注意:
1. 当前用户需要用对应 DLC 计算资源和库表的权限
2. 已经在 DLC 中创建对应的库表。
功能说明
向 WeData 的工作流调度平台提交一个 DLC SQL 任务执行。选 DLC 数据源类型时,提供“高级设置”,支持配置 Presto 和 SparkSQL 参数。
使用 Spark 作业引擎时,可以配置作业资源规格和参数,资源的配置不能超过计算资源本身的限制。
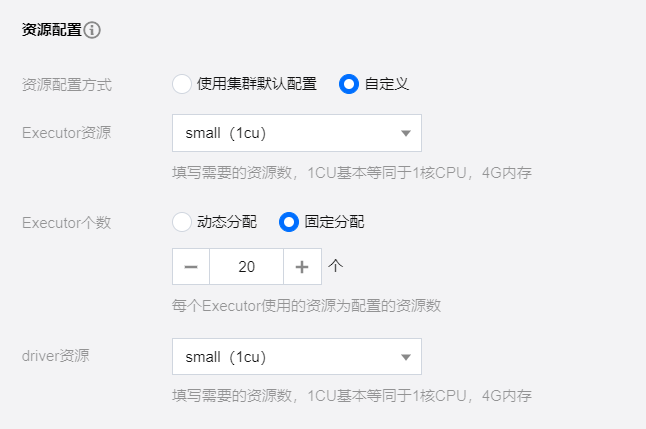
配置说明:
配置项 | 描述 |
资源配置方式 | 分为集群默认配置与自定义配置两种方式: 1. 使用集群默认配置 使用当前任务计算资源集群配置 2. 自定义 用户自定义 Executor、Driver 配置 |
Executor 资源 | 填写需要的资源数,1cu 基本等同于1核 CPU,4G 内存。 1. Small(小型):单个计算单位 (1cu) 2. Medium(中型):两个计算单位 (2cu) 3. Large(大型):四个计算单位 (4cu) 4. Xlarge(超大型):八个计算单位 (8cu) |
Executor 个数 | Executor 负责执行任务和处理计算工作的计算节点或计算实例,每个 Executor 使用的资源为配置的资源数。 |
Driver 资源 | 填写需要的Driver资源数,1cu 基本等同于1核 CPU,4G内存。 1. Small(小型):单个计算单位 (1cu) 2. Medium(中型):两个计算单位 (2cu) 3. Large(大型):四个计算单位 (4cu)。 4. Xlarge(超大型):八个计算单位 (8cu)。 |
示例代码
-- 创建一个用户信息表create table if not exists wedata_demo_db.user_info (user_id string COMMENT '用户ID',user_name string COMMENT '用户名称',user_age int COMMENT '年龄',city string COMMENT '城市') COMMENT '用户信息表';-- 向用户信息表中插入数据insert into wedata_demo_db.user_info values ('001', '张三', 28, 'beijing');insert into wedata_demo_db.user_info values ('002', '李四', 35, 'shanghai');insert into wedata_demo_db.user_info values ('003', '王五', 22, 'shenzhen');insert into wedata_demo_db.user_info values ('004', '赵六', 45, 'guangzhou');insert into wedata_demo_db.user_info values ('005', '小明', 20, 'beijing');insert into wedata_demo_db.user_info values ('006', '小红', 30, 'shanghai');insert into wedata_demo_db.user_info values ('007', '小刚', 25, 'shenzhen');insert into wedata_demo_db.user_info values ('008', '小李', 40, 'guangzhou');insert into wedata_demo_db.user_info values ('009', '小张', 23, 'beijing');insert into wedata_demo_db.user_info values ('010', '小王', 50, 'shanghai');select * from wedata_demo_db.user_info;
注意:
Presto 引擎示例代码:
适用表类型:原生 Iceberg 表、外部 Iceberg 表。
