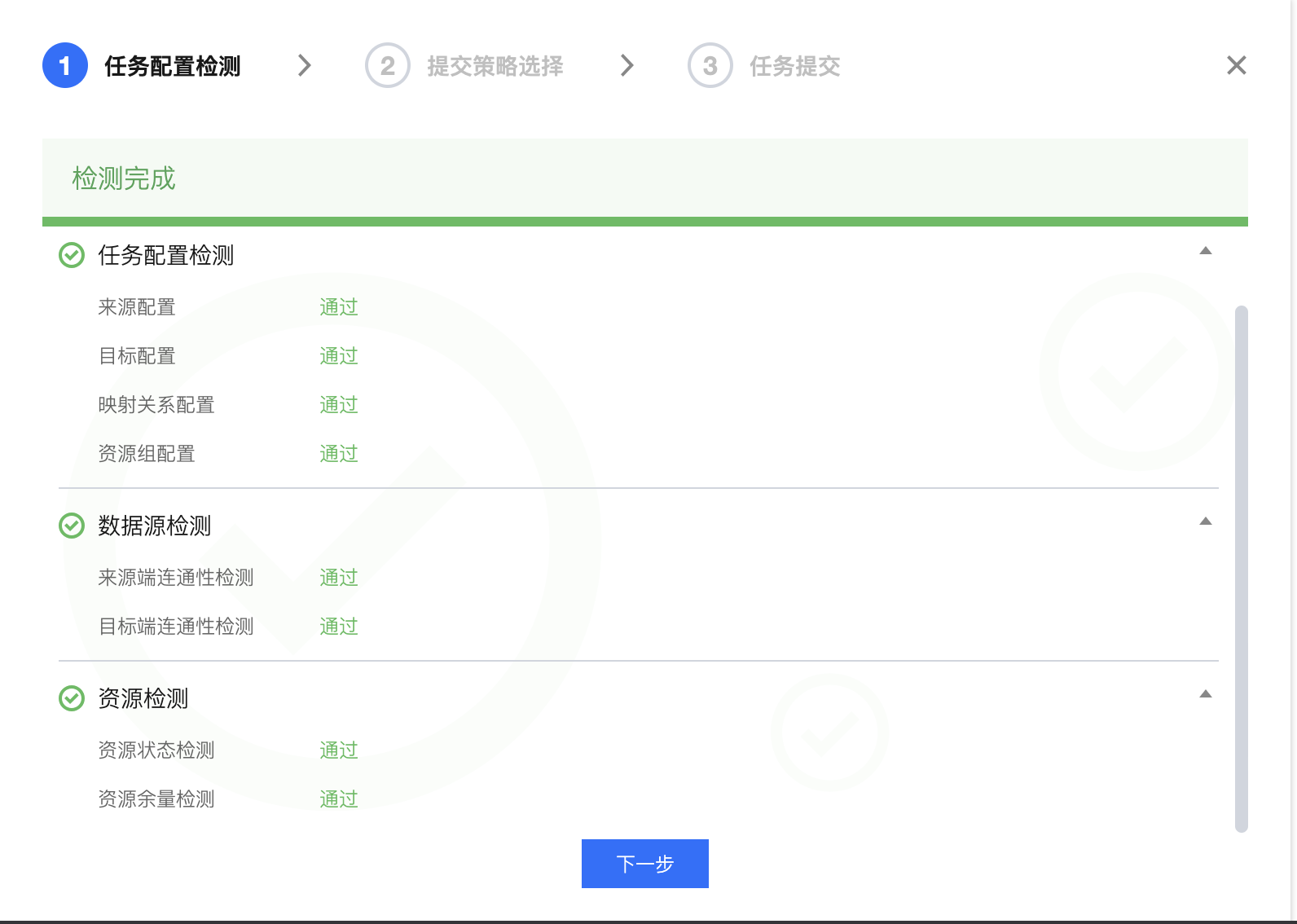 |
提交策略选择 | 本步骤中可选择本次任务提交策略: 首次提交:首次提交任务支持从默认或指定点位同步数据 立即启动,从默认点位开始同步:若源端配置为“全量 + 增量”读取方式,则默认先同步存量数据(全量阶段),完成后消费binlog获取变更数据(增量阶段);若源端配置为 “仅增量”读取,则默认使用 binlog 最新位点开始读取。 立即启动,从指定时间点开始同步:任务将根据配置的时间及时区同步数据。若未找到指定的时间位点,任务将默认从 binlog 最早位点开始同步;若源端读取方式为“全量 + 增量”,任务将默认跳过全量阶段从增量的指定时间位点开始同步。 暂不启动:提交后暂不启动运行任务,后续可在运维列表内手动启动任务。 非首次提交:支持带运行状态启动或继续运行任务 继续运行:此策略下新版本任务提交后,将从上次同步最后位点继续运行。 重新启动,从指定位点开始:此策略下您可指定重新启动读取的位点,任务将忽略老版本从指定位点重新开始读取。若未找到指定的时间位点任务将默认从 binlog 最早位点开始同步。 重新启动,从默认位点开始运行:此策略下将根据源端配置从默认位点开始读取。若源端配置为“全量+增量”读取方式,则默认先同步存量数据(全量阶段),完成后即可消费 binlog 获取变更数据(增量阶段);若源端配置为 “仅增量”读取,则默认使用 binlog 最新位点开始读取。 不同的任务状态支持的提交运行策略有所差异,详见后续表格。 同时,每次提交都将新生成一个实时任务版本,您可在对话框内配置版本描述。 | 1. 首次提交 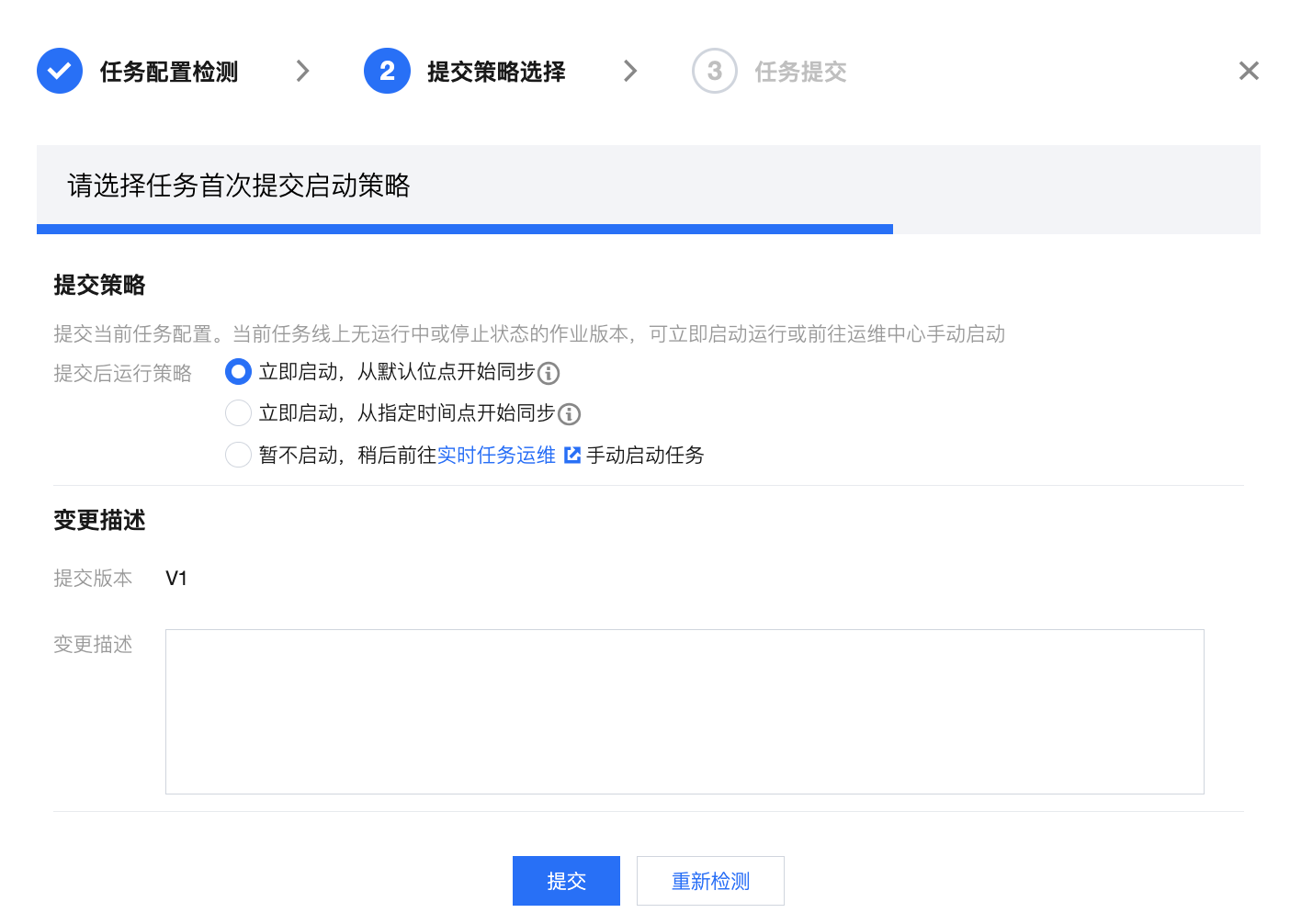 2.非首次提交 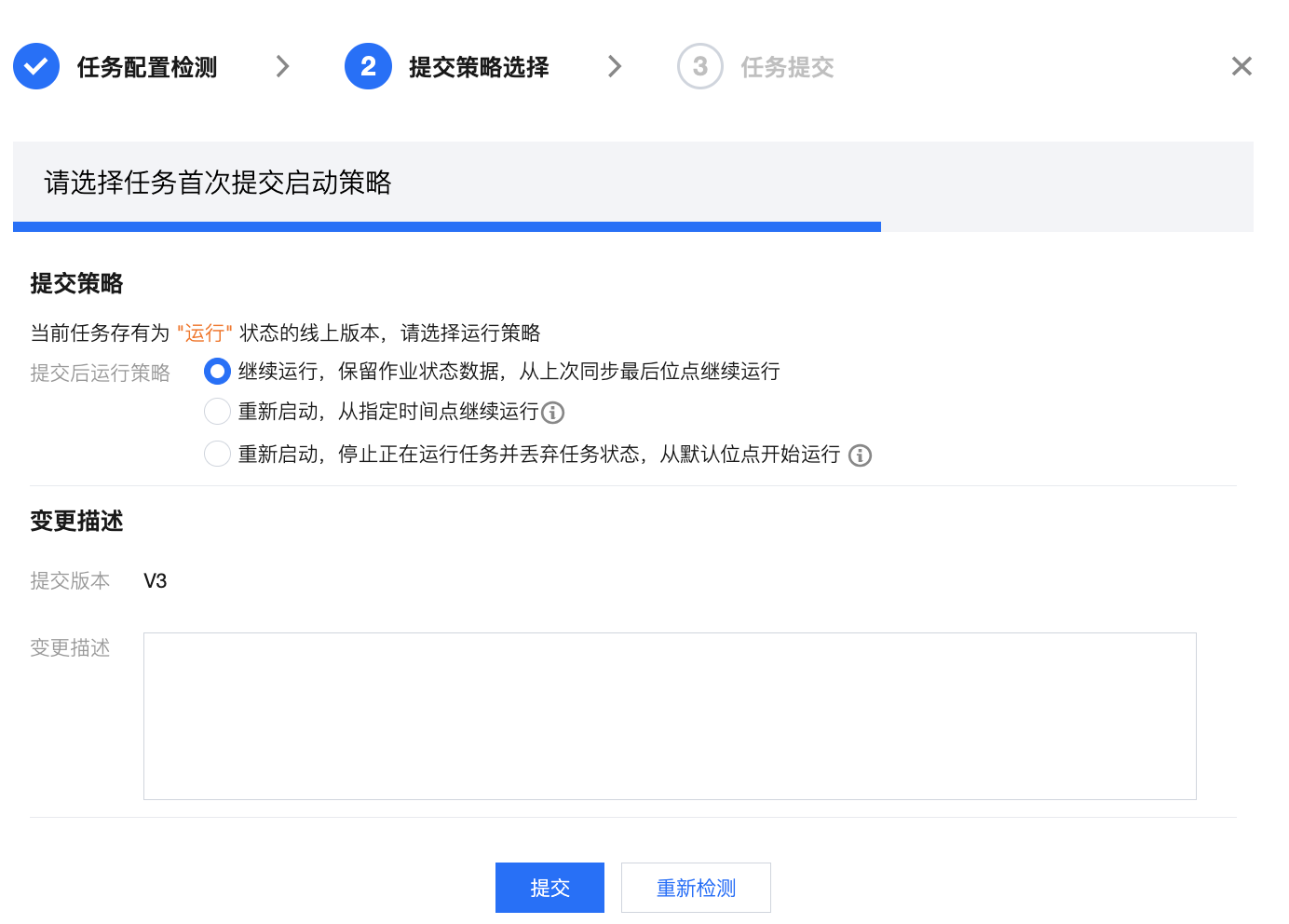 |
任务提交 | 提交成功后,您可单击前往运维查看任务运行情况。 | 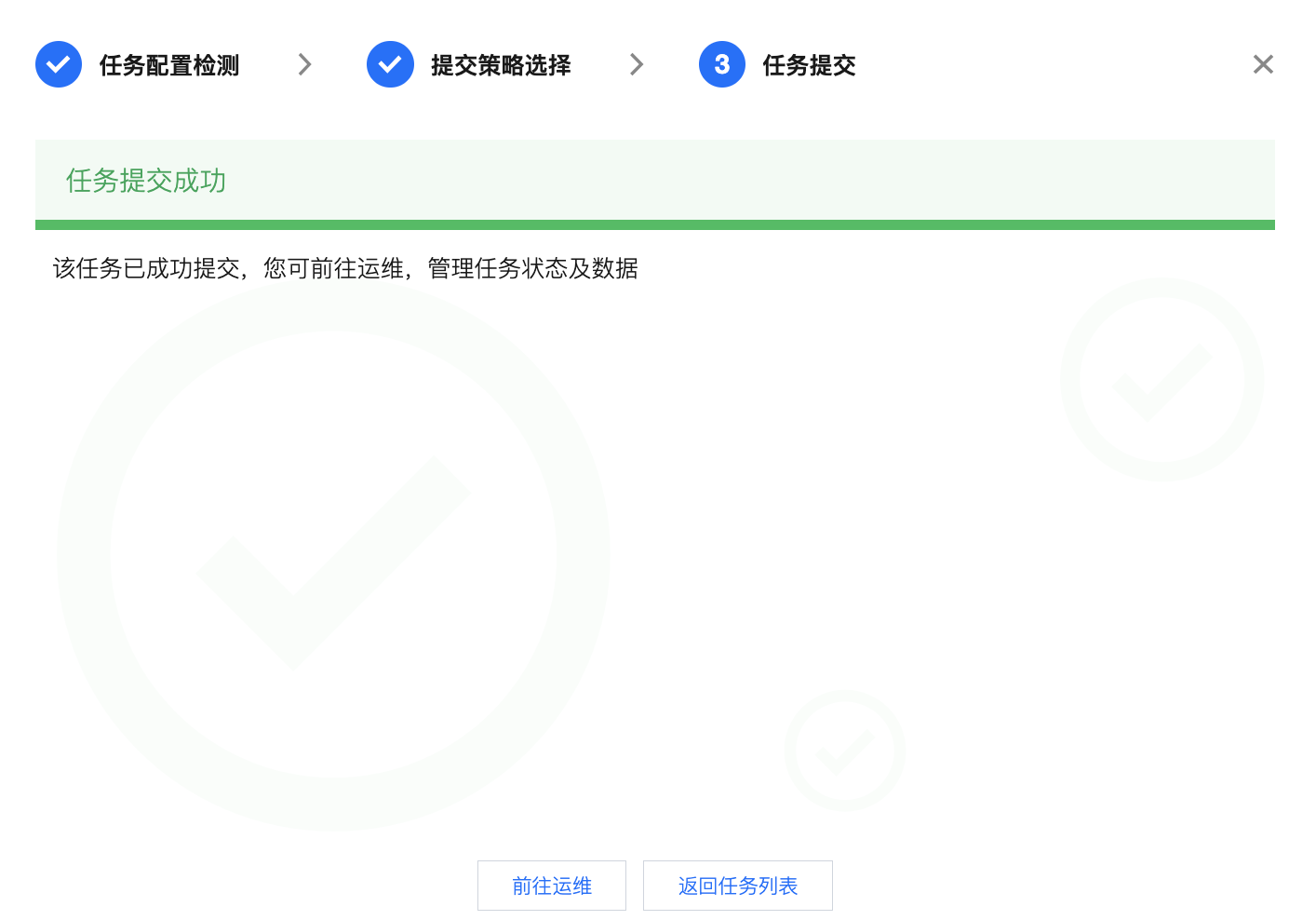 |
任务配置检测支持的检测项:
检测分类 | 检测项 | 说明 |
任务配置检测 | 来源配置 | 检测来源端的必填项是否有缺失 |
| 目标配置 | 检测目标端的必填项是否有缺失 |
| 映射关系配置 | 检测字段映射是否已配置 |
| 资源组配置 | 检测资源组是否有配置 |
数据源检测 | 来源端连通性检测 | 检测来源端数据源跟任务配置的资源组是否网络联通。检测不通过可查看诊断信息,打通网络后可重新检测,否则任务大概率会运行失败。 |
| 目标端连通性检测 | 检测目标端数据源跟任务配置的资源组是否网络联通。检测不通过可查看诊断信息,打通网络后可重新检测,否则任务大概率会运行失败。 |
资源检测 | 资源状态检测 | 检测资源组是否为可用状态。若资源状态不可用,请更换任务配置的资源组,否则任务大概率会运行失败。 |
| 资源余量检测 | 检测资源组当前剩余的资源是否满足任务配置的资源需求。若检测不通过,请适当调小任务资源配置或扩容资源组。 |
不同的任务运行状态支持的提交运行策略:
任务状态 | 提交运行策略 | 说明 |
1、首次提交 2、已停止/检测异常/初始化(非首次提交) | 立即启动,从默认位点开始同步 | 此策略下将根据源端配置从默认位点开始读取。若源端配置为“全量+增量”读取方式,则默认先同步存量数据(全量阶段),完成后即可消费binlog获取变更数据(增量阶段);若源端配置为 “仅增量”读取,则默认使用binlog最新位点开始读取。 |
