WeData 中提供了数据开发相关对象的跨项目克隆的能力,借助于跨项目克隆,可以实现从一个项目中将已经创建好的任务、工作流等对象克隆到另外一个项目中。
使用场景
在 A 项目为开发或者测试项目,B 项目为生产项目,通过跨项目克隆的方式将 A 项目中的任务、工作流等对象克隆到 B 项目中。
使用限制
注意:
当前支持的任务类型包括:离线同步、HiveSQL、SparkSQL、PySpark、Spark、MapReduce、Impala、Trino、StarRocks、DLC SQL、DLC PySpark、DLC Spark、DLC Spark Streaming、Setats SQL、TCHouse-P、TCHouse-X、TCHouse-X SQL、TDSQL-PostgreSQL、Python、Shell、JDBC SQL、分支节点、归并节点、SSH 节点。
目前仅支持同一个地域下面的项目克隆,暂不支持跨地域的克隆。
跨项目克隆建议源项目和目标项目一对一克隆,不建议多个源项目克隆到一个目标项目。多个源项目克隆到一个目标项目可能导致多个源项目的重名任务在目标项目中多次覆盖。
工作流调度模式的项目不支持跨项目克隆功能。
使用前提
案例说明
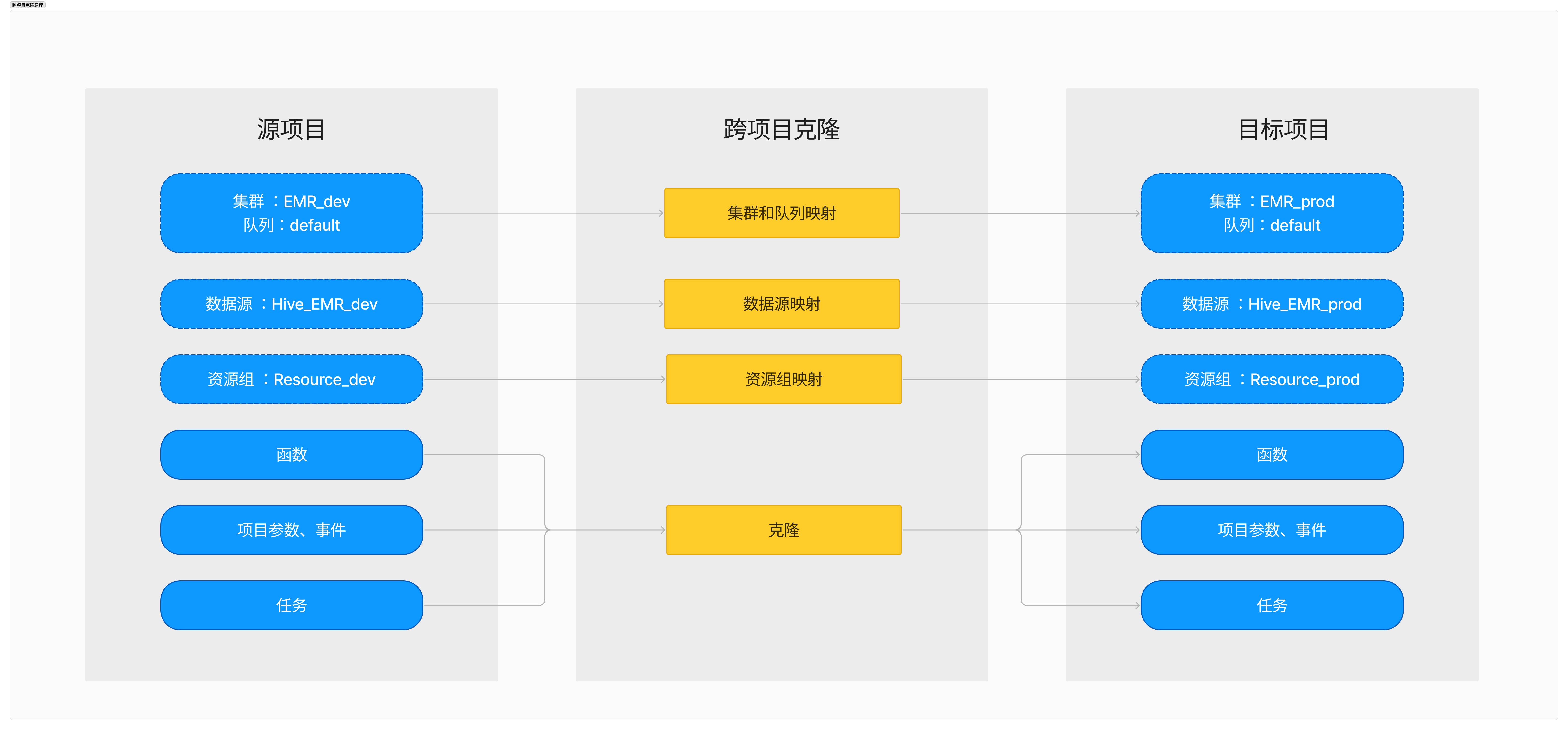
