TDMQ RocketMQ 版支持对您账户下的资源状态进行日常监控,您可以通过控制台实时查看 RocketMQ 各类资源的监控数据,了解集群的健康状况。
查看监控数据
1. 登录 TDMQ RocketMQ 版控制台。
2. 在左侧导航栏单击监控大盘,选择好地域和要查看的集群。
3. 在监控页面选择要查看的资源页签,设置好时间范围后,查看对应的监控数据。
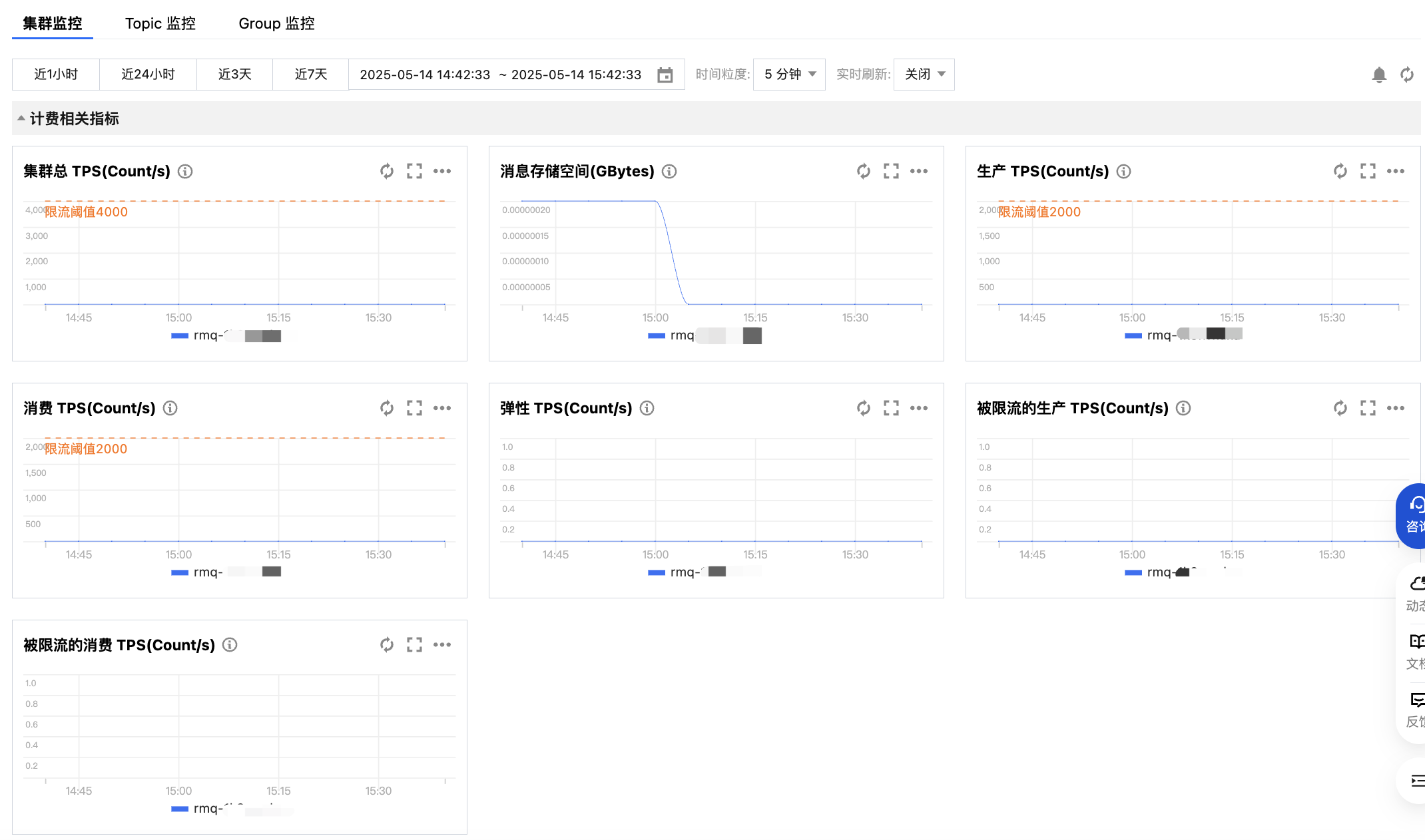
在集群监控页面,您可以选择集群内的多个 Topic,查看多个 Topic 的指标对比,如下图所示。
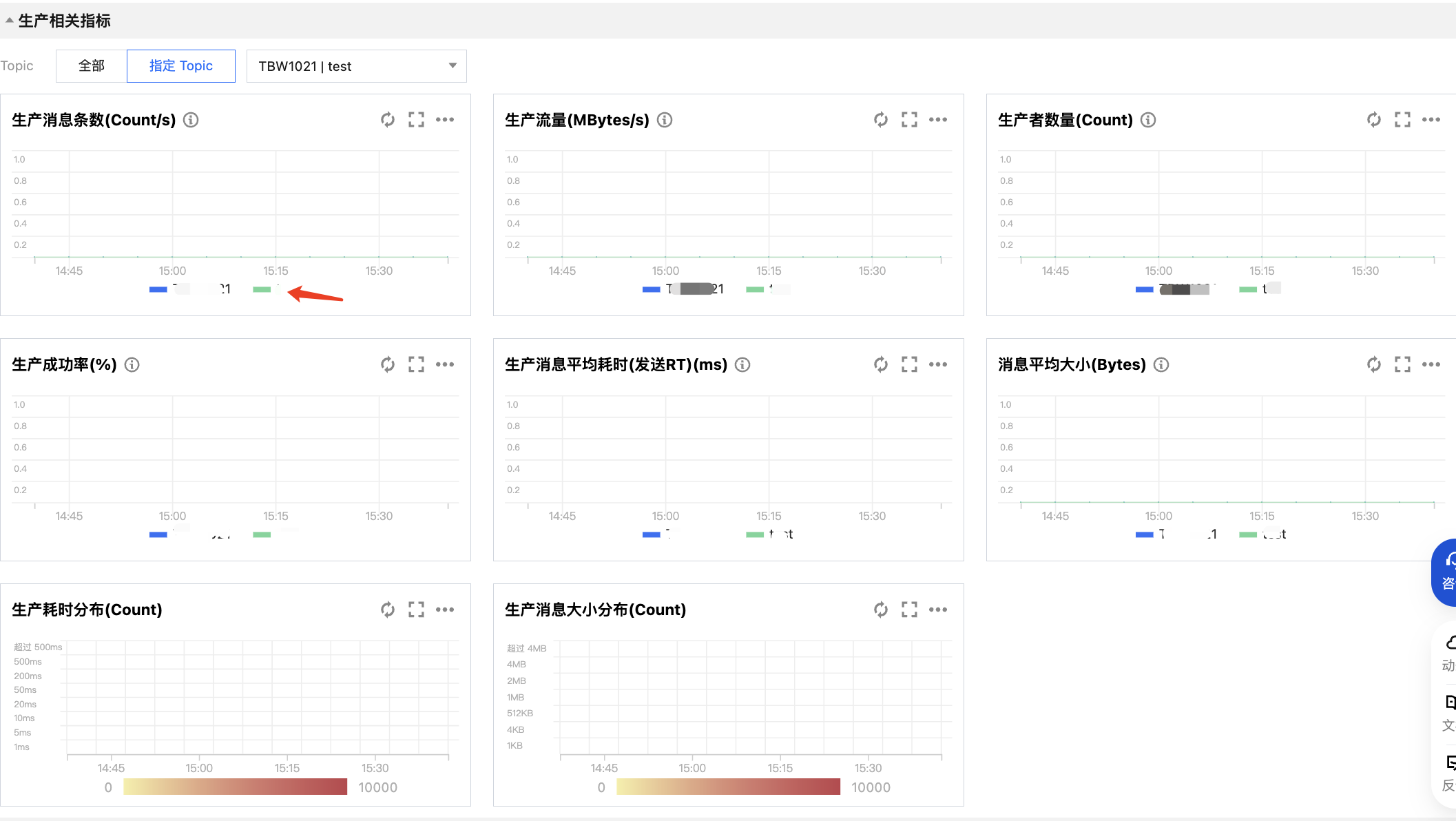