| 立即启动,指定时间点开始同步 | 此策略下需选择具体的开始时间,根据时间匹配位点。 1. 从指定时间点开始读取数据。若未匹配到指定位点,任务则默认从 binlog 最早位点开始同步 2. 若您源端读取方式为全量 + 增量,选择此策略将默认跳过全量阶段从增量的指定时间位点开始同步 |
| 暂不启动,稍后前往实时任务运维手动启动任务 | 此策略下仅提交任务到实时运维,不进行任务启动,后续可从实时运维页面批量启动任务。 |
运行中 (非首次提交) | 继续运行,保留作业状态数据,从上次同步最后位点继续运行 | 此策略下新版本任务提交后,将从上次同步最后位点继续运行。 |
| 重新启动,从指定时间点继续运行 | 此策略下您可指定重新启动读取的位点,任务将忽略老版本从指定位点重新开始读取。若未找到指定的时间位点任务将默认从binlog最早位点开始同步。 |
| 重新启动,停止正在运行任务并丢弃任务状态,从默认位点开始运行 | 此策略下将停止正在运行的任务并丢弃任务状态,然后根据源端配置从默认位点开始读取。若源端配置为“全量 + 增量”读取方式,则默认先同步存量数据(全量阶段),完成后即可消费 binlog 获取变更数据(增量阶段);若源端配置为 “仅增量”读取,则默认使用 binlog 最新位点开始读取。 |
已暂停 (非首次提交) | 继续运行,保留作业状态数据,从上次同步最后位点继续运行 | 此策略下新版本任务提交后,将从上次同步最后位点继续运行。 注意: 暂停操作时会生成快照,任务重新提交支持从最后位点继续运行。 强制暂停时不生成快照,任务重新提交支持从任务运行时最近一次生成的快照运行。这种暂停会导致任务数据重放一部分,如果目标写入是 Append 会有重复的数据,如果目标写入是 Upsert 则不会有重复问题。 |
| 重新启动,从指定时间点继续运行 | 此策略下您可指定重新启动读取的位点,任务将忽略老版本从指定位点重新开始读取。若未找到指定的时间位点任务将默认从 binlog 最早位点开始同步。 |
| 重新启动,停止正在运行任务并丢弃任务状态,从默认位点开始运行 | 此策略下将停止正在运行的任务并丢弃任务状态,然后根据源端配置从默认位点开始读取。若源端配置为“全量 + 增量”读取方式,则默认先同步存量数据(全量阶段),完成后即可消费 binlog 获取变更数据(增量阶段);若源端配置为 “仅增量”读取,则默认使用 binlog 最新位点开始读取。 |
失败 (非首次提交) | 从上次运行失败(checkpoint)位点恢复运行 | 此策略下将从任务上一次运行失败的位点继续运行 |
| 重新启动,根据任务读取配置从默认位点开始运行 | 此策略下将根据源端配置从默认位点开始读取。若源端配置为“全量 + 增量”读取方式,则默认先同步存量数据(全量阶段),完成后即可消费binlog获取变更数据(增量阶段);若源端配置为 “仅增量”读取,则默认使用binlog最新位点开始读取。 |
操作中 (非首次提交) | 不支持 | 线上有同名任务且状态为操作中时,不支持重新提交任务 |
步骤八:实时任务运维
六、实时单表:MySQL 同步至 TChouse-D
当业务只需要关注某个特定表的数据时,单表同步可以针对性地同步特定表的数据,这样可以减少不必要的数据处理和传输,提高同步效率。
在数据集成页面左侧目录栏单击实时同步,在实时同步页面上方选择单表同步新建并进入配置页面。配置单表同步时支持两种模式:单表模式和画布模式。后续以表单模式为例讲解配置流程。
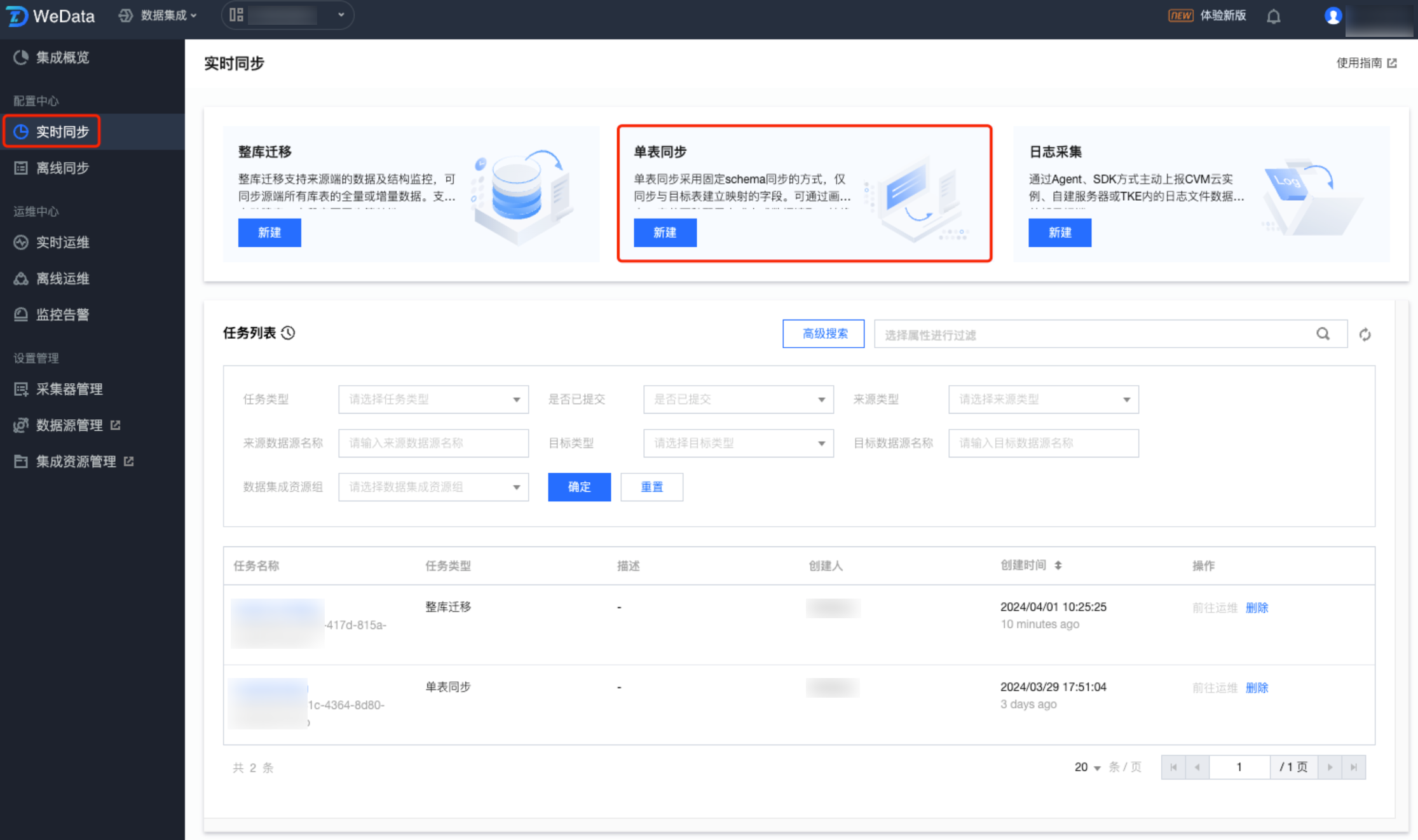
步骤一:配置 MySQL 读取节点
1. 在数据集成页面左侧目录栏单击实时同步。
2. 在实时同步页面上方选择单表同步新建(可选择表单和画布模式)并进入配置页面。
3. 选择 MySQL 节点并配置节点信息。
