操作场景
当业务流量发生变化导致实例数据和负载下降时,可以通过减少分片数量释放一定的数据库资源,将集群规模调整至与当前负载相匹配的状态,实现按需配置,避免资源浪费。
说明:
删减分片会触发数据迁移,可能对实例负载带来长时间影响。建议您优先评估直接降低 Mongod 节点规格来达到降低成本的目的。具体操作,请参见 变更 Mongod 节点配置规格。
删减分片功能目前处于公测期间。如有使用需求,请 提交工单 申请。
影响与约束
在删减分片数量操作前,请务必仔细阅读以下关键信息,以确保操作符合预期且不影响业务稳定性。
维度 | 减少分片 |
计费影响 | 包年包月:计算旧规格的剩余费用与新配置的价格,完成退款。在下一个续费时刻,按照新规格扣费。 按量计费:结算旧的规格,按照新规格重新开始计费。 具体计费信息,请参见 变配计费。 |
版本要求 | 通用版:MongoDB 4.0及以上。 云盘版:不支持删减分片。 |
服务影响 | 操作过程业务零中断,可正常读写数据库,并可自动备份与手动备份。 操作过程中,严禁执行任何可能干扰数据迁移的操作,包括但不限于: 数据回档与实例销毁。 配置变更与主从切换。 变更连接地址。 对待删分片操作。 |
限制与约束 | 删减顺序:按创建时间倒序自动选择待删分片。 空间要求:删减后,剩余分片的总存储空间必须 ≥ 集群已用空间的120%,否则无法删减。 删减数量:每次发起删减的数量不能超过原集群数量的一半,删减后分片数必须≥2个。 说明: 因内核限制,MongoDB 4.0版本一次只能删除一个分片。 均衡器要求:删减前需开启 Balancer 并设置 Balancing Window(均衡窗口),以控制数据迁移对业务的影响。 耗时:分片删减会触发数据重分布,受数据量、Balancer 设置等影响,可能较慢。 |
操作前检查清单
序号 | 检查项目 | 检查标准 | 具体说明与操作指引 |
1 | 实例状态 | 实例状态为 “运行中” | 在实例列表中确认目标实例运行正常。 |
2 | 分片数量 | 删减前,分片数量必须大于2 | 此为前提条件。若当前分片数等于2,则无法进行删减;删减后分片数将少于2,不符合集群架构要求。 |
3 | 实例到期时间 | 包年包月实例的到期时间需大于等于14天 | 在实例详情页面的配置信息区域查看到期时间,确保实例有足够剩余服务时长。 |
4 | 删减后存储空间 | 剩余分片的总存储空间 > 集群当前已使用空间 × 120% | 1. 在实例详情的规格信息区域查看总存储空间与已使用空间 2. 计算剩余分片的总存储空间,示例如下所示。 当前总空间:150GB (3分片 × 50GB) 计划删减:1个分片 删减后空间:100GB 当前已使用:1.5GB 所需最小空间:1.5GB × 120% = 1.8GB 判断:100GB > 1.8GB,检查通过。 |
5 | 均衡器设置 | 确保均衡器已开启,并建议设置均衡时间窗 | 1. 在控制台参数配置页面,将 openBalance.window 参数设置为 true 以开启均衡器。 2. 通过 balance.window 参数设置业务低峰期作为均衡时间窗,以减少数据迁移对业务的影响。具体操作,可参见 参数配置。 |
6 | 主分片检查 | 确认待删减分片不是任何非分片集合的主分片 | 1. 使用 MongoDB Shell 连接实例,通过 getSiblingDB("config").databases.find() 查询配置数据库,识别目标分片为主分片的数据库。 说明: 分片名称格式:cmgo-xxxxxxxx_n,其中,xxxxxxxx 为实例唯一标识(8位字符);n 为分片序号,从0开始编号。例如,一个5分片实例,分片名为 cmgo-xxxxxxxx_0 到 cmgo-xxxxxxxx_4,如果客户要删减最后一个分片,就应该指定 cmgo-xxxxxxxx_4。
2. 对识别出的每个数据库,通过 getCollectionNames() 方法,获取所有集合的完整列表。
3. 通过 db.collection.stats().sharded 检查每个集合的分片状态,如果返回值为 false(表示未分片),则必须使用 movePrimary 命令将该集合所在数据库的主分片迁移到其他分片。具体操作,请参见 movePrimary(数据库命令) 。 说明: 在 MongoDB 4.0和4.2版本,执行 movePrimary 后,需要刷新路由信息,否则业务读写可能受阻。刷新方法如下所示: 4.0版本:执行 movePrimary 后,重启所有 mongos 节点,或在所有 mongos 节点上执行 flushRouterConfig 命令。 4.2版本:执行 movePrimary 后,重启所有 mongos 和 mongod 节点,或在所有 mongos 和 mongod 节点上执行 flushRouterConfig 命令。
