简介
In-Database AI(库内模型服务) 是 DBAI 节点(TDSQL Boundless AI Node)提供的一站式机器学习能力套件,为用户提供从特征工程、模型训练、模型评估到在线推理的完整机器学习服务。用户无需将数据导出至外部平台,即可在数据库内完成模型的全生命周期管理。
系统内置多种经典回归与集成学习算法,支持特征筛选与预处理,推理层统一基于 ONNX Runtime 实现高性能推理服务,同时支持从对象存储(COS)导入外部已训练好的 ONNX 格式模型以及调用外部大语言模型服务。
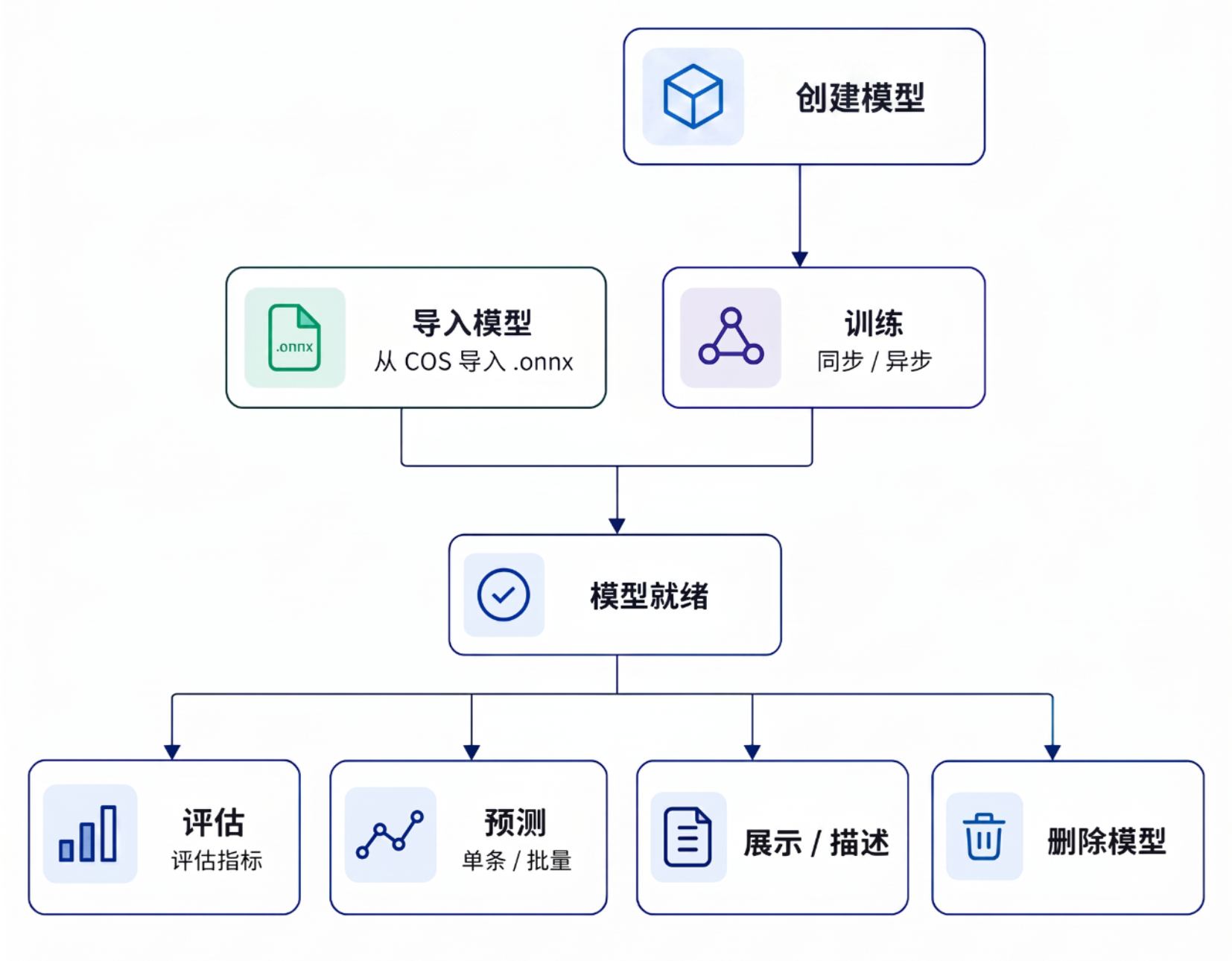
核心功能与优势
In-Database AI 对外提供以下核心能力:
特征工程:提供特征筛选(IV、PSI、Pearson)和特征预处理(归一化、One-Hot 编码、缺失值填充、标签编码)能力,预处理逻辑与模型绑定,推理时自动复用;
模型训练:内置 Linear Regression、SVR、LightGBM、Random Forest、GBRT、GBDT 共6种经典回归与集成学习算法,用户可直接在数据库内完成模型训练,训练结果自动转换为 ONNX 格式存储;
模型导入:支持从 COS 导入已训练好的 ONNX 模型文件,将外部平台的模型注册到数据库内统一管理和推理;
模型推理:统一基于 ONNX Runtime 执行,支持单条同步推理(在线场景)和批量异步推理(离线批量打分);
模型评估:支持 MSE、RMSE、MAE、R²、MAPE 等主流回归评估指标,基于测试数据集量化模型效果;
内置预训练模型:预置 BGE、E5、CLIP 等高质量 Embedding 模型,开箱即用;
外部 LLM 调用:支持注册外部大语言模型服务为数据库内函数,在查询中直接调用文本生成、情感分析等 AI 能力;
模型管理:提供模型查看、详情查询、异步任务监控及模型删除等完整生命周期管理操作。
基于以上能力,In-Database AI 具备以下功能优势:
数据零搬迁:训练与推理均在数据库内完成,无需将数据导出至外部平台,减少数据流转环节,降低安全风险;
训推一致性:预处理 Pipeline 与模型绑定持久化,训练和推理自动使用相同的数据处理逻辑,避免线上线下不一致;
灵活的执行模式:训练和推理均支持同步与异步两种模式,小任务即时返回,大任务后台执行不阻塞业务;
开放生态:既支持库内自主训练,也支持导入外部 ONNX 模型和对接外部 LLM 服务,兼容用户已有的 AI 资产;
开箱即用:内置多种预训练 Embedding 模型,无需额外训练即可使用向量化、语义搜索等能力。
功能使用
数据准备:特征工程
特征工程是建模前的关键步骤。通过对候选特征进行量化评估和筛选,用户可以选出对目标变量最具预测力和稳定性的特征子集,从而提升模型效果并降低过拟合风险。
特征筛选
服务提供以下三种特征筛选方法:
IV(Information Value) — 衡量特征对二分类目标变量的预测能力,IV 值越高表明区分正负样本的能力越强,广泛应用于信用评分、风控等场景
PSI(Population Stability Index) — 衡量特征分布在不同时间窗口间的漂移程度,PSI 过高说明特征不稳定,可能导致模型效果衰减,建议剔除
Pearson 相关系数 — 衡量特征与目标变量之间的线性相关性,同时检测特征间的多重共线性,帮助剔除冗余特征
支持单独使用某一方法,也支持多种方法组合筛选,系统对结果取交集,仅保留全部通过的特征。
示例:
SELECT FEATURE_SELECTION(METHOD = 'iv',TARGET = 'is_default',OPTIONS (bins = 10, threshold = 0.02))AS SELECT age, income, debt_ratio, credit_score, is_default FROM loan_data;-- 返回:-- +--------------+--------+----------------+-- | feature | iv | recommendation |-- +--------------+--------+----------------+-- | credit_score | 0.8523 | 强预测力 |-- | debt_ratio | 0.3214 | 中等预测力 |-- | income | 0.1056 | 弱预测力 |-- | age | 0.0089 | 无预测力(建议剔除)|-- +--------------+--------+----------------+
特征预处理
用户可在模型训练语句中通过
PREPROCESS 子句声明数据预处理逻辑。系统会将预处理参数与模型绑定持久化,在推理阶段自动执行相同的预处理操作,确保训练与推理的数据一致性。支持的预处理算子:
算子 | 功能 | 示例 |
NORMALIZE | 数值标准化(Z-Score 或 Min-Max) | NORMALIZE(col1, col2, method='minmax') |
FILL_NULL | 缺失值填充 | FILL_NULL(col1, strategy='mean') |
ONEHOT | 类别特征 One-Hot 编码 | ONEHOT(city, color) |
