功能说明
消息队列 CKafka 版提供了全面、多维度的监控指标体系,覆盖从实例到 Topic、消费组等各个层级,帮助您实时了解资源运行状态。本文为您介绍 CKafka 的各项监控指标的含义和推荐重点关注指标,您可以通过这些指标快速掌握实例等资源的健康状态,并决定是否需要升降配等运维操作,保障其稳定运行。
命名空间
Namespace=QCE/CKAFKA集群健康状态说明
CKafka 集群共有三种健康状态:健康、告警和异常。系统会定时巡检每个集群,巡检程序会检查该集群的连接数、磁盘使用百分比、生产峰值带宽、消费峰值带宽,当这些指标超过一定的阈值后会产生不同的健康状态。
若集群状态出现异常,您可以到控制台的监控页面查看相应的监控指标详情,以定位问题,若您有查看集群负载监控等进一步需求,可以到高级监控页面查看相关信息(当前仅专业版实例支持高级监控能力)。
指标 | 阈值(N) | 状态描述 |
连接数(默认最大值50000) | N ≤ 80% | 健康 |
| 80% < N ≤ 95% | 告警 |
| N > 95% | 异常 |
磁盘使用百分比 | N ≤ 80% | 健康 |
| 80% < N ≤ 95% | 告警 |
| N > 95% | 异常 |
生产峰值带宽(不含副本带宽) | N ≤ 80% | 健康 |
| 80% < N ≤ 100% | 告警 |
| N > 100% | 异常 |
消费峰值带宽 | N ≤ 80% | 健康 |
| 80% < N ≤ 100% | 告警 |
| N > 100% | 异常 |
注意:
基础监控指标
CKafka 基础监控能力支持实例、Topic、Consumer Group 三个维度的监控指标,适用于辅助异常问题发现、集群容量规划等基础运维场景需求。以下是 CKafka 基础监控能力提供的所有监控指标说明,请您根据实际业务需求合理配置监控和告警策略。
说明:
下方表格中内容与腾讯云可观测平台保持一致,确保您的数据在上报和告警时的一致性。部分时间粒度在 CKafka 控制台中没有展示,您可在腾讯云可观测平台进一步查看具体数据。
监控指标 | 指标英文名 | 单位 | 说明 |
实例最大生产流量 | InstanceMaxProFlow | MB | 实例单个副本的生产消息峰值带宽,不包含副本生产的带宽(计算实例生产带宽使用百分比时的参考依据),单位时间取最大值。 |
实例生产流量 | InstanceProFlow | MB | 实例生产流量(不包含副本产生的流量),按照所选择的时间粒度统计求和。 |
实例生产带宽百分比 | InstanceProduceBandwidthPercentage | % | 实例生产带宽占配额百分比,单位时间取平均值。 |
实例最大消费流量 | InstanceMaxConFlow | MB | 实例消费消息峰值带宽,消费时无副本的概念(计算实例消费带宽使用百分比时的参考依据),单位时间取最大值。 |
实例消费流量 | InstanceConFlow | MB | 实例消费流量(不包含副本产生的流量),按照所选择的时间粒度统计求和。 |
实例消费带宽百分比 | InstanceConsumeBandwidthPercentage | % | 实例消费带宽占配额百分比,单位时间取平均值。 |
实例生产消息条数 | InstanceProCount | Count | 实例生产消息条数,按照所选择的时间粒度统计求和。 |
实例消费消息条数 | InstanceConCount | Count | 实例消费消息条数,按照所选择的时间粒度统计求和。 |
实例落盘的消息总条数 | InstanceMsgCount | Count | 实例落盘的消息总条数(不包含副本),按照所选择的时间粒度取最新值。 |
集群消息请求速率 | InstanceTps | Count/s | 集群实例消息请求速率的情况,包括生产、消费、元数据、offset 提交,单位时间取平均值。 |
