本场景介绍使用 DTS 创建腾讯云数据库 TDSQL MySQL 的数据订阅任务操作指导。
前提条件
已准备好待订阅的腾讯云数据库,并且数据库版本符合要求,请参见 数据订阅支持的数据库。
已在源端实例中开启 binlog。
已在源端实例中创建订阅账号,需要账号权限如下:REPLICATION CLIENT、REPLICATION SLAVE、PROCESS 和全部对象的 SELECT 权限。
具体授权语句如下:
create user '迁移账号' IDENTIFIED BY '账号密码';grant SELECT, REPLICATION CLIENT,REPLICATION SLAVE,PROCESS on *.* to '迁移账号'@'%';flush privileges;
约束限制
1. 订阅的消息保存在 DTS 内置 Kafka(单 Topic)中,目前默认保存时间为最近1天,单 Topic 的最大存储为500G,当数据存储时间超过1天,或者数据量超过500G时,内置 Kafka 都会开始清除最先写入的数据。所以请用户及时消费,避免数据在消费完之前就被清除。
2. 数据消费的地域需要与订阅任务所属的地域相同。
3. 当前不支持 geometry 相关的数据类型。
4. 数据订阅源是 TDSQL MySQL 版时,不支持直接执行授权语句授权,所以订阅账号的权限需要在 TDSQL 控制台 单击实例 ID,进入账号管理页中添加。
订阅账号所需要的权限即上述授权语句中所示权限,对于为订阅账号进行
__tencentdb__ 的授权操作,在控制台修改权限弹窗中选择对象级特权,勾选所有权限即可。5. 数据订阅源是 TDSQL MySQL 版时,不支持订阅 二级分区 表。
5.1 如果在订阅任务启动前源库创建了二级分区表,则校验任务不通过。
5.2 如果在订阅任务运行中源库创建了二级分区表,那么订阅到二级分区表的数据是子表数据(订阅对象选择整库或者整实例,源库在订阅任务启动后创建的二级分区表也会被订阅,导致最终的结果订阅了二级分区表)。因为二级分区表的底层是通过子表实现,所以不建议用户在订阅任务过程中创建二级分区表,否则会导致如下示例的订阅数据差异。
示例:源库表名为“test_a”是二级分区表,那么 DTS 订阅到该表的 DML 的表名为“test_a_tdsql_subp0/test_a_tdsql_subp1”。
6. 订阅任务过程中,如果进行修改订阅对象等操作会发生任务重启,重启后可能会导致用户在 kafka 客户端消费数据时出现重复。
6.1 DTS 是按最小数据单元进行传输的,增量数据每标记一个 checkpoint 位点就是一个数据单元,如果重启时,刚好一个数据单元传输已完成,则不会导致数据重复;如果重启时,一个数据单元还正在传输中,那么再次启动后需要重新拉取这个数据单元,以保证数据完整性,这样就会导致数据重复。
6.2 用户如果对重复数据比较关注,请自行在消费数据时设置去重逻辑。
7. 源端 TDSQL MySQL 中对表的数量有限制,整个实例最多为5000个,超出后 DTS 任务会报错;同时,表的数量太多会导致源端的访问耗时变大,引起性能抖动和下降。
注意事项
数据订阅源是 TDSQL MySQL 版的订阅任务,各个分片的 DDL 操作都会被订阅并投递到 Kafka,所以对于一个分表的 DDL 操作,会出现重复的 DDL 语句。例如,实例 A 有3个分片,订阅了一个分表 tableA,那么对于表 tableA 的 DDL 语句会订阅到3条。