CREATE TABLE `cpt_demo`.`dempts` (id bigint COMMENT 'id number',num int,eno float,dno double,cno decimal(9,3),flag boolean,data string,ts_year timestamp,date_month date,bno binary,point struct<x: double, y: double>,points array<struct<x: double, y: double>>,pointmaps map<struct<x: int>, struct<a: int>>)COMMENT 'table documentation'PARTITIONED BY (bucket(16, id), years(ts_year), months(date_month), identity(bno), bucket(3, num), truncate(10, data));
SparkSQL 引擎示例代码
适用表类型:原生 Iceberg 表、外部 Iceberg 表。
CREATE TABLE `cpt_demo`.`dempts` (id bigint COMMENT 'id number',num int,eno float,dno double,cno decimal(9,3),flag boolean,data string,ts_year timestamp,date_month date,bno binary,point struct<x: double, y: double>,points array<struct<x: double, y: double>>,pointmaps map<struct<x: int>, struct<a: int>>)COMMENT 'table documentation'PARTITIONED BY (bucket(16, id), years(ts_year), months(date_month), identity(bno), bucket(3, num), truncate(10, data));
SparkSQL 作业引擎示例代码
适用表类型:原生 Iceberg 表、外部 Iceberg 表。
CREATE TABLE `cpt_demo`.`dempts` (id bigint COMMENT 'id number',num int,eno float,dno double,cno decimal(9,3),flag boolean,data string,ts_year timestamp,date_month date,bno binary,point struct<x: double, y: double>,points array<struct<x: double, y: double>>,pointmaps map<struct<x: int>, struct<a: int>>)COMMENT 'table documentation'PARTITIONED BY (id, ts_year, date_month);
说明:
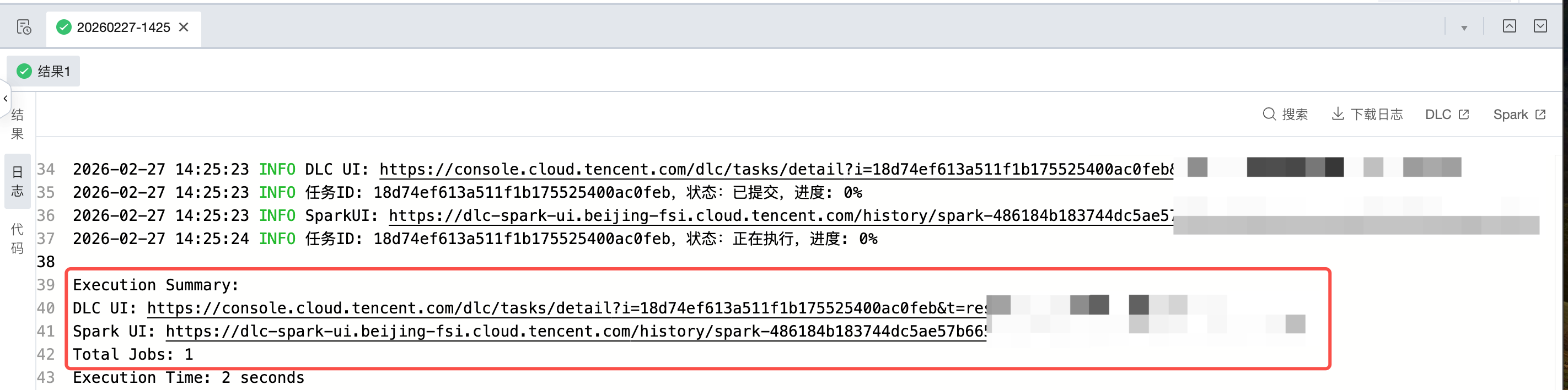
运行结果与详情查看
运行完成后可在下方查看运行结果和日志
针对 DLC SQL、DLC Spark、DLC PySpark任务,支持在日志和日志上方点击跳转到 DLC 或 Spark 查看更多日志和运行结果。
产品入口:
点击本次运行 > 对应SQL结果 > 日志 > DLC:跳转到 DLC 控制台查看更多运行日志、详情和洞察等信息。
点击本次运行 > 对应SQL结果 > 日志 > Spark:跳转到 Spark 对应执行页面查看更多运行日志和详情。
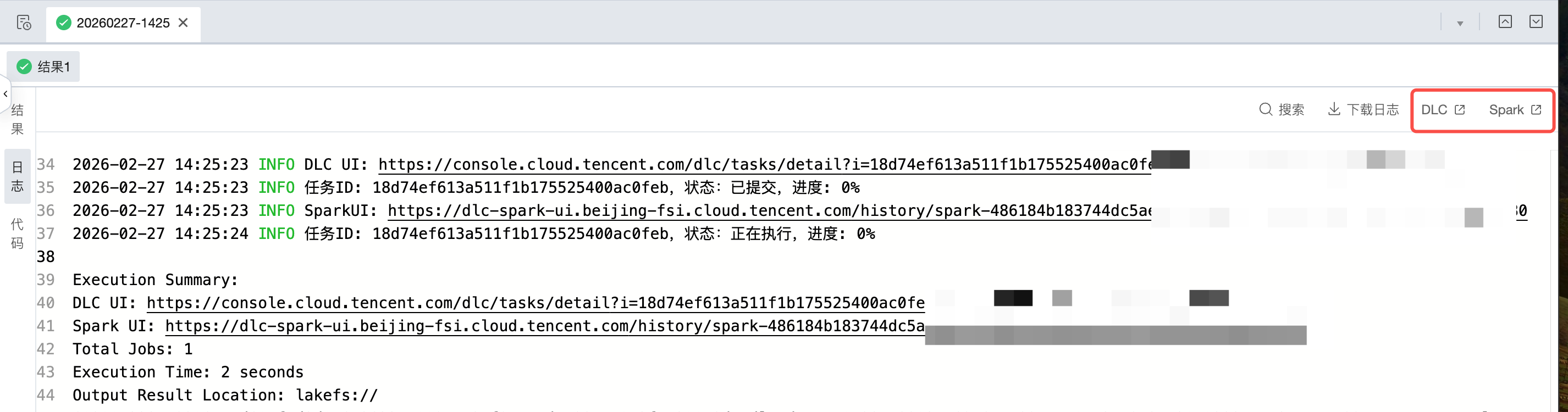
日志入口:
在日志中搜索 Execution Summary 可以定位到本次运行的执行总结,会展示本次运行的 DLC UI 和 Spark UI,按住键盘的 command 键,点击日志中的 UI,可以跳转到对应页面查看更多日志详情信息。