功能说明
向 WeData 的工作流调度平台提交一个 Spark 任务执行。
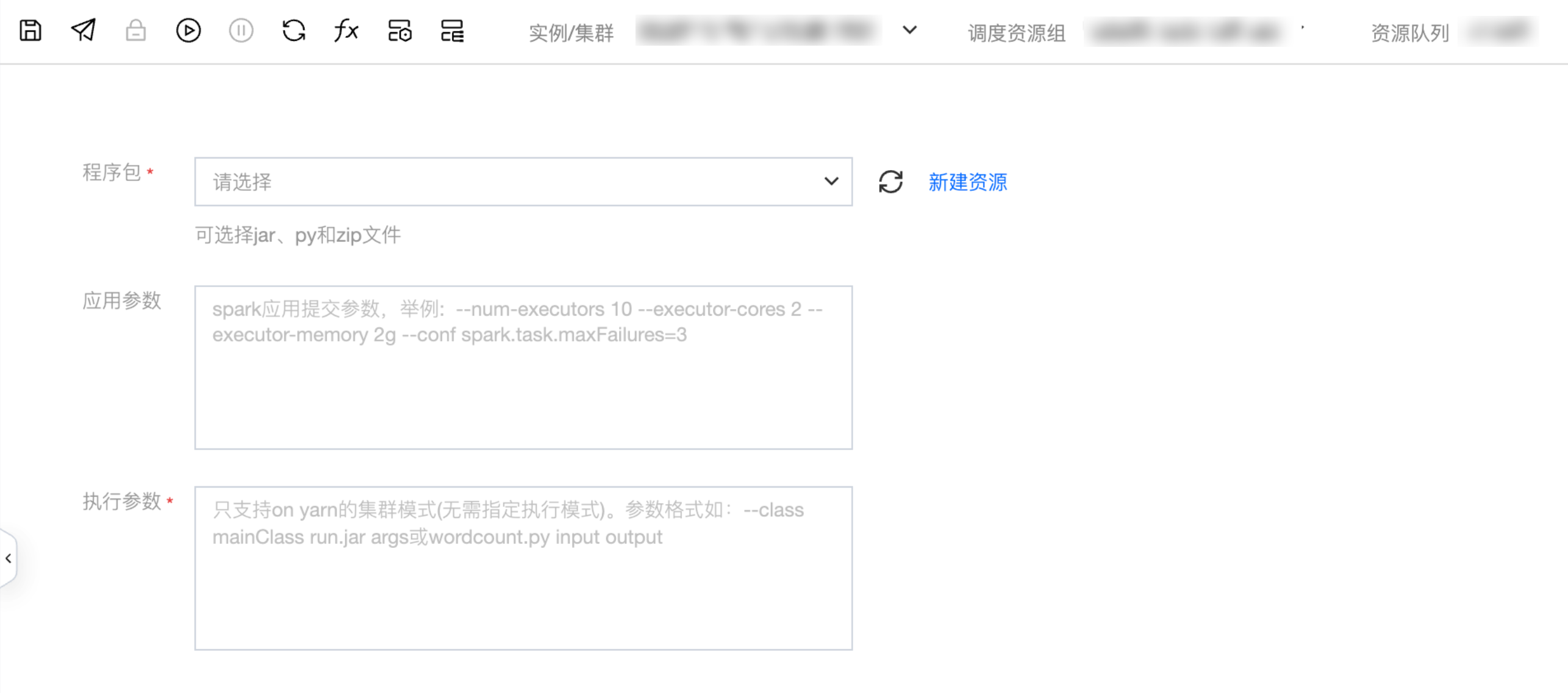
参数说明
参数 | 说明 |
spark 程序 zip 包 | 用户直接上传编写的 spark 程序代码文件,需要打包为 jar 后,将所有自定义的依赖打包为一个 zip 文件,不要打包目录,直接打包文件本身。 |
执行参数 | spark 程序的执行参数,无需用户写 spark-submit,无需指定提交用户,无需指定提交队列,无需指定提交模式(默认为 yarn)。参数格式如:--class mainClass run.jar args 或 wordcount.py input output。 |
应用参数 | spark 的应用参数。 |
SparkJar 示例:
提交一个统计单词个数即 wordcount 的任务,需要提前在 COS 中上传需要统计的文件。
步骤一:本地编写 Spark Jar 任务
