说明:
presto 引擎已下线,仅供存量用户使用。
如何开启 Presto 内置函数应用
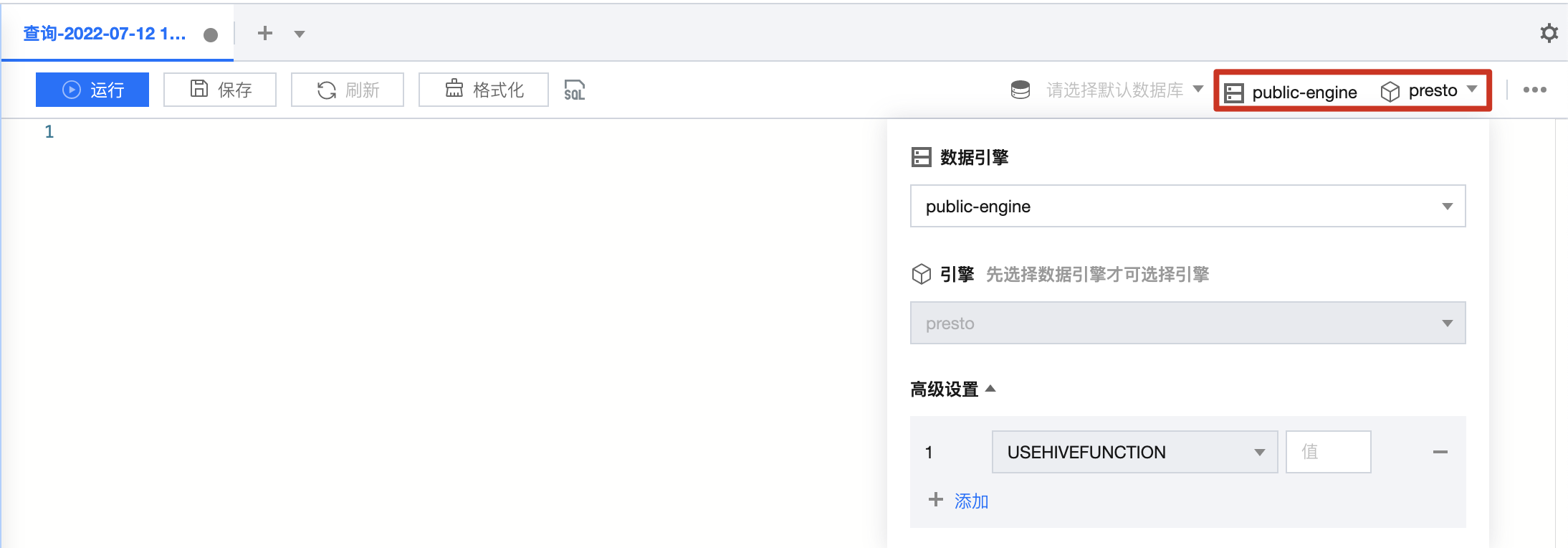
途径一:在数据探索对数据引擎进行函数配置
1. 登录 数据湖计算 DLC 控制台,选择服务地域。
2. 进入数据探索,选择数据引擎,当引擎内核为 Presto 时,可在高级配置中选择参数 USEHIVEFUNCTION,将该参数配置为 false 即可在使用该数据引擎进行 SQL 任务时使用 Presto 内置函数。
注意
在当前查询 session,所有使用该数据引擎的查询任务皆可使用 Presto 内置函数。
途径二:在 SQL 语句中添加参数
如您希望某个 SQL 任务调用 Presto 内置函数,可通过在 SQL 任务中添加配置信息实现。
示例:
SELECT/*+OPTIONS('useHiveFunction'='false')*/prestofunc(xx)
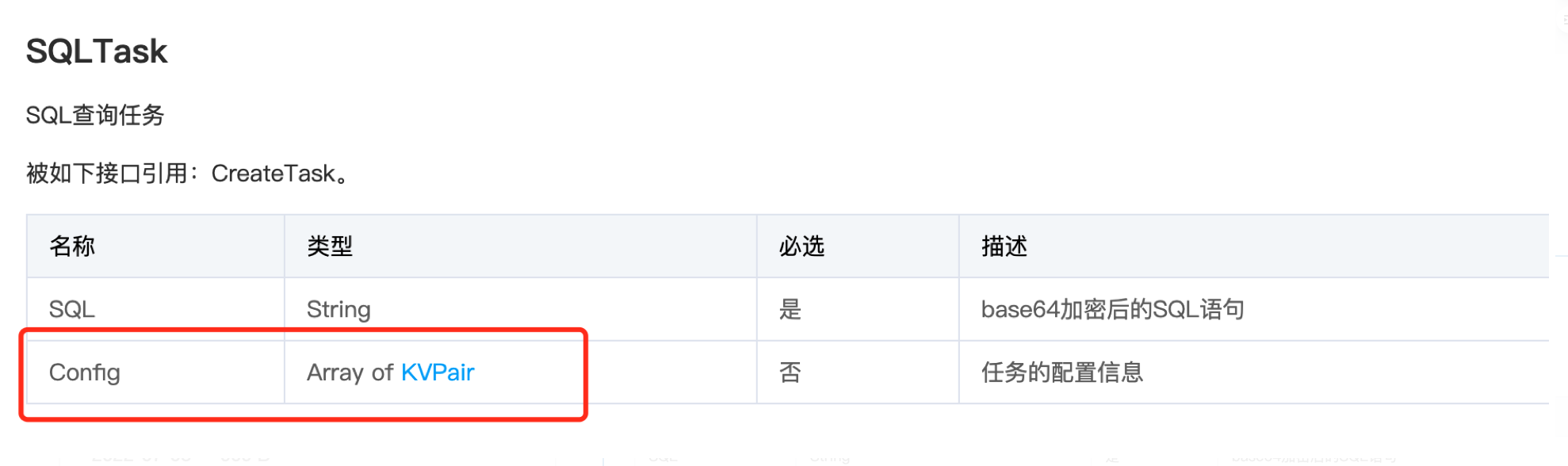
途径三:使用 API 时增加配置参数
在 task 结构体中 config 中设置 kv,useHiveFunction=false。
Stringstatement="SELECTdate_add('week',3,TIMESTAMP'2001-08-2203:04:05.321')";TasksInfotask=newTasksInfo();task.setTaskType("SQLTask");task.setSQL(Base64.getEncoder().encodeToString(statement.getBytes()));//添加以下参数配置KVPairpair=newKVPair();pair.setKey("useHiveFunction");pair.setValue("false");task.setConfig(newKVPair[]{pair});CreateTasksRequestrequest=newCreateTasksRequest();request.setDatabaseName("");request.setDataEngineName(PRESTO_ENGINE);request.setTasks(task);
途径四:使用 JDBC 进行任务创建时添加参数
在 JDBCURL 路径中添加
&presto.USEHIVEFUNCTION=true 参数或 info.setProperty("presto.USEHIVEFUNCTION","false");。Connectionconnection=DriverManager.getConnection("jdbc:dlc:dlc.tencentcloudapi.com?task_type=SQLTask&x省略中间参数xx&presto.USEHIVEFUNCTION=true",info);或者info.setProperty("presto.USEHIVEFUNCTION","false");info.setPropertv("user","");info.setProperty("password","");
支持的 Presto 内置函数列表
数学函数
函数名称 | 返回值 | 函数功能描述 |
abs(x) | 与 x 一致 | 返回x的绝对值 |
cbrt(x) | double | 返回 x 的立方根 |
ceil(x) | ceiling(x) | 与 x 一致 | 返回 x 向上最接近的整数。例如:ceil(2.2); -->3 |
cosine_similarity(x, y) | double | 返回向量 x 和 y 的相似度 例如:SELECT cosine_similarity(MAP(ARRAY['a'], ARRAY[1.0]), MAP(ARRAY['a'], ARRAY[2.0])); -->1.0 |
degrees(x) | double | 将弧度转换为角度 |
e() | double | 返回常数 e |
exp(x) | double | 返回 e 的x次方 |
floor(x) | 与 x 一致 | 返回 x 向下最接近的整数。例如:floor(2.2); -->2 |
ln(x) | double | 返回x的自然对数 |
log2(x) | double | 返回以 2 为底的 x 的对数 |
log10(x) | double | 返回以 10 为底的 x 的对数 |
mod(n, m) | 与 n 一致 | 返回 n 除以 m 的余数 |
pi() | double | 返回常数Pi |
pow(x, p) | power(x, p) | double | 返回 x 的 p 次幂 |
radians(x) | double | 将角度x(以度为单位)转换为弧度 |