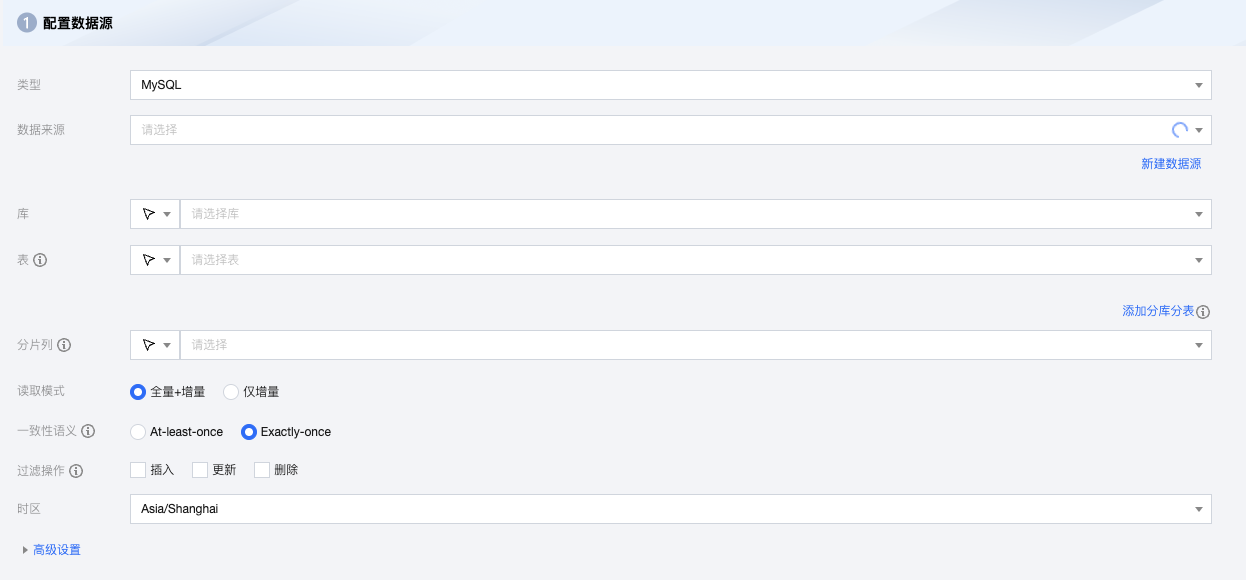
4. 参数信息如下表:
数据来源 | 选择该项目可用的 MySQL 数据源。 |
库 | 支持选择、或者手动输入需读取的库名称。 默认将数据源绑定的数据库作为默认库,其他数据库需手动输入库名称。 当数据源网络不联通导致无法直接拉取库信息时,可手动输入数据库名称。在数据集成网络连通的情况下,仍可进行数据同步。 |
表 | 支持选择、或者手动输入需读取的表名称。 分表情况下,可在 MySQL 源端支持选择或输入多个表名称,多个表需保证结构一致。 分表情况下,支持配置表序号区间。例如 'table_[0-99]' 表示读取 'table_0'、'table_1'、'table_2' 直到 'table_99' ; 如果您的表数字后缀的长度一致,例如 'table_000'、'table_001'、'table_002' 直到 'table_999',您可以配置为 '"table": ["table_00[0-9]", "table_0[10-99]", "table_[100-999]"]' 。 当数据源网络不联通导致无法直接拉取表信息时,可手动输入表名称。在数据集成网络连通的情况下,仍可进行数据同步。 |
添加分库分表 | 适用于分库场景,点击后可配置多个数据源、库及表信息。分库分表场景下需保证所有表结构一致,任务配置将默认展示并使用第一个表结构进行数据获取。 |
分片列 | 分片列用于将表分为多个分片进行同步。有主键的表建议优先选择表主键作为分片列; 无主键的表建议选择有索引的列作为分片列,且保证分片列不存在数据的更新操作,否则只能保证 At-Least-Once 语义。 |
读取模式 | 支持全量+增量和仅增量两种模式。 |
一致性语义 | Exactly-once At-least-once 注意: 仅代表读取端的一致性语义。当前版本两种模式状态不兼容,任务提交后如果修改模式,不支持带状态重启。 |
过滤操作 | 设置后将不同步指定操作类型的数据,支持插入、更新和删除。 |
时区 | 设置日志时间所属时区,默认上海。 |
高级设置(选填) | 可根据业务需求配置参数。 |
5. 预览数据字段,单击保存。
步骤二:配置 TChouse-D 写入节点
1. 在数据集成页面左侧目录栏单击实时同步。
2. 在实时同步页面上方选择单表同步新建(可选择表单和画布模式)并进入配置页面。
3. 选择 TChouse-D 节点并配置节点信息。
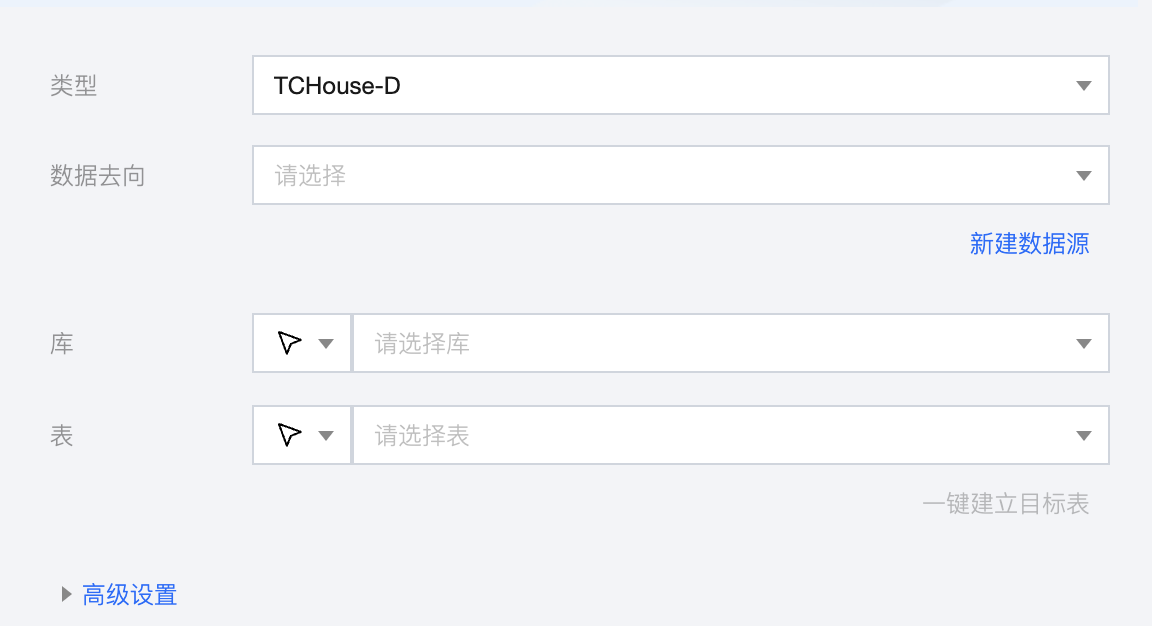
4. 参数信息如下表:
参数 | 说明 |
数据去向 | 需要写入的 TChouse-D 数据源。 |
库 | 支持选择、或者手动输入需写入的库名称 默认将数据源绑定的数据库作为默认库,其他数据库需手动输入库名称。 当数据源网络不联通导致无法直接拉取库信息时,可手动输入数据库名称。在数据集成网络连通的情况下,仍可进行数据同步。 |
表 | 支持选择、或者手动输入需写入的表名称。 当数据源网络不联通导致无法直接拉取表信息时,可手动输入表名称。在数据集成网络连通的情况下,仍可进行数据同步。 |
步骤三:任务配置检测与提交
当完成上面的步骤,可以进行任务配置检测和正式提交任务,此时可以查看任务配置界面左上角的相关按钮进行后续提交操作。每一个按钮的位置和功能如下:
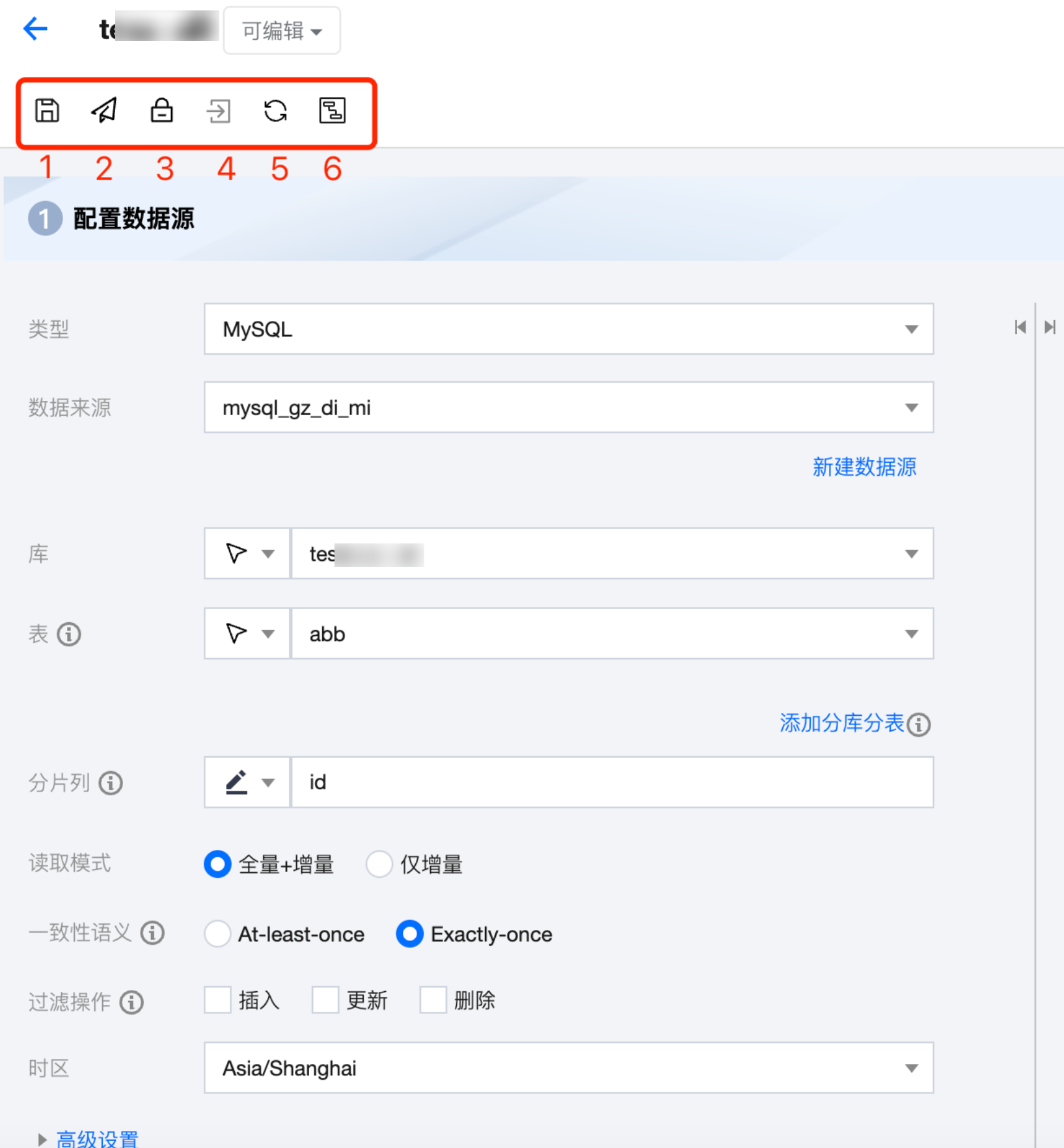
实时同步任务在配置完成后可配置运行策略并提交到生产环境中运行。目前可在任务配置页面支持保存、提交、锁定/解锁、前往运维及表单/画布转换操作。