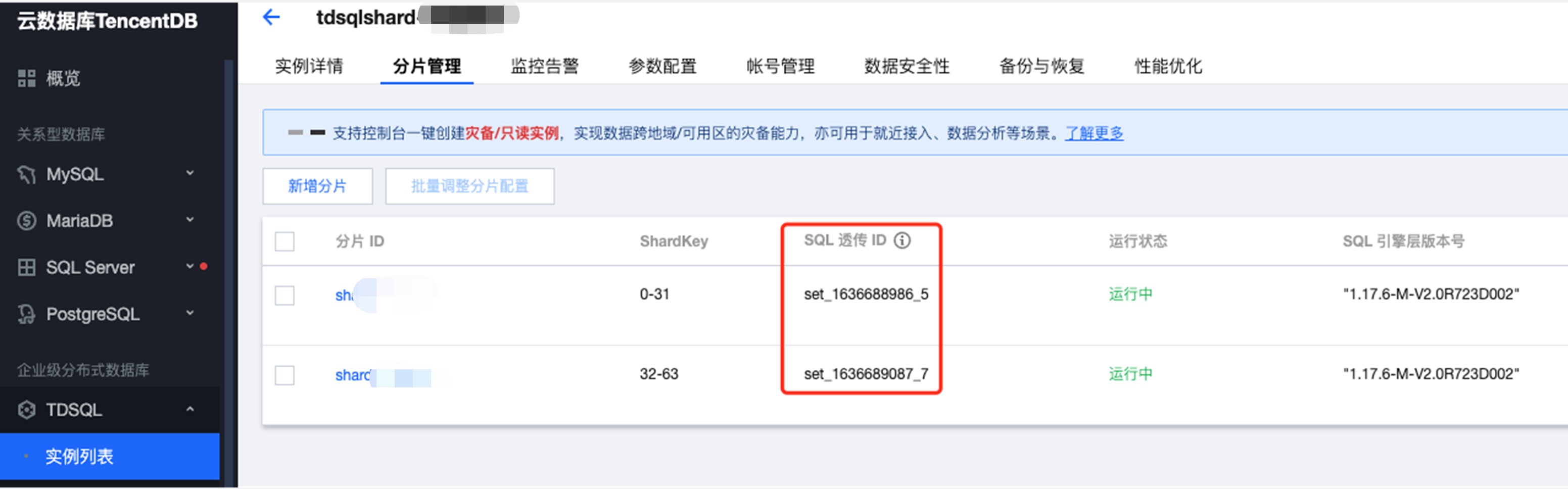
Kafka 中的每条消息的消息头中都带有分片信息,以 key/value 的形式存在消息头中,key 是 ShardId,value 是 SQL 透传 ID,可根据 SQL 透传 ID 区分该消息来自哪个分片。用户可以在 TDSQL 控制台 > 实例列表 > 分片管理中查看 SQL 透传 ID。
支持订阅的 SQL 操作
操作类型 | 支持的 SQL 操作 |
DML | INSERT、UPDATE、DELETE |
DDL | CREATE DATABASE、DROP DATABASE、CREATE TABLE、ALTER TABLE、DROP TABLE、RENAME TABLE |
操作步骤
1. 登录 DTS 控制台,在左侧导航选择数据订阅,单击新建数据订阅。
2. 在新建数据订阅页,选择相应配置,单击立即购买。
计费模式:支持包年包月和按量计费。
地域:地域需与待订阅的数据库实例订阅保持一致。
数据库:请根据具体数据库类型进行选择。
版本:选择 kafka 版,支持通过 Kafka 客户端直接消费。
订阅实例名称:编辑当前数据订阅实例的名称。
3. 购买成功后,返回数据订阅列表,单击操作列的配置订阅对刚购买的订阅进行配置,配置完成后才可以进行使用。
4. 在配置数据库订阅页面,选择相应配置,单击保存并下一步。
配置项 | 说明 |
实例类型 | 购买时选择的数据库类型,不可修改。 |
接入类型 | 当前仅支持源数据库为腾讯云数据库实例的场景,请选择“云数据库”。 |
云数据库 | 云数据库实例:源数据库的实例 ID。 支持选择只读/灾备实例,但推荐选择主实例,订阅服务对源库的压力非常小。 |
账号/密码 | 账号/密码:源数据库的账号、密码。 |
5. 在订阅类型和对象选择页面,选择订阅类型,单击保存并下一步。
配置项 | 说明 |
订阅类型 | 数据更新:订阅源库全部对象的数据更新,包括数据 INSERT、UPDATE、DELETE 操作。 结构更新:订阅源库全部对象的结构创建、修改和删除。 全实例:订阅源库全部对象的数据更新和结构更新。 |
Kafka 版本 | 显示 DTS 内置 Kafka 的版本,不可修改。 |
Topic 分区数量 | 设置数据投递到内置 kafka 中 Topic 的分区数量,增加分区数量可提高数据写入和消费的速度。单分区可以保障消息的顺序,多分区无法保障消息顺序,如果您对消费到消息的顺序有严格要求,请选择分区数量为1。 |
6. 在预校验页面,预校验任务预计会运行2分钟 - 3分钟,预校验通过后,单击启动完成数据订阅任务配置。
说明:
7. 单击启动后,订阅任务会进行初始化,预计会运行3分钟 - 4分钟,初始化成功后进入运行中状态。
8. 新增消费组,数据订阅 Kafka 版支持用户创建多个消费组(单个订阅任务最多支持创建10个消费组),进行多点消费。数据订阅 Kafka 版消费依赖于 Kafka 的消费组,所以在消费数据前需要创建消费组。
9. 订阅实例进入运行中状态之后,就可以开始消费数据。Kafka 的消费需要进行密码认证,具体示例请参考 数据消费 Demo,我们提供了多种语言的 Demo 代码,也对消费的主要流程和关键的数据结构进行了说明。