下面以 EMR 引擎为例,介绍通过跨项目克隆能力从源项目克隆对象到目标项目。跨项目克隆的原理是在源项目中选择对应的任务等对象,然后根据选择的目标项目将源项目中任务等对象的属性在目标项目中做映射,之后根据映射的结果在目标项目中创建对应的任务。
环境准备
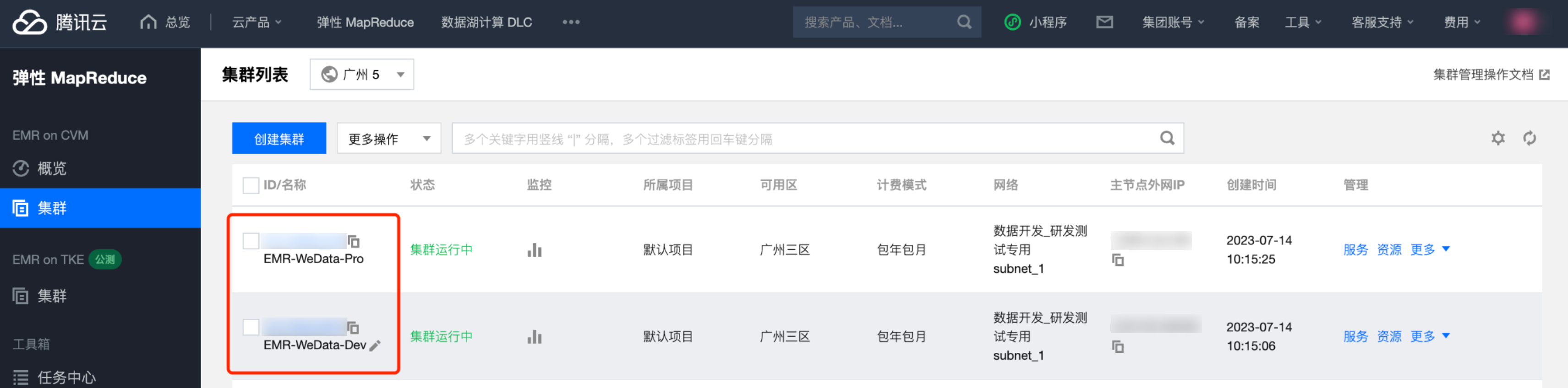
计算引擎侧(EMR )
在 EMR 中创建两个集群:开发集群(EMR-WeData-Dev),生产集群(EMR-WeData-Pro)。
WeData 侧
1. 登录 数据开发治理平台 WeData 控制台。
2. 单击左侧菜单中的项目列表,创建源项目用作开发项目,目标项目用作生产项目。
3. 单击左侧执行资源组,创建开发项目使用的资源组以及生产项目使用的资源组,并关联到对应项目。有关调度资源组创建、关联项目,请参考 调度资源组配置。
源项目配置
进入源项目后单击右上角项目管理,在左侧栏配置引擎、资源组、数据源等信息。
存算引擎
绑定 EMR 集群:EMR-WeData-Dev
执行资源组
绑定调度资源组,名称:广州调度资源组 -dev。
数据源
绑定了 EMR 存算引擎后,在项目管理-数据源管理中会自动生成 Hive 系统数据源。
目标项目配置
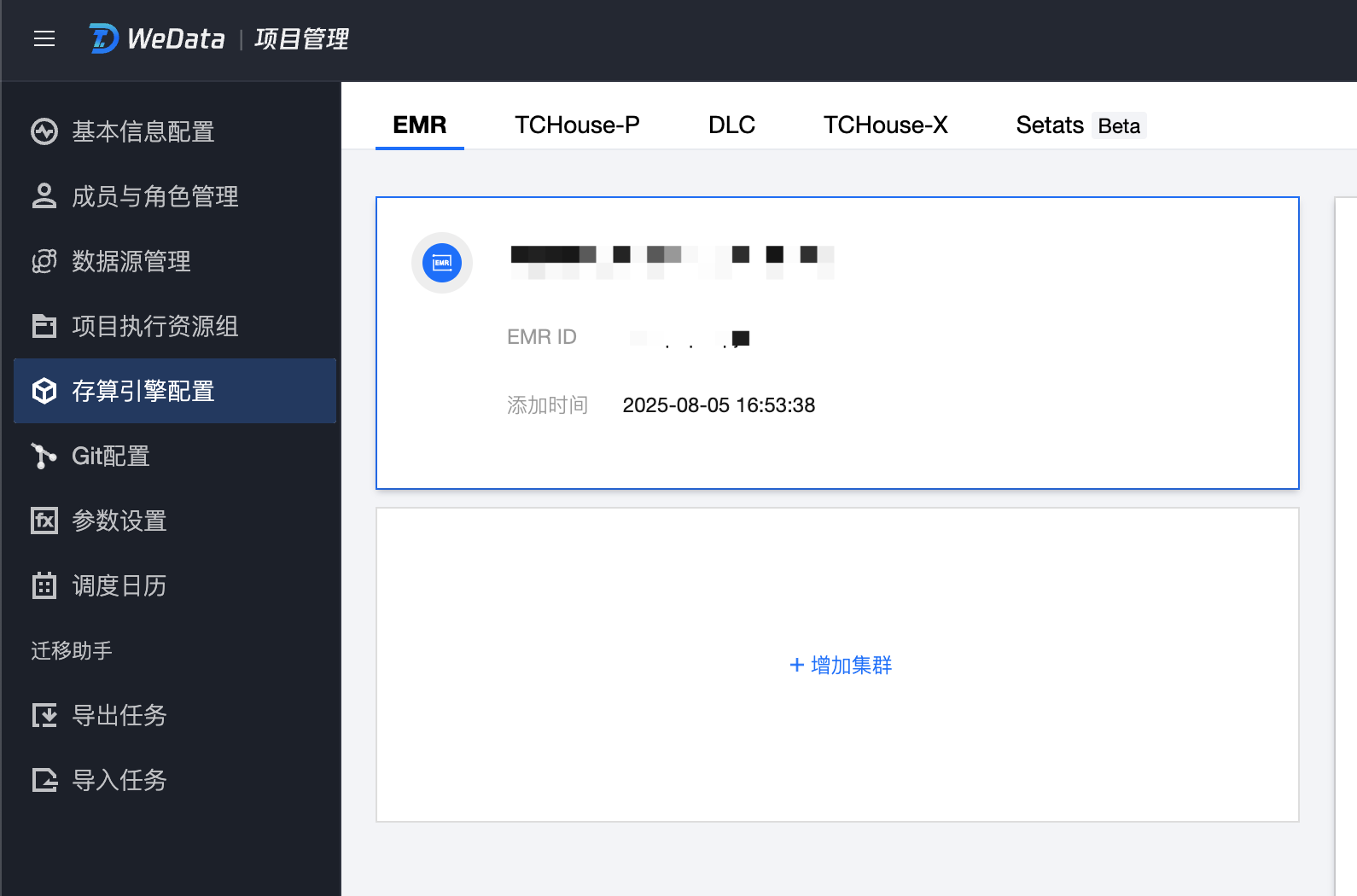
进入目标项目后单击右上角项目管理,在左侧栏配置引擎、资源组、数据源等信息。
存算引擎
绑定 EMR 集群
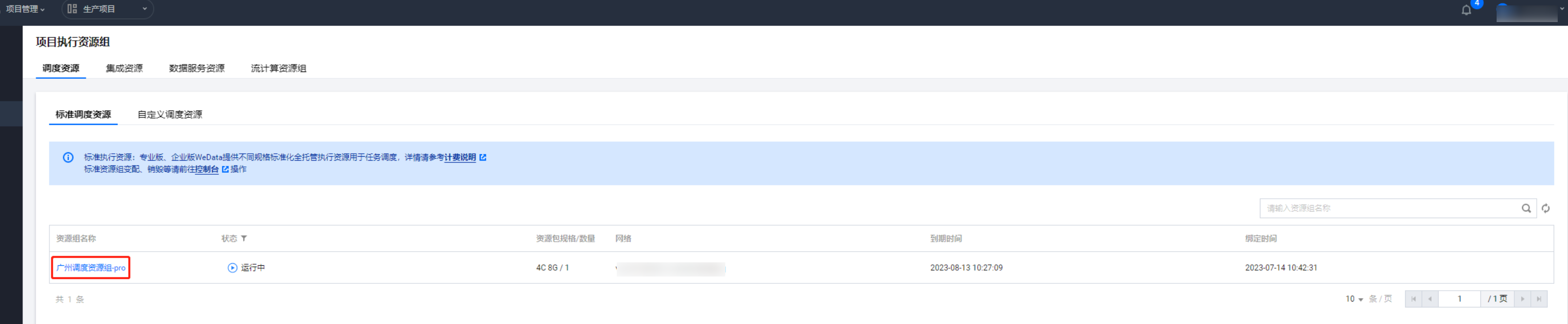