集群 TPS 明细 | BMetadataRequestsPersecOneminuterate BProduceRequestsPersecOneminuterate BFetchConsumerRequestsPersecOneminuterate BOffsetCommitRequestsPersecOneminuterate | Count/s | 集群 TPS 变化情况,单位时间取平均值。 |
实例磁盘占用量 | InstanceMsgHeap | MB | 实例磁盘占用量(包含副本),按照所选择的时间粒度取最新值。 |
磁盘使用百分比 | InstanceDiskUsage | % | 当前磁盘占用与实例规格磁盘总容量的百分比,单位时间取平均值。 |
实例生产限流次数 | InstanceProduceThrottle | Count | 实例生产限流次数,按照所选择的时间粒度统计求和。 |
实例消费限流次数 | InstanceConsumeThrottle | Count | 实例消费限流次数,按照所选择的时间粒度统计求和。 |
实例单节点最大连接数 | InstanceConnectCount | Count | 当前实例所有 broker 节点连接数,按照所选择的时间粒度取最大值。 |
集群级别连接数 | ConnectionNum | Count | 当前实例所有 broker 节点连接数,按照所选择的时间粒度取总和。 |
Topic 监控
监控指标 | 指标英文名 | 单位 | 说明 |
topic最大生产流量 | TMaxProduceFlow | MB/s | Topic 最大生产流量(不含副本流量),按照所选择的时间粒度取最大值。 |
topic最大消费流量 | TMaxConsumeFlow | MB/s | Topic 最大消费流量,按照所选择的时间粒度取最大值。 |
Topic 消费消息条数 | CtopicConCount | Count | Topic 的实际消费消息条数,按照所选择的时间粒度统计求和。 |
Topic 消费流量 | CtopicConFlow | MB | Topic 的实际消费流量(不包含副本产生的流量),按照所选择的时间粒度统计求和。 |
Topic 占用磁盘的消息总量 | CtopicMsgHeap | MB | Topic 实际占用磁盘的消息总量(不包含副本),按照所选择的时间粒度取最新值。 |
Topic 生产消息条数 | CtopicProCount | Count | Topic 的实际生产消息条数,按照所选择的时间粒度统计求和。 |
Topic 生产流量 | CtopicProFlow | MB | Topic 的实际生产流量(不包含副本产生的流量),按照所选择的时间粒度统计求和。 |
Topic 落盘的消息总条数 | CtopicMsgCount | Count | Topic 的实际落盘的消息总条数(不包含副本),按照所选择的时间粒度取最新值。 |
Topic 消费限流次数 | TTopicConsumeThrottle | Count/s | Topic 消费限流次数,按照所选择的时间粒度取平均值。 |
Topic 生产限流次数 | TTopicProduceThrottle | Count/s | Topic 生产限流次数,按照所选择的时间粒度取平均值。 |
Topic-Partition 监控
监控指标 | 指标英文名 | 单位 | 说明 |
Partition 消费消息条数 | PartitionConCount | Count | Partition 的实际消费消息条数,按照所选择的时间粒度统计求和。 |
Partition 消费流量 | PartitionConFlow | MB | Partition 的实际消费流量(不包含副本产生的流量),按照所选择的时间粒度统计求和。 |
Partition 落盘的消息总条数 | PartitionMsgCount | Count | Partition 的实际落盘的消息总条数(不包含副本),按照所选择的时间粒度求和。 |
