操作场景
DTS 支持将源数据库的全量、增量数据同步到 CKafka 中,方便用户快速获取业务变更数据并进行分析应用。本文为您介绍使用数据传输服务 DTS 将 MySQL/MariaDB/Percona/TDSQL-C MySQL 数据同步至腾讯云数据库 CKafka 的过程。
源数据库支持的部署类型如下:
自建 MySQL、第三方云厂商 MySQL、腾讯云数据库 MySQL。
自建 MariaDB、腾讯云数据库 MariaDB。
自建 Percona。
腾讯云数据库 TDSQL-C MySQL。
准备工作
1. 请仔细阅读 使用说明,了解功能约束和注意事项。
2. 请根据您需要使用的接入类型,提前打通 DTS 与数据库之间的访问通道,具体请参考 网络准备工作。
IDC 自建数据库/轻量数据库/其他云厂商数据库:接入方式可选择“公网/专线接入/VPN 接入/云联网”。
CVM 上的自建数据库:接入方式选择“云服务器自建”。
腾讯云数据库实例:接入方式选择“云数据库”。
3. 同步任务账号需要具备源数据库的权限如下:
GRANT RELOAD,LOCK TABLES,REPLICATION CLIENT,REPLICATION SLAVE,SHOW VIEW,PROCESS,SELECT ON *.* TO '账号'@'%' IDENTIFIED BY '密码';GRANT ALL PRIVILEGES ON `__tencentdb__`.* TO '账号'@'%';FLUSH PRIVILEGES;
4. 在目标 CKafka 中修改消息保留时间和消息大小上限,具体方法请参考 配置消息大小。
消息保存时间建议设置为3天,超过保存时间的数据会被清除,请用户在设置的时间内及时消费;消息大小上限,即 CKafka 可以接收的单个消息内存的大小,设置时需要大于源库表中单行数据的最大值,以确保源库的数据都可以正常投递到 CKafka 中。