rand() | random() | double | 返回 0.0 <= x < 1.0 范围内的随机值。 |
random(n) | 与 n 一致 | 返回介于 0 和 n (不包含n)之间的随机数 |
secure_rand() | secure_random() | double | 返回0.0 <= x < 1.0范围内的加密随机值 |
secure_random(lower, upper) | 与 lower 一致 | 返回范围为 lower <= x < upper 的加密随机值,其中lower < upper |
round(x) | 与 x 一致 | 返回x四舍五入到最接近的整数 |
round(x, d) | 与 x 一致 | 返回x四舍五入到小数点后 d 位 |
sign(x) | 与 x 一致 | 返回 x 所对应的正负号,x > 0 返回1;x< 0,返回-1;x=0, 返回 0 |
sqrt(x) | double | 返回 x 的平方根 |
truncate(x) | bigint | 返回截取小数点后的数 例如:truncate(4.9) -->4 |
truncate(x, n) | double | 返回 x 截取小数点后n位。n<0时,从小数点左边截取 例如:truncate( 12.333, -1) --> 10.0;truncate( 12.333,0) --> 12.0;truncate( 12.333,1) --> 12.3; |
二进制函数
函数名称 | 返回值 | 函数功能描述 |
length(b) | bigint | 以字节为单位,返回 b 的二进制长度 |
concat(b1, ..., bN) | varbinary | 返回连接b1,…,bN的二进制值 |
substr(b, start) | varbinary | 返回从 b 中 start 位开始截取二进制值,start > 0 时从开头截取,star t< 0 时从末尾开始截取 |
substr(b, start, length) | varbinary | 返回从 b 中 start 位开始截取 length 长度 的二进制值,start > 0 时从开头截取,star t< 0 时从末尾开始截取 |
to_base64(b) | varchar | 将二进制数据 b 转为 base64 字符串 |
from_base64(string) | varbinary | 将 base64 编码的字符串转为二进制数据 |
to_base64url(b) | varchar | 使用URL安全字符,将二进制数据 b 转为 base64 字符串 |
from_base64url(string) | varbinary | 使用URL安全字符,将 base64 编码的字符串转为二进制数据 |
from_base32(string) | varbinary | 将 base32 编码的字符串转为二进制数据 |
to_base32(b) | varchar | 将二进制数据 b 转为 base32 字符串 |
to_hex(b) | varchar | 将二进制数据 b 转为16进制字符串 |
from_hex(string) | varbinary | 将 16进制编码的字符串转为二进制数据 |
lpad(b, size, padb) | varbinary | 返回在 b 的左边拼接 padb ,直到长度达到 size的二进制数 |
rpad(b, size, padb) | varbinary | 返回在 b 的右边拼接 padb ,直到长度达到 size的二进制数 |
crc32(b) | bigint | 使用CRC32算法计算表达式的循环冗余校验值 |
md5(b) | varbinary | 计算二进制 b 的 md5 值 |
sha1(b) | varbinary | 计算二进制 b 的 sha1 值 |
sha256(b) | varbinary | 计算二进制 b 的 sha256 值 |
sha512(b) | varbinary | 计算二进制 b 的 sha512 值 |
xxhash64(b) | varbinary | 计算二进制 b 的 xxhash64 值 |
位运算函数
函数名称 | 返回值 | 函数功能描述 |
bit_count(x, bits) | bigint | 返回 bit 在 x 中的位数 |
bitwise_and(x, y) | bigint | 返回 x , y 的与 |
bitwise_not(x) | bigint | 返回 x 的按位取反 |
bitwise_or(x, y) | bigint | 返回 x, y的或 |
bitwise_xor(x, y) | bigint | 返回 x, y的异或 |
