概述
在 Kubernetes 上运行批处理作业时,常面临资源争抢和异构资源管理粗放的痛点。Kueue 作为一个工作负载排队管理器,在 Kubernetes 中负责管理 Job 等批处理任务的排队、准入和资源分配,确保集群资源公平、高效的被利用。它的核心工作原理是:当用户提交作业后,Kueue 会暂存(Suspend)该作业,而非立即创建 Pod。随后,Kueue 会根据预设的配额和调度策略,检查集群中的资源情况。一旦有足够的资源,Kueue 便会恢复(Resume)作业,使其得以正常执行。
工作原理
通过下面这个流程图,可以直观地理解 Kueue 中几个核心资源对象如何协同工作,以管理 Kubernetes 集群中的作业队列和资源分配。整个流程清晰地展示了一个作业从提交到执行的完整生命周期,以及各个对象在其中扮演的角色。
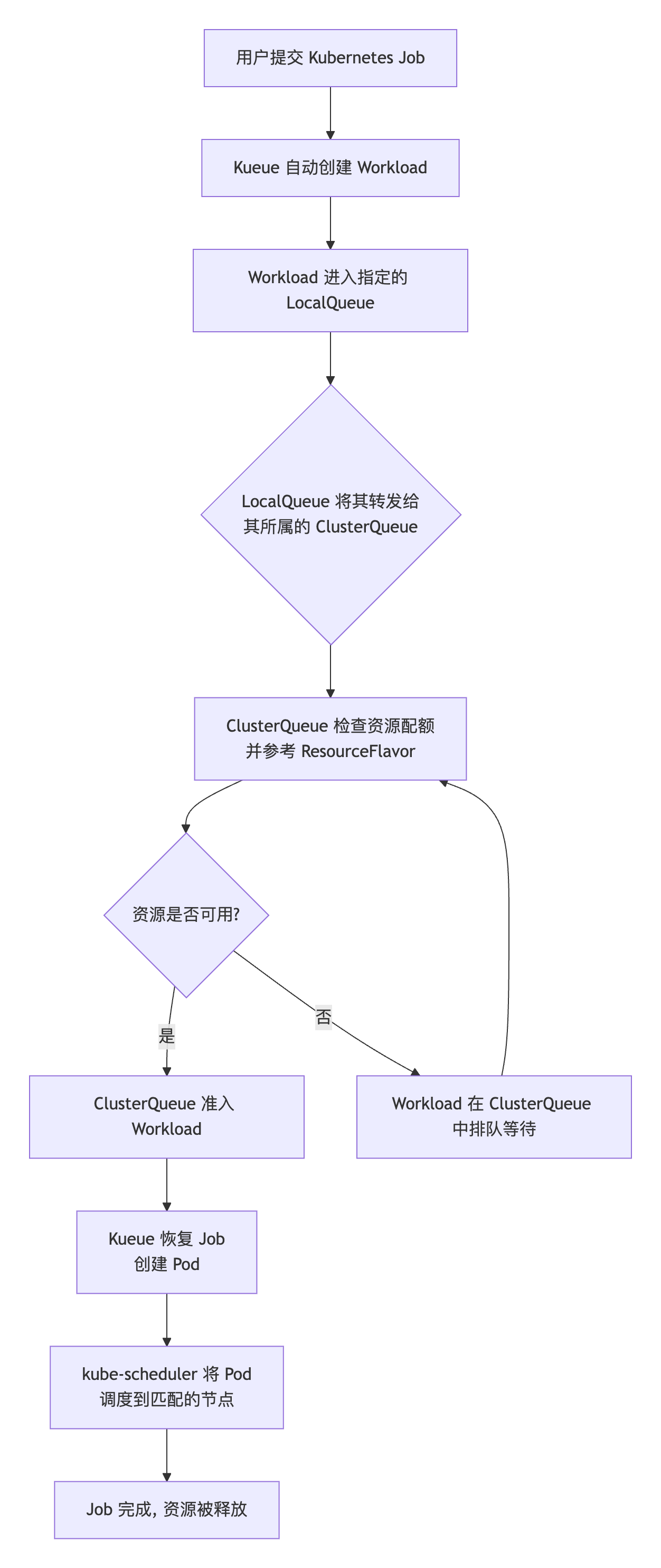
核心资源解析
1. ResourceFlavor
作用:定义“资源风味”,描述了集群中节点所能提供的资源类型和属性(如“高 CPU 型”、“带 GPU 型”、“抢占式实例”)。它通过标签选择器匹配具有特定属性的节点,是资源分配的基础。
角色定位:相当于资源的“菜单”,描述了集群里有什么“口味”的资源可供分配。ClusterQueue 的配额正是基于 ResourceFlavor 来定义的。
2. ClusterQueue
作用:这是一个集群级别的资源池。它聚合了一种或多种 ResourceFlavor 所描述的资源,并设置总体的资源配额、排队策略、公平共享及抢占规则。它是 Kueue 进行全局资源仲裁和决策的核心。
角色定位:相当于一个部门的“总预算”,规定了整个资源池的容量和分配规则。
3. LocalQueue
作用:这是一个命名空间级别的资源,作为用户提交工作的入口。每个 LocalQueue 都必须归属于一个特定的 ClusterQueue。它的主要功能是将来自其命名空间的作业请求转发到对应的 ClusterQueue中。
角色定位:相当于部门内各个“项目组的预算申请入口”。它实现了多租户隔离(不同团队有自己的队列)和资源共享(所有队列消耗同一个 ClusterQueue的预算)的统一。
4. Job 和 Workload
Job:这是用户直接提交的 Kubernetes 工作负载,例如 Kubernetes Job。
Workload:当 Kueue 发现一个 Job 带有特定的队列标签(如 kueue.x-k8s.io/queue-name: sample-queue)时,它会自动为这个 Job 创建一个对应的 Workload 对象 。这个 Workload 对象代表了在 Kueue 视野中进行排队、等待准入的工作单元。你可以通过查看 Workload 的状态来了解作业的排队情况。
安装 Kueue
前提条件
已创建了 TKE 集群(集群版本 >= 1.29),并且对集群有操作权限。
执行安装
1. 登录 容器服务控制台,进入运维中心 > 应用市场。