执行资源组
绑定标准调度资源组,名称:广州调度资源组 -pro。
数据源
绑定了 EMR 存算引擎后,在项目管理-数据源管理中会自动生成 Hive 系统数据源。

源项目中数据开发
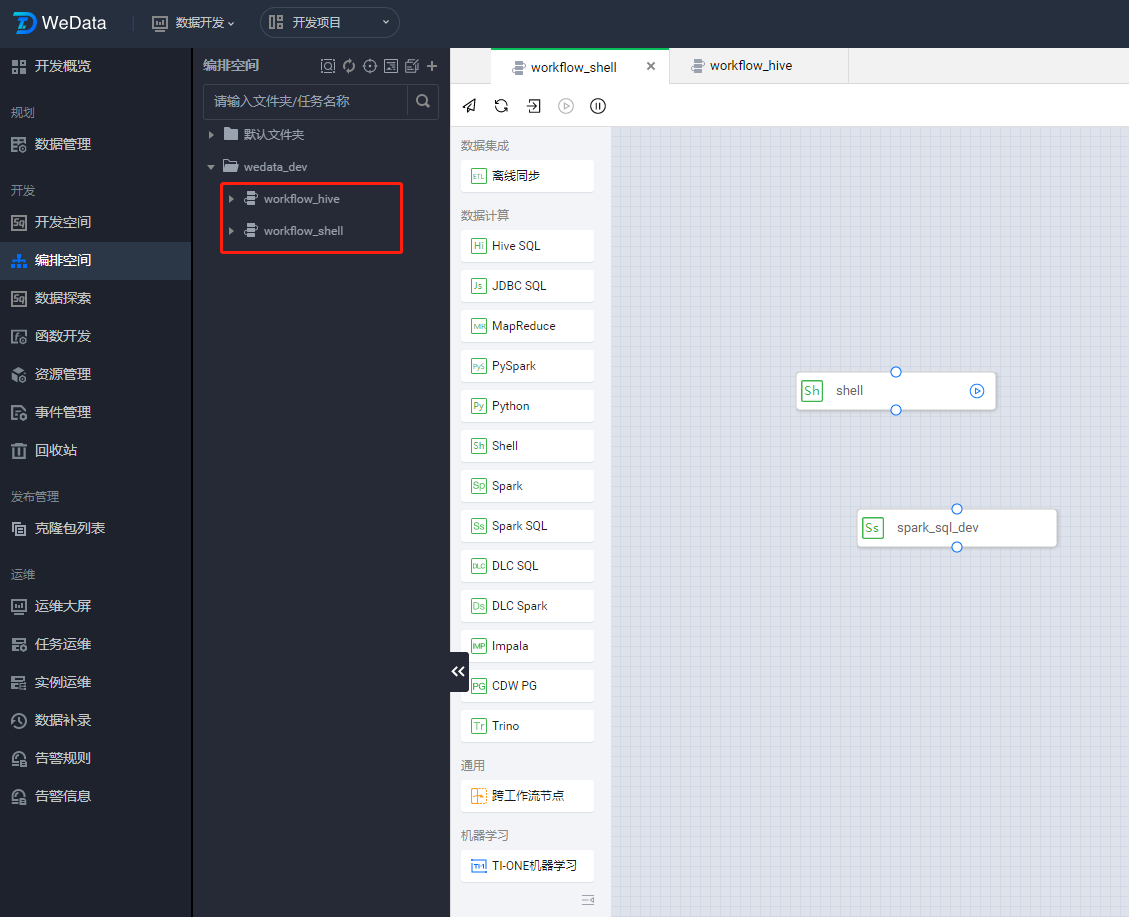
工作流
创建 workflow_hive 和 workflow_shell 工作流,在工作流中开发对应的任务。例如,下图中 workflow_shell 中开发了名称为 shell、spark_sql_dev 的任务。
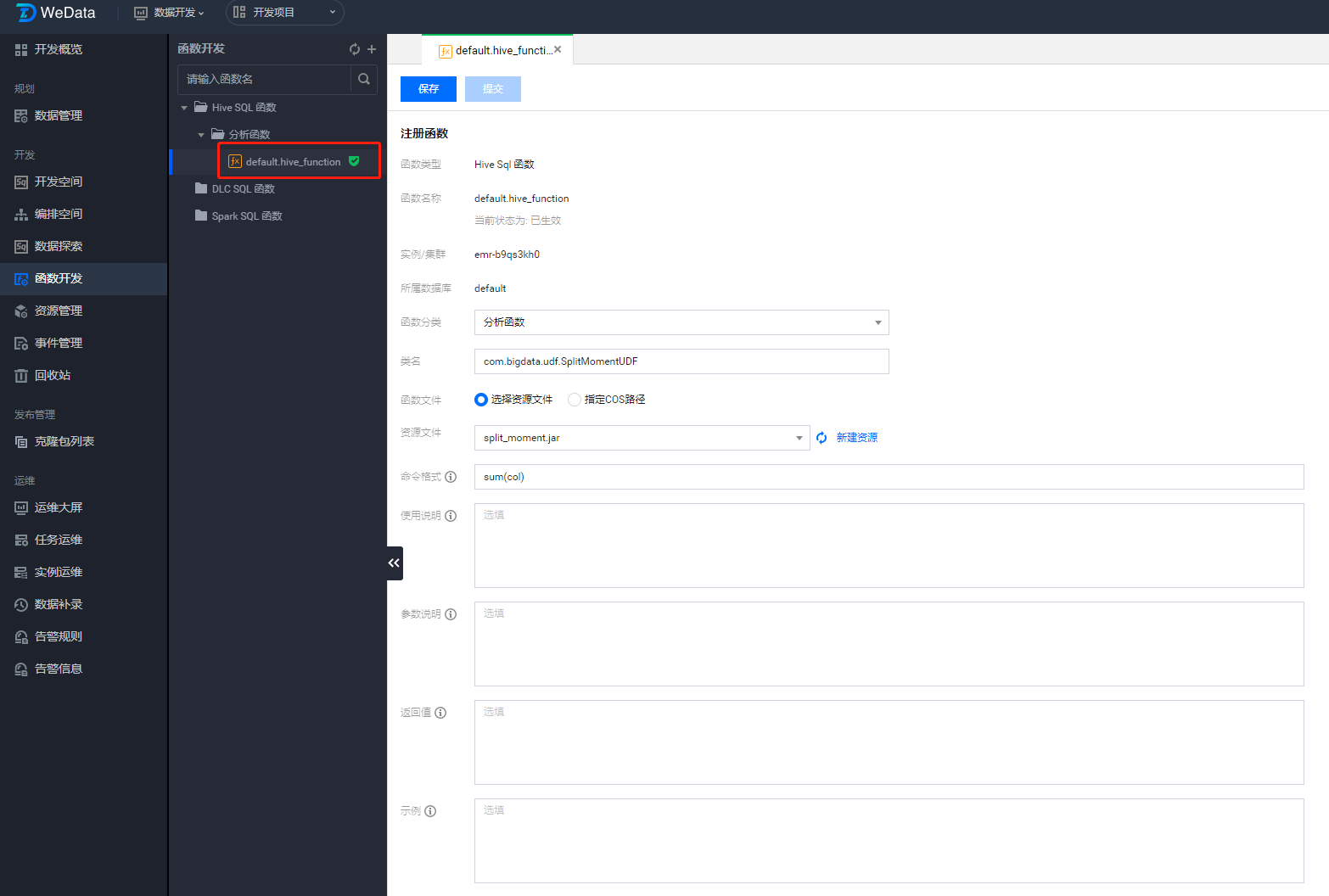
函数
在函数管理中创建函数,例如这里源项目的 default 库下面创建了 hive_function 的函数。
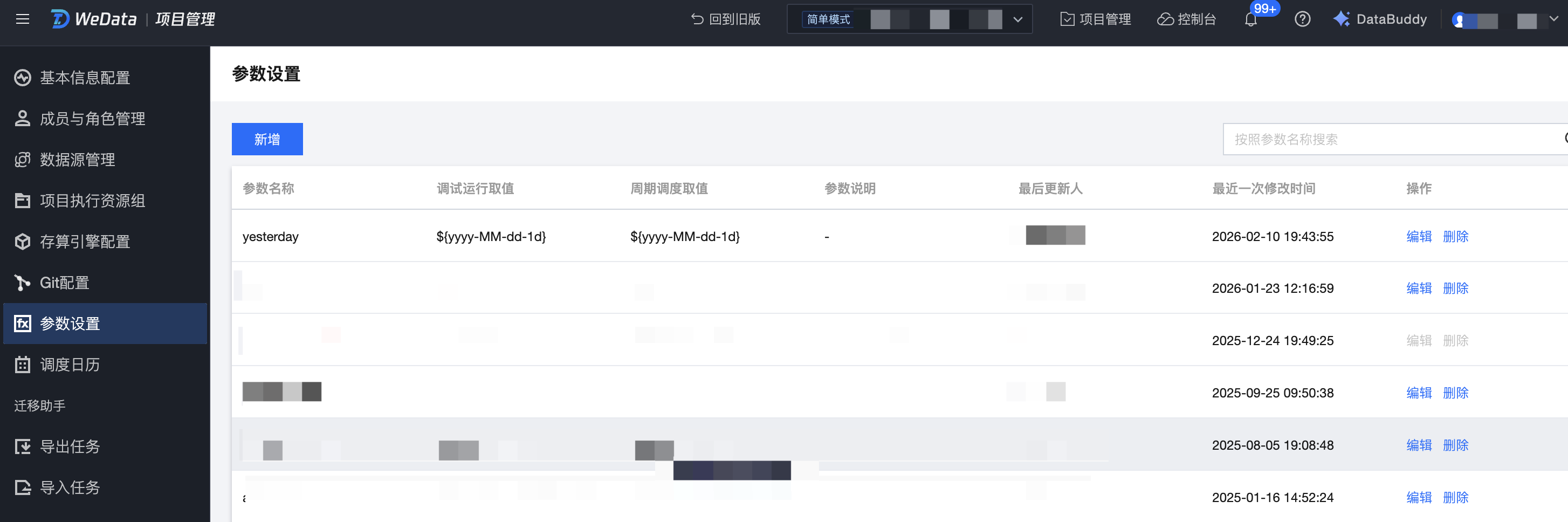
项目参数
在源项目的项目管理-参数设置中创建项目可用的调度参数。例如,这里在开发环境中创建了取值为 ${yyyy-MM-dd-1d} 的日期参数 yesterday。
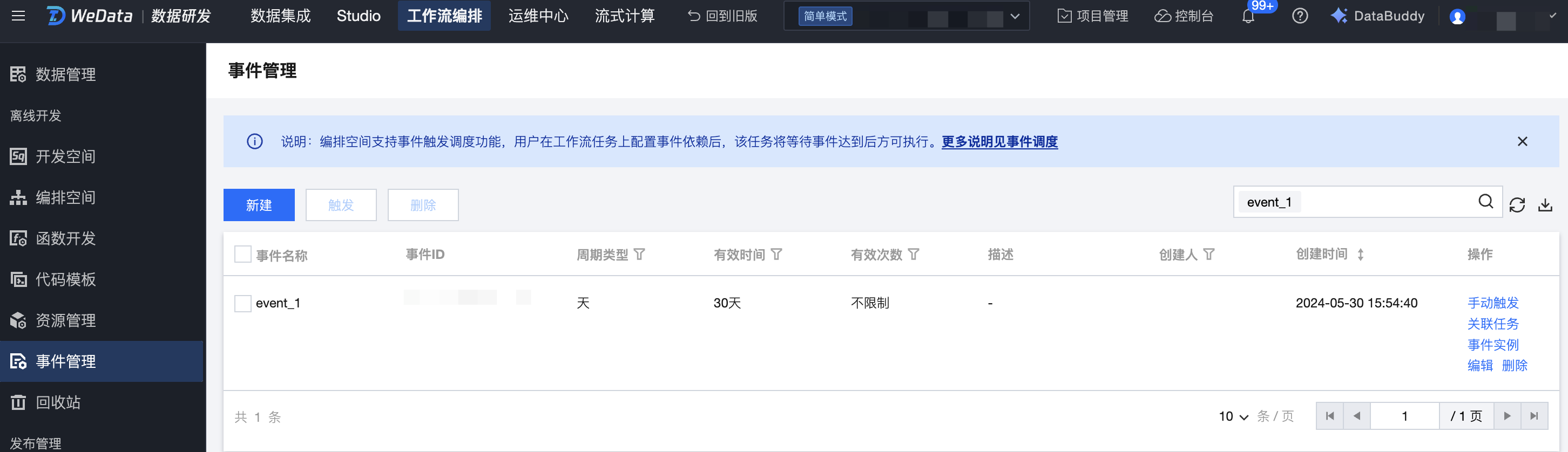
事件
在源项目的事件管理中创建调度任务需要依赖的事件,例如这里创建了 event_1 的事件。
在开发环境中完成任务开发以后,使用跨项目克隆功能将开发环境的任务克隆到生产环境。
跨项目克隆操作流程