序号 | 参数 | 说明 |
1 | 保存 | 保存当前任务配置信息,包括数据节点配置、节点连线、任务属性配置。 |
2 | 提交 | 将当前任务提交至生产环境,提交时根据当前任务是否有生产态任务可选择不同运行策略。 若当前任务无生效的线上任务,即首次提交或线上任务处于“失败”状态,可直接提交。 若当前任务存在“运行中”或“暂停”状态的线上任务需选择不同策略。停止线上作业将抛弃之前任务运行位点,从头开始消费数据,保留作业状态将在重启后从之前最后消费位点继续运行。  说明: 单击立即启动任务将在提交后立即开始运行,否则需要手动触发才会正式运行。 |
3 | 锁定/解锁 | 默认创建者为首个持锁者,仅允许持锁者编辑任务配置及运行任务。若锁定者5分钟内没有编辑操作,其他人可点击图标抢锁,抢锁成功可进行编辑操作。 |
4 | 前往运维 | 根据当前任务名称快捷跳转至实时运维页面。 |
5 | 刷新 | 刷新任务配置 |
6 | 画布转换/表单转换 | 表单模式和画布模式可以互相转换。表单模式下提供画布转换功能,画布模式下提供表单转换功能。 说明: 当前仅支持任务在保存成功状态下才允许转换。 若画布模式包含转换节点,不支持转为表单模式。 |
任务配置检测
任务提交时会进行基础环境和配置检测,请重点关注未通过项和警告项。未通过项大概率会导致任务运行失败,警告项请结合业务情况判断影响。当前检测结果不会阻断任务提交,您可选择重新检测或忽略异常继续提交。
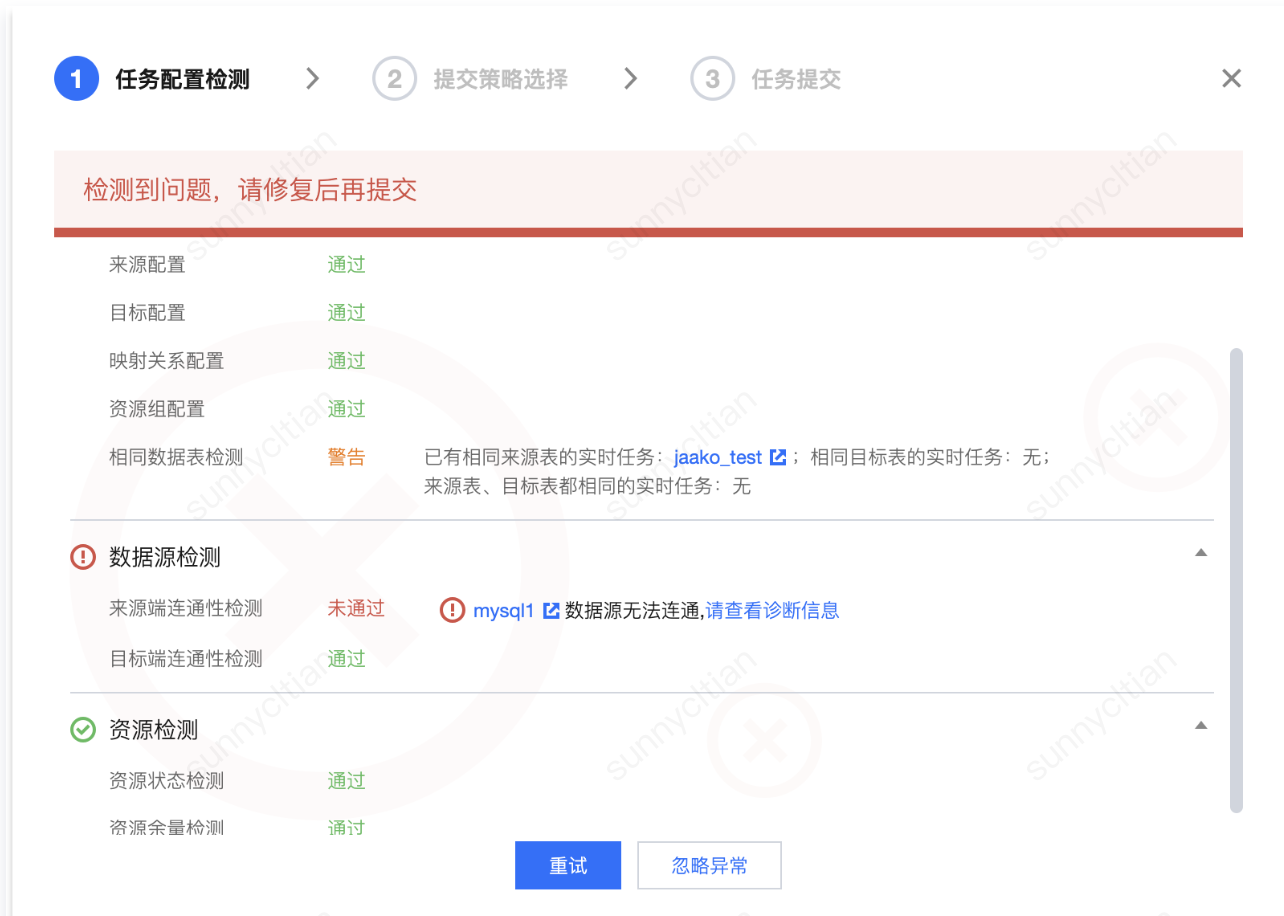
当前支持的检测项:
检测分类 | 检测项 | 说明 |
任务配置检测 | 来源配置 | 检测来源端的必填项是否有缺失 |
| 目标配置 | 检测目标端的必填项是否有缺失 |
| 映射关系配置 | 检测字段映射是否已配置 |
| 资源组配置 | 检测资源组是否有配置 |
| 相同数据表检测 | 检测当前项目下所有的实时单表任务(包含已提交和未提交)是否有同样来源表或目标表或来源表与目标表都相同的情况。相同表的判断依据为是否是同一个数据源同一个 DB 下的同名表。此检测项主要用于同一个表不希望有多个任务重复读取的场景。 |
数据源检测 | 来源端连通性检测 | 检测来源端数据源跟任务配置的资源组是否网络联通。检测不通过可查看诊断信息,打通网络后可重新检测,否则任务大概率会运行失败。 |
| 目标端连通性检测 | 检测目标端数据源跟任务配置的资源组是否网络联通。检测不通过可查看诊断信息,打通网络后可重新检测,否则任务大概率会运行失败。 |
资源检测 | 资源状态检测 | 检测资源组是否为可用状态。若资源状态不可用,请更换任务配置的资源组,否则任务大概率会运行失败。 |
| 资源余量检测 | 检测资源组当前剩余的资源是否满足任务配置的资源需求。若检测不通过,请适当调小任务资源配置或扩容资源组。 |
提交策略选择
正常提交或忽略异常提交后会进入提交策略选择页面,用户可根据业务需求选择不同的运行策略:
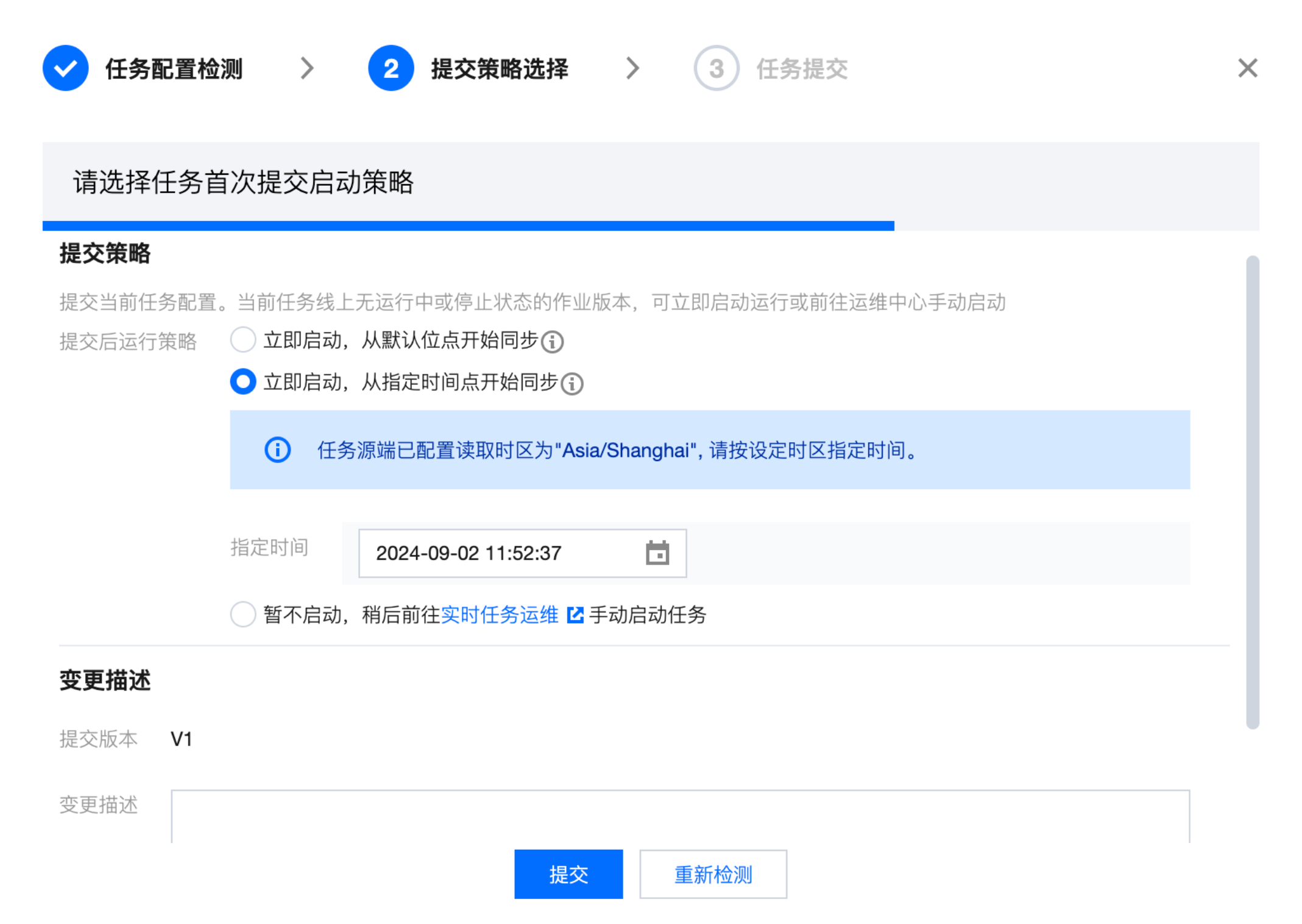
不同的任务运行状态支持的提交运行策略有所差异:
任务状态 | 提交运行策略 | 说明 |
1. 首次提交 2. 已停止/检测异常/初始化(非首次提交) | 立即启动,从默认位点开始同步 | 此策略下将根据源端配置从默认位点开始读取。若源端配置为“全量+增量”读取方式,则默认先同步存量数据(全量阶段),完成后即可消费binlog获取变更数据(增量阶段);若源端配置为 “仅增量”读取,则默认使用binlog最新位点开始读取。 |