5. 首次使用消息队列 CKafka 作为 DTS 同步链路的目标端,需要对目标端所属腾讯云子账号进行如下授权。
5.1 对子账号授权 “QcloudCKafkaReadOnlyAccess(消息队列 CKafka 版(CKafka)只读访问策略)”,允许 DTS 拉取到 CKafka 实例列表,具体请参见授权子账号使用 DTS。
5.2 创建 DTS 角色信息,允许 DTS 访问 CKafka 服务资源,具体请参考 授权 DTS 访问其他云服务资源。
操作步骤
因为 MySQL/MariaDB/Percona/TDSQL-C MySQL 同步至腾讯云数据库 CKafka,各场景的同步要求和操作步骤基本一致,本章节仅以 MySQL 到 CKafka 的数据同步为例进行介绍,其他场景请参考相关内容。
1. 登录 数据同步购买页,选择相应配置,单击立即购买。
参数 | 描述 |
计费模式 | 支持包年包月和按量计费。 |
源实例类型 | 选择 MySQL,购买后不可修改。 |
源实例地域 | 选择源实例所在地域,购买后不可修改。如果源数据库为自建数据库,选择离自建地域最近的一个地域即可。 |
目标实例类型 | 选择 Kafka,购买后不可修改。 |
目标实例地域 | 选择目的实例所在地域,购买后不可修改。 |
规格 |
2. 购买完成后,返回 数据同步列表,可看到刚创建的数据同步任务,单击操作列的配置,进入配置同步任务页面。

3. 在配置同步任务页面,配置源端实例、账号密码,配置目标端实例、账号和密码,测试连通性后,单击下一步。
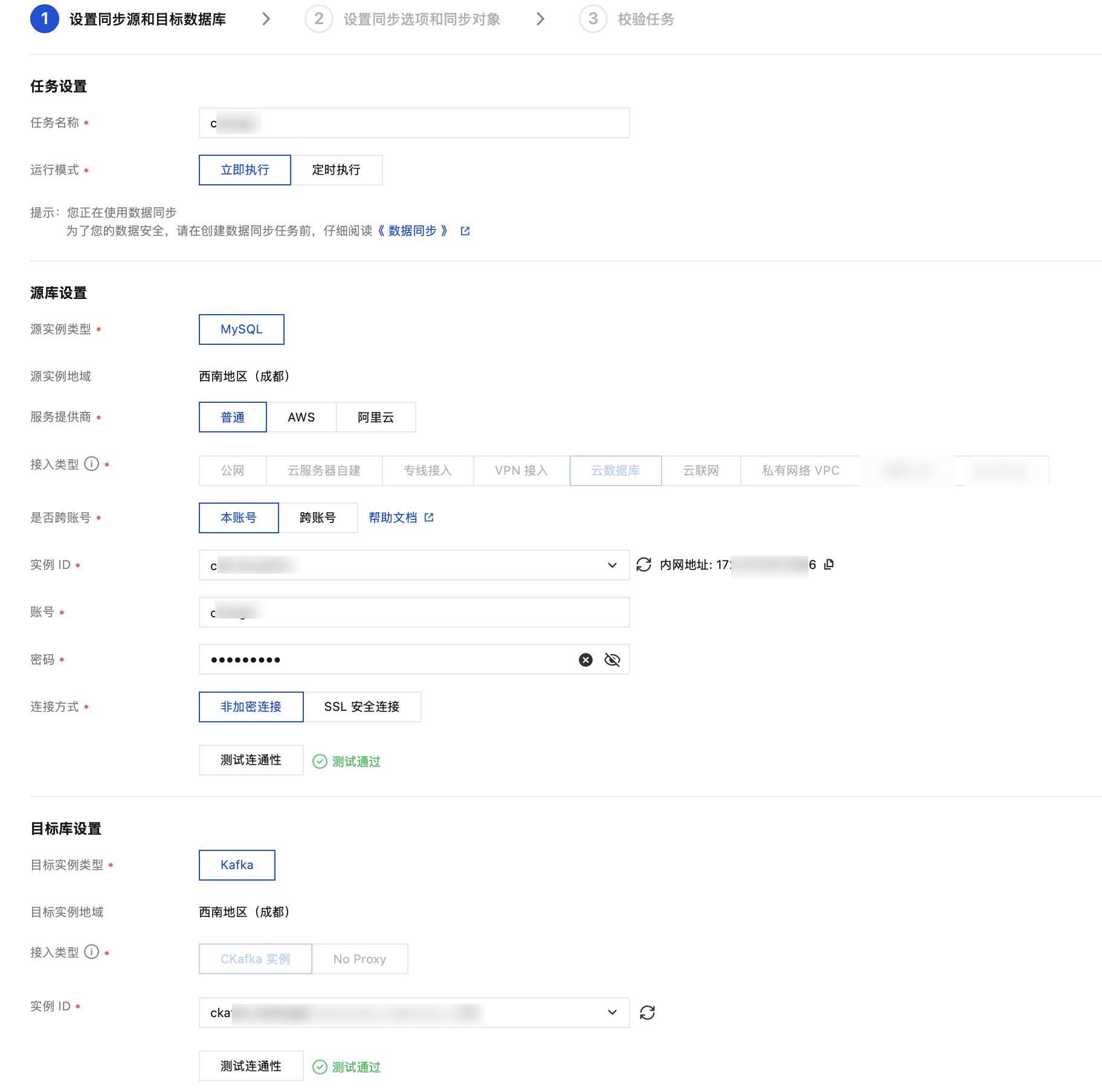
设置项 | 参数 | 描述 |
任务设置 | 任务名称 | DTS 会自动生成一个任务名称,用户可以根据实际情况进行设置。 |
| 运行模式 | 支持立即执行和定时执行两种模式。 |