2. 在应用市场中,应用场景选择调度。
3. 选择 kueue 进行创建,创建详情请参见 应用市场创建应用。如下图所示:
检查安装结果
1. 在应用管理中,查看应用状态是否为“正常”。如下图所示:
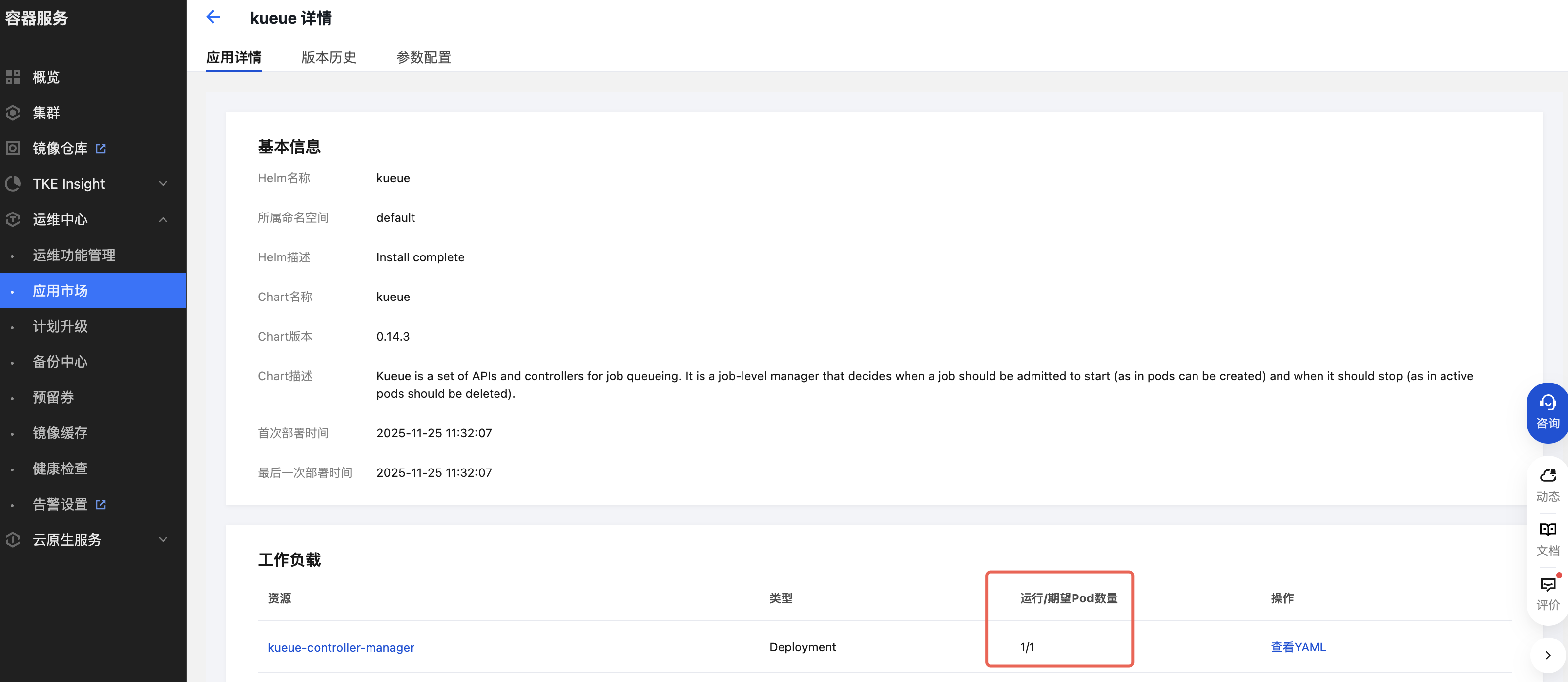
2. 单击应用名,进入应用详情页。如下图所示:
3. 查看工作负载状态是否为“正常”。如下图所示:
实践场景
场景一:批调度(All or Nothing)
1. 场景描述
在 AI 模型训练、大数据分析等分布式计算场景中,一个作业(Job)通常包含多个需要协同工作的 Pod 任务。这些任务是一个整体,所有 Pod 必须同时获得资源才能开始有效计算。如果只有部分 Pod 被调度成功(即“部分调度”),会导致以下问题:
已调度的 Pod 空占资源却无法进行有效工作。
作业整体无法完成,造成集群资源的浪费。
需要手动干预来清理停滞的作业。
Kueue 确保了作业的 “All or Nothing” 调度:要么作业要求的所有 Pod 都被成功调度并开始运行,要么 Kueue 会阻止作业启动,或在一段时间后自动清理已创建但未能完全就绪的 Pod(需要进行 waitForPodsReady 配置),从而保障了集群资源的有效利用和作业的原子性。下面的序列图清晰地展示了一个需要4个Pod 的 Job,从提交到最终实现 “All or Nothing” 调度的完整工作流程,特别是 waitForPodsReady 机制如何发挥作用:

2. 核心配置:启用 waitForPodsReady
这是实现 “All-or-Nothing” 语义的核心配置。它确保 Kueue 在放行一个 Job 后,会持续监控其 Pod 的创建和就绪状态。
检查与配置方法
1. 检查当前配置
查看 Kueue 配置,看是否有配置 waitForPodsReady,且没有被注释掉:
kubectl get cm -n kueue-system kueue-manager-config -o yaml | grep waitForPodsReady
2. 启用配置(如果尚未启用)
编辑 Kueue 的配置,在 data["controller_manager_config.yaml"] 下添加或修改以下配置:
apiVersion: controller-runtime.sigs.k8s.io/v1alpha1kind: ControllerManagerConfiguration...waitForPodsReady:enable: true # 开启All-or-Nothing调度功能timeout: 2m # 等待Pod就绪的超时时间(例如2分钟)blockAdmission: true # 防止多个作业互相阻塞导致死锁
enable: true,启用该配置。这是前提。
timeout: 2m,关键设置。定义了 Kueue 放行 Job 后,等待其所有 Pod 变为 Ready 状态的最大时长。如果超时,Kueue 会将该 Job 重新挂起(suspend: true),并删除已创建的所有 Pod,释放被占用的资源。
