功能介绍
智能拆条功能整合了大模型视频理解、语音识别、文字提取以及人物物体识别等技术,能够对长视频进行精准拆条和打点标记。系统可输出拆解后的视频片段,包括每个片段的封面图、起止时间、标题和内容摘要等信息。例如,将完整的新闻联播素材拆分为多个独立新闻事件视频,可显著提升新闻和体育类视频的拆条质量,有效促进二次创作,同时大幅降低人力和硬件成本。
前置操作

方式一、控制台使用
发起任务
1. 选择需要发起任务的视频,并单击媒体处理。
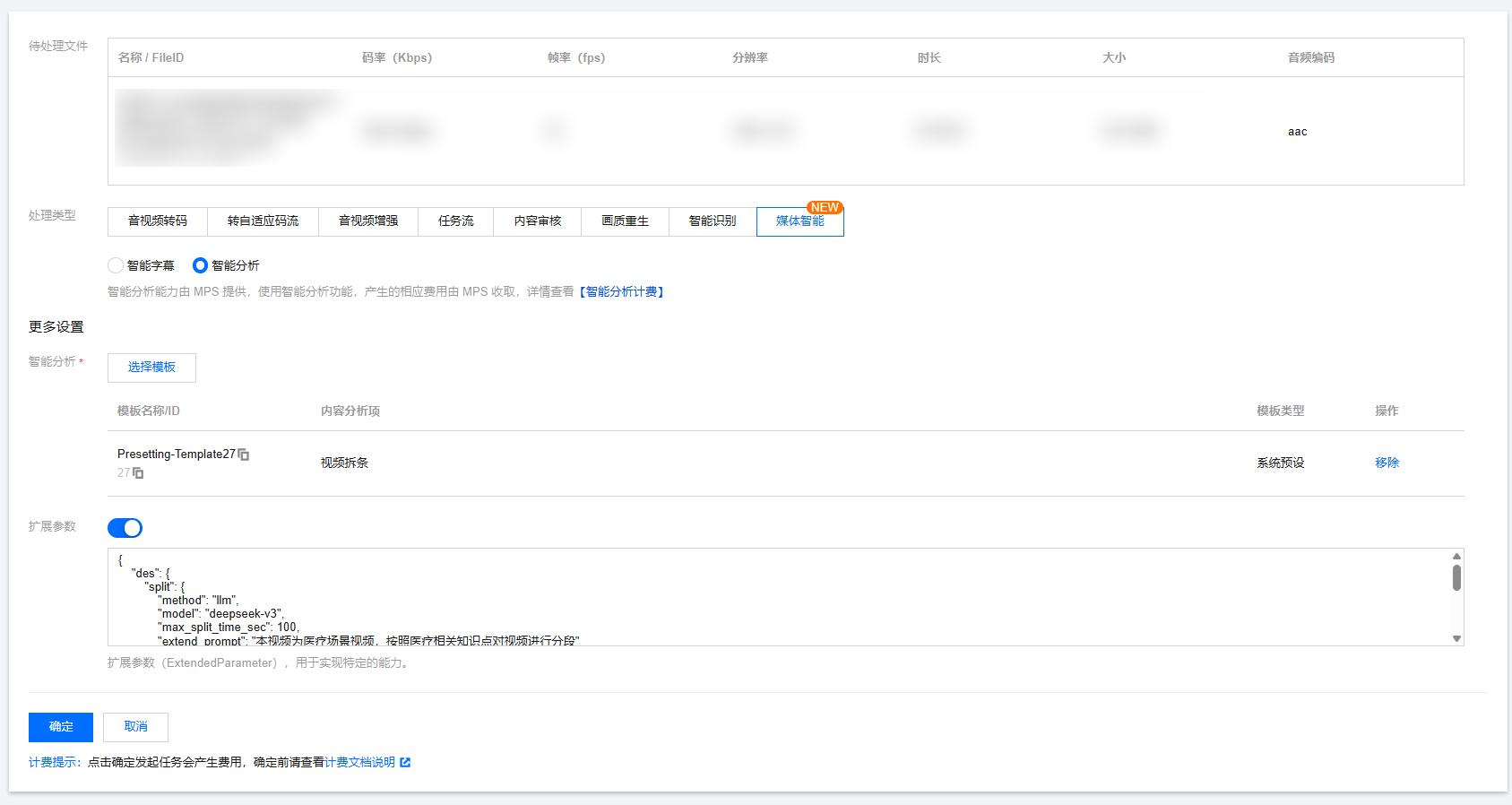
2. 处理类型选择“媒体智能”的智能分析,您可以选择27号预设模板,根据下文 扩展参数说明,传入所需参数发起任务。
说明:
控制台会自动转义,请直接传入 JSON 数据,不要传入转义后的字符串,否则会导致任务失败。
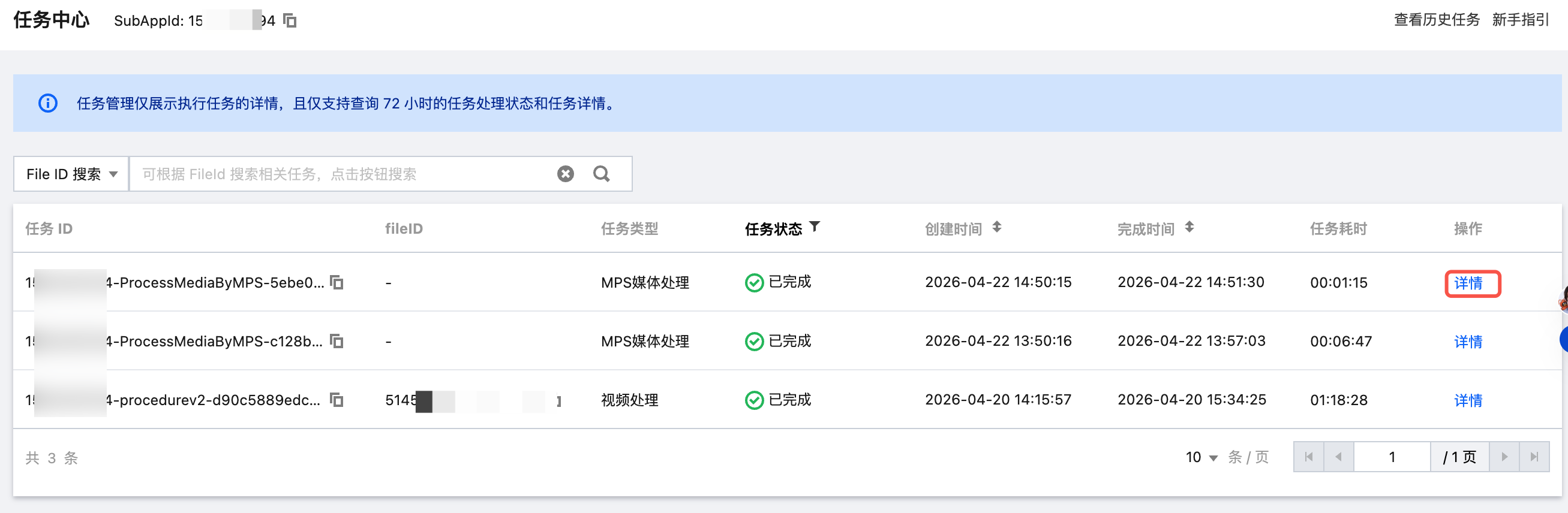
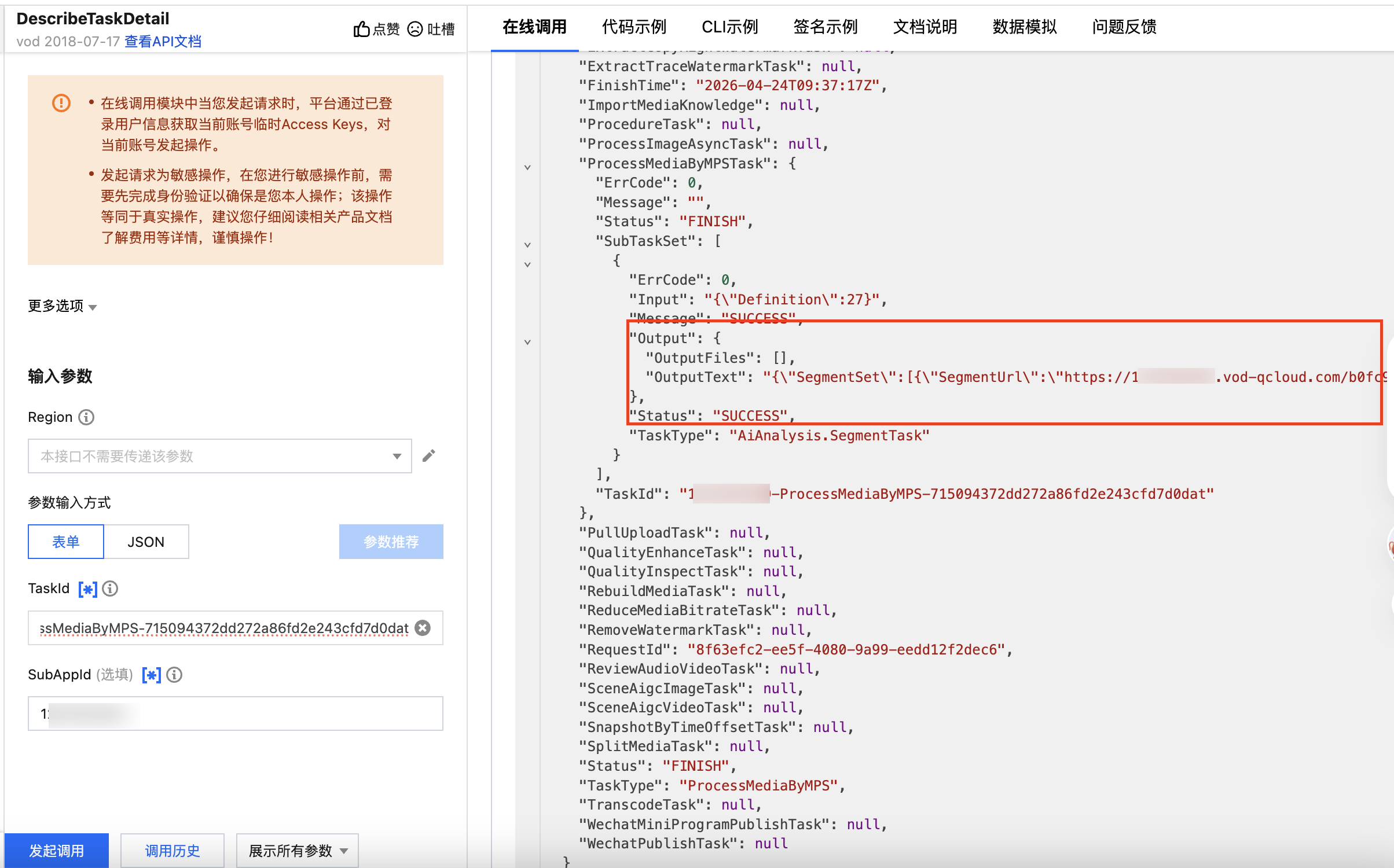
查看任务结果
在 云点播控制台 的任务中心页面,找到对应任务并单击详情查看结果。
您也可以调用 DescribeMediaInfos 接口,查询存入媒资的结果。
注意:
同一模板任务,媒资中仅保留最新的任务结果。
方式二、API 接入
发起任务
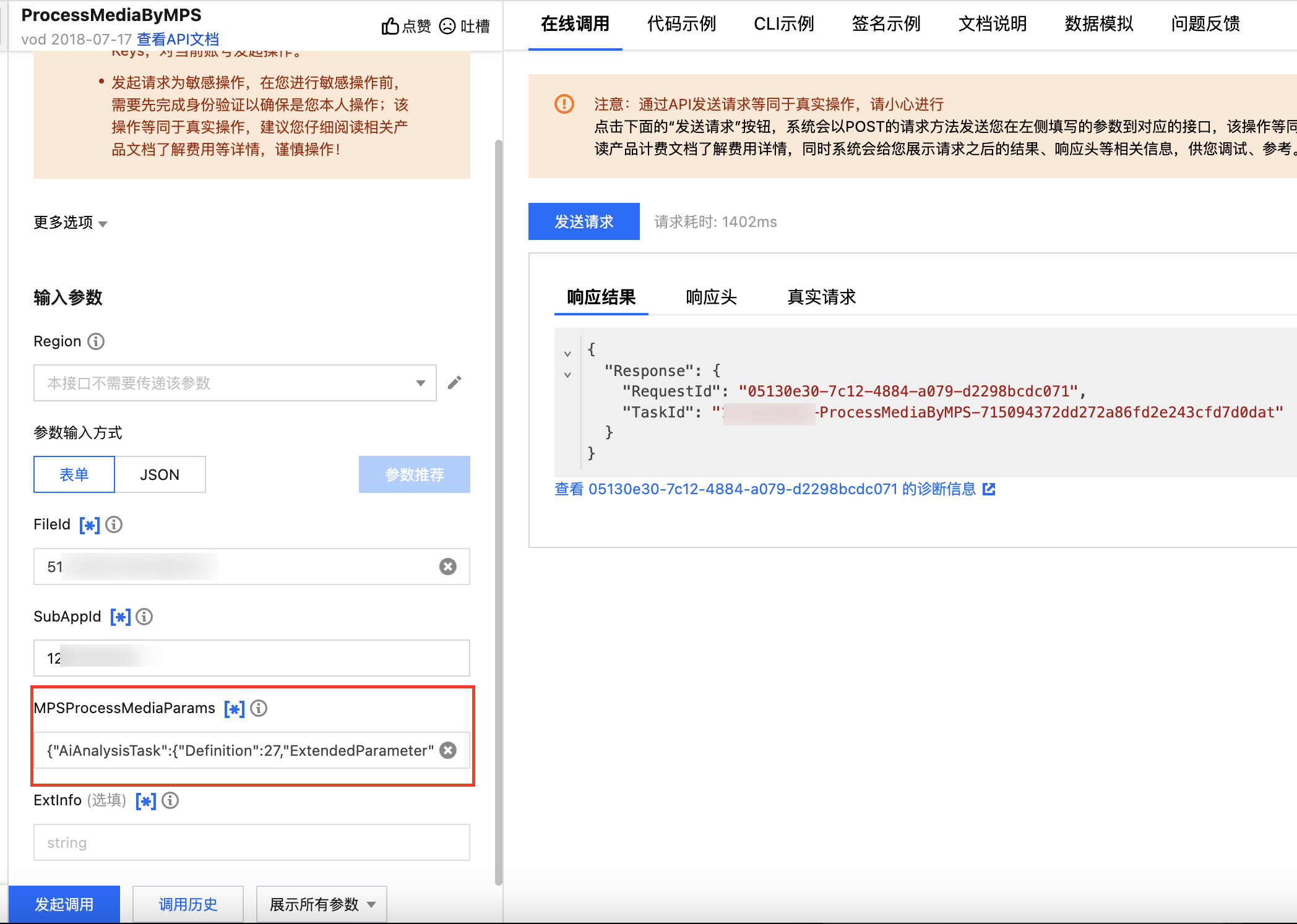