源实例设置 | 源实例类型 | 购买时所选择的源实例类型,不可修改。 |
| 源实例地域 | 购买时选择的源实例所在地域,不可修改。 |
| 接入类型 | 公网:源数据库可以通过公网 IP 访问。 云服务器自建:源数据库部署在 腾讯云服务器 CVM 上。 专线接入:源数据库可以通过 专线接入 方式与腾讯云私有网络打通。 VPN 接入:源数据库可以通过 VPN 连接 方式与腾讯云私有网络打通。 云数据库:源数据库属于腾讯云数据库实例。 云联网:源数据库可以通过 云联网 与腾讯云私有网络打通。 |
| 公网 | 主机地址:源数据库 IP 地址或域名。 端口:源数据库使用的端口。 |
| 云服务器自建 | 云服务器实例:云服务器 CVM 的实例 ID。 端口:源数据库使用的端口。 |
| 专线接入 | 私有网络/专线网关:专线接入时只支持私有网络专线网关,请确认网关关联网络类型。 私有网络:选择私有网络专线网关和 VPN 网关关联的私有网络和子网。 主机地址:源数据库 IP 地址。 端口:源数据库使用的端口。 |
| VPN 接入 | VPN 网关:VPN 网关,请选择通过 VPN 网关接入的 VPN 网关实例。 私有网络:选择私有网络专线网关和 VPN 网关关联的私有网络和子网。 主机地址:源数据库 IP 地址。 端口:源数据库使用的端口。 |
| 云数据库 | 云数据库实例:源数据库的实例 ID。支持选择只读实例。 |
| 云联网 | 主机地址:源数据库的主机 IP 地址。 端口:源数据库使用的端口。 私有网络云联网:云联网实例名称。 接入 VPC:接入 VPC 指的是云联网中接入订阅链路的 VPC。请在云联网关联的所有 VPC 中,选择除了源数据库所属 VPC 外的其他 VPC。