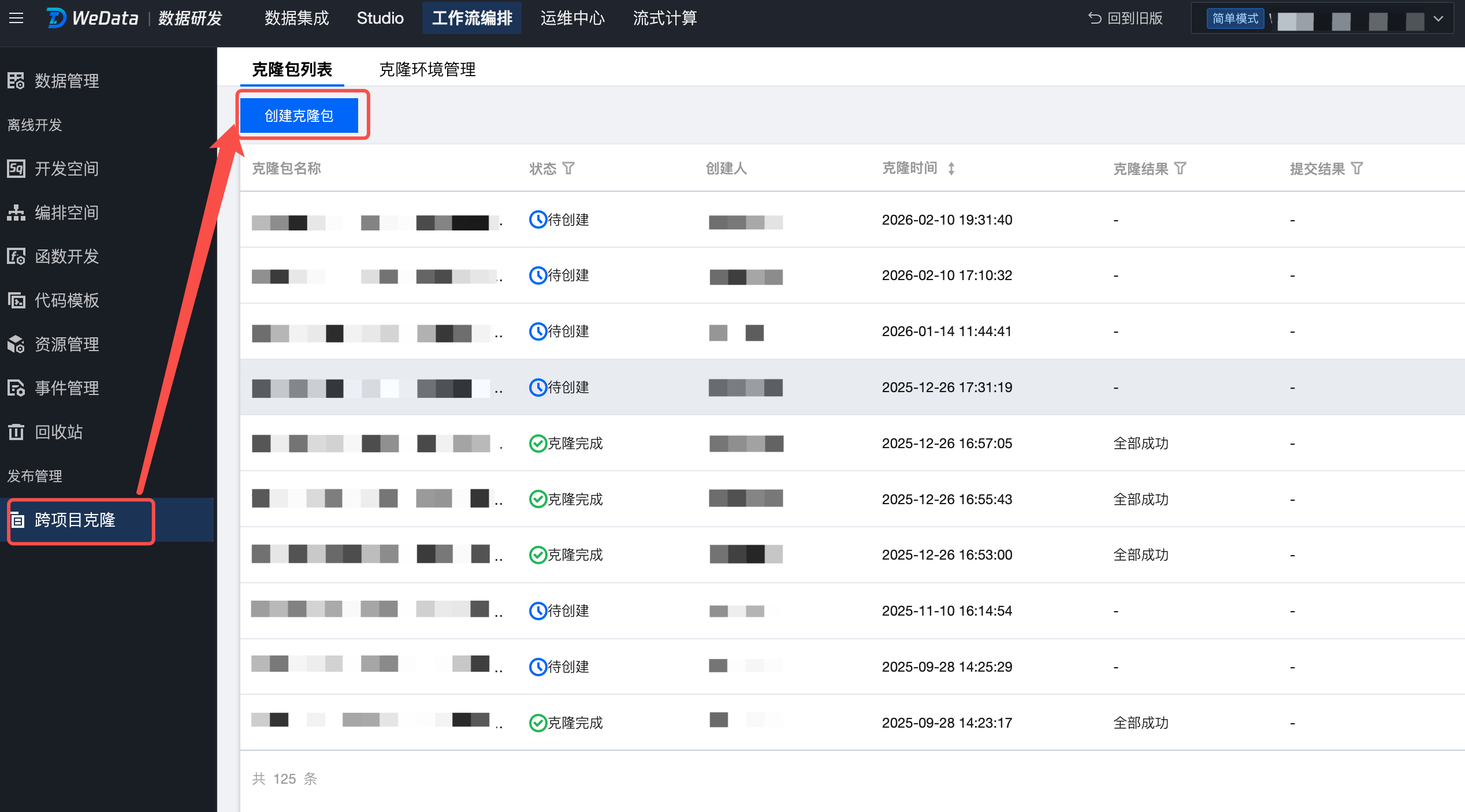
创建克隆包
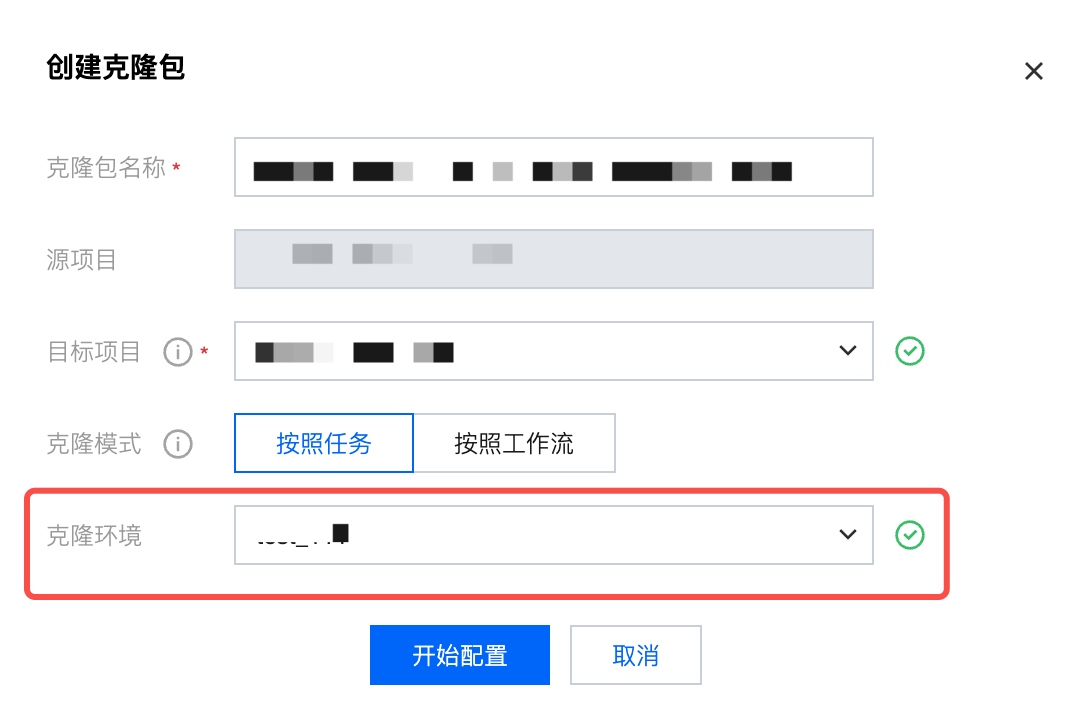
1. 进入开发项目,单击创建克隆包,进入创建克隆包页面。
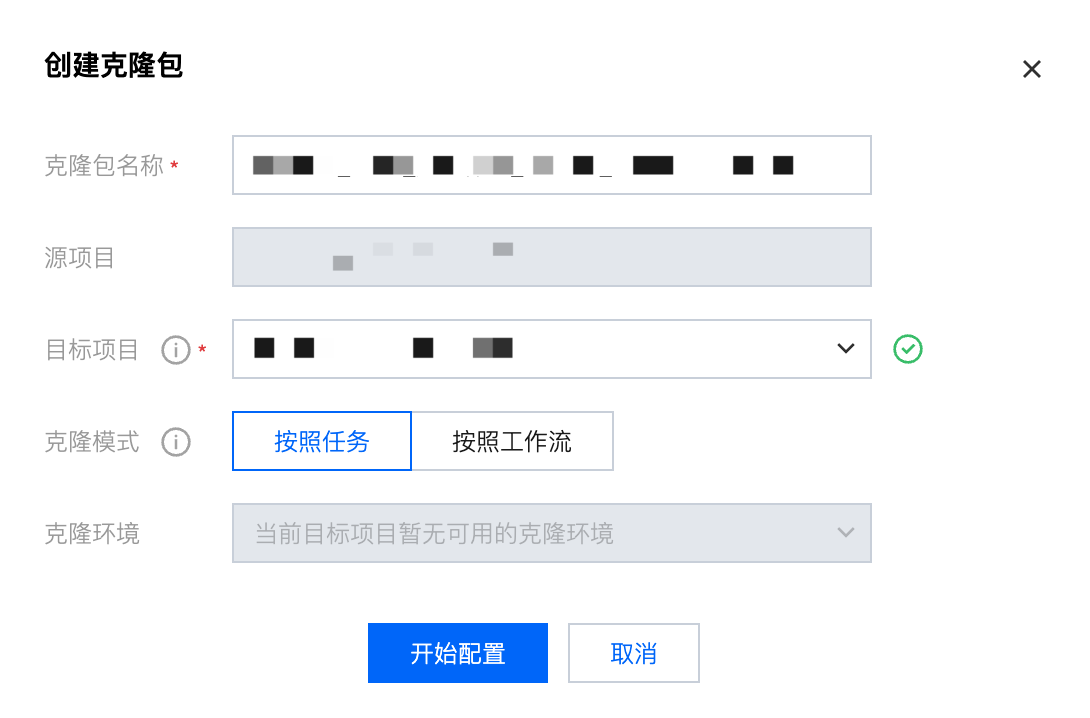
2. 填写克隆包名称及目标项目(源项目默认为当前项目)并选择按工作流模式,单击开始配置,进入克隆包配置页面。
第一步:添加克隆项
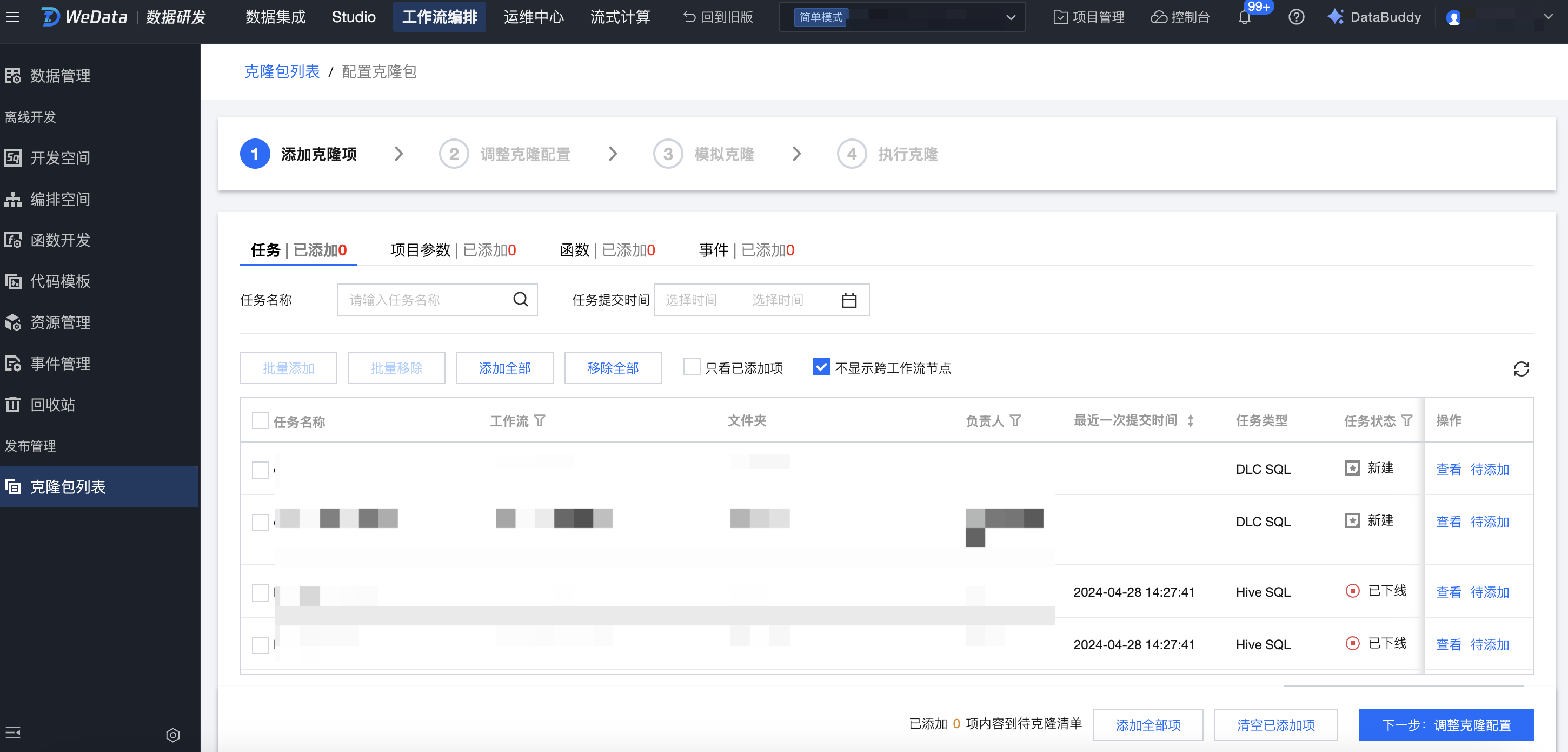
功能说明:
区域 | 说明 |
1 | 克隆项分类:工作流/任务、项目参数、函数、事件四部分内容,待克隆列表已添加数字联动显示已选取的克隆对象个数。 时间筛选:通过工作流提交时间筛选所需要查看的内容。 |
2 | 批量添加/移除:当用户在同一个克隆项分类中选择多条内容时,可以一键添加/移除选中的内容。 添加/移除全部:用户可以一键添加/移除项目内同一个克隆对象分类中的所有内容。 批量修改资源组:选中多条任务,批量修改资源组。 支持查看和待添加两种操作: 查看:用户可以单击查看,可以跳转至对应工作流、项目参数、函数及事件详情。 待添加/移除:用户可以对列表中的工作流、项目参数、函数及事件进行单独添加或移除操作。 |
添加完需要克隆的内容后,选择一个默认的调度资源组,单击下一步:调整克隆配置。
第二步:调整克隆配置