bitwise_left_shift(value, shift) | 与输入一致 | 返回 value 的左移动 shift 位的值 例如:bitwise_left_shift(TINYINT '7', 2) --> 28 |
bitwise_right_shift(value, shift) | 与输入一致 | 返回 value 的右移动 shift 位的值 例如:bitwise_right_shift(TINYINT '7', 2) -->1 |
字符串函数
函数名称 | 返回值 | 函数功能描述 |
chr(n) | varchar | 返回 n 的 Unicode 字符 |
codepoint(string) | integer | 返回字符串的Unicode值 例如:codepoint('0') -->48 |
concat(string1, ..., stringN) | varchar | 返回 string1,….,stringN的连接字符串 |
length(string) | bigint | 返回字符串的长度 |
hamming_distance(string1, string2) | bigint | 返回两个(相同长度)字符串对应位置的不同字符的数量 例如:hamming_distance(abc, art) -->2 |
levenshtein_distance(string1, string2) | bigint | 返回两个字串之间,由一个转成另一个所需的最少编辑(插入、删除、替换)的次数 例如: levenshtein_distance('ab', 'abcde') -->3 |
lower(string) | varchar | 返回string转为小写后的字符串 |
upper(string) | varchar | 返回string转为大写后的字符串 |
ltrim(string) | varchar | 从字符串中删除左边空格 |
rtrim(string) | varchar | 返回从字符串中删除后面空格 |
trim(string) | varchar | 返回删除字符串中的空格的字符串 |
replace(string, search) | varchar | 从字符串中删除所有search字符 |
replace(string, search, replace) | varchar | 用 replace 字符串替换 search 字符串 例如:replace('abcavc', ‘a', ‘c') -->'cbccvc' |
reverse(string) | varchar | 返回字符的反向排列 例如:reverse('abc') -->'cba' |
lpad(string, size, padstring) | varchar | 在 string 的左边拼接 padstring,直到字符串长度达到size。如果有size小于 string,则将string剪切为长度size的字符串。 |
rpad(string, size, padstring) | varchar | 在 string 的右边拼接 padstring,直到字符串长度达到达到size。如果有size小于 string,则将string剪切为长度size的字符串。 |
split(string, delimiter) | array | 返回 delimiter 分割字符串后的一个数组 |
split(string, delimiter, limit) | array | 返回 delimiter 分割字符串后按 limit 大小限制的数组,limit > 0,数组最后一个元素包含字符串中的所有剩余内容 例如:select split('ab-cd-efg', '-', 2) -->['ab','cd-efg'] |
split_part(string, delimiter, index) | varchar | 返回 delimiter 分割字符串后的数组中,index 位置的字符串,字段索引从 1 开始。如果 index >数组长度,则返回 null 例如:select split_part('ab-cd-efg', '-', 2) -->'cd' |
split_to_map(string, entryDelimiter, keyValueDelimiter) | map<varchar, varchar> | 返回 entryDelimiter 和 keyValueDelimiter 拆分字符串后的map 例如:select split_to_map('a:1,b:2', ',', ':') -->{'a':'1','b':'2'} |