| 立即启动,指定时间点开始同步 | 此策略下需选择具体的开始时间,根据时间匹配位点。 1. 从指定时间点开始读取数据。若未匹配到指定位点,任务则默认从binlog最早位点开始同步 2. 若您源端读取方式为全量 + 增量,选择此策略将默认跳过全量阶段从增量的指定时间位点开始同步 |
| 暂不启动,稍后前往实时任务运维手动启动任务 | 此策略下仅提交任务到实时运维,不进行任务启动,后续可从实时运维页面批量启动任务。 |
运行中 (非首次提交) | 继续运行,保留作业状态数据,从上次同步最后位点继续运行 | 此策略下新版本任务提交后,将从上次同步最后位点继续运行。 |
| 重新启动,从指定时间点继续运行 | 此策略下您可指定重新启动读取的位点,任务将忽略老版本从指定位点重新开始读取。若未找到指定的时间位点任务将默认从 binlog 最早位点开始同步。 |
| 重新启动,停止正在运行任务并丢弃任务状态,从默认位点开始运行 | 此策略下将停止正在运行的任务并丢弃任务状态,然后根据源端配置从默认位点开始读取。若源端配置为“全量 + 增量”读取方式,则默认先同步存量数据(全量阶段),完成后即可消费 binlog 获取变更数据(增量阶段);若源端配置为 “仅增量”读取,则默认使用 binlog 最新位点开始读取。 |
已暂停 (非首次提交) | 继续运行,保留作业状态数据,从上次同步最后位点继续运行 | 此策略下新版本任务提交后,将从上次同步最后位点继续运行。 注意: 暂停操作时会生成快照,任务重新提交支持从最后位点继续运行。 强制暂停时不生成快照,任务重新提交支持从任务运行时最近一次生成的快照运行。这种暂停会导致任务数据重放一部分,如果目标写入是 Append 会有重复的数据,如果目标写入是 Upsert 则不会有重复问题。 |
| 重新启动,从指定时间点继续运行 | 此策略下您可指定重新启动读取的位点,任务将忽略老版本从指定位点重新开始读取。若未找到指定的时间位点任务将默认从 binlog 最早位点开始同步。 |
| 重新启动,停止正在运行任务并丢弃任务状态,从默认位点开始运行 | 此策略下将停止正在运行的任务并丢弃任务状态,然后根据源端配置从默认位点开始读取。若源端配置为“全量 + 增量”读取方式,则默认先同步存量数据(全量阶段),完成后即可消费 binlog 获取变更数据(增量阶段);若源端配置为 “仅增量”读取,则默认使用 binlog 最新位点开始读取。 |
失败 (非首次提交) | 从上次运行失败(checkpoint)位点恢复运行 | 此策略下将从任务上一次运行失败的位点继续运行 |
| 重新启动,根据任务读取配置从默认位点开始运行 | 此策略下将根据源端配置从默认位点开始读取。若源端配置为“全量+增量”读取方式,则默认先同步存量数据(全量阶段),完成后即可消费binlog获取变更数据(增量阶段);若源端配置为 “仅增量”读取,则默认使用binlog最新位点开始读取。 |
操作中 (非首次提交) | 不支持 | 线上有同名任务且状态为操作中时,不支持重新提交任务 |
同时,每次提交都将新生成一个实时任务版本,您可在对话框内配置版本描述。
提交结果
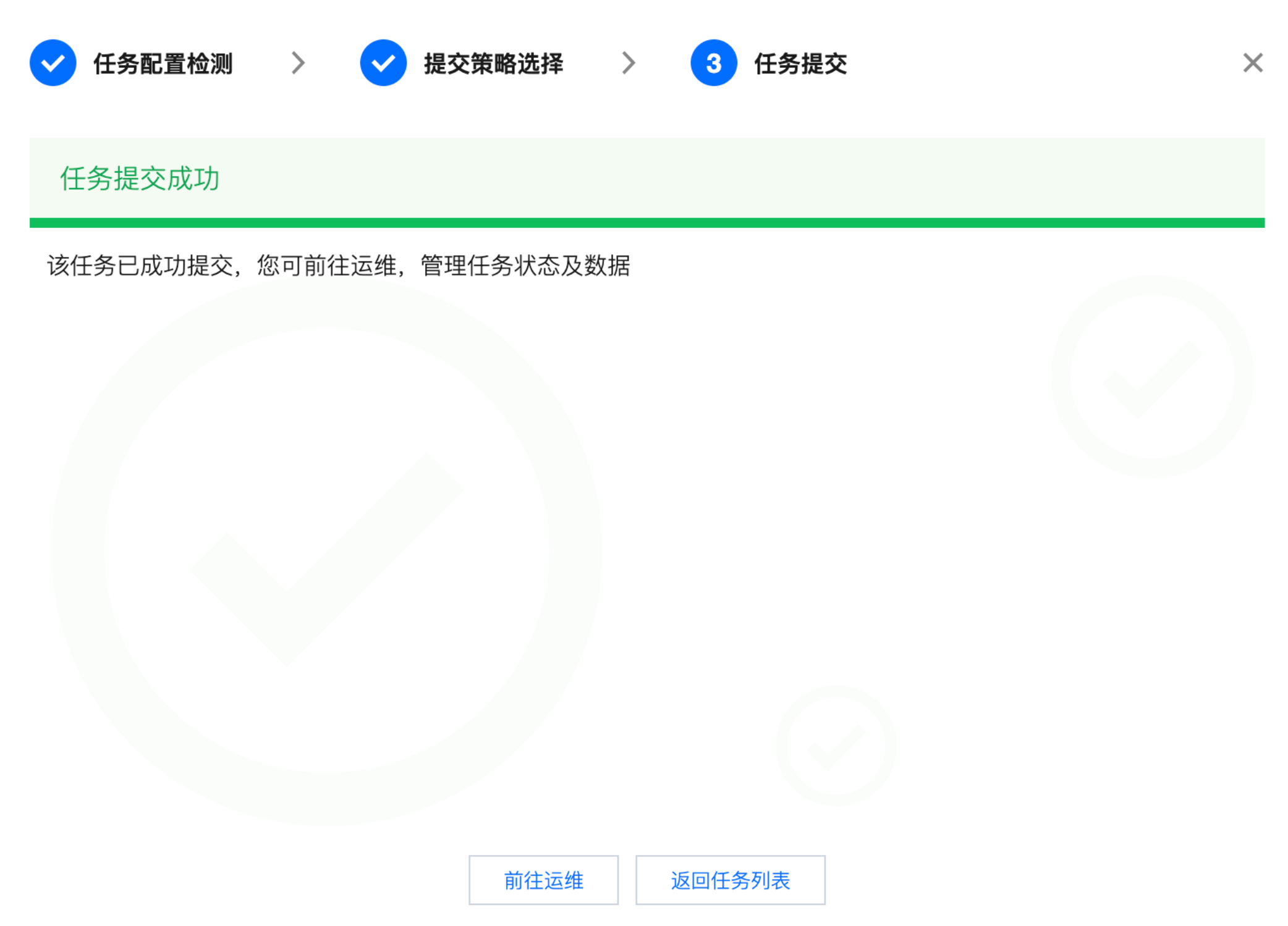
单击上图提交按钮后,会出现提交进度和提交结果:
任务提交中:
展示提交进度百分比。
任务提交结果 - 成功:
展示任务提交成功结果。
可前往运维进行任务运维管理或返回任务列表
任务提交结果 - 失败:
展示任务提交失败原因
步骤四:实时任务运维
七、实时节点高级参数
在配置读写节点时,可以配置高级设置,配置内容和使用场景如下所示:
MySQL 类型节点级别
如下为 MySQL 来源端在使用场景下支持的高级设置及其描述:
读/写 | 适用场景 | 配置内容: | 描述 |