在克隆配置中需要配置对应的映射关系,包括:计算引擎、资源队列、数据源、数据库等。
计算引擎
源项目计算引擎展示任务中用到的计算引擎,不支持修改。
目标项目计算引擎默认匹配同类型同名的计算引擎,用户可以选择其他同类型的引擎。
资源队列
源项目资源队列展示任务中用到的资源,不支持修改。
目标资源队列默认匹配同类型同名的资源队列,用户可以选择其他同类型的队列。
数据源
源项目数据源展示任务中用到的所有数据源,不支持修改。
目标数据源默认匹配同类型同名的数据源,用户可以选择其他同类型的数据源。
函数数据库
源项目函数数据库展示任务中用到的所有数据库,不支持修改。
目标项目函数数据库默认匹配同类型同名的函数数据库,用户可以选择数据库。
说明:
当前支持 EMR/DLC 引擎映射。
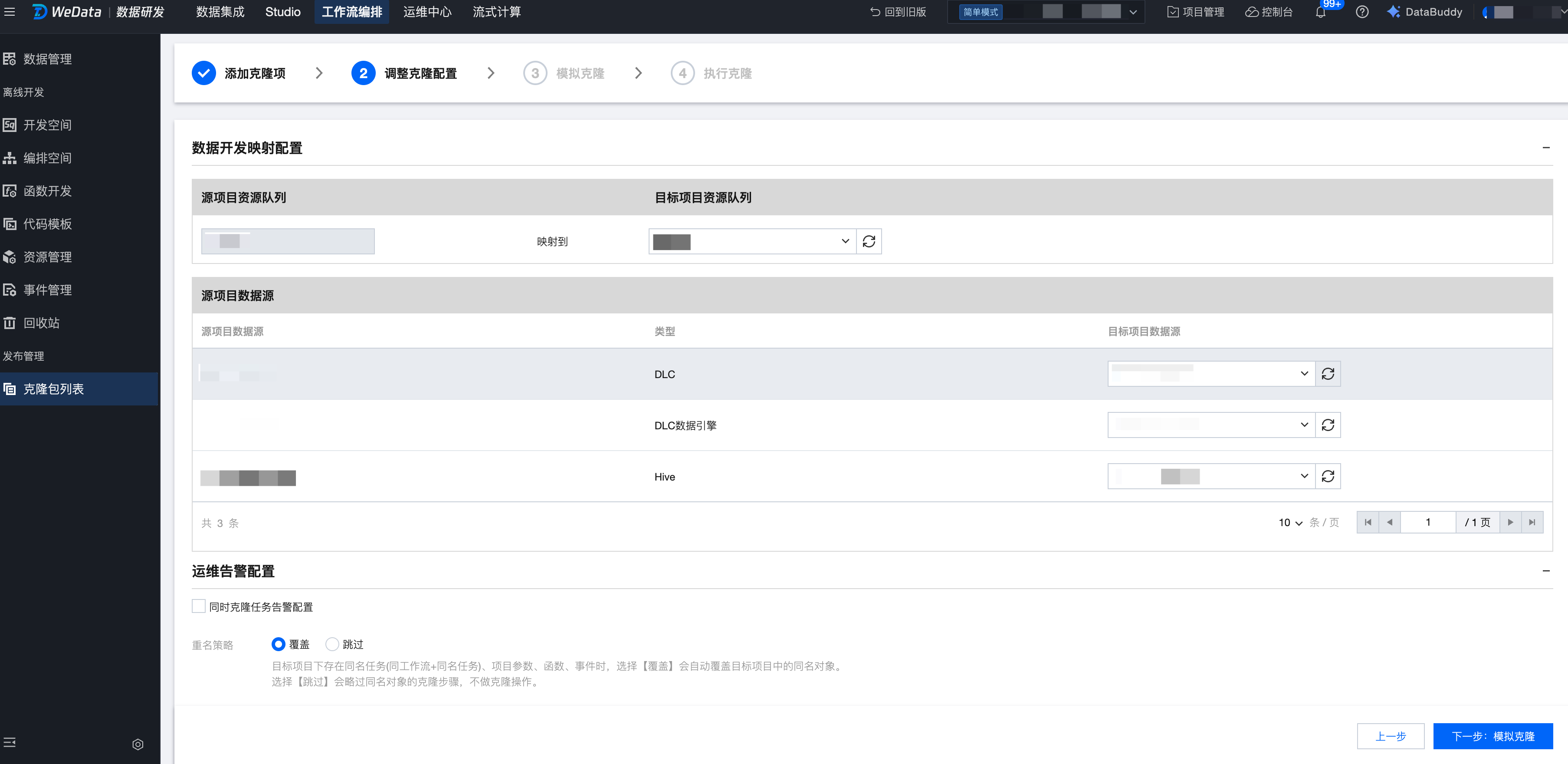
克隆策略:
重名策略:目标项目下存在同名文件夹、工作流、任务、项目参数、函数、事件时,支持跳过或覆盖策略。
任务自动提交:
是:当用户选择任务自动提交时,任务自动提交到调度中状态,下个调度周期生成对应的实例。
否:当用户不选择任务自动提交时,未调度的任务在克隆完成后需要手动提交。
项目参数自动提交、函数和事件自动保存默认打开。
第三步:模拟克隆
模拟克隆会对用户选中的克隆对象进行预先的模拟克隆,预览克隆后可能会出现的失败情况和依赖找不到的情况,从而帮助用户在克隆前重新调整任务的属性,避免克隆的风险。