split_to_map(string, entryDelimiter, keyValueDelimiter, function(K, V1, V2, R)) | map<varchar, varchar> | 返回 entryDelimiter 和 keyValueDelimiter 拆分字符串后的map,如果有重复key,则根据function指定的规则返回key对应的value 例如:split_to_map('a:1,b:2;a:3',‘,' , ':’, (k, v1, v2) -> v1)-->{'a':'1','b':'2'} |
substr(string, start) | varchar | 返回字符串 string 中 start 位置之后的字符串。位置从1开始, start <0时,从字符串末尾开始计数 |
substr(string, start, length) | varchar | 返回字符串 string 中 start 位置开始 length 长度的字符串。位置从1开始, start <0时,从字符串末尾开始计数 |
position(substring IN string) | bigint | 返回string中substring的第一个出现的位置。位置从1开始。如果未找到,则返回0 |
strpos(string, substring) | bigint | 返回string中substring的从左向右第一次出现的位置。位置从1开始。如果未找到,则返回0。 例如:strpos('abcdefg', 'a') -->1 |
strpos(string, substring, instance) | bigint | 返回string中substring的从左向右第 instance 次出现的位置。instance >0 , 位置从1开始。如果未找到,则返回0。 例如:strpos('abcaefg', 'ab',2) -->0 |
strrpos(string, substring) | bigint | 返回string中substring的从右向左第一次出现的位置。位置从1开始。如果未找到,则返回0 例如:strpos('abcdefg', 'a') -->7 |
strrpos(string, substring, instance) | bigint | 返回string中substring的从右向左第 instance 次出现的位置。instance >0 , 位置从1开始。如果未找到,则返回0。 例如:strpos('abcaefg', 'a',2) -->0 |
to_utf8(string) | varbinary | 将字符串转为utf8编码的二进制数 |
from_utf8(binary) | varchar | 将二进制数转为utf8编码的字符串,无效字符用Unicode字符U+FFFD替换 |
from_utf8(binary, replace) | varchar | 将二进制数转为utf8编码的字符串,无效字符用replace替换 |
日期时间函数
函数名称 | 返回值 | 函数功能描述 |
current_date | date | 返回当前日期 |
current_time | time | 返回当前带时区的时间 |
current_timestamp | timestamp | 返回当前带时区的时间戳 |
current_timezone() | varchar | 返回当前时区 |
date(x) | date | 返回当前日期 |
last_day_of_month(x) | date | 返回本月的最后一天 |
from_unixtime(unixtime) | timestamp | 返回 unix 时间戳 例如:from_unixtime(1475996660) -->2016-10-09 15:04:20.000 |
to_unixtime(timestamp) | double | 返回 timestamp 的 unix时间戳 |
from_unixtime(unixtime, string) | timestamp | 返回 unixtime的时间戳,string指定时区 例如:from_unixtime(1617256617,'Asia/Shanghai') -->2021-04-01 13:56:57.000 Asia/Shanghai |
from_iso8601_timestamp(string) | timestamp | 以 iso8601 格式将 string 转为时间戳 |
from_iso8601_date(string) | date | 以 iso8601 格式将 string 转为日期 |
localtime | time | 返回当前时间 |
localtimestamp | timestamp | 返回当前时间的时间戳 |
now() | timestamp | 返回当前带时区的时间戳 |