读 | 单表 + 整库 | scan.newly-added-table.enabled=true | 参数描述: 设置这个参数,在暂停 > 继续后可以感知新增的表。默认是 false 1. 全增量同步时使用该参数,新增的表会读取存量数据后再读取增量数据 2. 增量同步时使用该参数,新增的表只会读取增量数据 |
读 | 单表 + 整库 | scan.incremental.snapshot.chunk.size=20000 | 参数描述: 对于数据分布均匀的任务,这个参数代表一个 chunk 内大约的条数,可以用总的数据量除以 chunk size 估算任务有多少个 chunk 数,chunk 数的多少影响了 jobmanager 是否 oom,目前 2CU 的情况下可以支持10w多 chunk,如果数据量太大,我们可以调大 chunk size 来减少 chunk 数量 注意事项: 大数据量任务(例如,总数据量1个亿以上,单条记录大于0.1M)一般建议设置20000 |
读 | 单表 + 整库 | split-key.even-distribution.factor.upper-bound=10.0d | 参数描述: mysql 存量数据读取阶段,如果数据比较离散、主键字段的最大值超大,可以修改这个参数,来使用非均匀分割,减少由于主键值超大情况下导致 chunk 数量太大从而 jm oom 的问题 注意事项: 默认值为10.0d 一般不用修改 |
读 | 单表 + 整库 | debezium.query.fetch.size=0 | 参数描述: 代表每次读取从数据库拉取的数据条数,默认是0代表jdbc 默认的 fetch size 注意事项: 1. 大任务(例如,总数据量1个亿以上,单条记录大于0.1M)只有一个读取实例时建议取1024条 2. 任务存在多个读取实例时建议降低这个值,减少内存消耗,建议取512条 |
读 | 单表 + 整库 | debezium.max.queue.size=8192 | 参数描述: 属性定义了内部队列中存储的最大事件数。如果达到此限制,Debezium 将暂停读取新事件,直到处理和提交尚未处理的事件。这个属性可以帮助避免过多事件积压在队列中,导致内存耗尽和性能下降。默认是8192 注意事项: 1. 大任务(例如,总数据量1个亿以上,单条记录大于0.1M)只有一个读取实例建议取4096 2. 任务存在多个读取实例时建议降低这个值,减少内存消耗,建议取1024 |
Doris/TCHouse-D 类型节点级别
如下为 Doris/TCHouse-D 目标端在使用场景下支持的高级设置及其描述:
读/写 | 适用场景 | 配置内容: | 描述 |
写 | 仅单表 | sink.properties.*=xxx | 参数描述 : Stream Load 的导入参数。 例如 'sink.properties.column_separator' = ', ' 详细配置参考: |
写 | 仅单表 | sink.properties.columns=xxx | 参数描述 : 配置 columns 的函数映射关系。 例如 'sink.properties.columns' = 'dt,page,user_id,user_id=to_bitmap(user_id)' |
写 | 单表 + 整库 | sink.batch.size = 100000 sink.batch.bytes= 83886080 sink.batch.interval= 10s | 参数描述 : 提高写入 doris 效率 注意事项 : tm cu 建议设置为2CU,避免 tm oom |
八、常见问题