例如,广州地域数据库作为源数据库,则接入 VPC 选择其他地域,如成都 VPC 或者上海 VPC。 子网:已选择 VPC 网络的子网名称。 接入 VPC 地域:购买任务时选择的源数据库地域与接入 VPC 地域需要保持一致,如果不一致,DTS 会将购买任务中选择的源数据库地域,改为接入 VPC 地域。 |
| 账号/密码 | 账号/密码:源数据库的账号、密码。 |
目标实例设置 | 目标实例类型 | 购买时选择的目标实例类型,不可修改。 |
| 目标实例地域 | 购买时选择的目标实例地域,不可修改。 |
| 接入类型 | 根据您的场景选择,本场景选择“CKafka 实例”。 |
| 实例 ID | 选择目标实例 ID。 |
4. 在设置同步选项和同步对象页面,将对数据初始化选项、数据同步到 Kafka 策略、数据同步选项、同步对象选项进行设置,在设置完成后单击保存并下一步。
4.1 数据初始化选项。
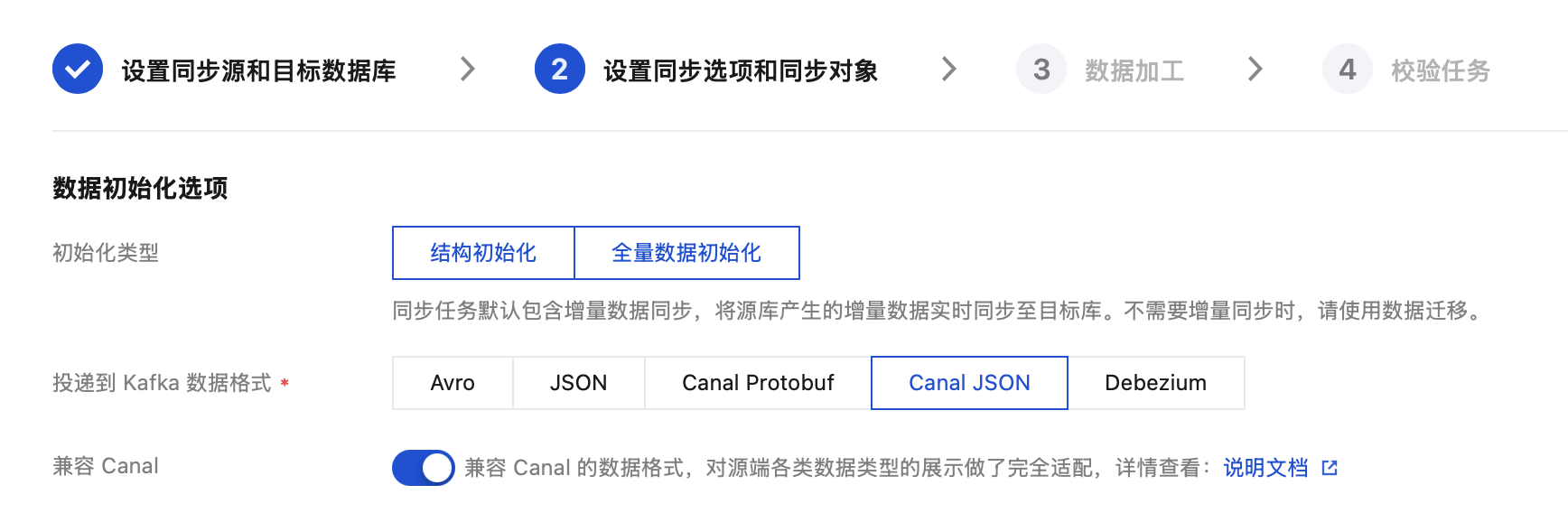
参数 | 描述 |
初始化类型 | 结构初始化:同步任务执行时会先将源实例中表结构初始化到目标实例中。 全量数据初始化:同步任务执行时会先将源实例中数据初始化到目标实例中。仅选择全量数据初始化的场景,用户需要提前在目标库创建好表结构。 |
投递到 Kafka 数据格式 | Avro:二进制格式,消费效率更高。 JSON:为轻量级的文本格式,更加简单易用。 Canal Protobuf:适配 Canal 的 Protobuf 数据格式。 Canal JSON:适配 Canal 的 JSON 数据格式。 Debezium:适配开源 Debezium 数据格式。 |
兼容 Canal | |
消息中是否包含 Schema | 选择投递到 Kafka 中的消息,是否包含 schema 字段信息。 说明: 投递到 Kafka 数据格式为 Debezium 时可以配置此参数。 |