blockAdmission: true,防止多个作业互相阻塞导致死锁,死锁场景可通过 此处 了解。
3. Kubernetes 对象创建
3.1 创建 ResourceFlavor
ResourceFlavor 是 Kueue 中定义的自定义资源,它定义了集群中可用的资源类型(如 CPU、GPU 机型)。
apiVersion: kueue.x-k8s.io/v1beta1kind: ResourceFlavormetadata:name: "default-flavor"
3.2 创建 ClusterQueue
ClusterQueue 是 Kueue 中定义的自定义资源,它定义了一个集群级别的资源池。通过 nominalQuota 来管理资源配额,是资源分配的核心。
apiVersion: kueue.x-k8s.io/v1beta1kind: ClusterQueuemetadata:name: cluster-queuespec:namespaceSelector: {} # 允许所有命名空间使用resourceGroups:- coveredResources: ["cpu"]flavors:- name: "default-flavor"resources:- name: "cpu"nominalQuota: 2 # 基础配额:2 核 CPU
3.3 创建 LocalQueue
LocalQueue 是 Kueue 中定义的自定义资源,作为在特定命名空间内用户提交工作的入口。它本身不持有配额,而是将工作负载转发到其绑定的 ClusterQueue 进行资源分配。
apiVersion: kueue.x-k8s.io/v1beta1kind: LocalQueuemetadata:namespace: defaultname: user-queuespec:clusterQueue: cluster-queue
3.4 提交作业
这是一个 Job 示例,它要求同时启动4个 Pod。通过在 Job 的标签中指定 kueue.x-k8s.io/queue-name,将其关联到特定的 LocalQueue,从而进入 Kueue 的调度队列。
apiVersion: batch/v1kind: Jobmetadata:name: all-or-nothing-jobnamespace: defaultlabels:kueue.x-k8s.io/queue-name: user-queuespec:parallelism: 4completions: 4suspend: truetemplate:spec:containers:- name: testimage: alpine:latestcommand: [ "/bin/sh" ]args: [ "-c", "sleep 36000000" ]resources:requests:cpu: 1restartPolicy: Never