1. MySql serverid 冲突
错误信息:
com.github.shyiko.mysql.binlog.network.ServerException: A slave with the same server_uuid/server_id as this slave has connected to the master。
解决办法:目前已经优化增加随机生成 serverid,之前的任务中如果在 mysql 高级参数中显示指定了 server-id 建议删除,因为可能多个任务使用了相同的数据源,并且 server-id 设置的相同导致冲突。
2. 报 binlog 文件找不到错误信息:
错误信息:
Caused by: org.apache.kafka.connect.errors.ConnectException: The connector is trying to read binlog starting at GTIDs xxx and binlog file 'binlog.xxx', pos=xxx, skipping 4 events plus 1 rows, but this is no longer available on the server. Reconfigure the connector to use a snapshot when needed。
错误原因:
作业正在读取的 binlog 文件在 MySQL 服务器已经被清理时,会产生报错。导致 Binlog 清理的原因较多,可能是 Binlog 保留时间设置的过短;或者作业处理的速度追不上 Binlog 产生的速度,超过了 MySQL Binlog 文件的最大保留时间,MySQL 服务器上的 Binlog 文件被清理,导致正在读的 Binlog 位点变得无效。
解决办法:如果作业处理速度无法追上 Binlog 产生速度,可以考虑增加 Binlog 的保留时间也可以优化作业减轻反压来加速 source 消费。如果作业状态没有异常,可能是数据库发生了其他操作导致 Binlog 被清理,从而无法访问,需要结合 MySQL 数据库侧的信息来确定 Binlog 被清理的原因。
3. MySQL 报连接被重置
错误信息:
EventDataDeserializationException: Failed to deserialize data of EventHeaderV4 .... Caused by: java.net.SocketException: Connection reset。
错误原因:
1. 网络问题。
2. 作业存在反压,导致 source 无法读取数据,binlog client 空闲,如果 binlog 连接在超时后仍然空闲 mysql 服务器会断开空闲的连接。
解决方法:
1. 如果是网络问题,可以调大 mysql 网络参数 set global slave_net_timeout = 120; (默认30s) set global thread_pool_idle_timeout = 120。
2. 如果是作业反压导致,可以通过调节作业减轻反压,例如增加并行度,提升写入速度,提升 taskmanager 内存减少 gc。
4. Mysql2dlc 任务 JobManager Oom
错误信息:
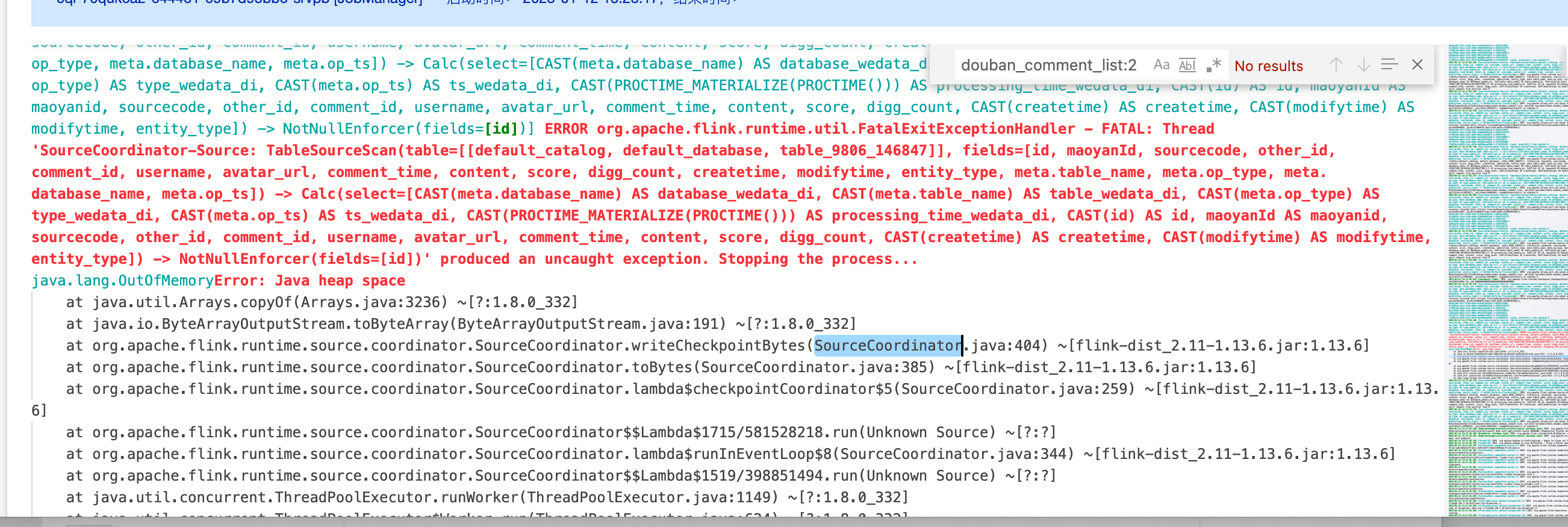
1. 用户数据量比较大,可以调大 jobmanager CU 数,使用 mysql 高级参数 scan.incremental.snapshot.chunk.size 调大 chunk size 大小,默认是8096。