|
删减分片
1. 登录 MongoDB 控制台。
2. 在左侧导航栏 MongoDB 的下拉列表中,选择分片实例。
3. 在右侧实例列表页面上方,选择地域。
4. 在实例列表中,找到目标实例。
5. 单击实例 ID,进入实例详情页面,切换至节点管理页面。
6. 在节点操作的下拉列表中,选择删减分片。

7. 在删减分片小窗口,了解删减分片的限制与条件,并参见下表,指定需删减的分片数量。
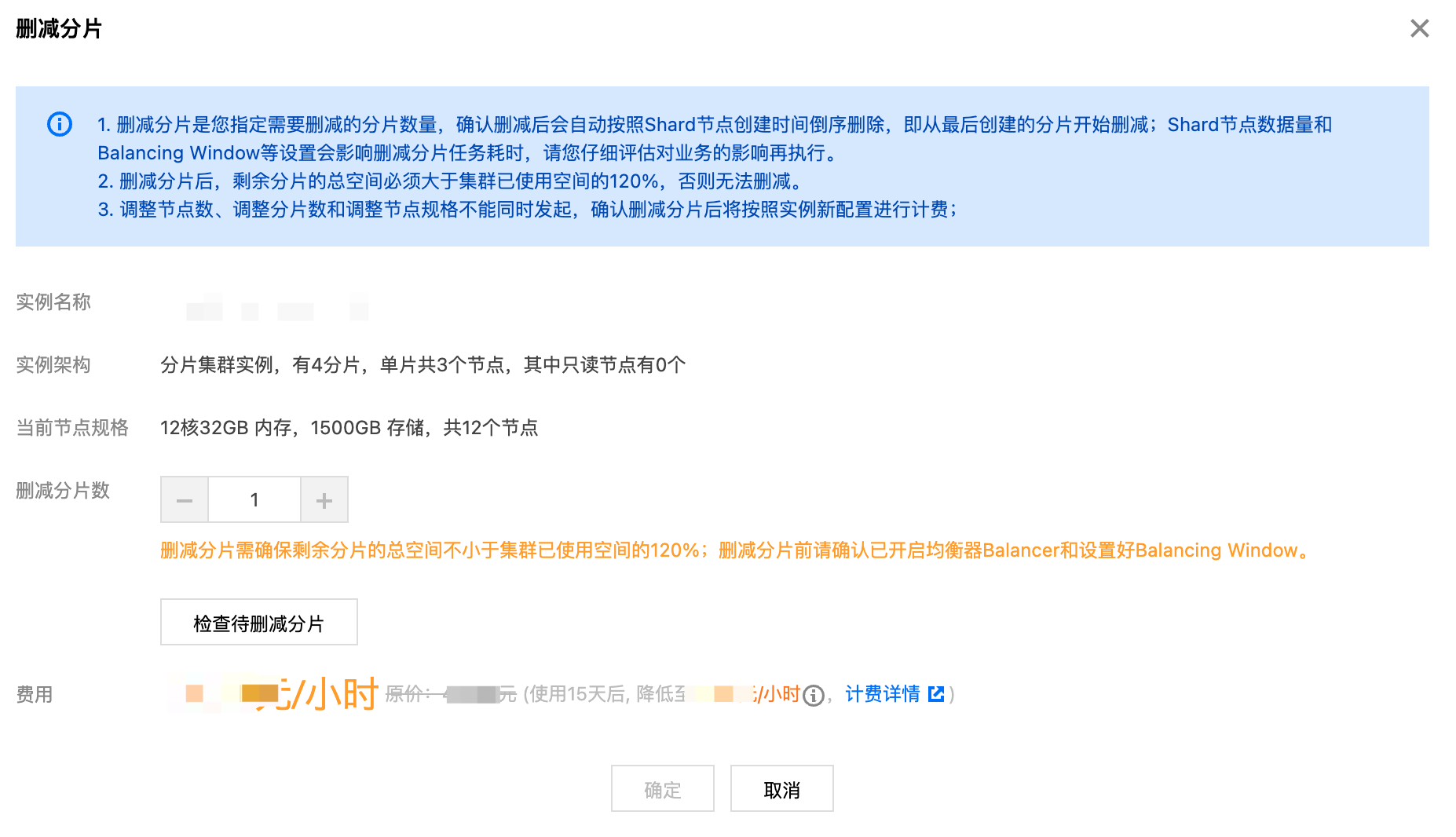
参数分类 | 参数项 | 参数示例 | 参数解释 |
实例基本信息 | 实例名称 | test-4dot2-XXX | 当前待删减分片数的实例名称。 |
| 到期时间 | 2025-04-24 19:23:43 | 包年包月计费模式,实例服务周期的截止时间。 |
| 实例架构 | 分片集群实例,有3分片,单片共4个节点,其中只读节点有1个 | 实例集群架构:分片集群实例。 分片数量:删减前的分片数量。 单分片节点数:单个分片的节点数、只读节点数。 |
| 当前节点规格 | 2核4GB内存,250GB存储,共10个节点 | 单分片节点规格:包括 CPU 核数、内存、存储容量。 集群节点总数:删减前实例总的节点数(分片数量 * 单分片的节点数 = 集群节点总数)。 |
删减配置 | 删减分片数 | 2 | 指定实例需删减的分片数量。 |
| | | 指定了删减分片数量之后,单击检查待删减分片,检查删减分片的条件是否满足。 检查剩余分片数量:确保删减后,剩余分片数量不少于2个。 检查存储空间:确保删减后,剩余分片的总存储容量大于集群当前已使用空间的120%。 检查主分片数据:检查待删减分片中是否包含任何数据库的主分片。若存在,您必须手动将其迁移至其他分片后方可继续操作。 |
费用信息 | 计费方式 | 6.69元/小时 | 按量计费:显示实例减少分片后每小时的计费单价。 包年包月:显示降级规格后所需退还的费用。 |
8. 确认无误,单击确定。若实例为包年包月计费,您需要在确认产品信息页面支付新旧规格的差价,方可成功完成配置调整。
注意:
若 Shard 节点数据量过大、Balancing Window 设置过小或存在 Jumbo Chunk,将直接导致删减分片任务耗时延长甚至阻塞失败。关于具体的排查与解决方法,请参见 删减分片任务:进度确认与异常排查指南。
9. 任务执行期间,如需停止删减,请在任务管理页面单击终止。终止后,分片数量将恢复原状。

相关 API
接口名称 | 功能描述 |
调整云数据库实例配置 | |
查询云数据库的售卖规格 |
附录:确认待删减分片不是任何非分片集合的主分片的操作示例
1. 通过
getSiblingDB("config").databases.find() 查询配置数据库,识别目标分片为主分片的数据库。如下示例,查询分片 cmgo-xxxxxxxx_3 为主分片的数据库。mongos> db.getSiblingDB("config").databases.find({primary: "cmgo-xxxxxxxx_3"}){ "_id" : "bulk_db_db_3", "primary" : "cmgo-xxxxxxxx_3", "partitioned" : false, "version" : { "uuid" : UUID("xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxx"), "timestamp" : Timestamp(1762855003, 5), "lastMod" : 1 } }{ "_id" : "bulk_db_db_4", "primary" : "cmgo-xxxxxxxx_3", "partitioned" : false, "version" : { "uuid" : UUID("xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx"), "timestamp" : Timestamp(1762855035, 2), "lastMod" : 1 } }{ "_id" : "bulk_db_db_10", "primary" : "cmgo-xxxxxxxx_3", "partitioned" : false, "version" : { "uuid" : UUID("xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx"), "timestamp" : Timestamp(1762855333, 3), "lastMod" : 1 } }{ "_id" : "bulk_db_db_14", "primary" : "cmgo-xxxxxxxx_3", "partitioned" : false, "version" : { "uuid" : UUID("xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx"), "timestamp" : Timestamp(1762855462, 30), "lastMod" : 1 } }