指定启动位点 | 初始化类型都不勾选时,表示仅增量同步,可设置增量同步的起始位点。 1. 增量同步任务,从设置的时间点开始同步数据,设置的时间点范围为:之前的14天-当前时间。 2. 如果全量同步和增量同步分开两个任务执行,这里请注意,进行增量同步时,DTS 已经同步的全量数据时间点1与设置的时间点2之间,不能存在 DDL(CREATE TABLE、ALTER TABLE、DROP TABLE、RENAME TABLE、CREATE INDEX、DROP INDEX)变更数据,否则任务会报错。 3. 从设置的指定时间点1,到增量任务启动点2之间(任务步骤从“寻找指定位点”转化为“同步增量”才算启动),源库操作注意事项如下。 建议源库不要进行主从切换、增加分片、重做备机操作,否则可能会影响 DTS 获取源库的 GTID 位点。 源端可以操作与同步对象无关的 DDL,但需要保证上一条 DDL 同步到目标端后再执行新的 DDL。密集地执行 DDL 可能会导致任务报错。 源端不能操作与同步对象有关的 DDL(CREATE TABLE、ALTER TABLE、DROP TABLE、RENAME TABLE、CREATE INDEX、DROP INDEX),否则同步任务会报错。 4. 因为指定位点同步是根据 Binlog 中 context 的时间(SET TIMESTAMP=XXXX)来判断其 GTID,为保证同步数据的正确性,建议用户不要修改该 context。 5. 请确认数据库设置的时区与当前控制台时区(即浏览器时区)一致,或者换算为数据库设置时区所对应的时间,否则可能会导致指定位点同步结果不合预期。 6. 如果设置的时间点在 XA 事务持续时间的范围内,则该 XA 事务不会被同步。对于这种情况,建议时间点可以往前设置一些(在 XA START 的时间之前)。 |
4.2 数据同步选项。
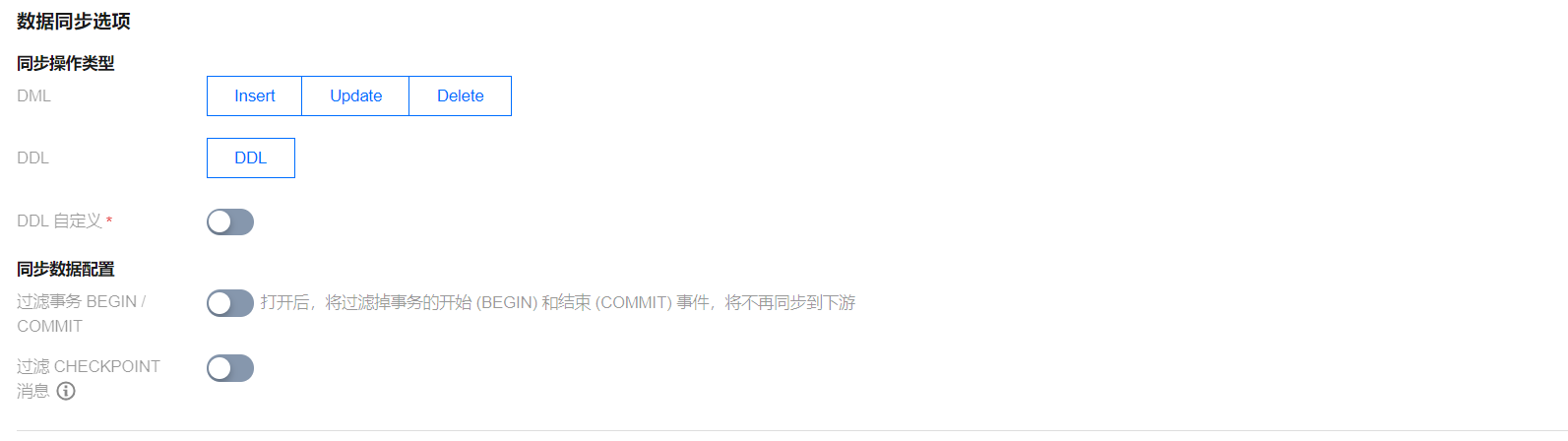
