本文主要介绍了从 mysql 数据库采集数据到流计算服务 Oceanus 进行分析,最后输出到 ElasticSearch 服务的实践。本方案可作为日志搜索场景解决方案使用。使用了云数据库 MySQL、流计算 Oceanus、Elasticsearch、Kibana 和私有网络 VPC。
环境搭建
创建 Oceanus 集群
说明
若之前未曾使用过私有网络 VPC、日志 CLS、对象存储 COS 等组件,需要先进行创建。
新建集群时,私有网络 VPC 及子网选择需和下文的 MySQL、ES 集群相同,否则需要手动打通(例如对等连接)。
创建完后的集群如下:
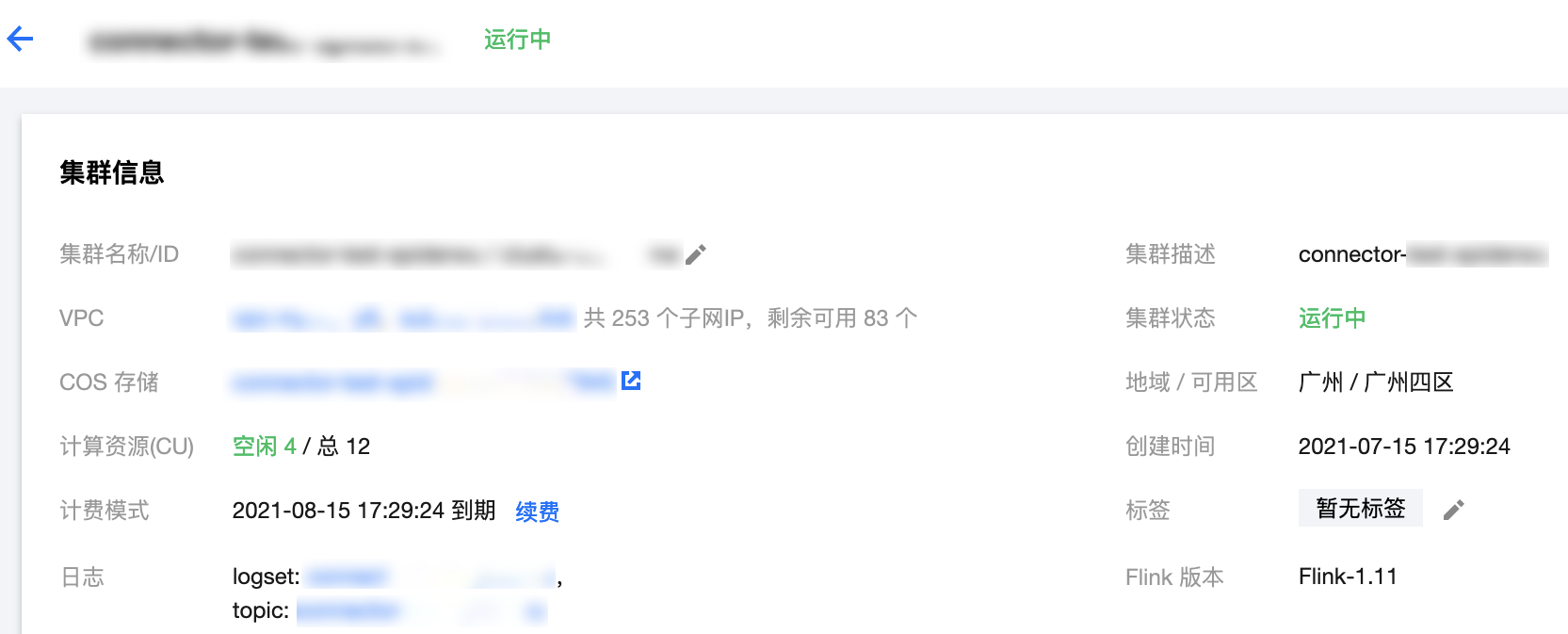
创建 MySQL 集群
binlog_row_image=FULL
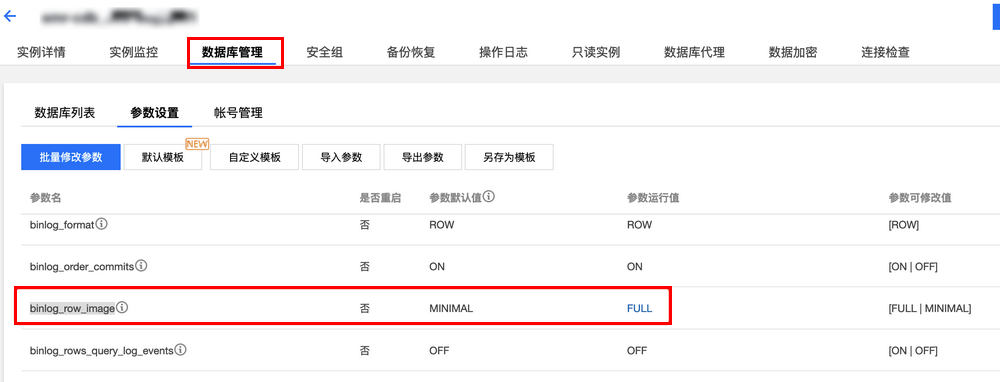
在 MySQL 数据库中创建表
执行如下 sql,或通过可视化页面创建数据库,创建表。
-- 创建数据库create database test;-- 以学生成绩表为例CREATE TABLE `cdc_source4es` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '学号',`score` int(11) NOT NULL COMMENT '分数',PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8 COMMENT='create for student score'
并在表中插入几条数据。
insert into cdc_source4es values(1, 99);insert into cdc_source4es values(2, 88);insert into cdc_source4es values(3, 77);
创建 ElasticSearch 集群
在 Elasticsearch Service 控制台 中,单击新建,创建 Elasticsearch Service 集群。建议选择与 Oceanus 相同地域、可用区和网络。文本以 Elasticsearch 7.5.1 版本的集群为例。
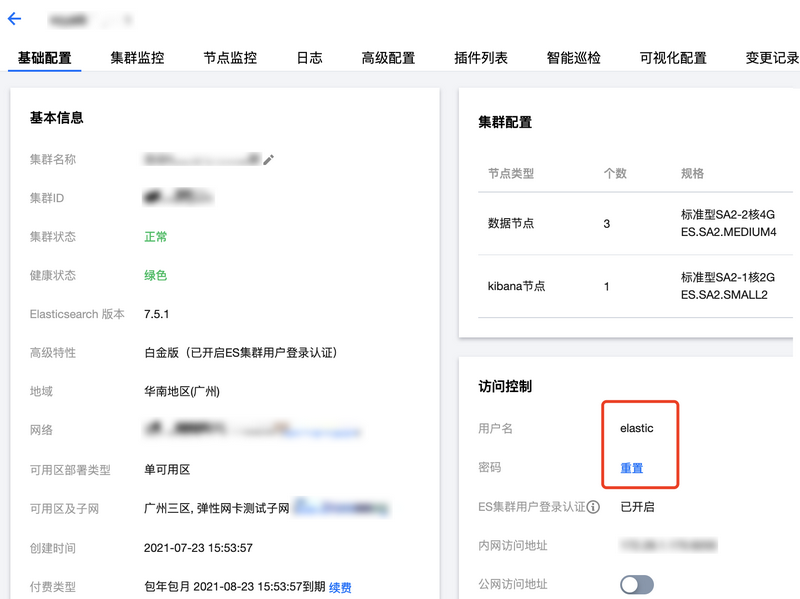
说明
Elasticsearch Service 中无需提前创建类似表的实体。
# 查看集群节点GET _cat/nodes
# 返回节点信息则为正常172.28.1.1 43 99 1 0.06 0.06 0.12 dilm - 1627027760001130832172.28.1.2 65 99 3 0.03 0.12 0.13 dilm - 1627027760001130732172.28.1.3 29 99 3 0.08 0.08 0.12 dilm * 1627027760001130632
作业创建