2. 对识别出的每个数据库,通过 getCollectionNames() 方法,获取所有集合的完整列表。如下示例,查询bulk_db_db_77 数据库的所有集合。
mongos> db.getSiblingDB("bulk_db_db_77").getCollectionNames()["collection_1","collection_10","collection_11","collection_12","collection_13","collection_14","collection_15","collection_16","collection_17","collection_18","collection_19","collection_2","collection_20","collection_3","collection_4","collection_5","collection_6","collection_7","collection_8","collection_9"]
3. 通过 db.collection.stats().sharded 检查每个集合的分片状态。如下示例,查询数据库 bulk_db_db_77.collection1 集合的分片状态。"sharded" : false, 则需要使用 movePrimary 命令将该集合所在数据库的主分片迁移到其他分片。
mongos> db.getSiblingDB("bulk_db_db_77").collection1.stats(){"sharded" : false,"primary" : "cmgo-xxxxxxxx_3","ns" : "bulk_db_db_77.collection1","count" : 0,"size" : 0,"storageSize" : 0,"totalIndexSize" : 0,"totalSize" : 0,"indexSizes" : {},"avgObjSize" : 0,"maxSize" : NumberLong(0),"nindexes" : 0,"scaleFactor" : 1,"nchunks" : 1,"shards" : {"cmgo-xxxxxxxx_3" : {"ns" : "bulk_db_db_77.collection1","size" : 0,"count" : 0,"numOrphanDocs" : 0,"storageSize" : 0,"totalSize" : 0,"nindexes" : 0,"totalIndexSize" : 0,"indexDetails" : {},"indexSizes" : {},"scaleFactor" : 1,"ok" : 1,"$clusterTime" : {"clusterTime" : Timestamp(1763094536, 1),"signature" : {"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),"keyId" : NumberLong(0)}},"$configTime" : Timestamp(1763094535, 2),"$topologyTime" : Timestamp(1762853939, 5),"operationTime" : Timestamp(1763094536, 1)}},"ok" : 1,"$clusterTime" : {"clusterTime" : Timestamp(1763094536, 1),"signature" : {"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),"keyId" : NumberLong(0)}},"operationTime" : Timestamp(1763094536, 1)}mongos> db.getSiblingDB("bulk_db_db_77").collection1.stats().shardedfalse