Partition 占用磁盘的消息总量 | PartitionMsgHeap | MB | Partition 实际占用磁盘的消息总量(不包含副本),按照所选择的时间粒度求和。 |
Partition 生产消息条数 | PartitionProCount | Count | Partition 的实际生产消息条数,按照所选择的时间粒度统计求和。 |
Partition 生产流量 | PartitionProFlow | MB | Partition 的实际生产流量(不包含副本产生的流量),按照所选择的时间粒度统计求和。 |
Consumer Group-Topic 监控
监控指标 | 指标英文名 | 单位 | 说明 |
主题最大 offset | MaxOffsetTopic | 不适用 | 当前主题中所有分区的最大 offset,按照所选择的时间粒度取最大值。 |
主题消费 offset(区分 offset 最大值) | CtopicMsgOffset | 不适用 | 当前主题所有分区中消费组消费的最大 offset,按照所选择的时间粒度取最大值。 |
主题未消费消息数 | CtopicUnconsumeMsgCount | Count | 当前主题所有分区消费组未消费消息总和,按照所选择的时间粒度取和。 |
主题消费速度 | CtopicConsumerSpeed | Count/min | 当前主题所有分区消费组消费速率总和,按照所选择的时间粒度取和。 |
Consumer Group-Partition 监控
监控指标 | 指标英文名 | 单位 | 说明 |
分区消费速度 | CpartitionConsumerSpeed | Count/min | 消费分组在该分区的消费速率(条/分钟)。 |
当前消费 offset | CpartitionOffset | / | 消费分组在该分区当前消费 offset。 |
当前分区最大 offset | CpartitionMaxOffset | / | 当前分区最大 offset。 |
未消费的消息条数 | CpartitionUnconsume | Count | 消费分组在该分区下未消费消息数。 |
限流监控(专业版)
在限流管理监控页,可查看用户/客户端维度的消费限流次数指标。
规则筛选说明:
在下拉框中选择用户名和 Client ID,所选用户名与 Client ID 的组合须对应一条已有限流规则。
不同规则类型的监控筛选逻辑:
规则类型 | 用户名下拉框 | Client ID 下拉框 |
同时配置用户名和 Client ID | 选择对应用户名 | 选择对应 Client ID |
仅配置 Client ID | 选择全部 | 选择对应 Client ID |
仅配置用户名 | 选择对应用户名 | 选择全部 |
以下是 CKafka 限流监控能力提供的监控指标介绍和说明。
监控指标 | 单位 | 指标说明 |
用户及客户端消费限流次数 | Count | 因命中指定用户/客户端限流规则而触发的消费限流次数。 |
高级监控指标(专业版)
在基础监控指标的基础上,CKafka 专业版集群额外支持高级监控能力。您可以通过高级监控查看节点级监控指标,用于异常问题定位、限流分析、耗时分析等业务排障场景需求。以下是 CKafka 高级监控能力提供的所有监控指标介绍和说明。
监控指标 | 指标说明 | 正常值范围 | 处理建议 |
Broker 节点存活 | 各 Broker 节点服务状态,通过心跳机制检测节点可用性。 | 正常值为100%。 若节点存活率小于正常值,即存在 Broker 宕机情况,将触发 ISR 收缩。 | 当节点状态异常时,建议立即重启故障节点并检查系统资源占用情况。 若多次重启失败,请联系在线客服。 |
