背景
写入加速是为日志场景特别研发的内核技术,我们知道日志场景的特点主要是高吞吐写入及海量存储,随着数据规模的海量增长,对 ES 写入性能的要求越来越高,ES 原生写入模型想要达到 百 TB/日级别的数据写入需要非常多的资源。日志场景一般给用户带来的收益偏低。这就形成了非常严重的收益与成本的矛盾。因此自研读写分离架构提升写入性能,降低计算成本。
优化方案
原生写入架构的弊端:
1. 副本冗余写入:从副本上的写入计算开销冗余(解析文档、分词等)。
2. 读写资源耦合:读写资源相互争抢,影响集群稳定性。
3. 分片长尾效应:当某一个分片执行较慢时就会拖累整体的写入吞吐。
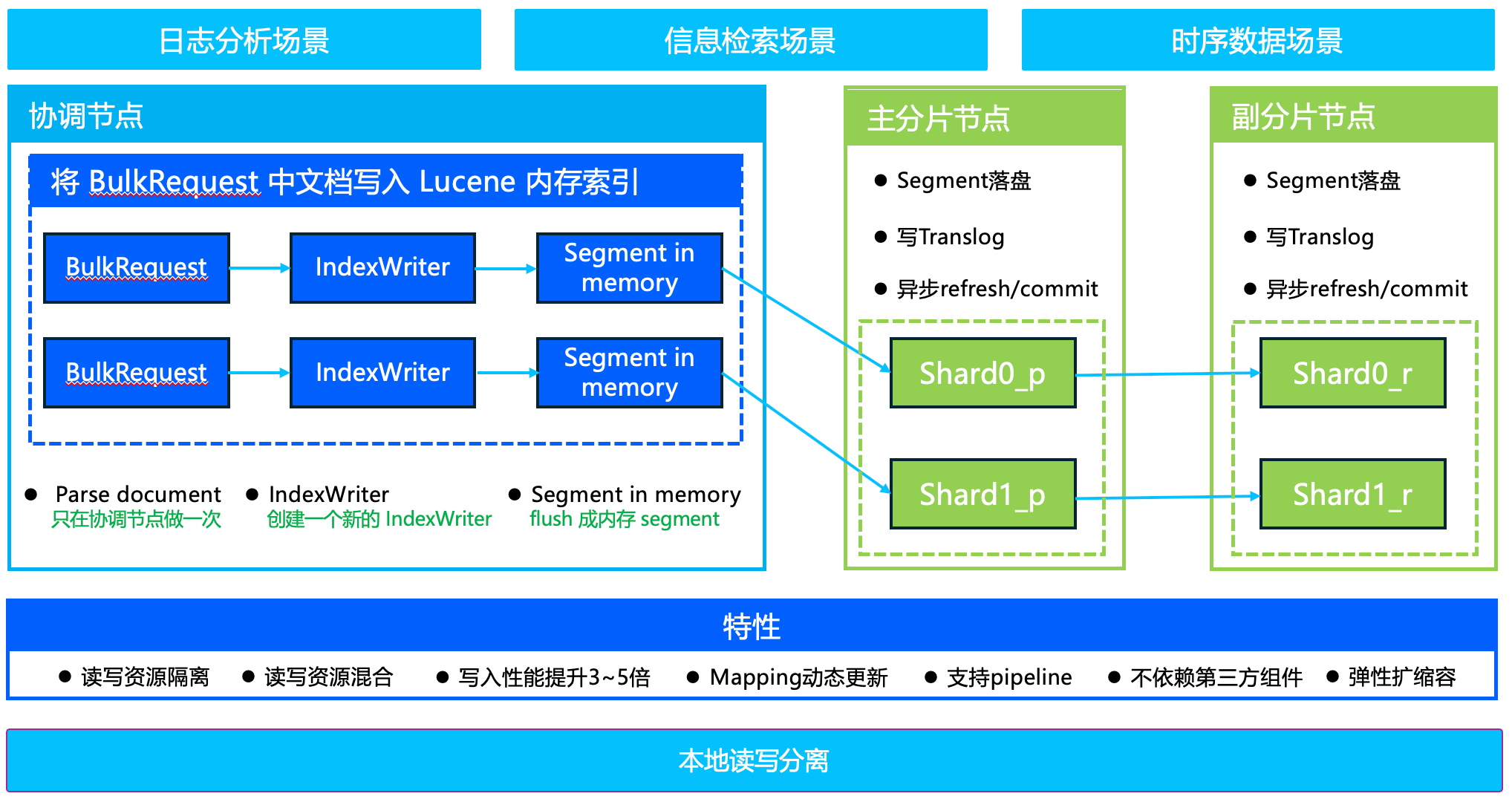
读写分离架构:
ES 写入数据时最终是通过 Lucene 写入到内存中,一段时间后 refresh 成 segment。我们可以在协调节点提前通过 Lucene 的 API 构建好 segment 并保存在内存中,然后把内存 segment 转发给具体索引分片,索引分片收到内存 segment 后定时追加到 Lucene 中,通过 segment 内存生成和拷贝,内存 merge,自定义 merge policy、定向路由等亮点思想和技术,提升写入吞吐3 - 5倍。
使用方法
创建新索引
索引创建时指定为读写分离类型(静态参数):"index.fast-indexing.enabled": true
PUT ${index}{"settings":{"index.fast-indexing.enabled": true}}
存量索引
由于 index.fast-indexing.enabled 参数是静态参数,对于已经创建好的存量索引,更改为读写分离类型的步骤如下:
1. POST ${index}/_close
2. 打开读写分离。
PUT ${index}/_settings{"index.fast-indexing.enabled": true}
3. POST ${index}/_open
使用限制
由于读写分离是提前在协调节点创建 segment,是将一次 bulk 请求内的所有文档都写入到同一个分片内,因此有如下限制:
1. 建议单个 bulk 请求大小一般在5 - 15mb。
2. 不支持文档更新和删除。
3. 自定义 ID 和 routing 将不生效。
4. GET ${index}/_doc/${id} 接口不生效。
优化效果
1. 不带副本:写入性能提升1 - 3倍。
2. 带副本:写入性能提升3 - 5倍。
3. 弹性扩缩容:可设置部分节点为专属协调节点,扩缩容专属协调节点即可实现计算资源的弹性扩缩容,无需数据搬迁。
支持版本
日志增强版。