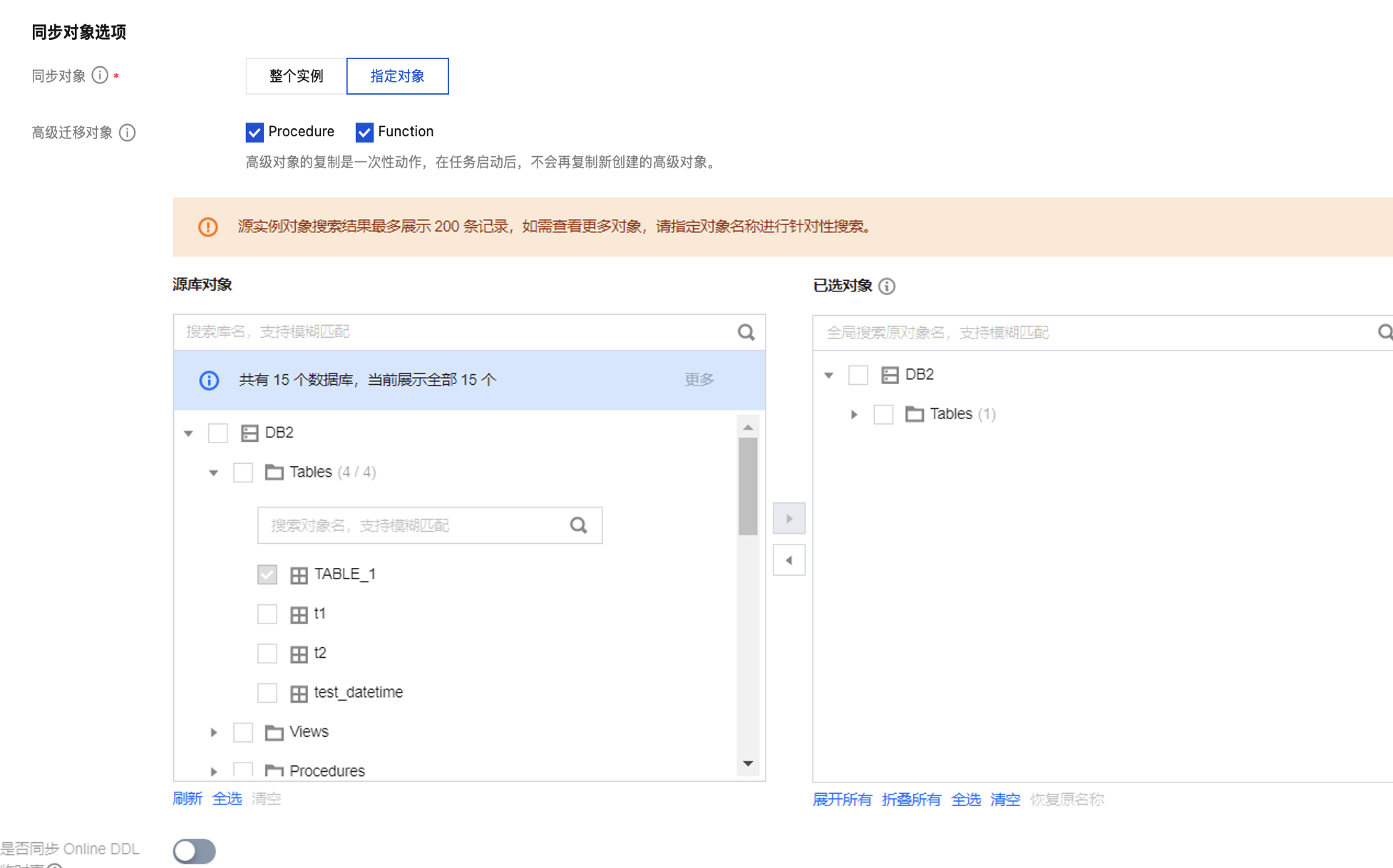
设置项 | 参数 | 描述 |
数据同步选项 | 同步操作类型 | 支持操作:Insert、Update、Delete、DDL。勾选“DDL 自定义”,可以根据需要选择不同的 DDL 同步策略。 |
| 过滤事务 BEGIN/COMMIT | 勾选后,DTS 进行数据同步时,将过滤掉事务的开始 (BEGIN) 和结束 (COMMIT)事件,不再同步到下游。 说明: 仅在“单 Topic + 单分区”场景下可配置过滤 BEGIN/COMMIT 消息,具体如下: Topic 策略选择“集中投递到单 Topic”,同时,分区策略选择“全部投递到 Partition0”。 Topic 策略选择“集中投递到单 Topic”,同时,用户的目标 Topic 中只设置了一个分区。 |
| 过滤 CHECKPOINT 消息 | 为了保证数据可重入,DTS 在事务之间插入 CHECKPOINT 消息,用来标识数据同步的位点,在任务中断后重启可实现断点续传。同时,消费端遇到 CHECKPOINT 消息会做一次 Kafka 消费位点提交,以便及时更新消费位点。 如果用户对 CHECKPOINT 消息比较在意,可以设置过滤 CHECKPOINT。过滤后 DTS 仍可以实现任务重启后的断点续传,仅在写入目标端 Kafka 时不插入 CHECKPOINT 消息,消费端也不能再按照 CHECKPOINT 更新消费位点。 |
同步对象选项 | 源实例库表对象 | 选择待同步的对象,支持基础库表、视图、存储过程和函数。高级对象的同步是一次性动作,仅支持同步在任务启动前源库中已有的高级对象,在任务启动后,新增的高级对象不会同步到目标库中。更多详情,请参考 同步高级对象。 |
| 已选对象 | 在左侧选择同步对象后,单击  |