创建 SQL 作业
在 流计算 Oceanus 控制台 的作业管理 > 新建作业中新建 SQL 作业,选择在新建的集群中新建作业。然后在作业的开发调试 > 作业参数中添加必要的 connector,如 mysql-cdc connector、elasticsearch6/7 connector。
注意
ES connector 版本要与购买的 ES 组件版本一致。
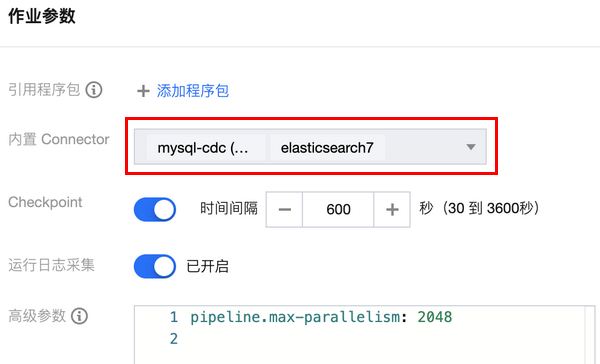
创建 Source 端
选择 mysql 作为数据源,并将后续的数据持续更新到 ES 中。
-- mysql-cdc connectorCREATE TABLE `mysql_source` (`id` int,`score` int,PRIMARY KEY (`id`) NOT ENFORCED -- 如果要同步的数据库表定义了主键, 则这里也需要定义) WITH ('connector' = 'mysql-cdc', -- 必须为 'mysql-cdc''hostname' = '172.28.28.213', -- 数据库的 IP'port' = '3306', -- 数据库的访问端口'username' = 'youruser', -- 数据库访问的用户名(需要提供 SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT, SELECT, RELOAD 权限)'password' = 'yourpassword', -- 数据库访问的密码'database-name' = 'test', -- 需要同步的数据库'table-name' = 'cdc_source4es' -- 需要同步的数据表名);
创建 Sink 端
Sink 无需在 ES 集群中提前做初始化,可直接写入数据。
-- 注意! 如果您启用了 Elasticsearch 的用户名密码鉴权功能, 目前只能使用 Flink 1.10 的旧语法。若无需鉴权, 则可以使用 Flink 1.11 的新语法。-- 参见 https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/connect.html#elasticsearch-connectorCREATE TABLE es_old_sink (`id` INT,`score` INT) WITH ('connector.type' = 'elasticsearch', -- 输出到 Elasticsearch'connector.version' = '7', -- 指定 Elasticsearch 的版本, 例如 '6', '7'. 