标准引擎体系由几个核心组成部分,引擎网络,网关,资源组,终端节点,执行机。使用 DLC 标准引擎之前,您还需要了解这些概念:
说明:
presto 引擎已下线,仅供存量用户使用。
相关概念
表格中简单介绍了标准引擎体系中的几个核心概念,详细信息可以点击相关链接了解。
概念 | 说明 |
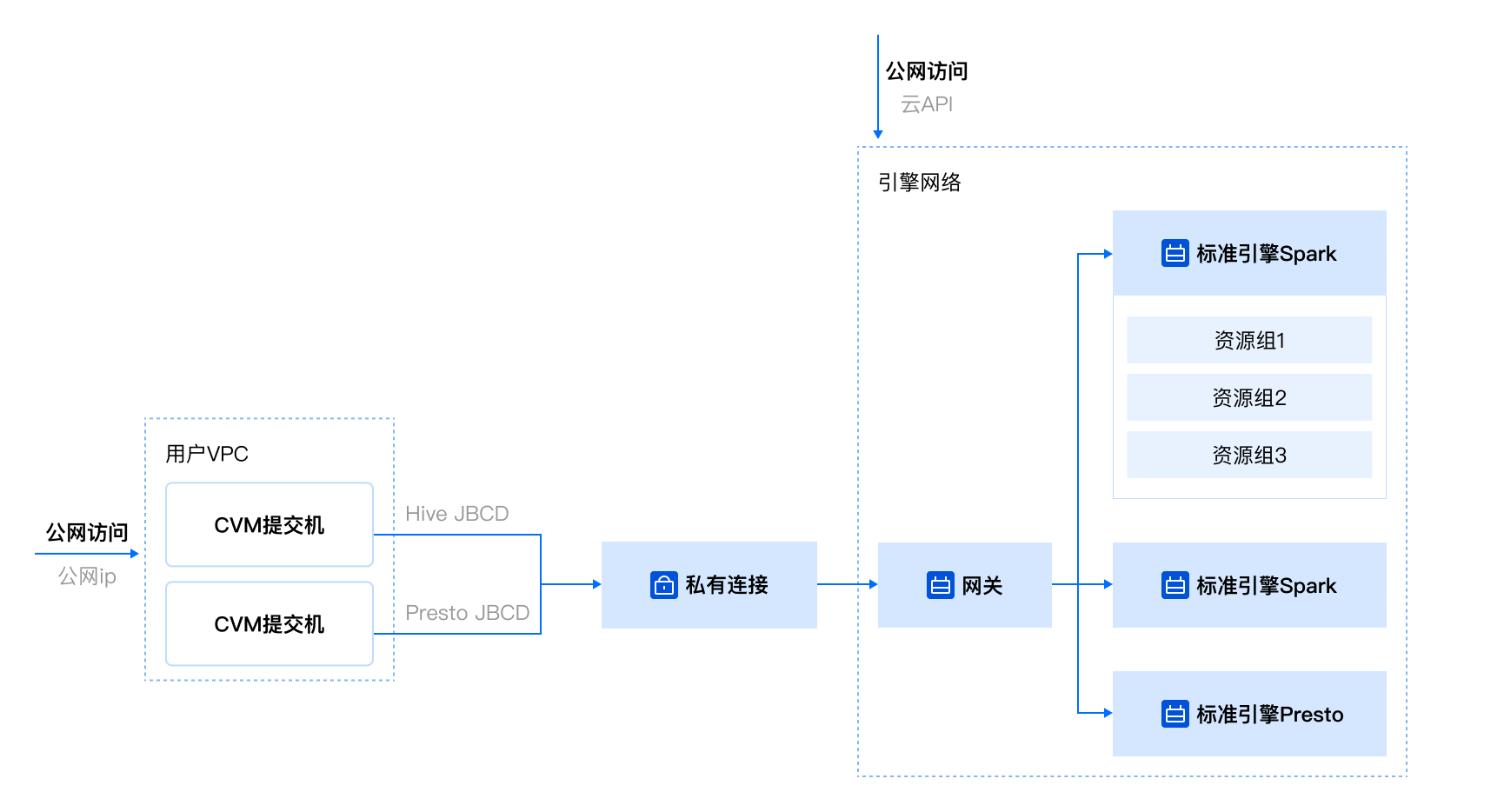
引擎网络是部署网关和标准引擎的托管的私有连接,是一个逻辑隔离的网络环境。用户可以根据业务需求自定义引擎网络的 IP 地址范围、网段。 | |
网关基于大数据组件 kyuubi 实现,是标准引擎服务的访问入口,为用户提供了更高效、更稳定的任务提交体验。 | |
标准引擎是 DLC 提供的一类计算资源,帮助用户快速启动一定规格的计算集群。标准引擎提供了对原生语法和行为的全面支持,这使得熟悉大数据生态的用户能够更加迅速地上手并轻松使用。 | |
标准 Spark 引擎支持使用资源组将引擎的资源做进一步按需划分,一个资源组是标准 Spark 引擎部分计算资源和对应配置的统称。 SQL 任务可以提交到指定的资源组进行执行。 | |
通过私有连接,能够打通用户账户 VPC 到标准引擎的网络,用户可以通过该 VPC 下的服务器进行任务提交。 | |
提交机 | 创建终端节点之后,该终端节点绑定的用户账号 VPC 下的任意一台服务器都可以作为提交机进行任务提交。 |
任务提交方式
用户可以通过多种方式提交任务:
1. 在提交机上通过 JDBC 访问,如图所示。
2. 通过 DLC 控制台数据探索页面提交 SQL 任务。
3. 通过 DLC 控制台数据作业页面提交 Spark 批流作业。
4. 通过云 API 提交任务。
快速购买并配置标准引擎
1. 如果首次购买标准引擎,DLC 推荐您通过文档标准引擎配置指引快速配置标准引擎。
2. 完成购买后,您可以通过数据探索页面或者提交机进行任务的提交。



