精彩集锦功能简介
精彩集锦功能可以通过智能算法自动捕捉并生成视频中的精彩片段,为用户提供快速回顾与分享,辅助提升后期制作的效率。
前置操作

集锦场景及计费说明
处理类型 | 精彩集锦版本分类 | 描述 | 支持视频场景 | 计费说明 |
处理离线文件 | 精彩集锦-大模型版 | 基于大模型视频理解,自动分析视频内容,从而提取出关键场景和亮点时刻。可自定义调整视频理解 Prompt。 | 自定义场景 全景相机、VLOG 视频场景 短剧影视剧场景 | 收取“精彩集锦-大模型版”费用。 |
| 精彩集锦-高级版 | 高级版集锦算法,主要适配体育赛事类、游戏电竞类视频。 | 足球赛事 篮球赛事 游戏电竞视频 通用场景 | 收取“精彩集锦-高级版”费用。 |
| 精彩集锦-基础版 | 自2025年12月起,该模型版本下线,只为存量客户提供服务。 | | 收取“精彩集锦-基础版”费用。 |
处理直播流 | 精彩集锦-直播流处理 | 基于大模型视频理解,针对直播场景进行了针对性模型优化。 | 广电新媒体直播 在线教育直播 电商带货直播 金融直播 足球篮球赛事直播 | 收取“精彩集锦-大模型版”费用。 |
使用方式
方式一、控制台使用
发起任务
1. 选择需要发起任务的视频,并单击媒体处理。
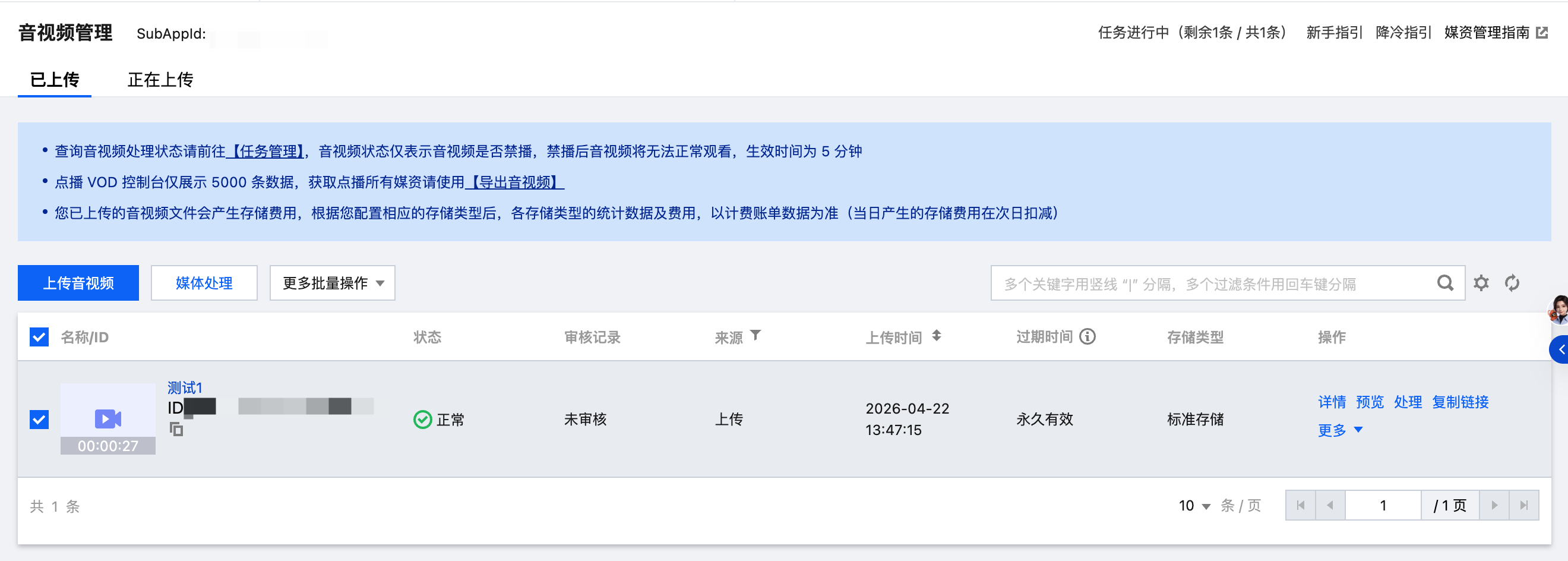
2. 处理类型选择“媒体智能”的智能分析,您可以选择26号预设模板,根据下文 扩展参数说明,传入所需参数发起任务。
说明:
控制台会自动转义,请直接传入 JSON 数据,不要传入转义后的字符串,否则会导致任务失败。
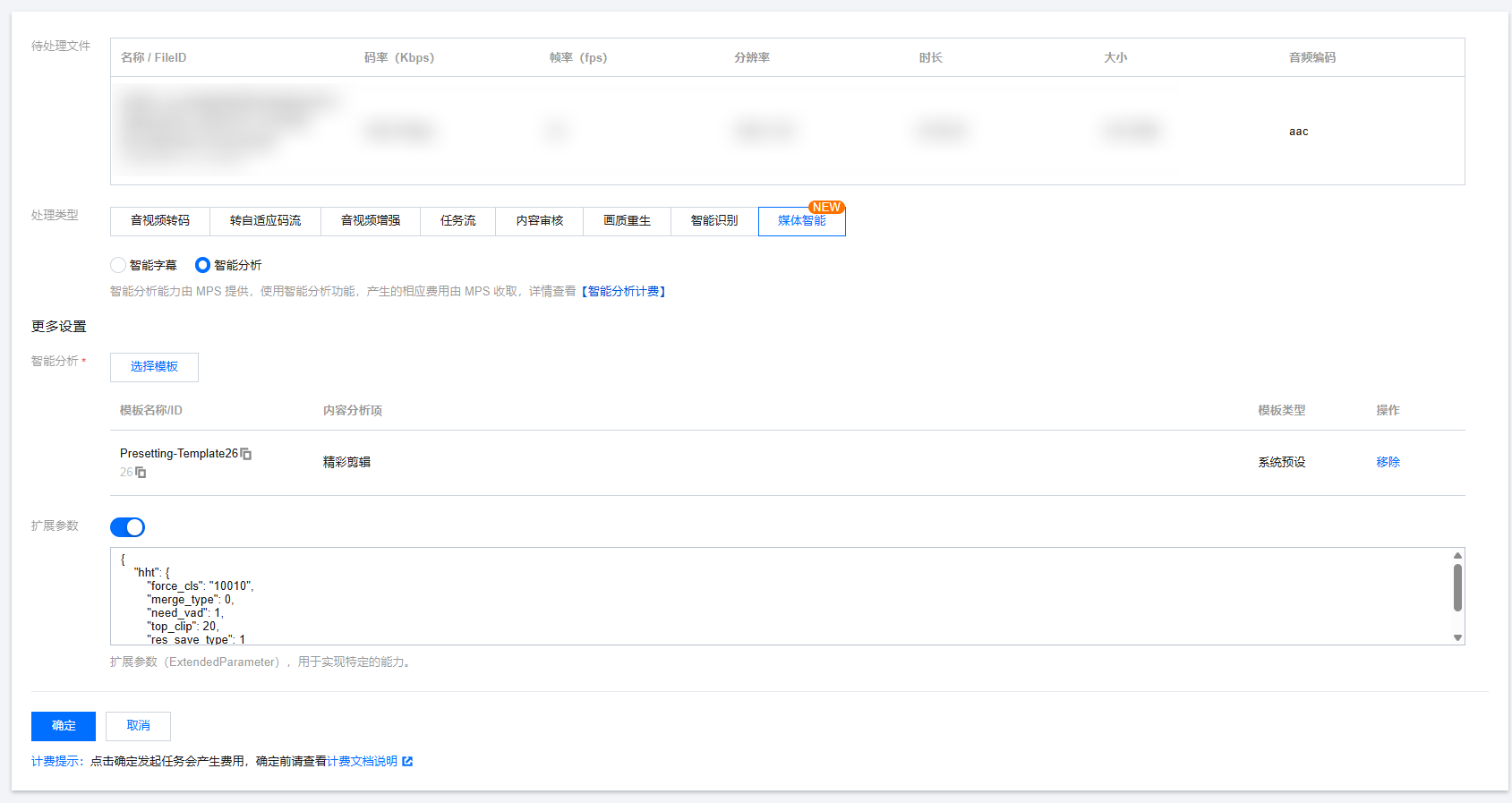
查看任务结果
在 云点播控制台 的任务中心页面,找到对应任务并单击详情查看结果。

您也可以调用 DescribeMediaInfos 接口,查询存入媒资的结果。
注意:
同一模板任务,媒资中仅保留最新的任务结果。
方式二、API 接入
发起任务