集群负载 | 集群整体负载情况,所有节点中取最大值。 | 单 AZ 部署,集群负载< 70% 。 2 AZ 部署时,集群常态负载< 35% 。 3 AZ 部署时,集群常态负载<47% 。 如果带宽使用率低但是集群负载高,需要结合集群负载指标进行集群带宽扩容。 | 建议负载过高时,及时升级集群带宽规格。具体可参见集群容量规划实践教程。 |
监控指标 | 指标说明 | 正常值范围 | 处理建议 |
网络空闲度 | 用于衡量实例当前网络并发处理剩余的 IO 资源,越接近1越空闲。 | 该值一般在0.5 - 1之间波动,小于0.3表示负载较高。 | 该值持续低于0.3时,通过控制台监控检查实例带宽使用率与磁盘使用百分比情况。 若带宽超80%则需升配扩容,若磁盘使用百分比超80%可调整磁盘容量或启用磁盘水位处理策略。 扩容操作请参考升级集群规格;启用磁盘水位处理策略请参考配置磁盘水位处理策略。 |
请求队列深度 | 反映当前未处理的生产请求个数,如果该值过大可能是同一时间请求量过大,CPU 负载过高或者磁盘 IO 出现瓶颈。 | 如果持续等于2000,表示集群负载比较高。 小于2000的时候可忽略,无影响。 | 客户端生产消费出现超时而云服务器负载却正常的情况下,说明单台服务器的请求队列已达到最大上限,默认单台节点 Broker 的请求队列长度配置是 500,可根据购买的资源配置情况适当调整(联系 在线客服)。 |
未同步副本数 | 集群中存在的未同步的副本个数,当实例存在未同步副本,表示集群的健康度可能存在问题。 | 为了保证您的实例正常运行,CKafka 为其设置了部分内置 Topic。这些 Topic 在某些情况下处于离线状态,但会被计入未同步副本数中,这并不影响您的业务正常运行。 正常情况下,未同步副本数应在5以下。如果曲线水位长期大于5,表示需要进行处理。 Broker 偶尔波动,曲线值凸起后,一段时间后,又回归平稳,属于正常现象。 | 当曲线水位长期大于5时,代表集群中存在未同步的副本,通常情况下是由于 Broker 节点异常或网络因素,可通过 Broker 日志来排查原因。 |
ZK 断连次数 | 无正常值范围。该值是一个累加值,Broker 启动后,断连一次加1,只有 Broker 重启才会置0。 ZK 断连次数是累加的,次数越大不表示集群有问题。需观察 ZK 断连频率,若 ZK 断连情况出现较频繁,则需进一步排查处理。 | 在控制台查看集群负载是否超80%,若超过阈值可以升级集群带宽规格。具体操作请参考升级集群规格。 该指标项如需告警,建议配置为环比告警。 | |
ISR 扩充次数 | ISR(In-Sync Replica)是指与 Leader 副本保持同步的 Follower 副本集合。Kafka ISR 扩充次数值存在未同步副本时,当未同步副本追上 Leader 数据,会重新加入 ISR,此时该次数就会加1。 | 无正常值范围,当集群出现波动时,会出现扩充。 非频繁波动(如每小时<3次)无需干预,若该值持续增加需要排查。 | 建议保障集群负载水位处于80%以下,超过时建议升配处理。具体操作请参考升级集群规格。 若集群水位正常,客户端可以优化生产端参数,调整 linger.ms 不为0,同时设置 ack=1,保证吞吐情况下,减少集群的同步压力。 如若频繁出现 ISR,生产或消费受到影响,且长时间未恢复,请联系我们。 |
ISR 收缩次数 | Kafka ISR 收缩次数,即当出现 Broker 宕机,ZooKeeper 重连的情况,会出现 ISR 缩小的次数统计。 | 无正常值范围,当集群出现波动时,会出现收缩。 瞬时波动无影响。若长期频繁出现,则需检查。 | 建议保障集群负载水位处于80%以下,超过建议升配处理。 如集群水位正常,建议对高负载分区进行手动分区平衡。 对于带 key 的消息,通过设置分区策略保障写入均衡。 如果单分区出现瓶颈,则增加分区提高写入并行度。 |
实例 Broker 存储使用率 | 该集群各 Broker 的磁盘占用率,单位时间内取最大值。 | 该值一般会在 0-100%之间。 如果该值达到80%以上,则需要进行相关处理。 | 升级存储规格,建议预留30%磁盘缓冲空间。 |