to_iso8601(x) | varchar | 返回 x 的iso8601 格式的字符串,x 可以为日期、时间戳或带时区的时间戳 |
date_trunc(unit, x) | 与输入一致 | 返回 以unit为单位截取x的时间,unit 为 second、minute、hour、day、week、month、quarter、year. 例如:date_trunc('hour', TIMESTAMP '2020-03-17 02:09:30') --> '2020-03-17 02:00:00' |
date_add(unit, value, timestamp) | 与输入一致 | 返回 加减相应单位的间隔时间 算出新的时间戳, value >0 表示加,value < 0 表示减. unit 为 millisecond、second、minute、hour、day、week、month、quarter、year. 例如:date_add('hour', 2, cast ('2023-07-20 20:22:22.022' as timestamp)) -->'2023-07-20 22:22:22.022' |
date_diff(unit, timestamp1, timestamp2) | bigint | 返回两个时间戳相差(指定单位的)时间。unit 为 millisecond、second、minute、hour、day、week、month、quarter、year. 例如:date_diff('hour', cast ('2023-07-01 22:22:22' as timestamp) , cast ('2023-07-03 22:22:22' as timestamp) )-->48 |
extract(field FROM x) | bigint | 返回根据field 提取 x的时间,field可以为:year、quarter、month、week、day、dow、doy、yow、hour、minute、second、timezone_hour、timezone_minute、day_of_week、day_of_year、day_of_month 例如:extract(year from current_date) 2023 |
day(x) | bigint | 返回 x 是月的第几天 |
day_of_month(x) | bigint | 返回 x 是月的第几天 |
day_of_week(x) | bigint | 返回 x 是一周的第几天,范围为1-7 |
day_of_year(x) | bigint | 返回 x 是年的第几天 |
dow(x) | bigint | 返回 x 是周的第几天。同 day_of_week(x) |
doy(x) | bigint | 返回 x 是年的第几天。同 day_of_year(x) |
hour(x) | bigint | 返回 x 是一天中的第几小时,范围 0-23 |
millisecond(x) | bigint | 返回 x 是一秒中的第几毫秒 |
minute(x) | bigint | 返回 x 是一小时中的第几分钟 |
month(x) | bigint | 返回 x 是一年中的第几个月 |
quarter(x) | bigint | 返回 x 是一年中的第几季度 |
second(x) | bigint | 返回 x 是一分钟中的第几秒 |
week(x) | bigint | 返回 x 是一年中的第几周 |
week_of_year(x) | bigint | 返回 x 是一年中的第几周 |
year(x) | bigint | 返回 x 的年份 |
数组函数
函数名称 | 返回值 | 函数功能描述 |
array_distinct(x) | array | 从数组中删除重复的值x。 |
array_intersect(x, y) | array | 返回 x 和 y 的交集中的不重复元素。 |
array_union(x, y) | array | 返回 x 和 y 的并集中的不重复元素。 |
array_except(x, y) | array | 返回属于 x 但不属于 y 的不重复元素。(差集) |
array_join(x, delimiter, null_replacement) | varchar | 使用delimiter连接 x 数组元素并用null_replacement来填充数组里面的空值。null_replacement为可选字符 |
array_max(x) | x | 返回输入数组的最大值 |
array_min(x) | x | 返回输入数组的最小值 |
array_position(x, element) | bigint | 返回数组 x 中第一次出现 element 的位置(数字)(如果未找到,则返回0) |