2. 用户数据量不大,但是主键最大值-最小值的差值却很大,导致使用均分 chunk 的策略时划分很多 chunk,修改分布因子,让用户数据走非均匀的数据切分逻辑,split-key.even-distribution.factor.upper-bound=5.0d,默认值分布因子已经修改为10.0d。
5. 用户的 binlog 数据格式不对,导致 debezium 解析异常
错误信息:
ERROR io.debezium.connector.mysql.MySqlStreamingChangeEventSource [] - Error during binlog processing. Last offset stored = null, binlog reader near position = mysql-bin.000044/211839464. 2023-02-20 21:37:28.480 [blc-172.17.48.3:3306] ERROR io.debezium.pipeline.ErrorHandler [] - Producer failure io.debezium.DebeziumException: Error processing binlog event.
解决方法:
修改 binlog_row_image=full 后需要重启数据库。
6. 是否支持 gh-ost?
支持,不会迁移 Online DDL 变更产生的临时表数据,只迁移源库使用 gh-ost 执行的原始 DDL 数据,同时您可以使用默认的或者自行配置 gh-ost 影子表和无用表的正则表达式。
7. Doris 规格如何选型及调优?
9. 导入任务过多,新导入任务提交报错 “current running txns on db xxx is xx, larger than limit xx ”?
调整 fe 参数 : max_running_txn_num_per_db,默认100,可适当调大,建议控制在500以内。
10. 导入频率太快出现 err=[E-235] 错误?
参数调优建议:可通过适当调大 max_tablet_version_num 参数暂时解决,此参数默认200,建议控制在2000以内。
业务调优建议:降低导入频率才能根本解决这个问题。
11. 导入文件过大,被参数限制。报错 “The size of this batch exceed the max size ”?
调整 be 参数 : streaming_load_max_mb,建议超过需要导入的文件大小。
12. 导入数据报错:“[-238]”?
原因:-238 错误通常出现在同一批导入数据量过大的情况,从而导致某一个 tablet 的 Segment 文件过多(由 )。
参数调优建议:可适当调大BE参数max_segment_num_per_rowset ,此参数默认值200,可按倍数调大(如400、800),建议控制在2000以内;
业务调优建议:建议减少一批次导入的数据量。
13. 导入失败,报错:“too many filtered rows xxx, "ErrorURL":"或 Insert has filtered data in strict mode, tracking url=xxxx.”?
原因:表的 schema、分区等与导入的数据不匹配。可在 TCHouse-D Studio 或客户端执行 doris 命令查看具体原因:show load warnings on `<tracking url>`,<tracking url> 即为报错信息中返回的 error url。网络