LABEL_ENCODE | 有序类别标签编码 | LABEL_ENCODE(size, order=['S','M','L','XL']) |
参数说明:
NORMALIZE:
参数 | 默认值 | 说明 |
method | 'zscore' | 'zscore':均值为0,方差为1;'minmax':缩放至 [0, 1] |
FILL_NULL:
参数 | 说明 |
strategy | 填充策略: 'mean' / 'median' / 'mode' / 'constant' |
value | 当 strategy 为 'constant' 时使用的固定填充值 |
示例:
CREATE MODEL sales_predictorALGORITHM = 'lightgbm'OPTIONS (n_estimators = 200, learning_rate = 0.05)PREPROCESS (NORMALIZE(temperature, humidity, method = 'minmax'),FILL_NULL(promotion_flag, value = 0),ONEHOT(store_type, weekday),LABEL_ENCODE(region, order = ['east', 'south', 'west', 'north']))AS SELECT temperature, humidity, promotion_flag, store_type, weekday, region, salesFROM store_salesWHERE year >= 2024;
模型构建:训练、导入与评估
模型训练
用户通过
CREATE MODEL 语句在数据库内训练模型。训练完成后,模型自动转换为 ONNX 格式存储,随时可用于推理。语法:
CREATE MODEL <model_name>ALGORITHM = '<algorithm_name>'[ OPTIONS ( <key> = <value> [, ...] ) ][ PREPROCESS ( <preprocess_expr> [, ...] ) ]AS <select_statement>[ ASYNC ];
参数说明:
参数 | 必选 | 说明 |
model_name | 是 | 模型唯一标识符,同名模型会报错(需先 DROP) |
ALGORITHM | 是 | 算法名称,见下表 |
OPTIONS | 否 | 算法超参数,不指定则使用默认值 |
PREPROCESS | 否 | |
AS <select> | 是 | 训练数据来源,最后一列默认作为 label |
ASYNC | 否 | 指定后以异步方式执行,立即返回 task_id |
支持的算法:
算法名称 | ALGORITHM 值 | 适用场景 |
Linear Regression | 'linear_regression' | 线性关系建模,可解释性要求高 |
SVR | 'svr' | 中小数据集非线性回归 |
LightGBM | 'lightgbm' | 大规模数据,精度与速度兼顾 |
Random Forest | 'random_forest' | 抗过拟合,对噪声数据鲁棒 |
GBRT | 'gbrt' | 中等规模精细建模 |
GBDT | 'gbdt' | 复杂非线性关系建模 |
示例:
CREATE MODEL house_price_lgbALGORITHM = 'lightgbm'OPTIONS (n_estimators = 100, learning_rate = 0.1)AS SELECT area, rooms, age, price FROM house_data;
执行模式:
同步模式(默认)— 系统阻塞等待训练完成,完成后返回训练摘要信息。适用于数据量较小、训练时间较短的场景。
CREATE MODEL my_modelALGORITHM = 'lightgbm'AS SELECT * FROM training_data;-- 返回:-- +------------+--------+-----------+------------+-- | model_name | status | algorithm | duration_s |-- +------------+--------+-----------+------------+-- | my_model | READY | lightgbm | 12.3 |-- +------------+--------+-----------+------------+
异步模式 — 系统立即返回任务 ID,训练在后台执行。适用于大数据集、训练耗时较长的场景。用户可随时查询训练进度。
CREATE MODEL my_modelALGORITHM = 'lightgbm'AS SELECT * FROM training_dataASYNC;-- 返回:-- +---------+----------+-- | task_id | status |-- +---------+----------+-- | t_a1b2c | CREATING |-- +---------+----------+
查询训练进度:
SHOW TRAIN JOB 't_a1b2c';-- 返回:-- +---------+--------+----------+------------+-- | task_id | status | progress | duration_s |-- +---------+--------+----------+------------+-- | t_a1b2c | READY | 100% | 45.2 |-- +---------+--------+----------+------------+
模型导入
对于已在外部平台完成训练的模型,用户可通过
IMPORT MODEL 语句从 COS(对象存储)导入 ONNX 格式的模型文件,注册到数据库内统一管理和推理。导入时支持声明预处理逻辑,推理阶段系统将自动执行。语法:
IMPORT MODEL <model_name>FROM '<cos_path>'INPUT ( <column_name> <data_type> [, ...] )OUTPUT ( <column_name> <data_type> [, ...] )[ PREPROCESS ( <preprocess_expr> [, ...] ) ];
参数说明:
参数 | 必选 | 说明 |
model_name | 是 | 模型唯一标识符 |
FROM | 是 | COS 路径,格式为 cos://bucket/path/model.onnx |
INPUT | 是 | 模型输入特征的列名与数据类型 |
OUTPUT | 是 | 模型输出的列名与数据类型 |
PREPROCESS | 否 |
支持的数据类型:
类型 | 说明 |
FLOAT | 32位浮点数 |
DOUBLE | 64位浮点数 |
INT | 32位整数 |
BIGINT | 64位整数 |
STRING | 字符串(用于类别特征) |
示例:
基础导入:
IMPORT MODEL external_price_modelFROM 'cos://ml-models/production/price_v3.onnx'INPUT (area FLOAT,rooms INT,floor INT,age FLOAT,has_parking INT)OUTPUT (predicted_price FLOAT);-- 返回:-- +------------------------+--------+-----------+-- | model_name | status | source |-- +------------------------+--------+-----------+-- | external_price_model | READY | cos_import|-- +------------------------+--------+-----------+
携带预处理的导入:
IMPORT MODEL external_score_modelFROM 'cos://ml-models/production/score_v2.onnx'INPUT (age FLOAT,income FLOAT,city STRING)OUTPUT (risk_score FLOAT)PREPROCESS (NORMALIZE(age, income, method = 'minmax'),ONEHOT(city));
模型评估
模型训练或导入完成后,用户可使用测试数据集对模型进行效果评估,量化模型的预测质量。
语法:
EVALUATE MODEL <model_name>[ METRICS ( <metric_name> [, ...] ) ]AS <select_statement>;
支持的评估指标:
指标 | 全称 | 说明 |
mse | Mean Squared Error | 均方误差 |
rmse | Root Mean Squared Error | 均方根误差 |
mae | Mean Absolute Error | 平均绝对误差 |
r2 | R-Squared | 决定系数 |
mape | Mean Absolute Percentage Error | 平均绝对百分比误差 |
说明:
若不指定
METRICS 子句,系统将默认返回全部指标。示例:
EVALUATE MODEL house_price_lgbMETRICS (rmse, r2, mae)AS SELECT area, rooms, age, price FROM test_data;-- 返回:-- +------------------+-------+------+--------+-- | model_name | rmse | r2 | mae |-- +------------------+-------+------+--------+-- | house_price_lgb | 12.45 | 0.93 | 8.72 |-- +------------------+-------+------+--------+
模型服务:推理、内置模型与管理
单条推理(同步)
将
PREDICT 作为函数嵌入查询语句中,实时返回预测结果。语法:
SELECT PREDICT(<model_name>, <col1>, <col2>, ...) AS <alias>[, <other_columns>]FROM <table>[ WHERE <condition> ];
示例:
-- 对单条记录进行推理SELECT id, PREDICT(house_price_lgb, area, rooms, age) AS predicted_priceFROM house_dataWHERE id = 1001;-- 返回:-- +------+-----------------+-- | id | predicted_price |-- +------+-----------------+-- | 1001 | 356.8 |-- +------+-----------------+-- 对小批量数据进行同步推理SELECT id, PREDICT(house_price_lgb, area, rooms, age) AS predicted_priceFROM house_dataWHERE city = 'shanghai'LIMIT 100;
批量推理(异步任务)
面向大规模数据的离线推理场景。系统以后台任务形式执行,立即返回任务 ID,推理结果写入用户指定的目标位置。
语法:
CREATE PREDICT JOBUSING MODEL <model_name>INPUT ( <select_statement> )OUTPUT TO '<target>';
输出目标支持:
COS 路径 —
cos://bucket/path/result.csv数据库表 —
db_name.table_name示例:
-- 结果写入 COSCREATE PREDICT JOBUSING MODEL house_price_lgbINPUT (SELECT area, rooms, age FROM house_data WHERE city = 'beijing')OUTPUT TO 'cos://ml-results/batch_predict_20260520.csv';-- 返回:-- +---------+----------+-- | task_id | status |-- +---------+----------+-- | t_x7y8z | RUNNING |-- +---------+----------+-- 结果写入数据库表CREATE PREDICT JOBUSING MODEL house_price_lgbINPUT (SELECT id, area, rooms, age FROM house_data)OUTPUT TO 'mydb.prediction_results';
任务状态查询
SHOW PREDICT JOB '<task_id>';-- 返回:-- +---------+-----------+----------+------------+----------------------------------+-- | task_id | status | progress | duration_s | output_location |-- +---------+-----------+----------+------------+----------------------------------+-- | t_x7y8z | COMPLETED | 100% | 128.5 | cos://ml-results/batch_...csv |-- +---------+-----------+----------+------------+----------------------------------+
任务状态说明:
状态 | 说明 |
RUNNING | 任务执行中 |
COMPLETED | 任务完成,结果可读取 |
FAILED | 任务失败,可通过错误信息排查原因 |
内置预训练模型
以下模型由系统预置,用户无需训练或导入即可直接调用:
BGE-Large-ZH-v1.5 — 中文文本 Embedding 模型,精度最高,适合语义匹配准确率要求极高的场景,如精细化搜索、知识库问答
Multilingual-E5 — 多语言 Embedding 模型,支持100+语种的统一语义空间,适合跨语言检索与多语言内容理解
CLIP 系列 — 图文多模态 Embedding 模型,支持以文搜图、以图搜文,适合电商搜索、内容审核、多模态推荐
外部 LLM 函数调用
用户可将外部大语言模型服务(如 GPT、Claude、混元、文心等)注册为数据库内的可调用函数,在查询中直接调用 LLM 进行文本生成、摘要提取、情感分析、实体抽取等操作。
注册:
CREATE LLM FUNCTION <function_name>ENDPOINT = '<service_url>'OPTIONS (api_key = '<key>',model = '<model_name>',timeout_ms = 30000,max_tokens = 1024);
调用:
-- 文本摘要SELECT id, LLM_INVOKE(my_llm, concat('请总结以下内容:', content)) AS summaryFROM articlesWHERE id = 1001;-- 情感分析SELECT id, title, LLM_INVOKE(my_llm, concat('判断以下评论的情感倾向(正面/负面/中性):', comment)) AS sentimentFROM user_reviewsLIMIT 50;-- 使用 PROMPT 模板SELECT id, LLM_INVOKE(my_llm, PROMPT('extract_entities', content)) AS entitiesFROM documents;