调用 ProcessMediaByMPS,FileId 处填写需要处理的媒资 ID,SubAppId 处填入子应用 ID,MPSProcessMediaParams 参数中填写 AiAnalysisTask 任务,并将 Definition 设置为 27(预置模板)。ExtendedParameter 根据需求填额外的扩展参数,通过该参数实现特定的能力。
智能拆条任务 MPSProcessMediaParams 参数示例如下:
{"AiAnalysisTask":{"Definition":27,"ExtendedParameter":"{\\"strip\\":{\\"type\\":\\"screen_strip\\"}}"}}
查询任务结果
可以在输出信息中找到输出文件路径。
扩展参数说明
传入扩展参数(ExtendedParameter)可以指定不同拆条场景,获得更好的拆条效果。
场景一:大模型拆条
功能描述
通过识别视频语音、画面文字内容后提取出文本,基于大模型对视频进行拆条。输出内容包括:拆出的视频片段、每个片段的封面图、起止时间、标题、摘要等。
参数
在 ExtendedParameter 中填入以下参数,具体参数建议线下对接确认:
{"des": {"split": {"method": "llm","model": "deepseek-v3","max_split_time_sec": 100,"extend_prompt": "本视频为医疗场景视频,按照医疗相关知识点对视频进行分段"},"need_ocr": true,"text_requirement": "摘要在40字以内","dstlang": "zh"},"strip": {"type": "content"}}
其中"des"部分可选参数参考下表:
参数 | 是否必填 | 类型 | 说明 |
split.method | 否 | string | 视频分段方法,llm 表示大模型分段,nlp 表示传统 nlp 分段,默认为 llm。 |
split.model | 否 | string | 分段大模型,可选 hunyuan,deepseek-v3,deepseek-r1,默认为 deepseek-v3。 |
split.max_split_time_sec | 否 | int | 强制指定最大分段时间,单位秒。建议必要情况下再使用,可能影响分段效果。默认3600。 |
split.extend_prompt | 否 | string | 补充大模型分段任务提示词,如“本视频为教学视频,按照相关知识点对视频进行分段”。建议先不填进行测试,效果不达预期时再补充。 |
need_ocr | 否 | bool | 是否使用 ocr 辅助分段,true 表示开启,默认为 false。 不开启,系统仅识别视频语音内容辅助视频分段;开启,还会识别视频画面上的文字内容辅助视频分段。 |