同理,您可以查看某个 Topic 下,订阅关系内的多个 Group 的相关指标对比;也可以查看某个 Group 下,订阅关系内的多个 Topic 的相关指标对比。
时间选择器说明
您可通过以下功能灵活控制监控数据展示:自由选择时间区间、调整时间粒度和刷新频率。
操作 | 图标 | 说明 |
时间范围选择 | 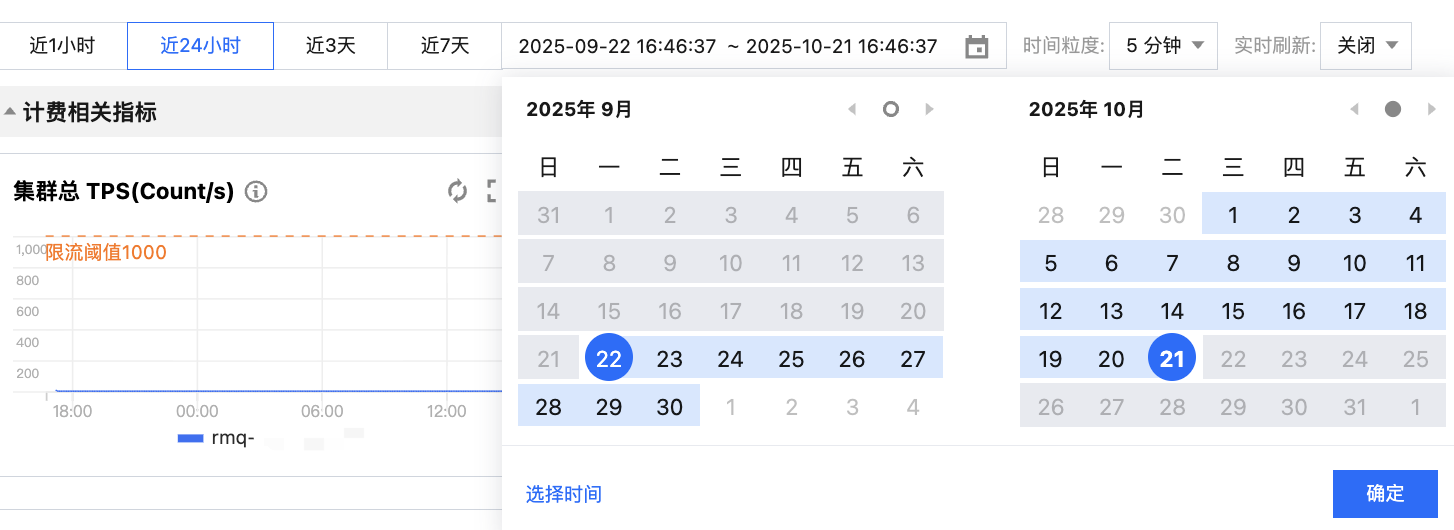 | 时间选择框,单击可选择图表展示的监控时间范围,默认选取近一小时内数据。 通过上方时间值可以快速选择指定时间区间。 通过日历可以选择大范围时间段。 通过左下角“选择时间”可以进一步选择精确到秒的时间范围。 |
时间粒度 |  | 时间粒度,单击可选择1分钟、5分钟或者1小时。 |
实时刷新 |  | 实时刷新间隔,单击右侧下拉选项可设置图表整体自动刷新时间,支持30秒、1分钟、5分钟或者关闭。 |
图表图标说明
对 RocketMQ 提供的每幅监控图像,您都可执行以下操作:
操作 | 图标 | 说明 |
查看数据 |  | 鼠标悬停在图像上方,可以查看对应时间点下的数据明细。 |
刷新数据 |  | 可单击刷新该监控图表的最新数据。 |
全屏显示 |  | 单击可全屏展示对应图表,按 Esc 或右上角的叉号退出全屏模式。 |
数据导出 |  | 单击可选择将图表数据以图片的形式导出。 |