该示例中,只有当指定的 LocalQueue 绑定的 ClusterQueue 中定义的配额能同时满足4个 Pod 的资源需求时,该 Job 才会被真正执行。
kueue.x-k8s.io/queue-name: user-queue:会使用该队列所属 ClusterQueue 中管理的配额进行资源判断。
parallelism 等于 completions 代表 “All or Nothing” 语义。
3.5 验证效果
查看作业状态:
kubectl get jobs all-or-nothing-job
当集群资源不够时,状态如下:
NAME STATUS COMPLETIONS DURATION AGEall-or-nothing-job Suspended 0/4 37s
查看 Workload 状态(Workload 为 Kueue 创建的调度单元):
kubectl get workloads
状态如下:
NAME QUEUE RESERVED IN ADMITTED FINISHED AGEjob-all-or-nothing-job-48f8a user-queue 62s
查看 ClusterQueue 状态:
kubectl get clusterqueue cluster-queue
状态如下:
NAME COHORT PENDING WORKLOADScluster-queue 1
场景二:资源异构场景下优化资源调度
1. 场景描述
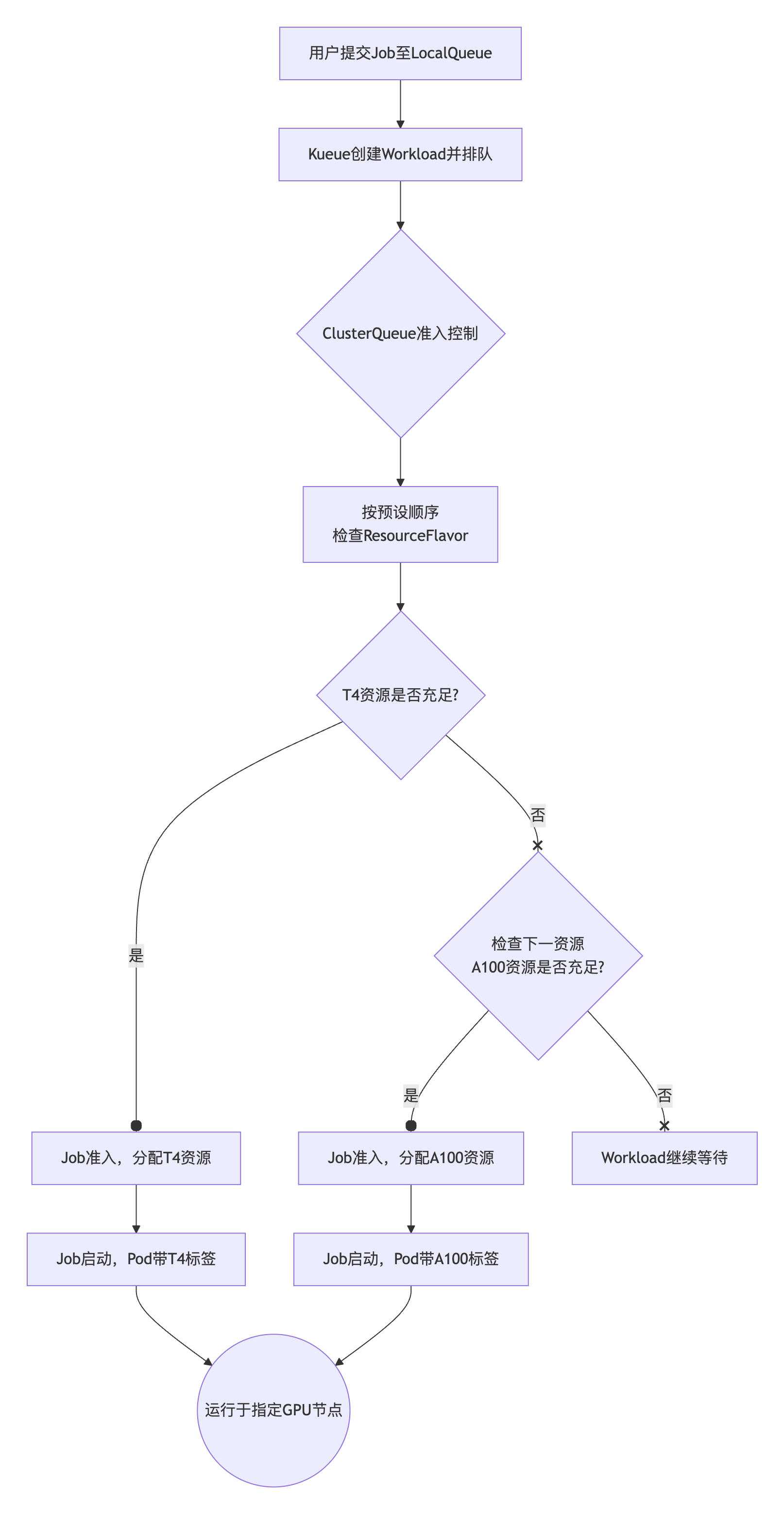
当集群中存在多种专用硬件(如两种不同的 nvidia.com/gpu 资源,即 T4 和 A100 GPU)时,会有一个限制:系统可能无法区分它们,Pod 可能会被调度到任意一种硬件上。通过 Kueue 的 ResourceFlavor 和 ClusterQueue 机制,可以实现:优先使用 T4 GPU,在 T4 GPU 资源不足时,自动降级使用 A100,其工作流程如下:
2. 创建 ResourceFlavor
首先,定义两种 GPU 资源对应的 ResourceFlavor,它们通过 nodeSelector 匹配到对应标签的节点上。
apiVersion: kueue.x-k8s.io/v1beta1kind: ResourceFlavormetadata:name: gpu-t4nodeSelector:gpu-type: nvidia-t4 # 匹配拥有此标签的T4节点---apiVersion: kueue.x-k8s.io/v1beta1kind: ResourceFlavormetadata:name: gpu-a100nodeSelector:gpu-type: nvidia-a100 # 匹配拥有此标签的A100节点
3. 配置 ClusterQueue
这是实现优先级策略的核心。flavors 列表的顺序直接决定了优先级,Kueue 将严格按照从前到后的顺序尝试分配资源。
