实践背景
随着云原生与微服务架构的普及,应用系统的复杂度呈指数级增长。一个用户请求可能跨越 CDN、负载均衡、多组微服务、数据库等十余层组件,故障根因可能藏在网络链路的任一节点,也可能源于服务内部的代码逻辑。在传统监控模式中,云拨测(CAT)作为主动监控手段,通过全球分布式节点模拟用户请求,可提前发现可用性异常与网络性能瓶颈,但缺乏对请求后端流转过程的洞察;应用性能监控(APM)的链路追踪则聚焦请求在系统内部的调用轨迹,能精准定位服务间的性能瓶颈,却依赖真实流量触发,无法实现 “未雨绸缪” 的前瞻性监控。
当云拨测与链路追踪深度集成后,形成了 “主动探测 + 全链溯源” 的一体化可观测能力:既保留了拨测 “主动发现、全域覆盖” 的优势,又获得了链路追踪 “深度下钻、根因定位” 的能力,彻底打破了 “网络层监测” 与 “应用层分析” 的数据孤岛。
方案优势
云拨测与链路追踪的集成并非简单的数据叠加,而是通过能力互补实现 “1+1>2” 的效果,其核心优势体现在以下四个维度:
全链路可视化:从 “用户视角” 到 “系统内核” 的穿透
传统拨测仅能提供 DNS 解析、TCP 握手、页面加载等网络层指标,无法解释 “某地域响应延迟突增的原因”,链路追踪虽能展示服务调用链,却难以关联 “用户实际访问路径的网络特性”。
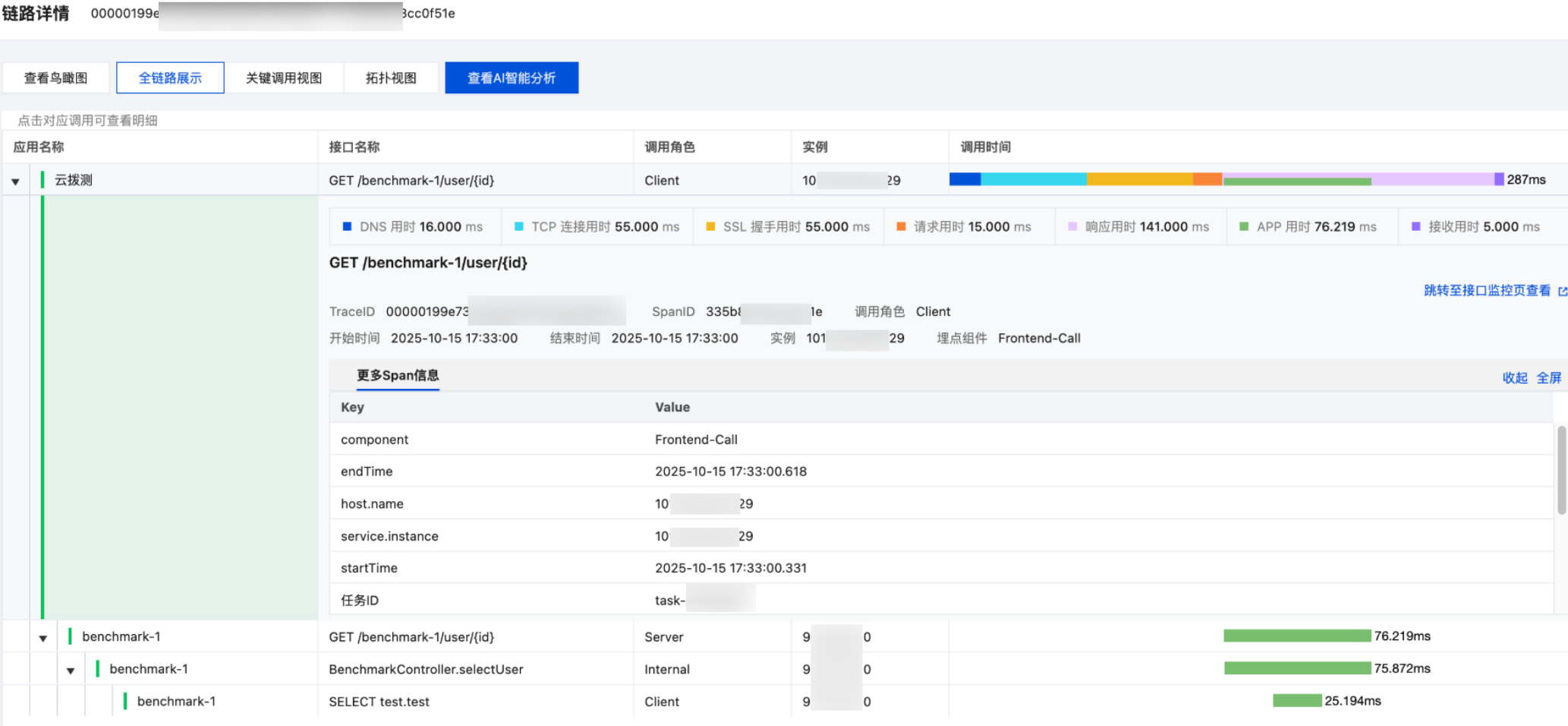