array_remove(x, element) | array | 删除数组 x 中和element相同的所有元素 |
array_sort(x) | array | 返回 x 的排序结果。x的元素必须是可排序的。空元素将放置在返回数组的末尾 |
array_sort(array(T), function(T, T, int)) | array(T) | 返回 array 根据比较函数function排序的结果 例如:array_sort(ARRAY [3, 2, 5, 1, 2], (x, y) -> IF(x < y, 1, IF(x = y, 0, -1))) -->[5, 3, 2, 2, 1] |
arrays_overlap(x, y) | 布尔值 | 判断数组 x 和 y 是否有任何共同的非空元素 |
cardinality(x) | bigint | 返回数组的基数(大小) |
concat(array1,array2,…,arrayN) | array | 连接数组array1,array2,...,arrayN |
contains(x, element) | 布尔值 | 判断数组 x 是否包含 element |
element_at(array(E),index) | E | 返回 array数组中 index 位置的元素。如果index> 0,从左向右计数,index < 0, 从右向左计数 |
filter(array(T), funciton(T, boolean)) | array(T) | 返回用函数function返回true的元素构造的新数组 例如:filter( array[5, -6, NULL, 7], x -> x > 0); --> [5, 7] |
repeat(element,count) | array | 重复元素element的count次数 |
reverse(x) | array | 返回一个具有相反数组顺序的数组x。 |
sequence(start, stop, n) | array(bigint ) | 从start 根据步长 n 到 stop 生成一个整数序列,n 为可选项,不填为1。如果start小于等于stop 每次自增1,否则自增 -1 |
shuffle(x) | array | 打乱数组元素 |
slice(x, start, length) | array | 返回将 x 数组从start位置开始,切片成长度为length的数组 |
transform(array(T), function(T, U)) | array(U) | 返回 array数组中的每个元素T经过function后生成U组成的数组 例如:transform(array [5, 6], x -> x + 1); -- [6, 7] |
JSON函数
函数名称 | 返回值 | 函数功能描述 |
is_json_scalar(json) | boolean | 判断 json是否为 json数字或 json字符串或 true 或 false 或 null 例如: is_json_scalar('[1, 2, 3]') -->false |
json_array_contains(json, value) | boolean | 判断 value 是否存在于 json(一个包含 json数组的字符串)中。 例如:json_array_contains('[1, 2, 3]', 2) -->true |
json_array_length(json) | bigint | 返回 json(一个包含 json数组的字符串)的数组长度。 例如:json_array_length('[1, 2, 3]') --> 3 |
json_extract(json, json_path) | json | 在 json(一个包含 json的字符串)上计算类似 JSONPath 的表达式 json_path,并将结果作为 json返回。 例如:json_extract('{"log":{"file":{"path":"/etc/nginx/logs/access.log"},"offset":19991212}}', '$.log.file.path')--> "/etc/nginx/logs/access.log" |
json_extract_scalar(json, json_path) | varchar | 与 json_extract() 类似,但将结果值作为字符串返回,而不是json串。json_path 所引用的值必须是布尔值、数字或字符串。 例如:json_extract_scalar('{"log":{"file":{"path":"/etc/nginx/logs/access.log"},"offset":19991212}}', '$.log.file.path') -->/etc/nginx/logs/access.log |