创建工程
1. 以 maven 为例,创建一个工程并引入 spark 依赖。
说明:
这里 groupId 和 artifactId 需要替换为的 groupId 和 artifactId。
这里 spark 依赖范围设置为 scope,表示 spark 仅在编译和打包过程中需要提供依赖,运行时依赖由平台提供。
# 生成maven工程,也可以通过ide操作mvn archetype:generate -DgroupId=com.example -DartifactId=my-spark -DarchetypeArtifactId=maven-archetype-quickstart
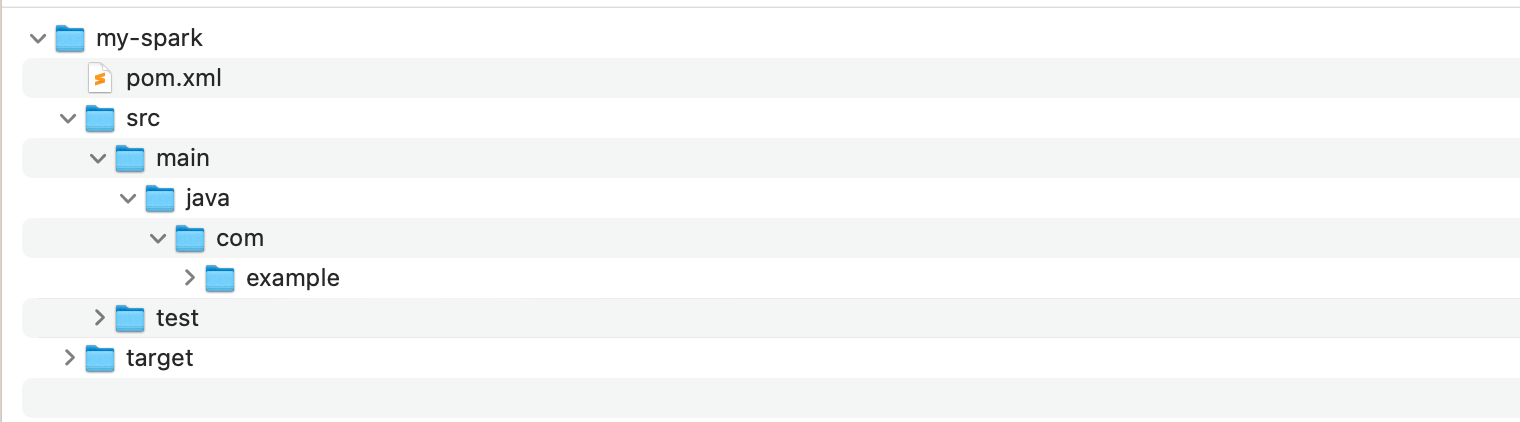
2. 生成的目录结构如:
3. 引入依赖:
# pom.xml中引入spark依赖<dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