调用 ProcessMediaByMPS,FileId 处填写需要处理的媒资 ID,SubAppId 处填入子应用 ID,MPSProcessMediaParams 参数中填写 AiAnalysisTask 任务,并将 Definition 设置为 26(预置模板)。ExtendedParameter 根据需求填额外的扩展参数,通过该参数实现特定的能力。
精彩集锦任务 MPSProcessMediaParams 参数示例如下:
{"AiAnalysisTask":{"Definition": 26,"ExtendedParameter":"{\\"hht\\": {\\"force_cls\\": \\"10010\\",\\"merge_type\\": 0,\\"need_vad\\": 1,\\"top_clip\\": 20,\\"res_save_type\\": 1}}"}}
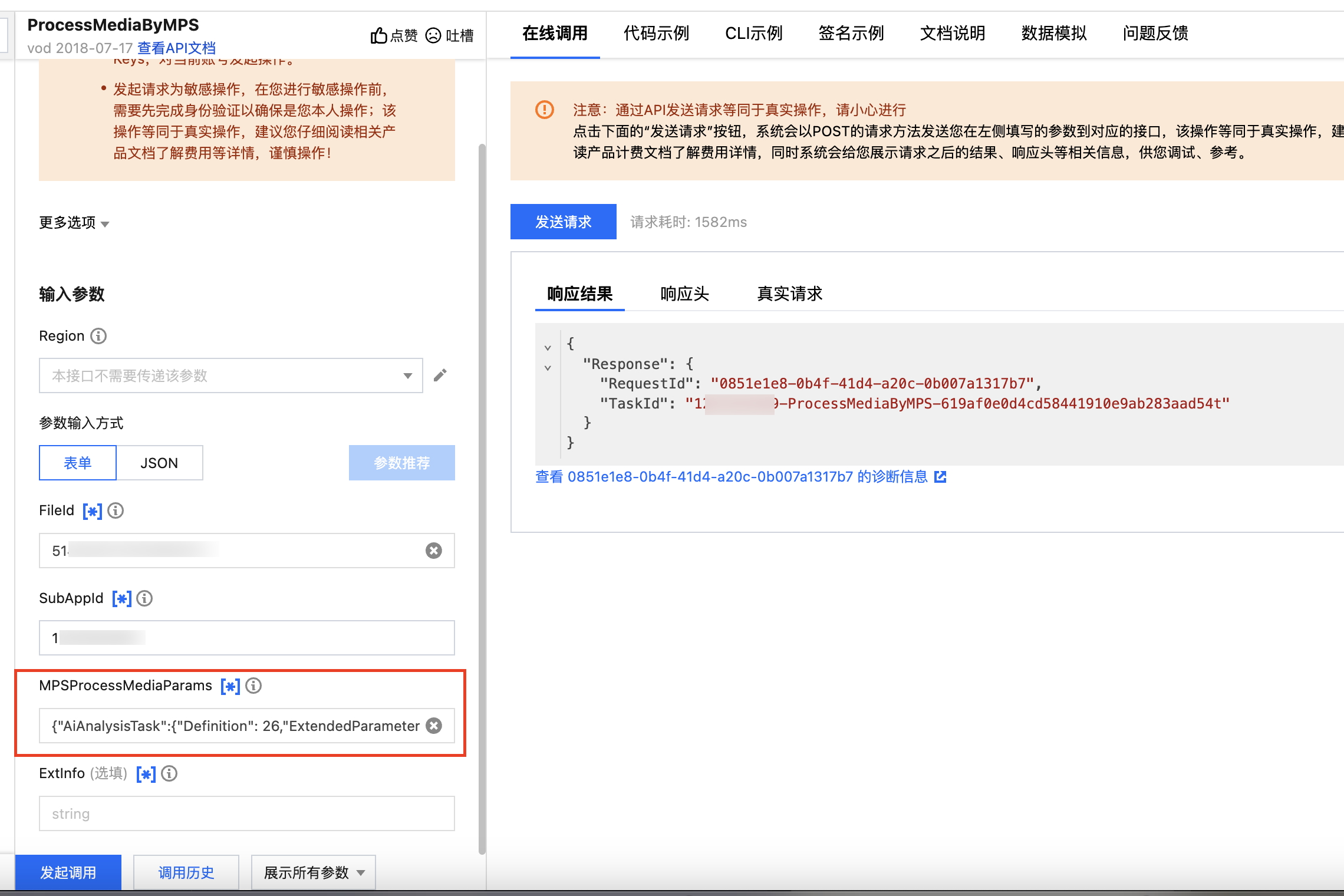
查询任务结果
可以在输出信息中找到输出文件路径。
指定离线集锦场景&扩展参数示例
目前仅支持使用预设26号模板发起精彩集锦任务,无法自定义模板调整集锦参数。指定集锦版本、指定视频场景等参数调整需求,您需要通过在发起任务时额外传入扩展参数来实现。以下是常见集锦场景及对应扩展参数示例:
说明:
示例参数可能无法达到最佳集锦效果,建议根据视频特性微调参数。如需专业支持,请 联系我们。
精彩集锦-大模型版
自定义场景
multimodal_prompt 支持输入您的自定义 Prompt 需求。扩展参数示例如下://prompt示例,可自定义调整。详细字段定义请参考下文附录{"hht":{"top_clip":5,"force_cls":10020,"prompts":{"multimodal_prompt":"滑雪场景,输出人物高光"},"scenario":"滑雪","model_segment_limit":[3,6]}}
{"hht": {"top_clip": 5,"force_cls": 10020,"prompts": {"multimodal_prompt": "滑雪场景,输出人物高光"},"scenario": "滑雪","model_segment_limit": [3, 6]}}