在模拟克隆中提供了预计克隆的状态:
克隆失败:会显示当前对象模拟克隆失败的原因,例如在目标项目中找不到跨工作流节点对应的任务等。
克隆成功(有预警):任务会克隆成功,但是任务的上游任务和上游事件可能在目标项目中找不到。
克隆成功(无预警):克隆成功,模拟克隆成功。
1. 模拟克隆只是用当前任务的状态做预检查,由于克隆过程中源项目和目标项目可能会有变更,不代表克隆后一定会出现这些情况。所以,针对模拟克隆有问题的情况,用户可以点击下方的复选框继续选择克隆。
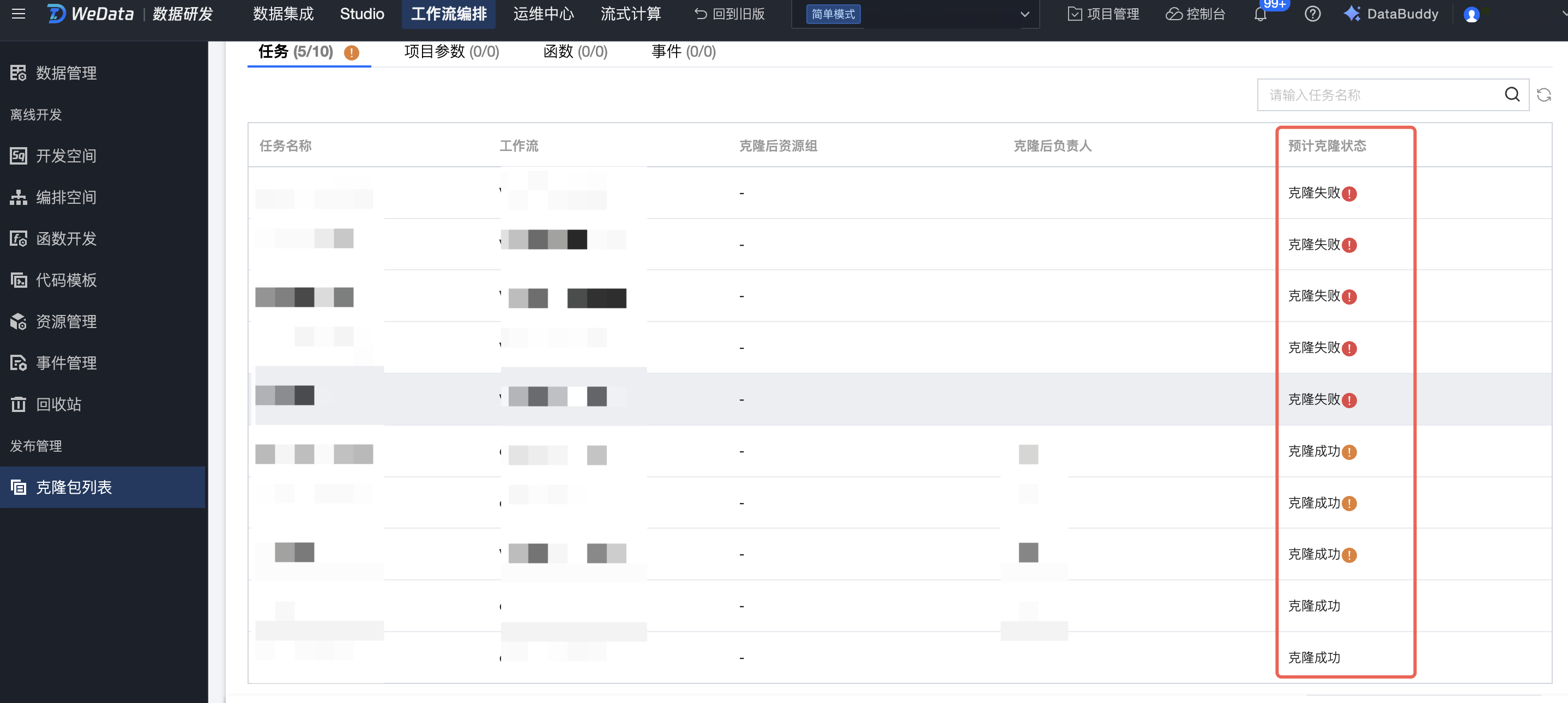
2. 单击下一步:执行克隆,进入执行克隆。
第四步:执行克隆
执行克隆后,等待一段时间可以查看最终的克隆报告。
查看报告:克隆报告详细展示了克隆概览、克隆结果、克隆明细。
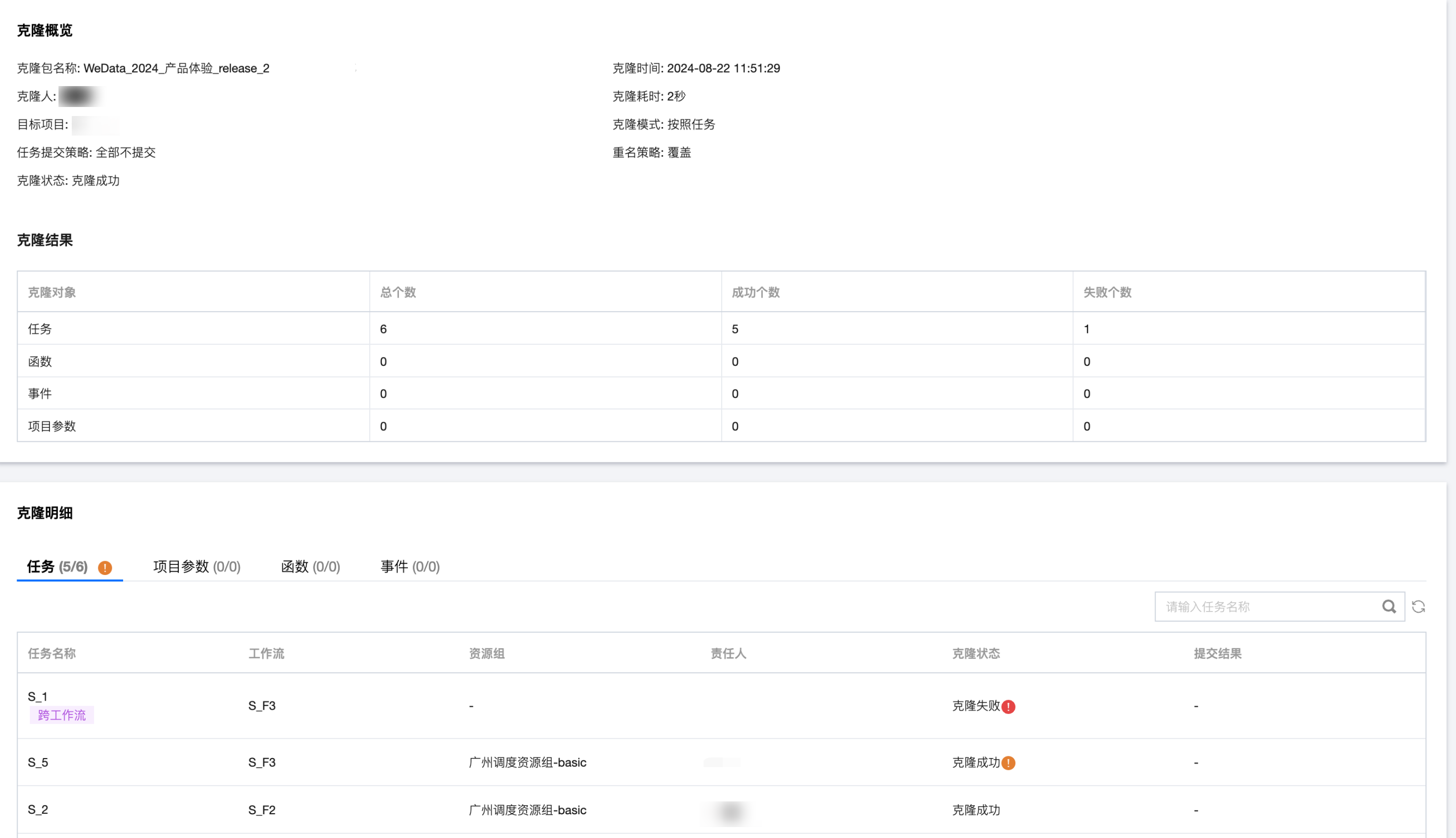
克隆概览:默认展示克隆包名称、时间、模式等信息。
克隆结果:以表格形式分别展示工作流/任务、项目参数、函数、事件的总个数、成功/失败个数。
克隆明细:按照工作流、项目参数、函数和事件分别展示克隆包中具体的内容和状态,以及对象克隆失败的原因。
克隆环境配置
克隆环境的功能,是帮助您提前配置好源项目和目标项目的实体的映射关系,并在后续的克隆中可以快捷使用。支持配置:引擎映射、资源队列映射、数据源映射、资源组映射、运行告警配置、重名策略和任务提交策略。