>2.4.7</version><scope>provided</scope></dependency></dependencies>
编写代码
1. 在 src/main/java/com/example 目录下新建一个 JavaClass,输入的 Class 名,这里使用 WordCount,在 Class 添加样例代码如下:
package com.example;import java.util.Arrays;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaPairRDD;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import scala.Tuple2;public class WordCount {public static void main(String[] args) {// create SparkConf objectSparkConf conf = new SparkConf().setAppName("WordCount");// create JavaSparkContext objectJavaSparkContext sc = new JavaSparkContext(conf);// read input file to RDDJavaRDD<String> lines = sc.textFile(args[0]);// split each line into wordsJavaRDD<String> words = lines.flatMap(line -> Arrays.asList(line.split(" ")).iterator());// count the occurrence of each wordJavaPairRDD<String, Integer> wordCounts = words.mapToPair(word -> new Tuple2<>(word, 1)).reduceByKey((x, y) -> x + y);// save the word counts to output filewordCounts.saveAsTextFile(args[1]);}}
说明:
这里 spark 依赖范围设置为 scope,表示 spark 仅在编译和打包过程中需要提供依赖,运行时依赖由平台提供。
2. 将代码打包成 jar 文件,并在 maven 中加入以下打包插件:
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><configuration><source>1.8</source><target>1.8</target><encoding>utf-8</encoding></configuration></plugin><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>