| 是否同步 Online DDL 临时表 | 如果使用 gh-ost、pt-osc 工具对源库中的表执行 Online DDL 操作,DTS 支持将 Online DDL 变更产生的临时表迁移到目标库。 勾选 gh-ost,DTS 会将 gh-ost 工具产生的临时表名(`_表名_ghc`、`_表名_gho`、`_表名_del`)迁移到目标库。 勾选 pt-osc, DTS 会将 pt-osc 工具产生的临时表名(`_表名_new`、 `_表名_old`)迁移到目标库。 |
4.3 数据同步到 Kafka 策略。
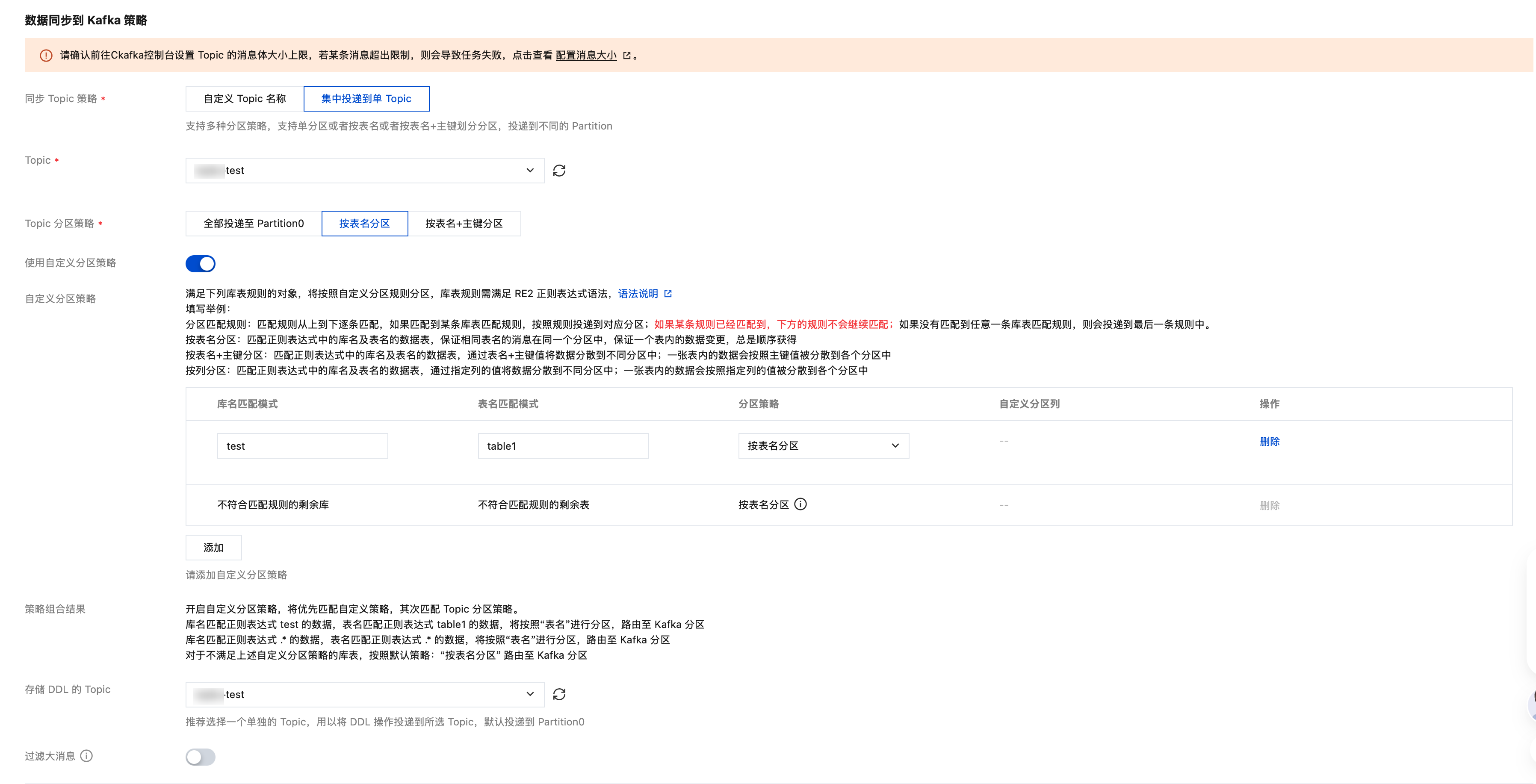
参数 | 描述 |
自定义 Topic 名称规则 | 自行设置投递的 Topic 名称,设置后可以将不同的表数据投递到不同 Topic 中。填入 Topic 名称后,目标端 Kafka 会自动创建该 Topic,如果没建成功,任务会报错。 设置规则如下,具体示例请参见 数据投递到 Kafka 策略设置示例。 用户添加了多条规则,自定义 Topic 匹配规则会从上到下逐条匹配。设置的库名和表名规则都匹配上,才会投递到该条规则对应的 Topic 中。如果没有匹配到库表匹配规则,则会投递到最后一条规则的 Topic 中;如果匹配到多条库表匹配规则,则会投递到所有匹配规则的 Topic 中。 库表、表名的匹配规则支持 RE2 正则表达式。如果需要精确匹配,则要加开始符“^”和结束符“$”,如精准匹配“test”表应该为“^test$”。 说明: 匹配规则对库表名大小写敏感。 如果源库设置 lower_case_table_names = 0,则库表匹配规则中,库表名需要与源库中的名称大小写严格保持一致。 如果源库设置 lower_case_table_names = 1,则库表名统一转换为小写,库表匹配规则中库表名统一输入小写。 |