使用流程:
第一步:创建克隆环境
跨项目克隆>克隆环境管理>新建克隆环境
仅项目管理员可操作新建。
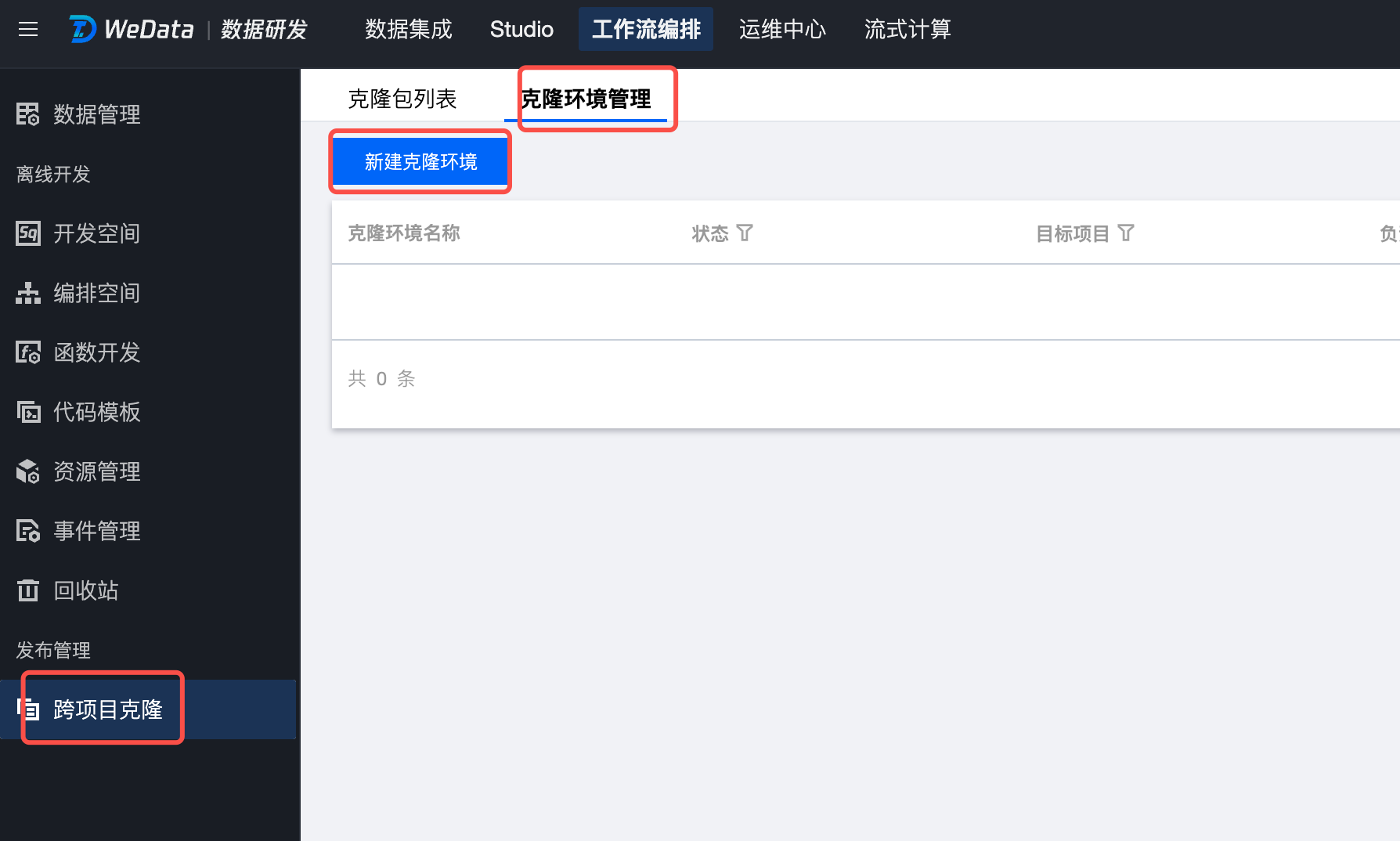
配置克隆环境:定义源项目和目标项目实体间的映射关系,支持配置:引擎映射、资源队列映射、数据源映射、资源组映射、运行告警配置、重名策略和任务提交策略,您可按需进行配置。
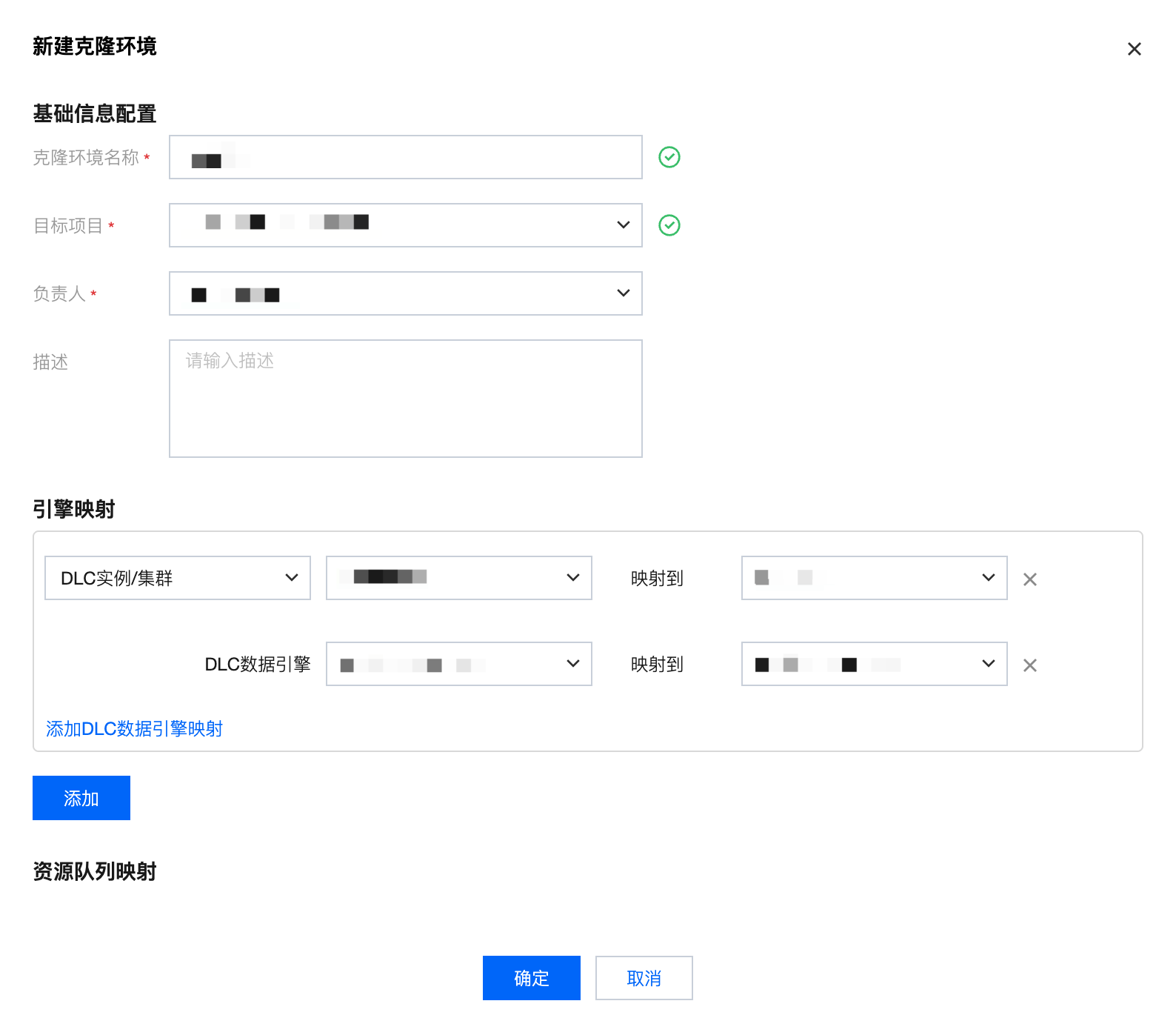
第二步:新建克隆包时使用克隆环境
在新建克隆包时选择克隆环境,则在进入克隆配置时,映射关系会根据您在克隆环境中定义的环境自动填充,您也可按需修改。
克隆环境管理
克隆环境列表支持克隆环境的查看、编辑、禁用、启用、删除等操作。
查看权限:仅当前账号有目标项目权限时,才能查看
编辑、启用、禁用、删除权限:仅项目管理员,且项目管理员有目标项目权限时,才能操作。

依赖关系说明
跨项目克隆的任务涉及到比较复杂依赖关系的处理,这里介绍一下跨项目克隆的依赖处理原则。
基本假设
源项目名称:(S)Source
目标项目名称:(T)Target
其他项目名称:(O)Other
跨工作流节点:当前工作流内的跨工作流节点。
任务克隆准则
1. 选择什么就克隆什么,不会添加额外的信息,不会改变任务本身的属性。
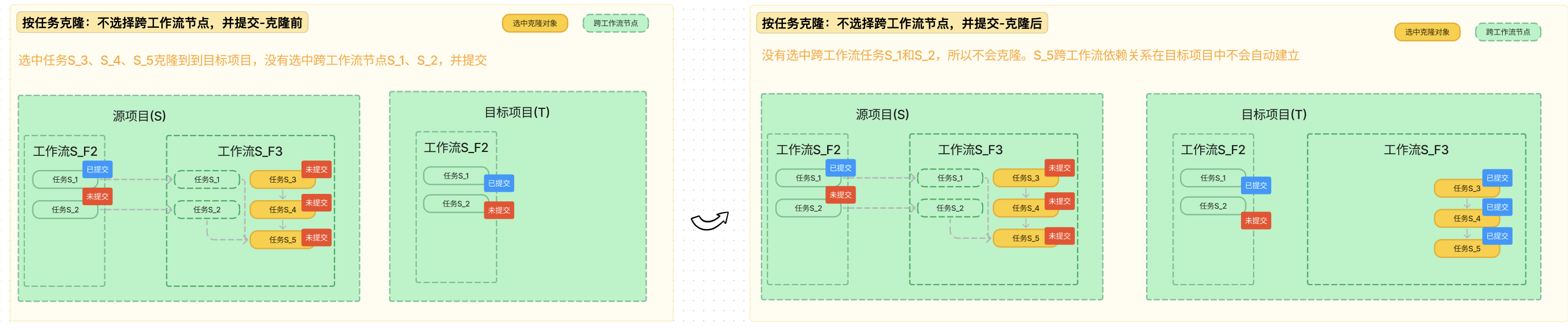
没有选择跨工作流节点,就不会克隆跨工作流节点,不会克隆跨工作流依赖。