全景相机、VLOG 视频场景
基于大模型视频理解,并针对 VLOG 视频、运动视频、风景视频、无人机全景视频等多种场景进行了针对性调优,可以精准获取拍摄过程中的精彩瞬间并生成高质量的集锦片段。扩展参数示例如下:
//平面视频高光。详细字段定义请参考下文附录{"hht":{"top_clip":5,"force_cls":10020,"model_segment_limit":[3,6]}}//全景视频高光。详细字段定义请参考下文附录{"hht":{"top_clip":5,"force_cls":10020,"model_segment_limit":[3,6],"use_panorama_direct":1,"panorama_video":1}}
//平面视频高光{"hht": {"top_clip": 5,"force_cls": 10020,"model_segment_limit": [3, 6]}}//全景视频高光{"hht": {"top_clip": 5,"force_cls": 10020,"model_segment_limit": [3, 6],"use_panorama_direct": 1,"panorama_video": 1}}
短剧影视剧场景
基于大模型视频理解,并针对短剧影视剧视频进行了针对性调优,可以自动提取主角出场时刻、BGM 时刻等高光片段,辅助提升后期制作的效率。
{"hht":{"force_cls":"10010","merge_type":0, "need_vad":1, "top_clip":100, "res_save_type":1,"scenario":"电视剧高光"}}
{"hht": {"force_cls": "10010","merge_type": 0,"need_vad": 1,"top_clip": 100,"res_save_type": 1,"scenario": "电视剧高光"}}
精彩集锦-高级版
足球赛事场景