text_requirement | 否 | string | 补充大模型摘要任务提示词。例如限制字数"摘要在40字以内"。 |
dstlang | 否 | string | 视频语言,用于视频语音识别与摘要相关结果语言指定,默认为"zh"。 "zh":中文 "en":英文 |
场景二:镜头拆条
根据画面镜头/场景的变化进行拆条。输出内容包括:拆出的视频片段、每个片段的封面图、起止时间。
参数
在 ExtendedParameter 中填入以下参数:
{"strip":{"type":"screen_strip"}}
场景三:新闻拆条
对新闻视频中的导播台,以及“快讯”等特征进行定位识别, 从而达到新闻拆条的效果。输出内容包括:拆出的视频片段、每个片段的封面图、起止时间。
参数
在 ExtendedParameter 中填入以下参数:
{"strip":{"type":"news"}}
场景四:目标拆条
支持指定物体、人物等目标,识别视频中该目标出现的关键帧,将相应片段拆出来。例如,针对监控视频,只拆分出有人出现的画面片段。输出内容包括:拆出的视频片段、每个片段的封面图、起止时间。
参数
在 ExtendedParameter 中填入以下参数, 具体需要检测的物体目标建议线下对接确认:
{"strip":{"type":"object","objects":["人"], "object_set":[91020415]}}