管理:
-- 查看已注册的 LLM 函数SHOW LLM FUNCTIONS;-- 查看函数详情DESCRIBE LLM FUNCTION my_llm;-- 删除 LLM 函数DROP LLM FUNCTION my_llm;
模型管理
产品提供完整的模型生命周期管理能力,用户可随时查看模型列表、了解模型详情、监控异步任务状态以及删除不再需要的模型。
查看模型列表:
SHOW MODELS;-- 返回:-- +------------------------+-----------+------------------+---------------------+--------+-- | model_name | algorithm | source | created_at | status |-- +------------------------+-----------+------------------+---------------------+--------+-- | house_price_lgb | lightgbm | trained | 2026-05-20 10:30:00 | READY |-- | house_price_lr | linear_reg| trained | 2026-05-19 14:00:00 | READY |-- | external_price_model | onnx | cos_import | 2026-05-18 09:15:00 | READY |-- +------------------------+-----------+------------------+---------------------+--------+
查看模型详情:
DESCRIBE MODEL house_price_lgb;-- 返回:-- +----------------+----------------------------------------------------+-- | property | value |-- +----------------+----------------------------------------------------+-- | model_name | house_price_lgb |-- | algorithm | lightgbm |-- | status | READY |-- | source | trained |-- | created_at | 2026-05-20 10:30:00 |-- | features | area (FLOAT), rooms (INT), age (FLOAT) |-- | label | price (FLOAT) |-- | options | n_estimators=100, learning_rate=0.1 |-- | preprocess | NORMALIZE(area, age, method='minmax') |-- | model_size | 2.3 MB |-- | training_rows | 50000 |-- | train_duration | 12.3s |-- +----------------+----------------------------------------------------+
查看异步任务:
SHOW JOBS;-- 返回:-- +---------+----------+------------------+-----------+---------------------+-- | task_id | type | model_name | status | created_at |-- +---------+----------+------------------+-----------+---------------------+-- | t_a1b2c | TRAIN | my_model | COMPLETED | 2026-05-20 10:00:00 |-- | t_x7y8z | PREDICT | house_price_lgb | RUNNING | 2026-05-20 11:30:00 |-- +---------+----------+------------------+-----------+---------------------+
删除模型:
删除模型将同时清理关联的 ONNX 文件、预处理 Pipeline 及元数据信息。
DROP MODEL <model_name>;
DROP MODEL house_price_lr;-- 返回:-- +----------------+--------+-- | model_name | status |-- +----------------+--------+-- | house_price_lr | DROPPED|-- +----------------+--------+
注意:
正在执行推理任务的模型不允许删除,需先取消相关任务。删除操作不可恢复。