基于视频内容理解,自动识别并提取足球赛事视频中的关键行为事件,包括射门、进球、点球、红牌、黄牌、回放等关键行为事件。
{"hht":{"force_cls":"4001","merge_type":0, "need_vad":1, "top_clip":100, "res_save_type":1}}
{"hht": {"force_cls": "4001","merge_type": 0,"need_vad": 1,"top_clip": 100,"res_save_type": 1}}
篮球赛事场景
{"hht":{"force_cls":"4002","merge_type":0, "need_vad":1, "top_clip":100, "res_save_type":1}}
{"hht": {"force_cls": "4002","merge_type": 0,"need_vad": 1,"top_clip": 100,"res_save_type": 1}}
附:扩展参数字段说明
参数 | 是否必填 | 类型 | 说明 |
top_clip | 否 | int | 选取置信度最高的集锦片段,默认值为5。 示例:\\"top_clip\\":10,表示最多输出置信度最高的10个集锦片段。 |
force_cls | 否 | int | 指定集锦类别: 10010:短剧、电视剧场景 4001:足球 4002:篮球 1001:王者荣耀 100101:王者荣耀竞赛 1003:英雄联盟 10020: 大模型集锦,适用于自定义视频场景、vlog/风景视频场景等 |
need_vad | 否 | int | vad 用于判断视频一句话结尾,vad 扩展能够让视频语音完整,默认开启。 1:使用 vad 0:不使用 |
threshold | 否 | float | 置信度阈值,低于阈值的片段都过滤掉,每种类型的集锦都会有默认阈值设置。 备注:建议客户初次使用时不设置。 |
res_save_type | 否 | int | 是否存储结果,默认存储。 1:存储结果 0:只输出时间段 |