监控指标 | 指标说明 | 正常值范围 | 处理建议 |
Broker 节点生产限流次数 | 各个 Broker 节点触发生产限流的次数。 | 无正常值范围。 少量突发的限流是正常情况,对业务无影响,无需特别关注。如持续频繁出现,需进行进一步排查。 | 检查带宽使用率,若生产流量>带宽规格的80% 则进行升配处理。具体操作请参考升级集群规格。 确保分区为节点的整数倍,单分区不出现写入瓶颈,出现瓶颈需要调整写入的分区策略,保障均衡写入。 开启磁盘水位处理中的磁盘自动扩容功能。具体操作请参考配置磁盘水位处理策略。 |
Broker 节点生产流量(MB) | 各个 Broker 节点的生产流量。 | 无正常值范围,根据业务及购买规格波动。 一般生产流量偶尔超过购买带宽规格时无需特别关注,如持续高于购买规格则需进一步操作。 | 建议升级带宽规格,至少保留20%的缓冲区间。具体操作请参考升级集群规格。 若单节点持续高位需要确定是否存在写入不均衡的情况,例如消息配置了 key 的情况,优化写入不均衡的问题。 |
最大生产流量(Bytes/s) | 各个 Broker 节点的最大生产流量。 | 无正常值范围,根据业务及购买规格波动。 一般最大生产流量峰值偶尔超过购买规格时无需特别关注,如持续高于购买规格则需进一步操作。 | 建议升级带宽规格,至少保留20%的缓冲区间。具体操作请参考升级集群规格。 若单节点持续高位需进行手动分区平衡。 |
单机生产流量占用率(%) | 单机生产流量占用购买流量的百分比。 | 该值一般会在 0-100%之间。 短时间内的占用率高峰可能为业务正常现象,无需特殊关注。如占用率长期较高,建议进一步处理。 | 如果该值长期达到80%以上,建议进行升配处理。具体操作请参考升级集群规格。 |
生产总耗时 | 表示生产请求的总耗时,由回包队列、延时回包、fetch 请求耗时、本地处理、请求队列耗时等指标汇总而成。 在每一个时间点,总耗时不等于以上五个耗时的累加,因为每个指标都是各自取平均得到的,故不累加相等。 | 一般值在0 - 100ms 之间,数据量大的时候0 - 1000ms 的耗时属于正常范围。 只要不长时间大于1000ms,可以不用处理。 如持续大于1000ms,建议进一步排查。 | 建议保障集群负载水位处于80%以下,超过建议升配处理。具体操作请参考升级集群规格。 如集群水位正常,尝试优化生产参数 ack 为-1,linger.ms 调大为非0进行写入优化。 |
请求队列耗时 | 生产请求在接收请求队列内等待的时间,表示请求包等待后续的进程处理。 | 一般值在0 - 50ms 之间,数据量大的时候0 - 200ms 的耗时属于正常范围。 只要不长时间大于200ms,可以不用处理。 如持续大于200ms,建议进一步排查。 | 建议保障集群负载水位处于80%以下,超过建议升配处理。具体操作请参考升级集群规格。 如集群水位正常,尝试优化生产参数 ack 为-1,linger.ms 调大为非0进行写入优化。 |
本地处理耗时 | 生产请求在 Leader Broker 处理的时间,即从请求队列拿出请求包,写入到本地 page cache 的时间。 | 一般值在0 - 50ms 之间,数据量大的时候0 - 200ms 的耗时属于正常范围。 只要不长时间大于200ms,可以不用处理。 如持续大于200ms,建议进一步排查。 | 建议使用存储是 SSD 磁盘的集群。 批量写入场景建议调大 batch.size,同时调大 linger.ms 优化攒批效率。 |
ack 等待耗时 | 生产请求等待数据同步的耗时,当客户端 ack = -1时该值才会大于0,即只要 ack = 1或者0,该值都是0。 | 一般值在0 - 200ms 之间,数据量大的时候0 - 500ms 的耗时属于正常范围。 跨可用区实例当 ack = -1时,该值会比非跨可用区的实例高,具体请参见 跨可用区部署。 只要不长时间大于500ms,可以不用处理。 如持续大于500ms,建议进一步排查。 | 降低副本数(ack=1优先保护生产和吞吐)。 |