集成链路追踪后,一次拨测请求将携带唯一 TraceId 贯穿全程:从全球任一探测节点发起的模拟请求,其网络层耗时与应用层调用轨迹可在同一视图中呈现。例如与链路追踪集成后,用户可通过 “拨测任务详情→查看调用链路” 直接跳转至全链分析界面,清晰看到网络请求到后端链路的各个阶段的耗时构成。这种穿透性可视化,让运维人员既能知道 “用户感受到慢”,又能明确 “慢在系统的哪一层”。
故障定位效率:从 “经验排查” 到 “精准溯源” 的跃迁
故障排查的核心痛点在于 “定位范围模糊”。拨测发现某地域接口成功率从99.9%降至80%时,传统模式需依次排查网络链路、CDN 节点、服务实例、数据库等十余项组件,MTTR(平均修复时间)常以小时计。
集成方案通过 “拨测异常触发链路溯源” 实现分钟级根因定位:拨测节点检测到异常后,自动通过 TraceId 关联该请求的全链路数据,快速锁定故障环节。例如腾讯云拨测在检测到域名劫持时,可通过集成的链路数据瞬间区分 “DNS 解析层篡改”(返回127.0.0.1无效 IP)与 “传输层拦截”(TCP 握手 RST 包异常),将 MTTR 从小时级压缩至分钟级。
主动被动协同:从 “事后响应” 到 “事前防控” 的转变
链路追踪依赖真实用户流量,对于低访问量的核心接口(如财务对账接口)或预发布环境,往往因缺乏流量覆盖而形成监控盲区;云拨测则可通过定时探测主动填补这些空白,二者协同实现 “全域无死角” 监控。
体验与技术关联:从 “指标割裂” 到 “价值对齐” 的统一
