Flink 核心是一个开源的分布式、高性能、高可用、准确的数据流执行引擎,其针对数据流的分布式计算提供了数据分布、数据通信以及容错机制等功能。基于流执行引擎,Flink 提供了更高抽象层的 API 以便您编写分布式任务。
分布式:表示 Flink 程序可以运行在多台机器上。
高性能:表示 Flink 处理性能比较高。
高可用:表示 Flink 支持程序的自动重启机制。
准确的:表示 Flink 可以保证处理数据的准确性。
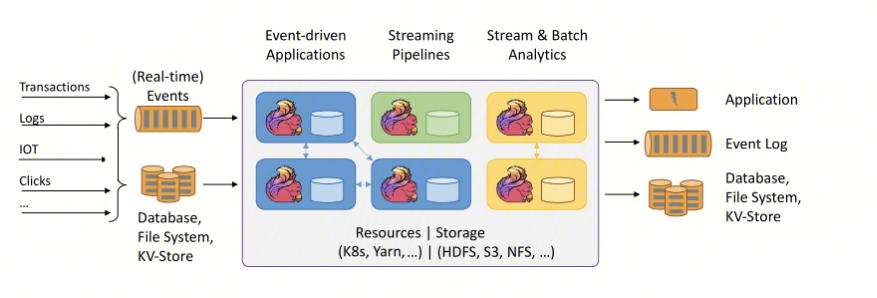
下图中左边是数据源,从这里可以看出来,这些数据是实时生产的一些日志,或者是数据库,文件系统,kv 存储系统中的数据。中间是 Flink,负责对数据进行梳理。右边是目的地,Flink 可以将计算好的数据输出到其它应用系统中,或者存储系统中。Flink 的三大核心组件如下:
Data Source:也就是图中左边的数据源。
Transformations:算子(负责对数据进行处理)。
Data Sink:输出组件(负责把计算好的数据输出到其它应用系统中)。
使用场景
Flink 主要有以下三种应用场景:
1. 事件驱动型应用
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。
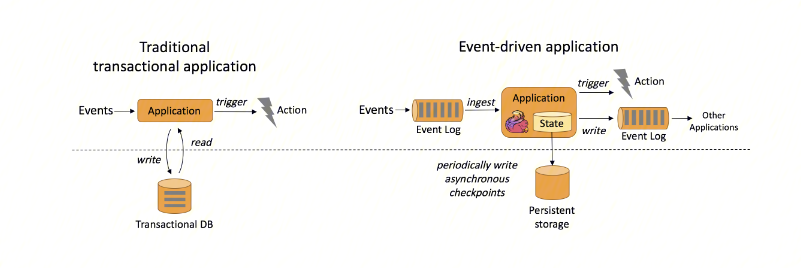
Flink 的以下特性很好地支持了事件驱动型应用。
高效的状态管理,Flink 自带的 State Backend 可以很好的存储中间状态信息。
丰富的窗口支持,Flink 支持包含滚动窗口、滑动窗口及其他窗口。
多种时间语义,Flink 支持 Event Time、Processing Time 和 Ingestion Time。
不同级别的容错,Flink 支持 At Least Once 或 Exactly Once 容错级别。
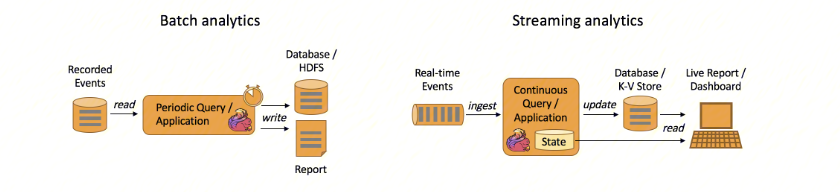
2. 实时数据分析应用:
数据分析任务需要从原始数据中提取有价值的信息和指标。传统的分析方式通常是利用批查询,或将事件记录下来并基于此有限数据集构建应用来完成。为了得到最新数据的分析结果,必须先将它们加入分析数据集并重新执行查询或运行应用,随后将结果写入存储系统或生成报告。
3. 实时数据仓库和 ETL
ETL(Extract-Transform-Load)的目的是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程。
传统的离线数据仓库将业务数据集中进行存储后,以固定的计算逻辑定时进行 ETL 和其他建模后产出报表等应用。离线数据仓库主要是构建 T+1 的离线数据,通过定时任务每天拉取增量数据,然后创建各个业务相关的主题维度数据,对外提供 T+1 的数据查询接口。
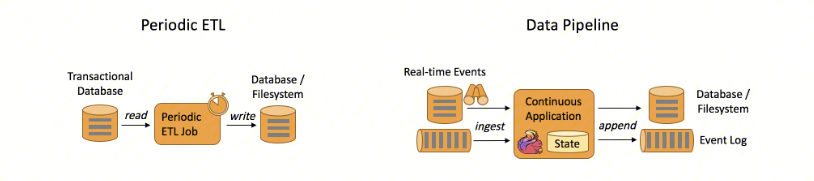
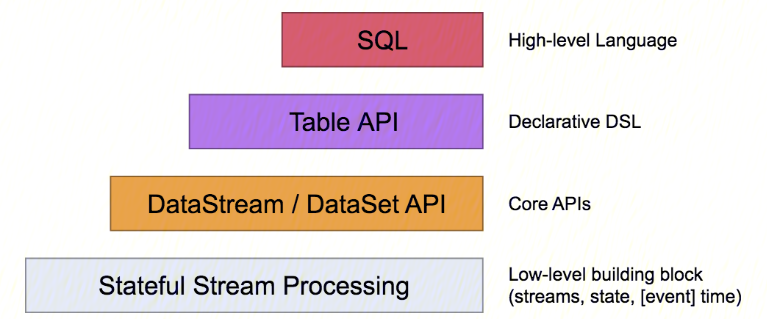
Table API & SQL :Table API 一般与 DataSet 或者 DataStream 紧密关联,可以通过一个 DataSet 或者 DataStream 创建出一个 Table,然后再使用类似 filter、sum、join、select 等这种操作。最近还可以将一个 Table 对象转换成 DataSet 或者 DataStream。SQL API 的底层是基于 Apache Calcite,Apache Calcite 实现了标准 SQL,使用起来比其它 API 更加灵活,因为可以直接使用 SQL 语句。Table API 和 SQL API 可以很容易地结合在一块使用。因为它们都返回 Table 对象。
DataStream API & DataSet API :主要提供针对流数据和批数据的处理,是对低级 API 进行了一些封装,提供了 filter、sum、max、min等高阶函数,简单易用,所以这些 API 在实际生产中应用还是比较广泛的。
Stateful Stream Processing :提供了对时间和状态的细粒度控制,简洁性和易用性较差,主要应用在一些复杂事件处理逻辑上。
环境信息
Flink 默认部署在集群的 Master、Core 节点,安装了 Flink 组件的集群其功能都是开箱即用的。
登录机器后使用命令 su hadoop 切换到 hadoop 用户进行一些Flink的本地测试。
Flink 软件路径在 /usr/local/service/flink 下。
相关日志路径在 /data/emr/flink/logs 下。