延时回包耗时 | 生产请求被系统延时回包的耗时,当实例的流量没超过购买流量时,该值都为0,如果被限流,则会大于0。 | 当实例不超限时,该值长期为0。 如果实例超限,会根据超限的比例,延时0 - 5分钟,即该值最大为5分钟。 | 当值持续>0时启动生产端限流,检查突发流量来源。 若持续超限需升配扩容带宽。具体操作请参考升级集群规格。 |
回包队列耗时 | 生产请求在回包队列的等待耗时,表示请求包在等待被发送给客户端。 | 一般值在0 - 50ms 之间,数据量大的时候0 - 200ms 的耗时属于正常范围。 只要不长时间大于200ms,可以不用处理。 如持续大于200ms,建议进一步排查。 | 检查网络拥塞情况和 TCP 连接数,优化生产端连接复用,同时减少生产者所在节点的水位。 |
生产延时回包耗时95th | 95% 的生产请求被系统延时回包的耗时低于该值。 | 当实例不超限时,该值长期为0。 如果实例超限,会根据超限的比例,延时0 - 5分钟,即该值最大为5分钟。 | 该场景一般出现在限流情况,需确认是否超过带宽及超过情况。 如果持续超过则需要处理,可通过升配解决。具体操作请参考升级集群规格。 |
监控指标 | 指标说明 | 正常值范围 | 处理建议 |
Broker 节点消费限流次数 | 各个 Broker 节点触发消费限流的次数。 | 无正常值范围。 少量突发的限流是正常情况,对业务无影响,无需特别关注。如持续频繁出现限流,需进行进一步排查。 | 检查带宽使用率,若消费流量>规格的80%则进行扩容处理。扩容操作请参考升级集群规格。 开启磁盘水位处理中的磁盘自动扩容功能。具体请参考配置磁盘水位处理策略。 |
Broker 节点消费流量(MB) | 各个 Broker 节点的消费流量。 | 无正常值范围,根据业务及购买规格波动。 一般生产流量偶尔超过购买规格时无需特别关注,如持续高于购买规格则需进一步处理。 | 建议升级带宽规格,至少保留20%的缓冲区间。扩容操作请参考升级集群规格。 开启弹性带宽能力。具体操作请参考开启弹性带宽。 |
最大消费流量(Bytes/s) | 各个 Broker 节点的最大消费流量。 | 无正常值范围,根据业务及购买规格波动。 一般最大生产流量峰值偶尔超过购买规格时无需特别关注,如持续高于购买规格则需进一步处理。 | 建议升级带宽规格,至少保留20%的缓冲区间。扩容操作请参考升级集群规格。 开启弹性带宽能力。具体操作请参考开启弹性带宽。 |
单机消费流量占用率 | 单机消费流量占用购买流量的百分比。 | 该值一般会在0-100之间。 如果该值长期达到80以上,则需要考虑升配。 | 如果该值长期达到80%以上,建议进行升配操作。具体操作请参考升级集群规格。 |
消费总耗时 | 表示消费的总耗时,由回包队列、延时回包、fetch 请求耗时、本地处理、请求队列耗时指标汇总而成。 在每一个时间点,总耗时不等于以上五个耗时的累加,因为每个指标都是各自取平均得到的,故不累加相等。 | 一般值会在500ms - 1000ms 之间(客户端默认的 fetch.max.wait.ms=500ms),数据量大的时候500 - 5000ms 的耗时属于正常范围。 如持续大于5000ms,建议进一步排查。 | 建议保障集群负载水位处于80%以下,超过建议升配处理。具体操作请参考升级集群规格。 调高消费者超时时间 request.timeout.ms,避免误判超时。 |
请求队列耗时 | 消费请求在请求队列内等待的时间,表示请求包等待后续的进程处理。 | 一般值在0 - 50ms 之间,数据量大的时候0 - 200ms 的耗时属于正常范围。 只要不长时间大于200ms,可以不用处理。 如持续大于200ms,建议进一步排查。 | 建议保障集群负载水位处于80%以下,超过建议升配处理。具体操作请参考升级集群规格。 如集群水位正常,尝试优化生产参数,设置 ack 为-1,linger.ms 调大为非0进行写入优化。 |