3. 然后在项目根目录执行:
mvn package
4. 在 target 目录可以看到包含依赖的 jar 文件。这里为 my-spark-1.0-SNAPSHOT-jar-with-dependencies.jar。
数据准备
由于 WeData 数据开发只支持 zip 文件,因此首先需要将 jar 包打成 zip 文件,还需要执行以下操作获得 zip 文件。如果有其他依赖的配置文件等也可以一并打成 zip 包。
zip spark-wordcount.zip my-spark-1.0-SNAPSHOT-jar-with-dependencies.jar
步骤二:上传 SparkJar 的任务包
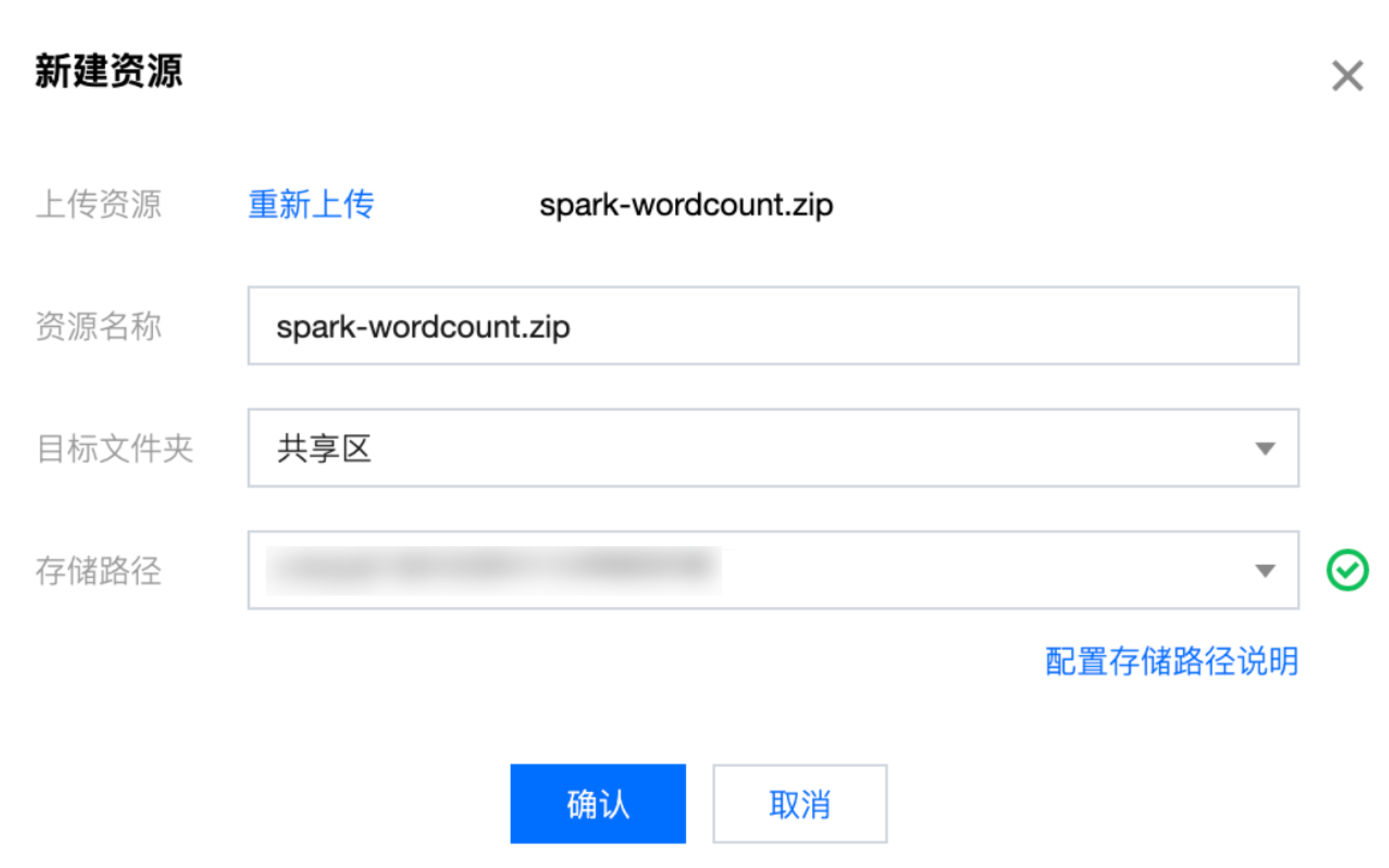
1. 在 资源管理 中新建资源文件,上传资源文件包。
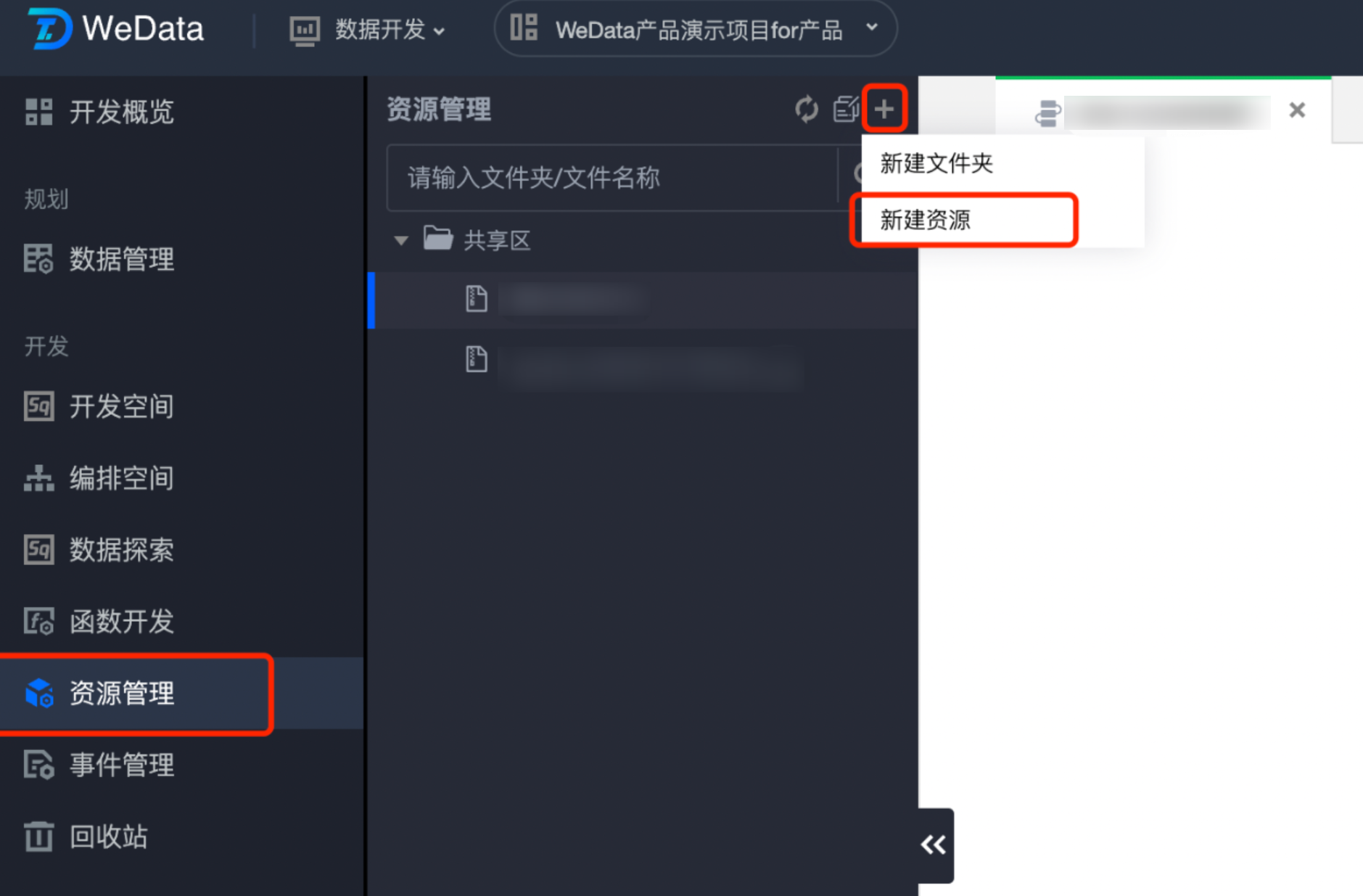