output_pattern | 否 | string | 输出视频命名格式,{}表示占位符。 {year}-{month}-{day}-{hour}-{minute}-{second}_{start_dts}-{end_dts}-{timestamp}-{session}.mp4 默认输出格式: hht-{year}{month}{day}{hour}{minute}-{session}-{timestamp}-index.mp4 |
image_pattern | 否 | string | image-{start_dts}.jpg 可以占位的参数同上 默认输出格式: hht-{year}{month}{day}{hour}{minute}-{session}-{timestamp}-index.jpg |
merge_type | 否 | int | 注意:仅离线场景可用,默认值:5003 为不合并,其他场景合并。 是否合并结果为一个视频: 1:合并(top_clip 参数不生效) 0:不合并(merge_time 参数不生效) |
merge_time | 否 | int | 注意:仅离线场景可用, 默认值:5003 为实际输出,其他场景最长不超过一小时。 合并成一个视频时,指定视频输出长度。 |
prompts | 否 | Object | prompts 定义列表,可以指定 prompt 来输出自己想要的结果,用法可以参考大模型示例。 |
scenario | 否 | string | 指定场景, force_cls 为10020时生效。 |
model_segment_limit | 否 | Array | 注意:这个参数是控制模型输出时长, 具体还是以模型输出为主。 输出视频长度限制, 会输入给模型作为参考,不是强制值,force_cls 为10020时生效,示例: "model_segment_limit":[3,6] // 期望大模型输出分片在3到6秒。 |
prompts 结构
参数 | 是否必填 | 类型 | 说明 |
multimodal_prompt | 否 | string | 多模态模型 prompt。 |