本地处理耗时 | 消费请求在 Leader Broker 拉取数据的时间,即从本地磁盘读取数据。 | 一般值在0 - 500ms 之间,数据量大的时候0 - 1000ms 的耗时属于正常范围。 只要不长时间大于1000ms,可以不用处理,因为消费可能会有读冷数据的情况,此时耗时会较高。 如持续大于1000ms,建议进一步排查。 | 建议使用存储是 SSD 磁盘的集群。 |
消费等待耗时 | 客户端默认的 fetch.max.wait.ms = 500ms,即表示客户端允许在读不到数据的时候,服务端等待多久返回包给客户端。 | 一般值会在500ms 左右(客户端默认的 fetch.max.wait.ms = 500ms),该值的大小取决于客户端的参数设置。 | 根据业务情况调整等待时间 fetch.max.wait.ms。 说明: 在停止消费的场景下,fetch 耗时不需要作为延时参考,应综合健康状态、消费延时、消费堆积等多个指标进行参考。 |
延时回包耗时 | 消费请求被系统延时回包的耗时,当实例的流量没超过购买流量时,该值都为0,如果被限流,则会大于0。 | 当实例不超限时,该值长期为0。 如果实例超限,会根据超限的比例,延时0 - 5分钟,即该值最大为5分钟。 | 当值持续大于0时启动消费端限流,检查突发流量来源。 若持续超限需升配扩容带宽。具体操作请参考升级集群规格。 |
回包队列耗时 | 消费请求在回包队列的等待耗时,表示请求包在等待被发送给客户端。 | 一般值会在于0 - 50ms 之间,数据量大的时候0 - 200ms 的耗时属于正常。 只要不长时间大于200ms,就可以不用处理。 如持续大于200ms,建议进一步排查。 | 优化消费者网络配置,缩短等待间隔 fetch.max.wait.ms。 检查 Broker 节点 TCP 重传率。 如果消费者所在节点水位偏高,需要垂直升配或者水平扩容。具体操作请参考升级集群规格。 |
消费延时回包耗时95th | 95% 的消费请求被系统延时回包的耗时低于该值。 | 当实例不超限时,该值长期为0。 如果实例超限,会根据超限的比例,延时0 - 5分钟,即该值最大为5分钟。 | 该场景一般出现在限流情况,需确认是否超过规格带宽。 如果持续超过则需要处理,可通过升配解决。具体操作请参考升级集群规格。 |
监控指标 | 指标说明 | 正常值范围 | 处理建议 |
CPU 使用率(%) | CPU 使用率是某进程在一段时间内占用的 CPU 时间占总的 CPU 时间的百分比。 | 该值一般会在 1-100%之间。 持续5个以上周期范围在90%以上,则表示系统负载很高,需要处理排查。 | 升配实例规格,具体操作请参考升级集群规格。 |
内网入带宽(MB) | 内网入带宽是指 CVM 在集群内通信能够达到的带宽,根据不同的规格限制内网带宽和内网收包能力。 | 该值一般会大于0(集群内 CVM 监控会有数据产生)。 如果没有入带宽产生则代表 CVM 服务异常,或网络异常不可到达。 | 检查安全组规则。 排查 VPC 网络路由问题,有数据但超过限制规格时购买内网带宽包。 |
内网出带宽(MB) | 内网出带宽是指 CVM 在集群内通信能够达到的带宽,根据不同的规格限制内网带宽和内网发包能力。 | 该值一般会大于0(集群内 CVM 监控会有数据产生)。 如果没有出带宽产生则代表 CVM 服务异常,或网络异常不可到达。 | 检查安全组规则。 排查 VPC 网络路由问题,有数据但超过限制规格时购买内网带宽包。 |
内存利用率(%) | 内存总空间减去所有内存可用空间占用内存总空间的百分比为内存利用率 | 正常取值范围1-100。 如果内存使用率达到90%以上,则代表程序占用内存过高,需要对某些进程处理。 | 升配带宽规格提高物理资源规格,具体操作请参考升级集群规格。 |