跨工作流节点克隆过去仍是跨工作流节点,非跨工作流节点仍是非跨工作流节点,HiveSQL 任务克隆过去依然是 HiveSQL 任务。
2. 依赖于第三个项目的依赖关系,关系不会随着克隆而改变。
依赖于其他项目(O)的依赖关系,克隆过去还是依赖于其他项目(O)。依赖的项目映射除外。
3. 同项目跨工作流依赖,依赖关系是否保留依赖于跨工作流节点和跨工作流节点对应的任务是否在目标项目存在。
4. 工作流内任务依赖,依赖关系是否存在依赖于上游任务是否存在。
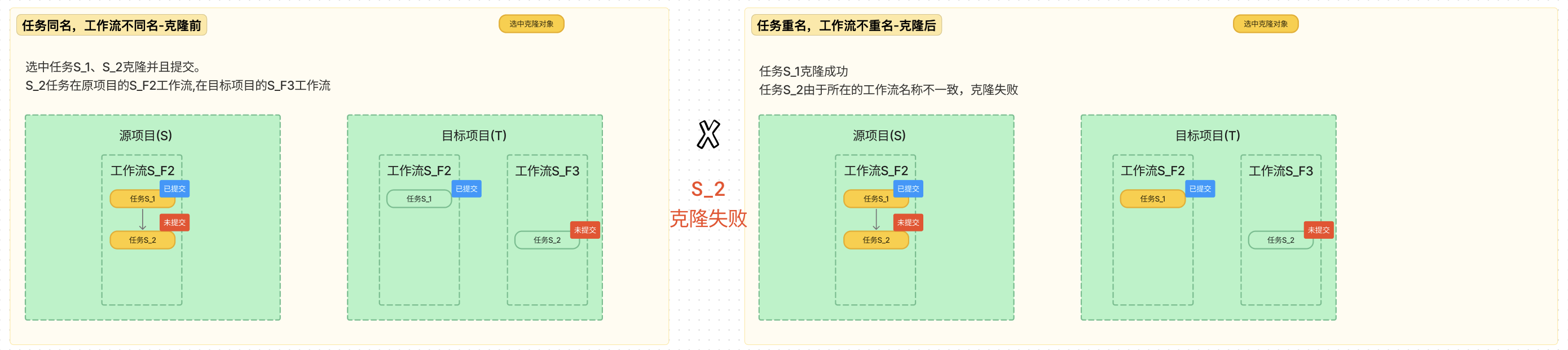
5. 重名的判断原则:任务名称 + 工作流名称一致,才会判断成同一个任务。
6. 跨项目克隆只是任务的复制,无法保证源项目中提交调度成功的任务在目标项目中一定会提交成功。例如,目标项目中上游任务没有提交成功,则下游任务会提交失败。
常见任务依赖场景
按任务克隆:选择跨工作流节点
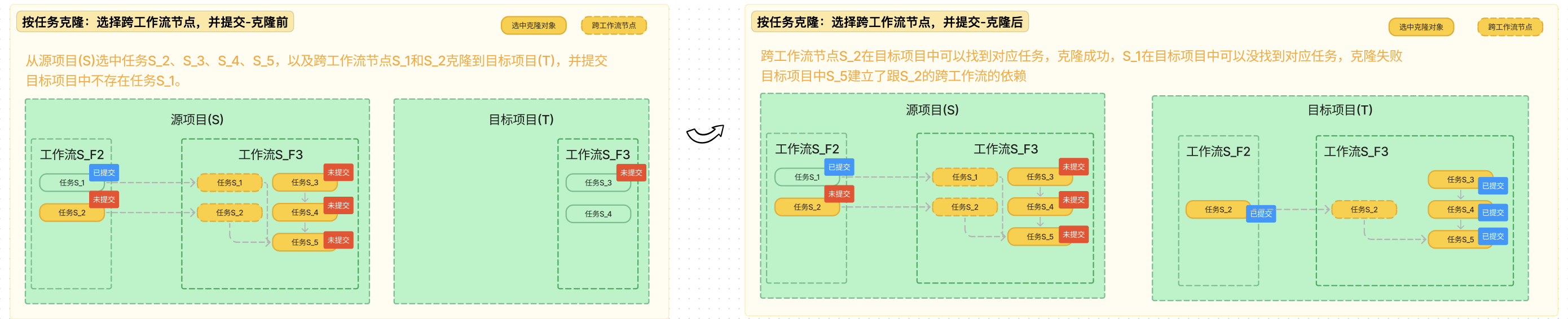
按任务克隆:不选择跨工作流节点
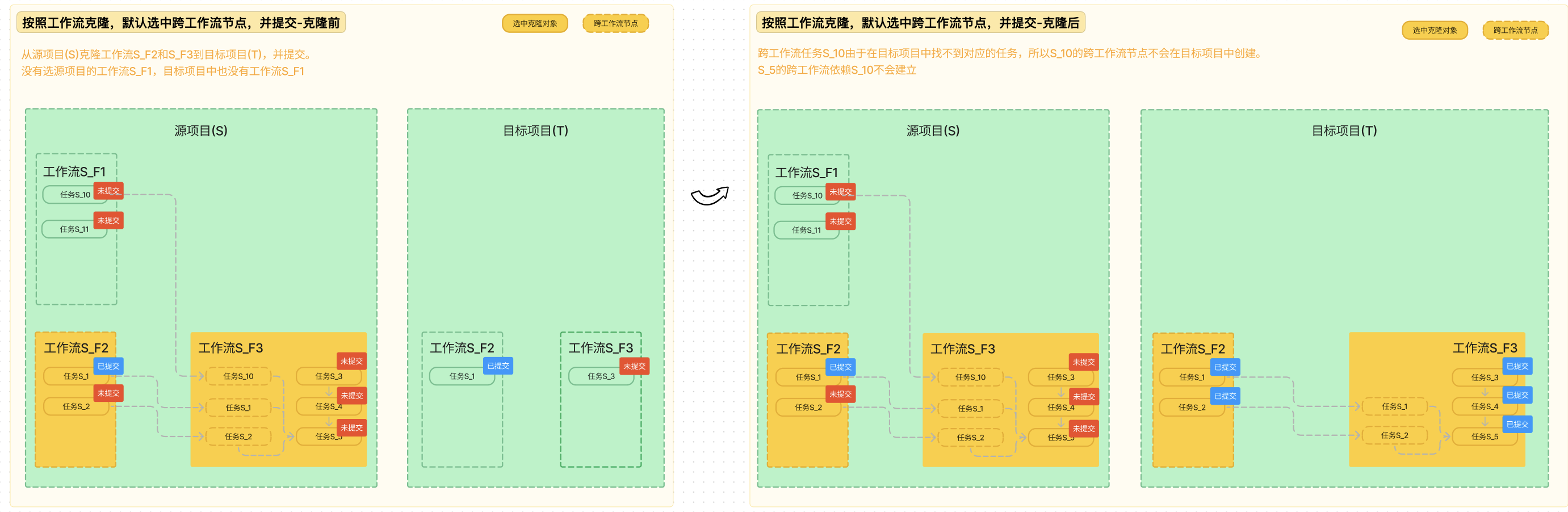
按照工作流克隆:会默认选中工作流中的跨工作流节点
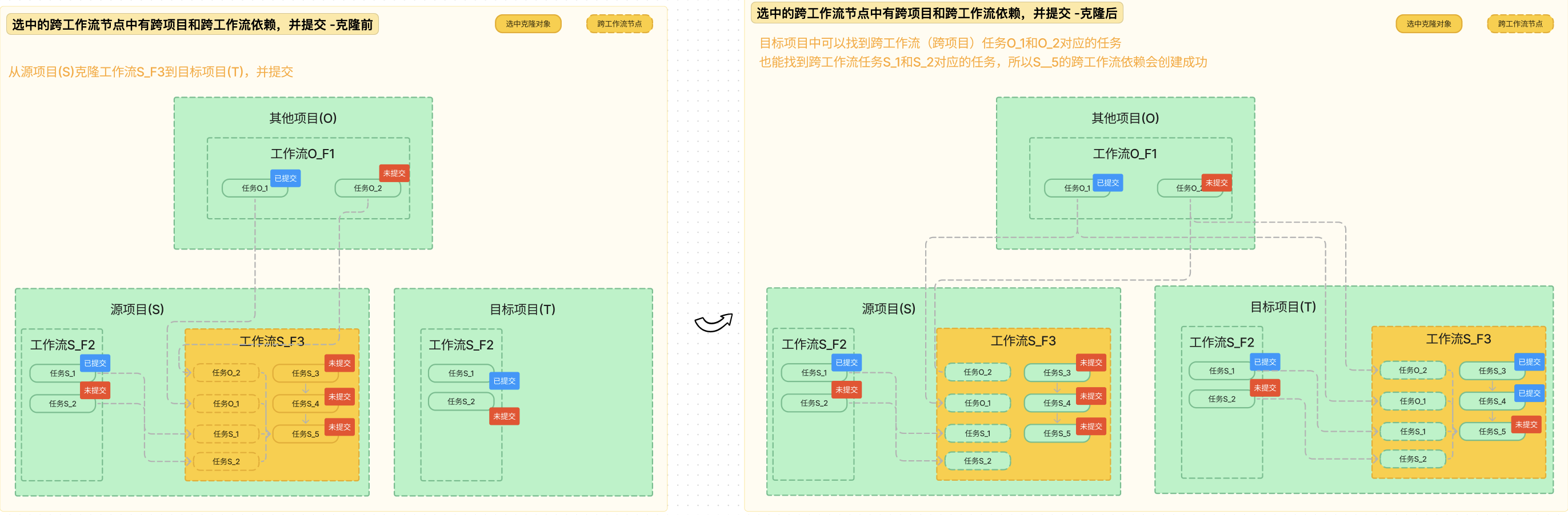
选中的任务跨工作流节点中有跨项目和跨工作流依赖
任务同名,工作流不同名