json_format(json) | varchar | 返回从输入的 json值序列化的 json文本。这是 json_parse() 的逆函数。 例如:json_format(JSON '[1, 2, 3]') -->[1,2,3] |
json_parse(string) | json | 返回从输入的 json文本反序列化的 json值。这是 json_format() 的逆函数。 例如:json_parse('[1, 2, 3]') -->[1,2,3] |
json_size(json, json_path) | bigint | 与 json_extract() 类似,但返回值的大小。对于对象或数组,大小是成员的数量,标量值的大小是零。 例如:json_size('{"x": [1, 2, 3]}', '$.x') -->3 |
聚合函数
函数名称 | 返回值 | 函数功能描述 |
arbitrary(x) | 与输入一致 | 如果存在,则返回x的任意非空值 |
array_agg(x) | array[x] | 返回由输入x元素创建的数组 |
avg(x) | double | 返回所有输入值的平均值(算术平均值) |
bool_and(boolean) | every(boolean) | boolean | 输入的每个值都为true,则返回true,否则返回false |
bool_or(boolean) | boolean | 输入的值只要有一个为true,则返回true,否则返回false |
checksum(x) | varbinary | 返回输入值的校验和 |
count(*) | bigint | 返回行数 |
count(x) | bigint | 返回非空输入值的数量 |
count_if(x) | bigint | 返回输入值中为true值的数量,等价于count(CASE WHEN x THEN 1 END) |
geometric_mean(x) | double | 返回几何平均值 |
max_by(x, y) | 与输入 x 一致 | 返回 x 中与 y 的最大值相关连的值 |
max_by(x, y, n) | array[x] | 按照y降序排列,返回 x 中 n 个 与 y 中 n 个最小值相关联的值 |
min_by(x, y) | 与输入 x 一致 | 返回 x 中与 y 的最小值相关连的值 |
min_by(x, y, n) | array[x] | 按照 y 升序排列,返回 x 中 n 个 与 y 中 n 个最小值相关联的值 |
max(x) | 与输入一致 | 返回输入中的最大值 |
max(x, n) | 与输入 x 一致 | 返回输入中最大的 n 个值 |
min(x) | 与输入一致 | 返回输入中的最小值 |
min(x, n) | 与输入 x 一致 | 返回输入中最小的 n 个值 |
set_agg(x) | 与输入一致 | 返回一个不重复元素的数组 |
set_union(array(T)) | array(T) | 返回输入的每个数组中包含的所有不同值的数组 例如:select set_union(elements) FROM (VALUES ARRAY[1, 2, 3], ARRAY[2, 3, 4]) AS t(elements) -->ARRAY[1, 2, 3, 4] |
sum(x) | 与输入一致 | 返回和 |
bitwise_and_agg(x) | bigint | 返回所有位的与 |
bitwise_or_agg(x) | bigint | 返回所有位的或 |
histogram(x) | | 返回一个包含每个输入值出现次数的map |
map_agg(key, value) | map(K, V) | 返回key-value组成的map |
map_union(x(K, V)) | map(K, V) | 返回所有输入映射的并集,如果一个key对应多个value,则结果集中key对应的value值为多个value中的任意一个value值 |
map_union_sum(x(K, V)) | map(K, V) | 返回相同key求和后的并集map,如果key对应的value为空,则计为0 |
multimap_agg(key, value) | | 返回 key-value组成的map,key可以对应多个值 |
窗口函数
函数名称 | 返回值 | 函数功能描述 |
row_number() | bigint | 为每一行分配一个唯一的连续编号 |
rank() | bigint | 计算某个值在一组值中的排名。如果出现排名相等,则在排名序列中留出空位。 |