注意务必要和所选的内置 Connector 版本一致'connector.hosts' = 'http://172.28.1.175:9200', -- Elasticsearch 的连接地址'connector.index' = 'connector-test-index', -- Elasticsearch 的 Index 名'connector.document-type' = '_doc', -- Elasticsearch 的 Document 类型'connector.username' = 'elastic', -- 可选参数: Elasticsearch 用户名'connector.password' = 'yourpassword', -- 可选参数: Elasticsearch 密码'update-mode' = 'upsert', -- 可选无主键的 'append' 模式,或有主键的 'upsert' 模式'connector.key-delimiter' = '$', -- 可选参数, 复合主键的连接字符 (默认是 _ 符号, 例如 key1_key2_key3)'connector.key-null-literal' = 'n/a', -- 主键为 null 时的替代字符串,默认是 'null''connector.failure-handler' = 'retry-rejected', -- 可选的错误处理。可选择 'fail' (抛出异常)、'ignore'(忽略任何错误)、'retry-rejected'(重试)'connector.flush-on-checkpoint' = 'true', -- 可选参数, 快照时不允许批量写入(flush), 默认为 true'connector.bulk-flush.max-actions' = '42', -- 可选参数, 每批次最多的条数'connector.bulk-flush.max-size' = '42 mb', -- 可选参数, 每批次的累计最大大小 (只支持 mb)'connector.bulk-flush.interval' = '60000', -- 可选参数, 批量写入的间隔 (ms)'connector.connection-max-retry-timeout' = '1000', -- 每次请求的最大超时时间 (ms)--'connector.connection-path-prefix' = '/v1' -- 可选字段, 每次请求时附加的路径前缀'format.type' = 'json' -- 输出数据格式, 目前只支持 'json');
算子操作
下面语法中只做了简单的数据插入,没有进行复杂计算。
-- Flink SQL 进行运算INSERT INTO es_old_sink select id, score from mysql_source;
验证总结
在 Kibana 的 Dev Tools 中查询 ES 中的数据是否插入成功。
# 查询该索引下所有的数据GET connector-test-index/_search



