腾讯云向量数据库(Tencent Cloud VectorDB)采用开源工具 ann-benchmark 进行性能测试,并且为适应云上测试场景,对 ann-benchmark 工具进行了改造适配。本文详细介绍基于 ann-benchmark 工具进行数据库性能测试的方法。
下载并上传工具与数据集
1. 下载测试工具。
2. 获取腾讯云向量数据库提供的数据集。
说明:
ann-benchmark 官方数据集默认不需要提前下载,测试工具运行时会自动检查 ./data 目录下是否存在数据集文件,如果不存在则会主动联网下载。
3. 登录云服务器 CVM 环境,使用
rz 命令上传测试工具于 CVM。CVM 要求,请参见 测试环境。4. 执行
unzip ann-benchmarks-dev.zip命令解压测试工具压缩包 ann-benchmarks-dev.zip。5. 使用
rz 命令上传数据集于测试工具解压目录../ann-benchmarks-dev/ann-benchmarks/data。测试 128 维数据在 HNSW 索引下单核查询性能
步骤1 : 安装工具环境依赖
进入已解压的测试工具包的路径,安装 python 运行依赖。
cd ann-benchmarkspip3 install -r requirements.txt
步骤2:修改配置文件
执行如下命令,拷贝配置文件,并打开配置文件,配置相关参数。需配置的参数信息,请参见下表,其余参数保持默认值即可。
cp ann_benchmarks/algorithms/vector_db/config.yml mytest.ymlvi mytest.yml
配置文件参数 | 参数含义 | 建议值 |
arg_groups 下的第一个参数 | 索引类型为 HNSW 的参数 M,指每个节点在检索构图中可以连接多少个邻居节点 | 设置 16 |
HttpBase | 连接向量数据库访问地址 | |
User | 连接用户名 | root |
ApiKey | 向量数据库的 API 访问密钥 | |
IndexType | 索引类型 | HNSW |
MetricType | 相似度计算方法 | L2 |
ColReplicaNum | 副本数 | 2 |
Threads | 单线程进行测试 | 1 |
ColShardNum | 分片数量 | 3 |
EfConstruction | 索引类型为 HNSW 的参数 ef,搜索时,指定寻找节点邻居遍历的范围 | 500 |
BuildIndexOnUpsert | 指定插入数据时,同步更新索引 | true:重新创建索引。 false:不重新创建索引。 |
query_args | 指定了在数据插入完成后,需要进行ef为10,15,20 等的查询 | [ 10, 15, 20, 25, 30, 35, 40, 50, 60, 80, 120, 200, 400 ] |
float:any:- base_args: [ '@metric' ]constructor: VectorDbdisabled: falsedocker_tag: ann-benchmarks-vector_dbmodule: ann_benchmarks.algorithms.vector_dbname: vector_dbrun_groups:vector_db:arg_groups:- [ 16 ]- DbName: db-testHttpBase: http://127.0.0.1:18100NeedAuth: trueUser: rootApiKey: invalid-by-defaultDropDb: falseCreateDb: trueReCreateCollection: falseDropCollectionOnDone: falseIndexType: HNSWMetricType: L2ColReplicaNum: 2ColShardNum:EfConstruction: 500ExitOnError: trueThreads: 1MultiCpuUpsert: trueUpsertBatchSize: 500BuildIndexOnUpsert: trueKNNSeekMode: falseKNNSeeKStartEf: 90KNNSeekStep: 1KNNSeekExpect: 0.95args: { }query_args:- [ 10, 15, 20, 25, 30, 35, 40, 50, 60, 80, 120, 200, 400 ]- RetrieveVector: false
步骤3:运行测试工具
说明:
euclidean 使用的是 L2 相似度算法,angular 使用的是 IP 算法。
python3 run.py --dataset sift-128-euclideam --local --force --parallelism 1 --algorithm vector_db --definitions=mytest.yml --runs 1
步骤4:查看测试运行结果
测试结束后,测试结果保存在 results 文件夹中,需要使用如下命令将结果转换为可读的 csv 文件。如下所示,可通过生成的 mytest.csv 文件,查看 128 维数据在 HNSW 索引下单核的性能表现。
python3 data_export.py --output=mytest.csv
探索指定召回率,需设置的查询 EF 值
步骤1:打开探索模式
打开配置文件 mytest.yml,修改配置文件中的 KNNSeekMode 参数为 true, 该模式测试工具会反复运行不同 ef 值的查询,直到获得最匹配的召回率为止。
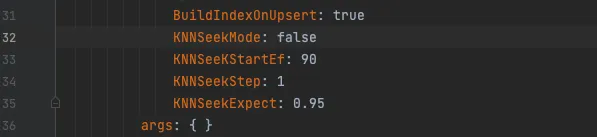
步骤2:配置探索参数
配置文件参数 | 参数含义 | 建议值 |
KNNSeekStartEF | 指定开始查询 ef 设置的起始值,即从哪一个ef 参考值开始查询 | 90 |
KNNSeekStep | 指定探索模式中,每次 ef 值变化几个单位。如1,则表示 KNNSeekStartEF+=1 或相减,每次递增或递减的步长 | 1 |
KNNSeekExpect | 期望找到的召回率 | 0.95 |
步骤3:运行工具
python3 run.py --dataset sift-128-euclideam --local --force --parallelism 1 --algorithm vector_db --definitions=mytest.yml --runs 1 --only_query
步骤4: 查看运行结果
结果显示如下图所示,KNNSeekExpect=0.95,即在ef=61时,可获得最接近0.95的召回率。

Search 检索查询性能
步骤1:设置期望的 EF 值,压测查询配置
在配置文件中,如下使用8核压测查询
ef=111的情况。 注意需要设置 KNNSeekMode为 false。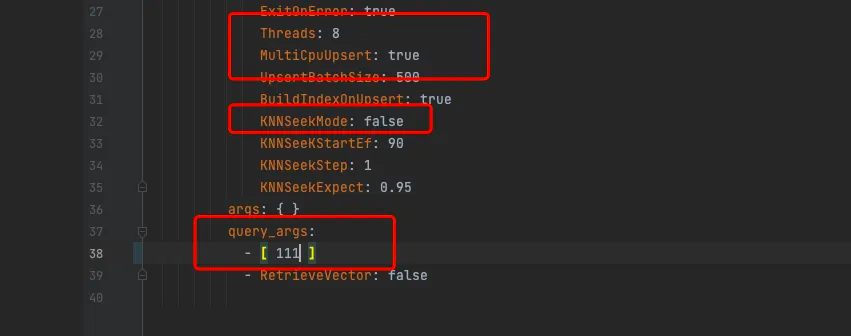
步骤2:运行工具
python3 run.py --dataset sift-128-euclideam --local --force --parallelism 1 --algorithm vector_db --definitions=mytest.yml --runs 999 --only_query --batch
步骤3:查看结果
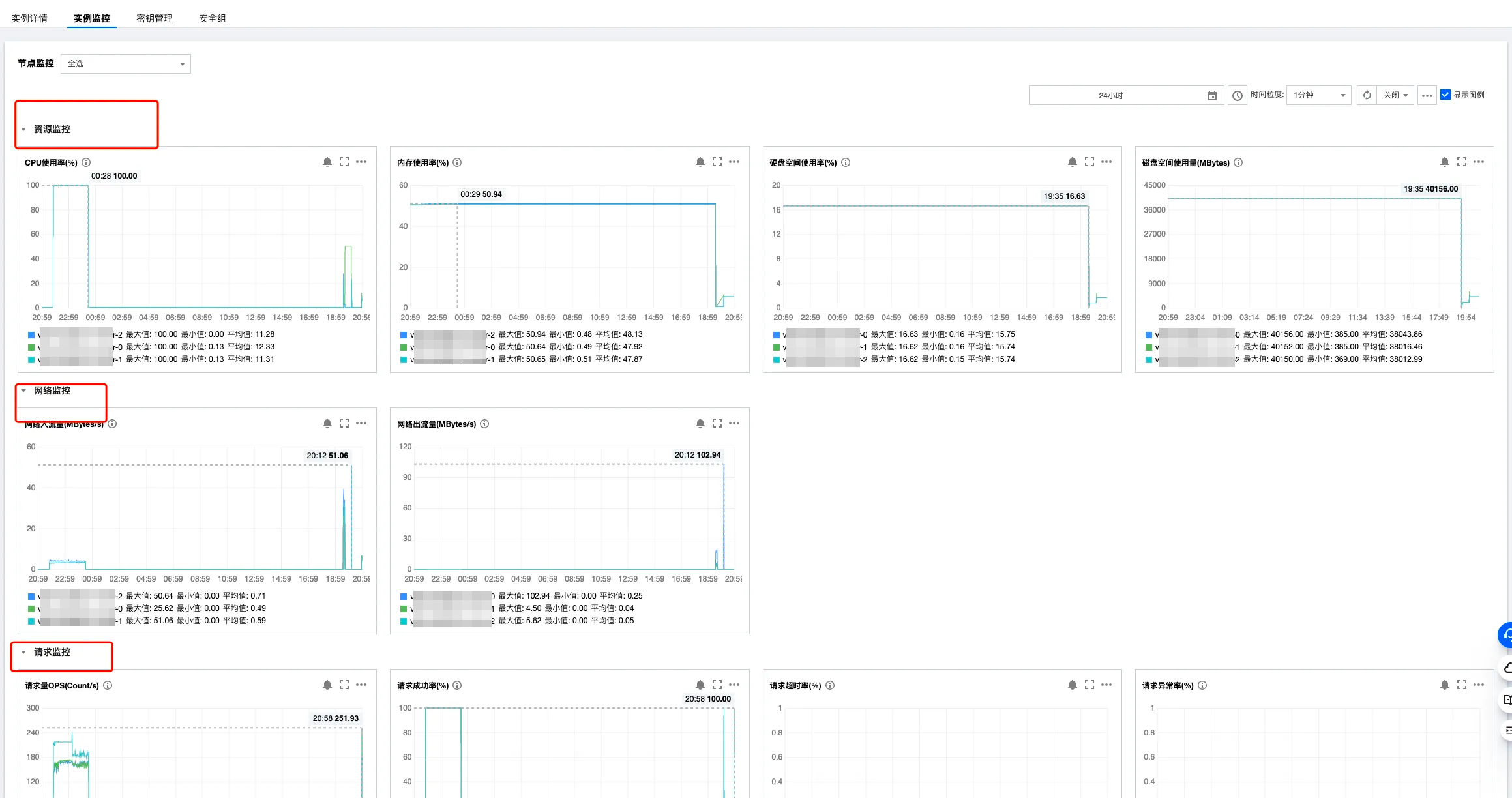
说明:
受限于 python 语言的线程模型,有时测试工具无法把测试压力打满,导致实例性能无法达到极限,此时可使用多进程或多台 CVM 同时进行压测。