percent_rank() | double | 计算某个值在一组值中的百分比排名。返回值以 0 到 1 之间的小数表示。 |
dense_rank() | bigint | 计算某个值在一组值中的排名,如果出现排名相等,与函数rank不同,dense_rank不会在排名序列中产生空位。 |
cume_dist() | bigint | 计算某个值在分区中相对于所有值的位置。 |
ntile(n) | bigint | 将窗口分区的行划分为 n 个桶,返回行所在的桶数,范围从 1 到 n |
first_value(x) | 与输入一致 | 返回分区中某列第一条数据的值 |
last_value(x) | 与输入一致 | 返回分区中某列最后一条数据的值 |
nth_value(x, n) | 与输入一致 | 返回距窗口头第 n 行的值。n 从 1 开始。 如果ignoreNulls=true,查找第 n 行时将跳过 null。否则,每一行都计入 n。 如果不存在这样的第 n 行(例如,当 n 为10时,窗口大小小于10),则返回null。第一个参数为列名,第二个参数为之前第 n 行。 |
lead(x[, n[, default_value]]) | 与输入一致 | 返回窗口中当前行向下第 n 行的值。n 默认值为 1,default 默认值为 null。 如果第 n 行的 值为 null,则返回 null。 如果不存在这样的偏移行(例如,当偏移量为1时,窗口的最后一行没有任何向下行),则返回 default 。第一个参数为列名,第二个参数为之前第 n 行,第三个参数为默认值。 |
lag(x[, n[, default_value]]) | 与输入一致 | 返回窗口中当前行向上第 n 行的值。n 默认值为 1,default 默认值为 null。 如果第 n 行的 值为 null,则返回 null。 如果不存在这样的偏移行(例如,当偏移量为1时,窗口的第一行没有任何向上行),则返回 default。第一个参数为列名,第二个参数为之前第 n 行,第三个参数为默认值。 |
网址函数
函数名称 | 返回值 | 函数功能描述 |
url_extract_host(url) | varchar | 返回 ur 的主机 |
url_extract_parameter(url, name) | varchar | 返回 url 中 name 的第一个值,按照RFC 1866#section-8.2.1查找 |
url_extract_path(url) | varchar | 返回 url 的路径 |
url_extract_port(url) | bigint | 返回 url 的端口 |
url_extract_protocol(url) | varchar | 返回 url 的协议 |
url_extract_query(url) | varchar | 返回 url 的查询字符串 |
url_encode(value) | varchar | 对 value 进行 encode 编码 |
url_decode(value) | varchar | 对 encode 编码 的url 解码 |
其他函数
函数名称 | 返回值 | 函数功能描述 |
uuid ( ) | uuid | 返回一个随机生成的UUID |
cast(value AS type) | type | 将 value 强制转为 type 类型 |
try_cast(value AS type) | type | 将 value 转成 type 类型,如果失败返回 null |
typeof(expr) | varchar | 返回 expr 的类型名称 例如: typeof(cos(2) + 1.5) -->double |
regexp_extract(string, pattern) | varchar | 返回 string 中正则表达式 pattern 匹配的第一个子字符串 例如:regexp_extract('1a 2b 14m', '\\d+') ->1 |
regexp_replace(string, pattern) | varchar | 从 string 中移除正则表达式 pattern 匹配的子字符串 例如:regexp_replace('1a 2b 14m', '\\d+[ab] ') --> '14m' |
regexp_split(string, pattern) | | 使用正则表达式 pattern 拆分字符串并返回一个数组,保留后面的空字符串 例如:regexp_split('1a 2b 14m', '\\s*[a-z]+\\s*'); -- [1, 2, 14, ] |
regexp_like(string, pattern) | boolean | 判断 string 中是否有 pattern 匹配的字符串 |