公网入带宽(MB) | 公网入带宽是指 CVM 在公网通信能达到的带宽,根据不同规格限制公网带宽和外网收包能力。 | 有公网入流量下会大于0,否则为0。 如异常为0,则需进一步排查。 | 检查弹性公网 IP 是否欠费。 超过限制规格时升配公网带宽,具体操作请参考公网带宽管理。 |
公网出带宽(MB) | 公网出带宽是指 CVM 在公网通信能达到的带宽,根据不同规格限制公网带宽和外网发包能力。 | 有公网出流量下会大于0,否则为0。 如异常为0,则需进一步排查。 | 检查弹性公网 IP 是否欠费。 超限时升配公网带宽,具体操作请参考公网带宽管理。 |
监控指标 | 指标说明 | 正常值范围 | 处理建议 |
堆内存使用率(%) | Broker 的 JVM 堆内存使用量占总堆内存的百分比,单位时间内取最大值。 | 该指标的最大值一般会在 80-90之间波动。 如果长时间保持上升趋势,则需要关注堆内存的使用方式。 | 保障集群水位处于80%以下,如超过,建议升配处理,具体操作请参考升级集群规格。 如集群水位未超,首先确保版本是最新版本,如果不是最新版本,则升级到最新版本,具体操作请参考升级实例版本。 如果是最新版本,且依然持续存在问题,请联系 在线客服。 |
Young GC 次数(Count) | Broker Young GC 的次数。 | 正常在0 - 300之间。 如果持续高于300,则需要调整 GC 参数。 | 保障集群水位处于80%以下,如超过,建议升配处理,具体操作请参考升级集群规格。 如集群水位未超,首先确保是最新版本,如果不是最新版本,则升配最新版本,具体操作请参考升级实例版本。 如果是最新版本,且依然持续存在问题,请联系 在线客服。 |
Full GC 次数(Count) | Broker Full GC 的次数。 | 正常为0。 如果有出现大于0的情况,则需要处理。 | 保障集群水位处于80%以下,如超过,建议升配处理,具体操作请参考升级集群规格。 如集群水位未超,首先确保是最新版本,如果不是最新版本,则升配最新版本,具体操作请参考升级实例版本。 如果是最新版本,且依然持续存在问题,请联系 在线客服。 |
Dashboard 指标(专业版)
CKafka 专业版集群支持 Dashboard 能力,展示关键指标的 Top 排行,用于辅助生产消费热点分析、磁盘用量分析等业务优化分析场景的需求。
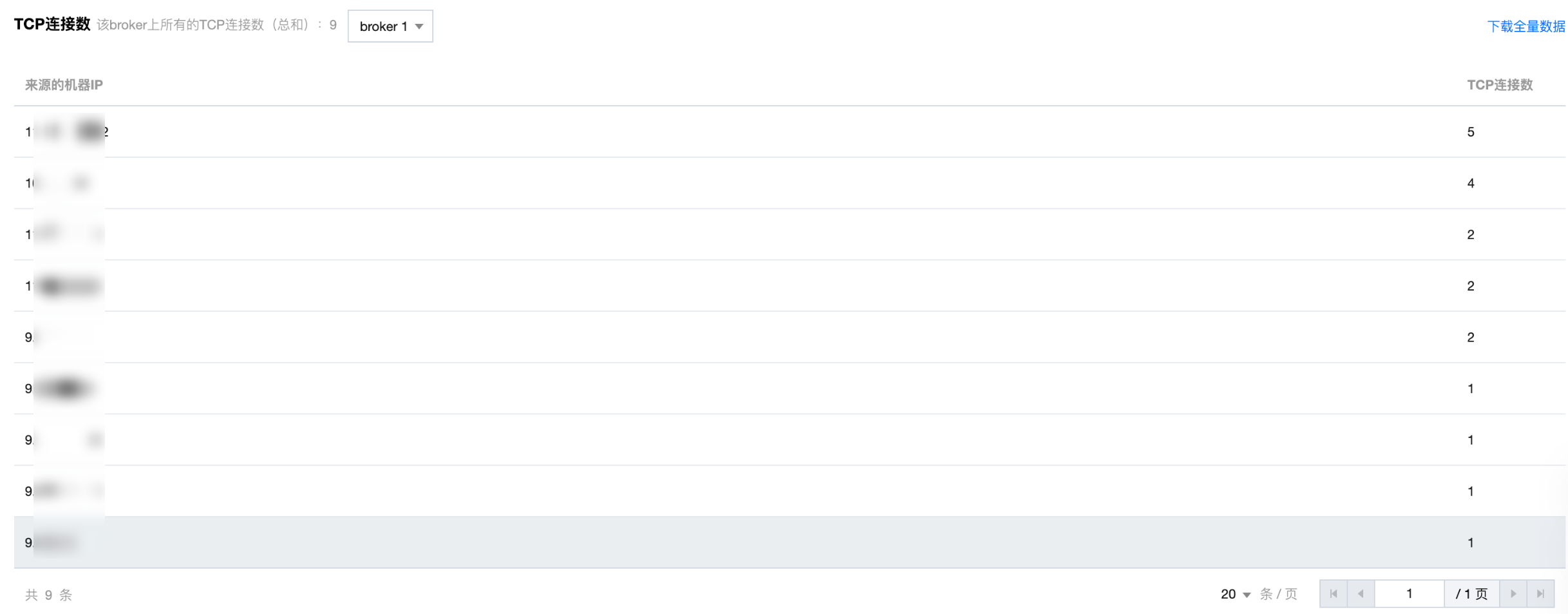
TCP 连接数指标展示 Broker 上所有 TCP 连接的总数,通过下拉框可以切换查看不同 Broker 上的连接情况,当 TCP 连接数 ≤ 500 时,系统支持全量数据下载。
用户可通过此数据快速查看各机器的连接情况,若连接数接近或达到上限,建议优先排查异常连接或扩容实例,避免影响服务可用性。
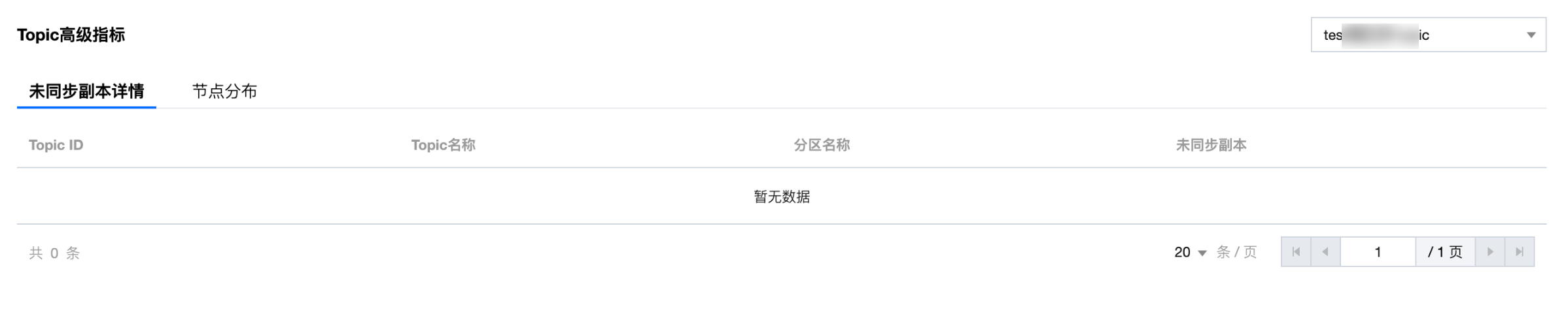
未同步副本详情:展示指定 Topic 的未同步副本详情,用于快速定位副本同步异常的分区,保障数据冗余和可用性。
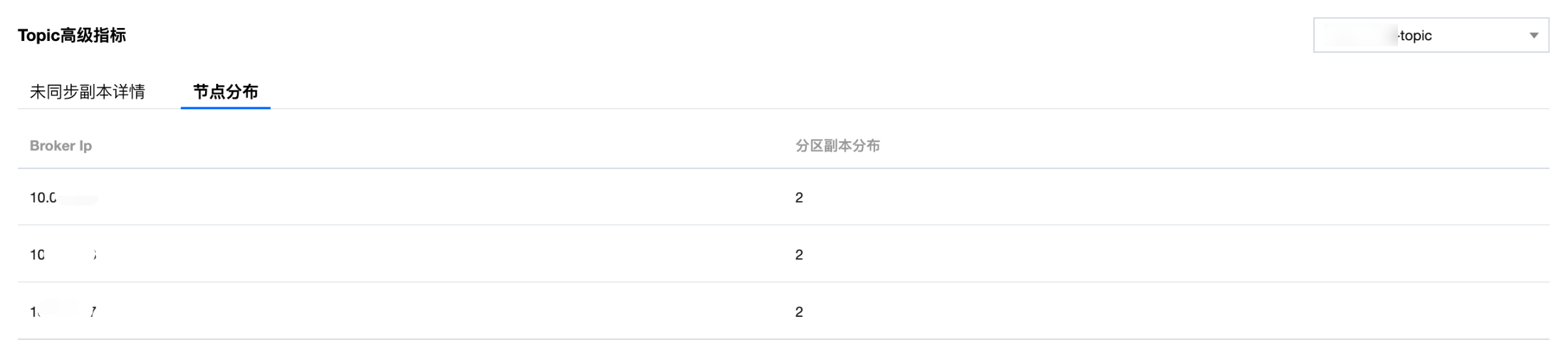
节点分布:展示指定 Topic 的副本在 Broker 节点上的分布情况。该指标可以用于如下场景:
辅助定位副本分布不均匀的 Broker。
用于容灾评估、确保分区副本分散在不同节点。
为集群扩缩容提供数据迁移参考、规划节点增减。
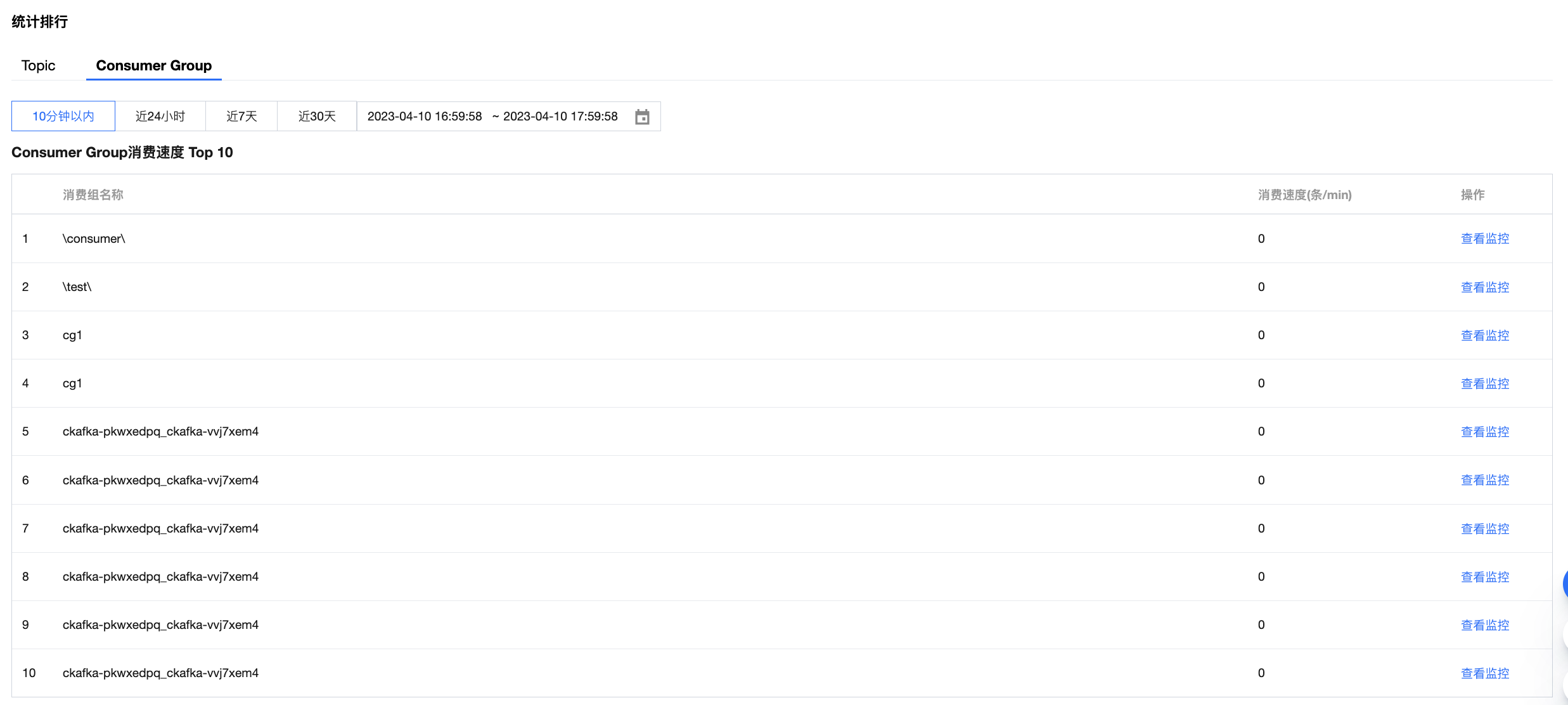
Topic:展示 Topic 生产/消费流量 Top10 和 占用磁盘容量 Top10,并支持查看指定节点的 Topic 统计排行。通过该指标可以快速发现高负载 Topic,定位单节点流量异常或存储过载问题。
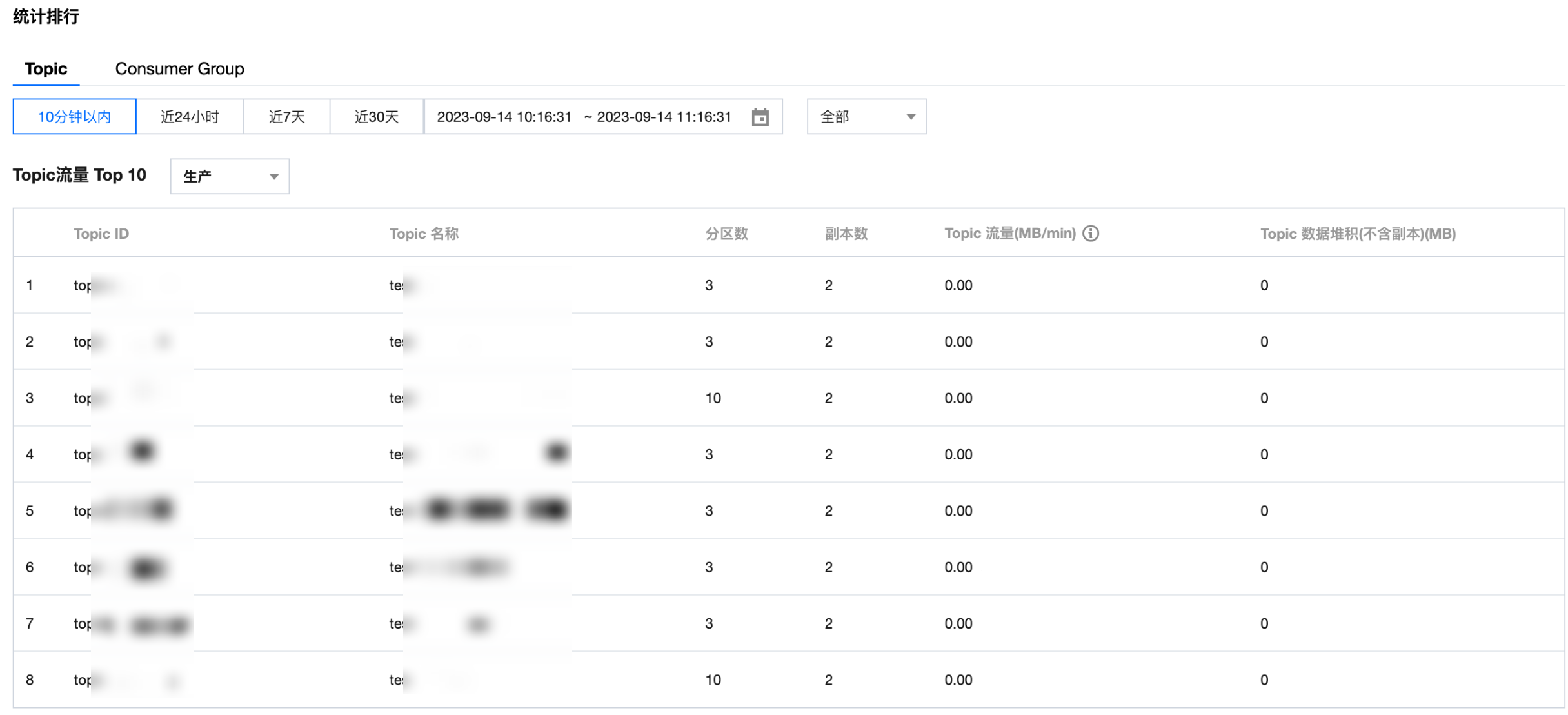
Consumer Group:展示 Consumer Group 消费速度 Top10。通过该指标可以识别高吞吐消费组,定位消费延迟或积压问题,从而进一步优化消费端资源配置。