企业常面临 “指标矛盾”:拨测显示 “首屏加载 2s(优)”,但真实用户投诉 “页面卡顿”;链路追踪显示 “服务 RT 50ms(优)”,但某运营商用户访问成功率仅 70%。根本原因在于 “用户体验指标” 与 “技术性能指标” 的割裂。
集成方案通过 TraceId 建立二者的关联桥梁:将拨测采集的 “地域 - 运营商 - 终端” 维度用户体验数据(如4G/5G 网络下的首屏耗时),与链路追踪的 “服务 - 接口 - 数据库” 技术指标(如该请求对应的订单服务调用耗时)绑定。
操作步骤
1. 在 云拨测 > 任务列表 页面,单击新建任务。
说明:
当前仅支持在 HTTP(s)协议类型中开启链路追踪功能。
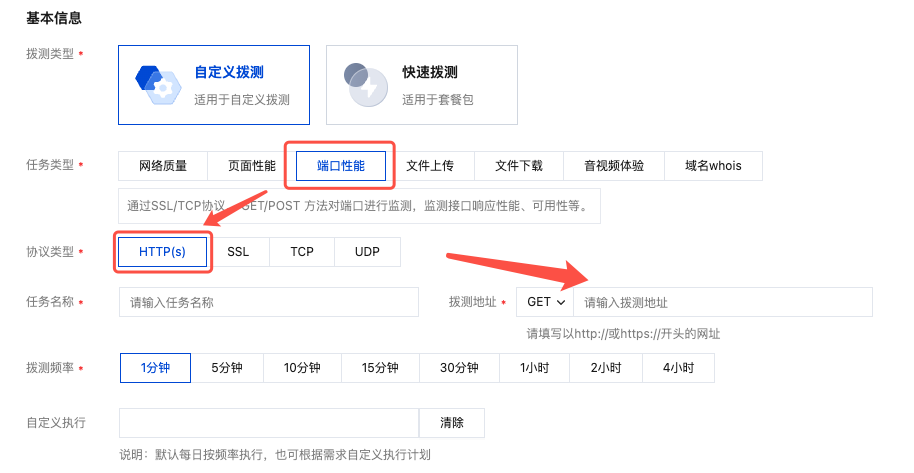
3. 在拨测参数配置模块中,启用链路追踪功能,指定协议类型 OpenTelemetry 或 SkyWalking,关联已接入的应用性能监控(APM)实例,请参见 APM 接入指引。
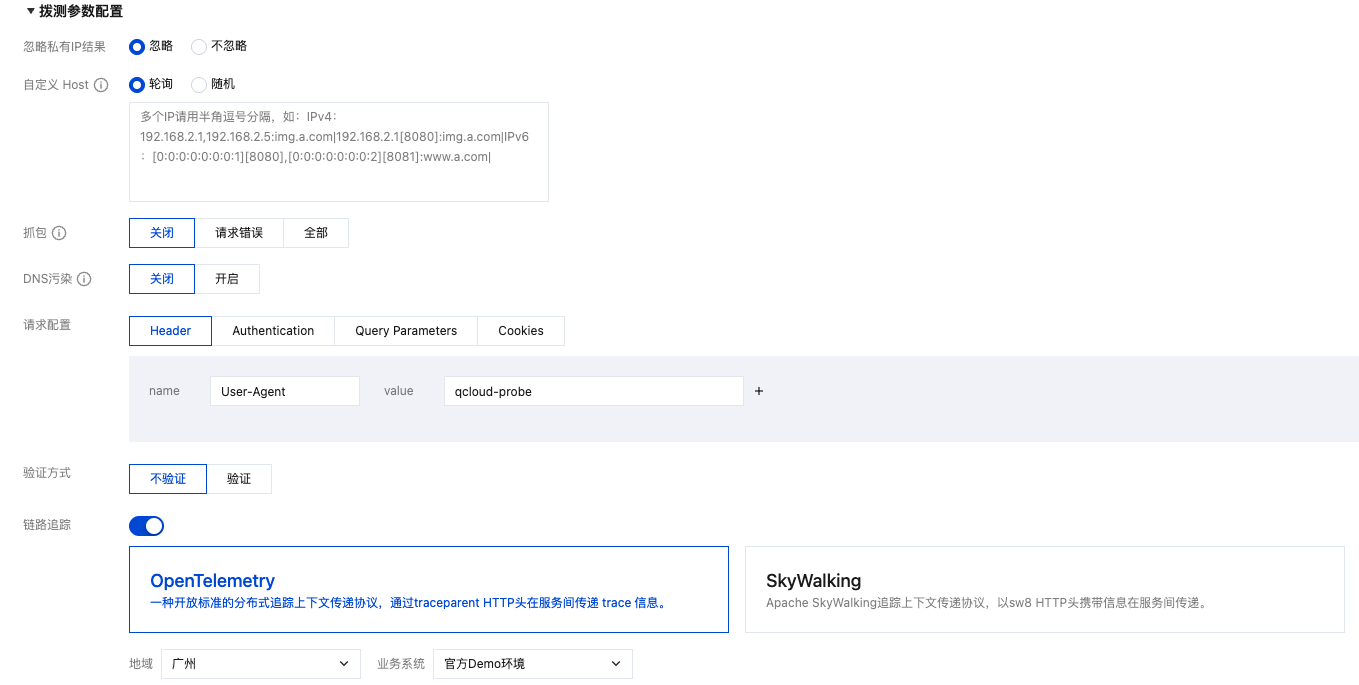
4. 配置完成后,单击创建任务即可完成链路观测体系搭建。
5. 链路观测体系数据查看。在 多维分析 页面详情数据列表,单击一次具体拨测以查看其详情,然后在该详情页中单击查看链路追踪。
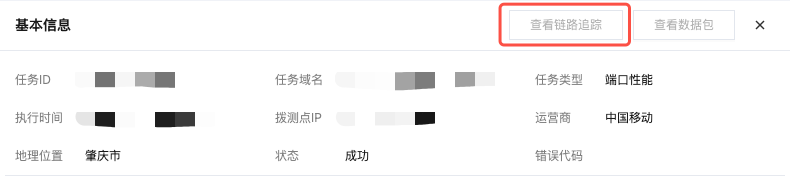
6. 单击查看链路追踪后,会跳转到应用性能监控(APM)的链路详情模块,即可查看完整链路观测数据。