apiVersion: kueue.x-k8s.io/v1beta1kind: ClusterQueuemetadata:name: clusterqueue-gpu-sharedspec:namespaceSelector: {} # 匹配所有命名空间resourceGroups:- coveredResources: ["nvidia.com/gpu"] # 管理的资源类型flavors:# 注意:flavors数组的顺序定义了优先级!# Kueue将首先尝试将Pod调度到gpu-t4,仅在配额不足或不匹配时,才尝试gpu-a100- name: gpu-t4resources:- name: "nvidia.com/gpu"nominalQuota: 8 # T4 GPU的总配额- name: gpu-a100resources:- name: "nvidia.com/gpu"nominalQuota: 4 # A100 GPU的总配额
4. 创建 LocalQueue
LocalQueue 作为用户提交工作的入口,指向我们上面创建的 ClusterQueue。
apiVersion: kueue.x-k8s.io/v1beta1kind: LocalQueuemetadata:namespace: defaultname: gpu-workloadsspec:clusterQueue: clusterqueue-gpu-shared # 指向共享的集群队列
5. 提交 GPU 作业
apiVersion: batch/v1kind: Jobmetadata:namespace: defaultname: gpu-inference-joblabels:kueue.x-k8s.io/queue-name: gpu-workloads # 关键:指定队列spec:parallelism: 1completions: 1template:spec:containers:- name: inference-containerimage: nvidia/cuda:12.0-runtime-ubuntu20.04command: ["python", "model-inference.py"]resources:requests:nvidia.com/gpu: 1 # 请求1个GPU,不指定类型limits:nvidia.com/gpu: 1restartPolicy: Never
6. 运行效果与优势
1. 可以细粒度地管理 GPU 资源的调度和使用。
2. 当一个 Job 被调度时,Kueue 会优先检查 clusterqueue-gpu-shared 中 gpu-t4 的配额。只要配额足够,Job 就会被调度到 T4 节点上,如果 T4 的配额已用尽,但 gpu-a100 尚有配额,新提交的 Job 将会被 Kueue 准入并调度到 A100 节点上。
3. 管理员只需要维护一个 ClusterQueue,通过调整 flavors 的顺序和配额即可轻松改变资源分配策略,无需用户修改应用配置。