2. 新建资源配置:
步骤三:创建 SparkJar 任务并配置调度
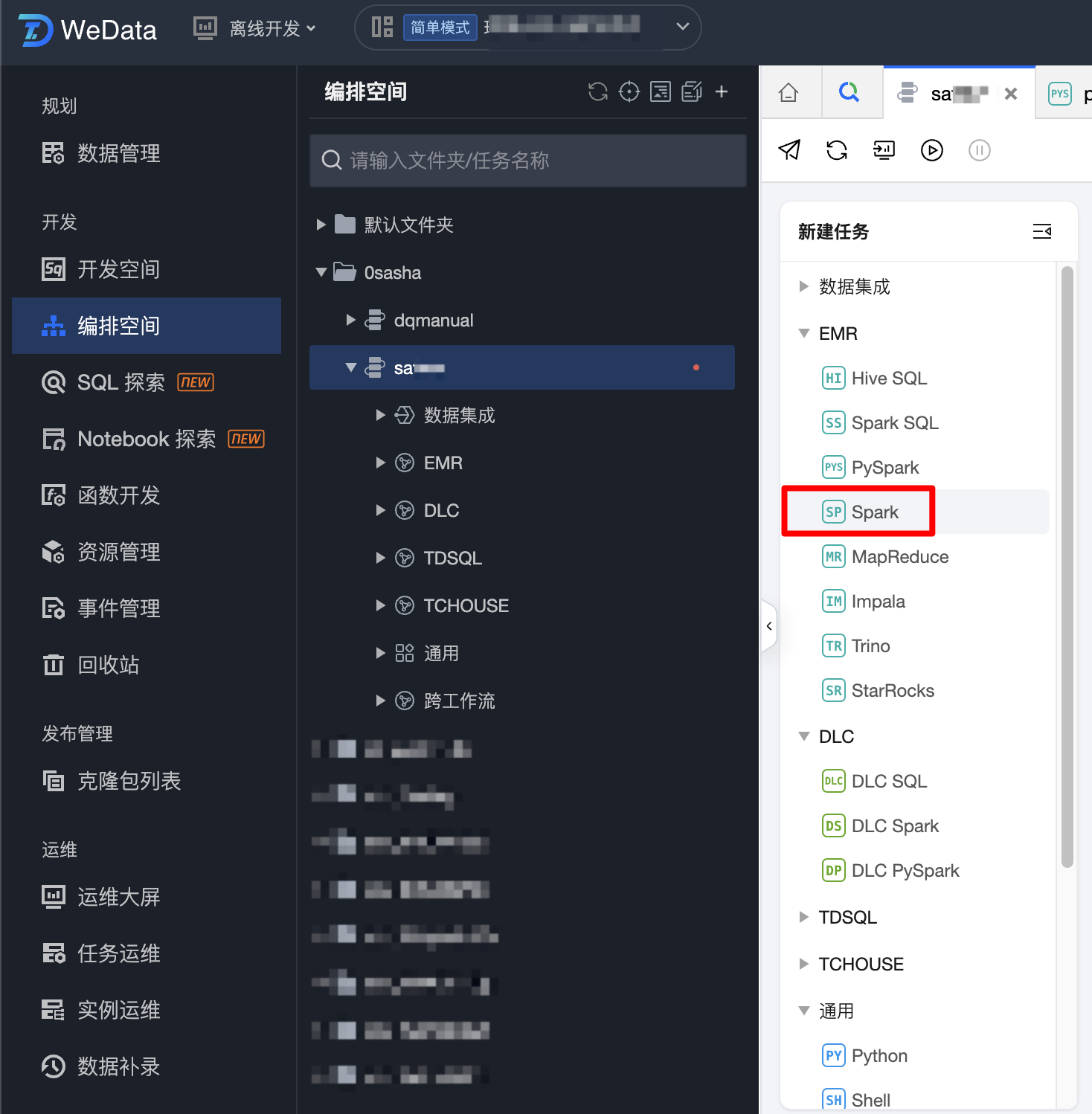
1. 在编排空间中新建一个工作流,在工作流中创建 Spark 任务。
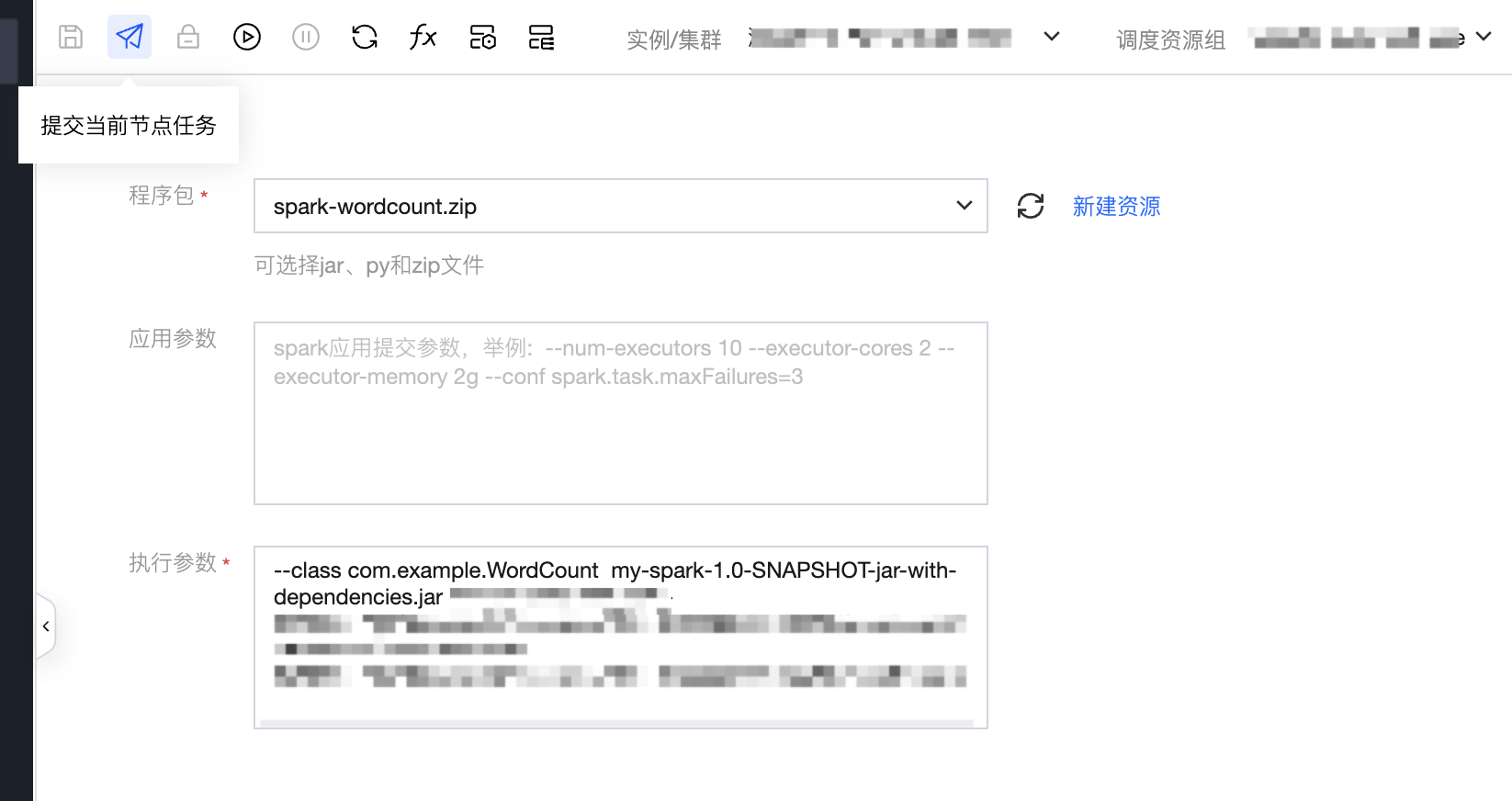
2. 填写任务参数。
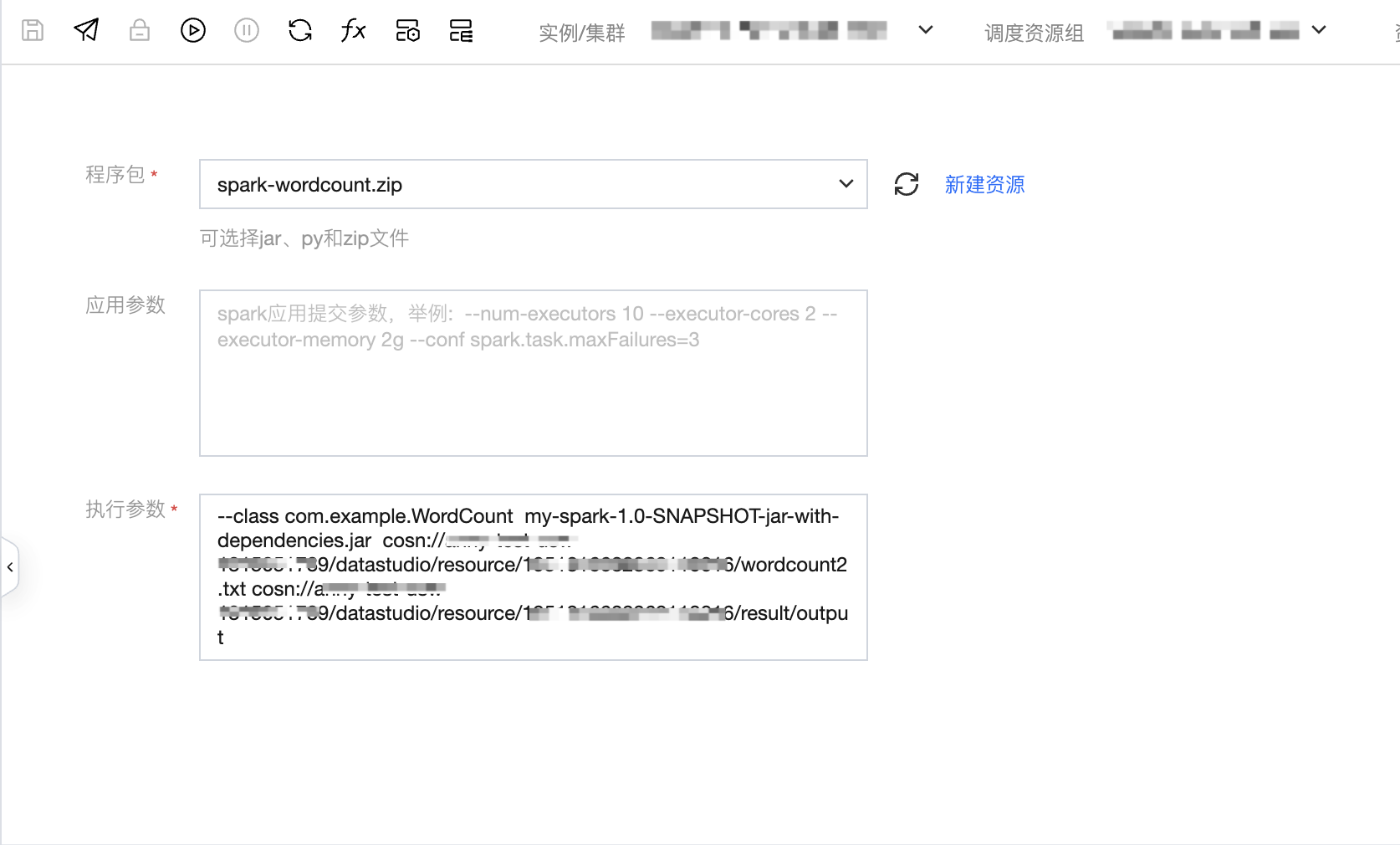
3. 执行参数格式示例:
--class mainClass run.jar args
或
wordcount.py input output
4. 在示例中完整的格式如下:
--class com.example.WordCount my-spark-1.0-SNAPSHOT-jar-with-dependencies.jar cosn://wedata-demo-1314991481/wordcount.txtcosn://wedata-demo-1314991481/result/output