集中投递到单 Topic 分区策略 | 全部投递至 Partition0:将源库的同步数据全部投递到第一个分区。 按表名分区:将源库的同步数据按照表名进行分区,设置后相同表名的数据会写入同一个分区中。 按表名+主键分区:将源库的同步数据按照表名+主键分区,适用于热点数据,设置后热点数据的表,通过表名+主键的方式将数据分散到不同分区中,提升并发消费效率。 |
自定义分区策略 | 自定义分区策略是通过正则表达式对库名和表名进行匹配,将匹配到的数据按照“表名、表名 + 主键、列”进行分区,剩余未匹配到的数据再按照 Topic 分区策略的设置进行分区。 |
存储 DDL 的 Topic | 可选,如果用户需要将源库的 DDL 操作单独投递到指定 Topic 中,可以在此处选择设置。
设置后默认投递到已选 Topic 的 Partition0;如果没设置会根据上面选择的 Topic 规则进行投递。 |
过滤大消息 | 开启后,超过最大消息大小的消息将被过滤,不会投递到 Kafka。 说明: 选择开启过滤大消息,在弹出的对话框中,设置最大消息大小,取值范围为:1 ~ 100,单位:MB。 |
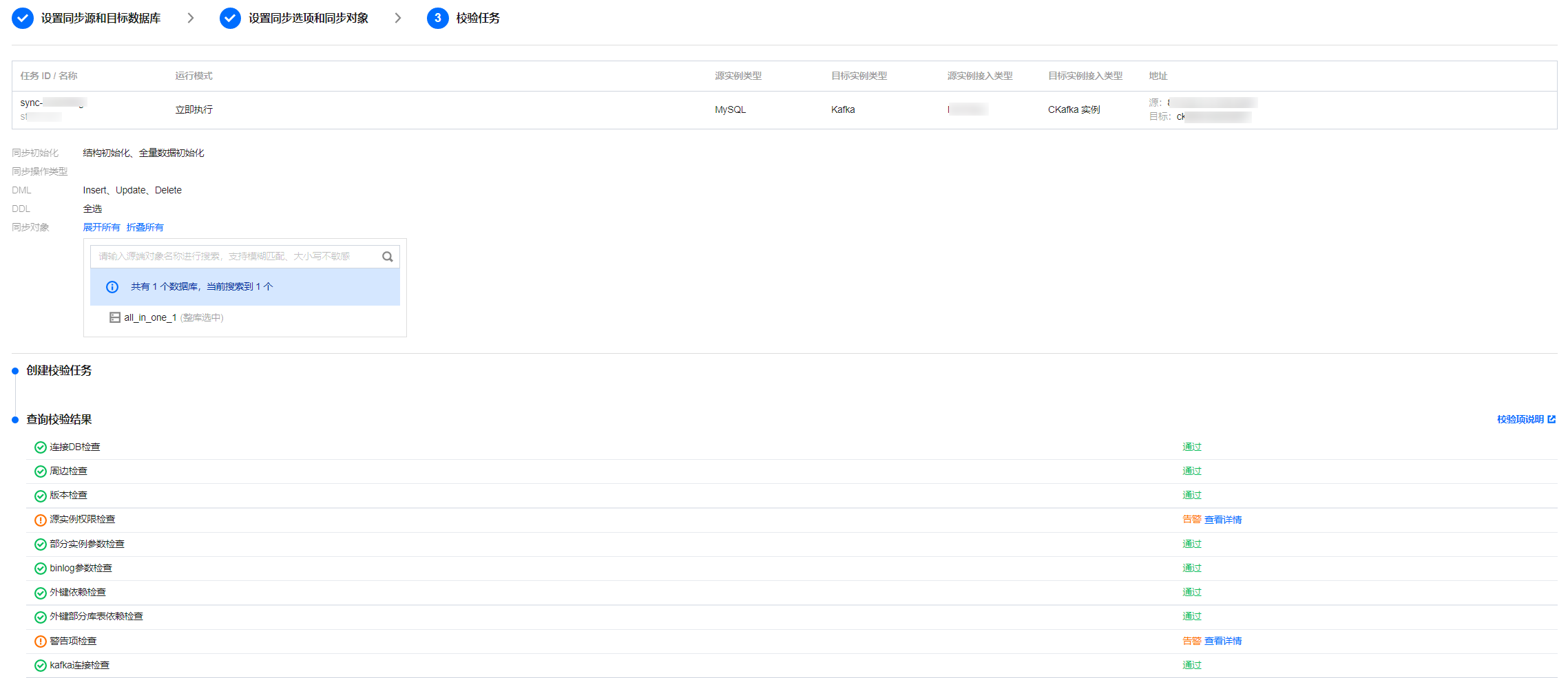
5. 在校验任务页面,完成校验并全部校验项通过后,单击启动任务。
如果校验任务不通过,可以参考 校验不通过处理方法 修复问题后重新发起校验任务。
失败:表示校验项检查未通过,任务阻断,需要修复问题后重新执行校验任务。
警告:表示校验项检查不完全符合要求,可以继续任务,但对业务有一定的影响,用户需要根据提示自行评估是忽略警告项还是修复问题再继续。
6. 返回数据同步任务列表,任务开始进入运行中状态。
说明:
选择操作列的更多 > 结束可关闭同步任务,请您确保数据同步完成后再关闭任务。

7. (可选)您可以单击任务名,进入任务详情页,查看任务初始化状态和监控数据。
后续操作