注意:
其中 cosn://wedata-demo-1314991481/wordcount.txt 是需要处理的文件的 COS 路径。
cosn://wedata-demo-1314991481/result/output 是计算结果的输出的 COS 路径,这个文件夹目录事先不能被创建,不然运行会失败。
5. wordcount.txt 的示例文件如下:
hello WeDatahello Sparkhello Scalahello PySparkhello Hive
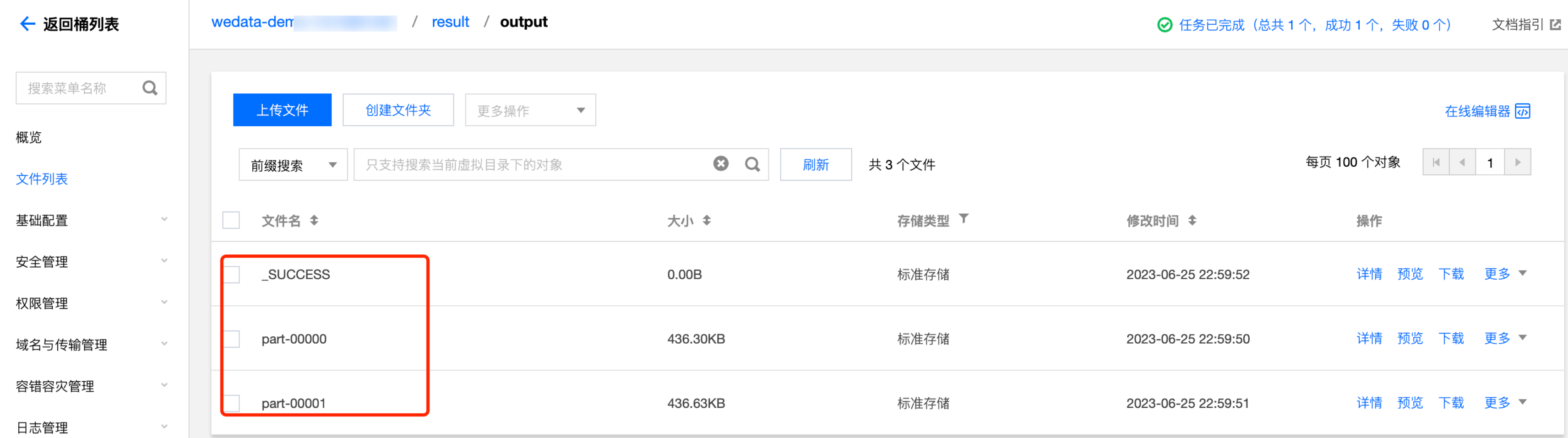
6. 调试运行后,查看计算的结果如下:
注意:
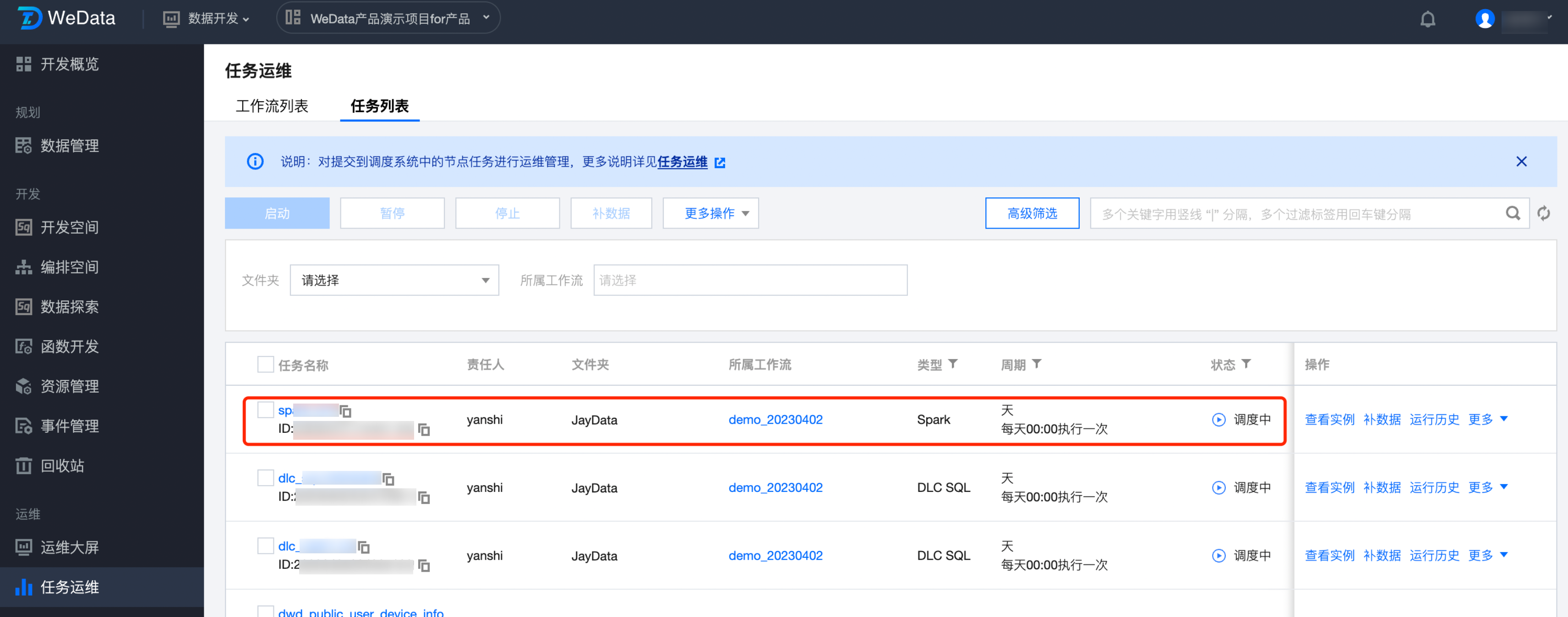
7. 发布 Spark 任务,开启调度。提交 SparkJar 任务:
8. SparkJar 任务运维如下图所示: