Setats 是 Oceanus 团队自研的流湖一体统一存储,Setats 的目标是用一套存储同时支撑批写批读、流写流读、状态存储等多种处理模式,并能够实现秒级数据可见性。在传统大数据架构中,数据分析依赖数据湖、消息队列、本地 KV 存储等多套存储系统,这些系统相互割裂,导致数据冗余、运维复杂、成本高昂。Setats 通过统一的存储架构,支持多种不同的数据读写模式,从而消除了多套存储带来的冗余与复杂性。
Setats 目标支持如下使用场景:
能力特点 | 详细说明 |
秒级流写流读 | 数据写入后秒级对下游可见,支持实时变更日志(CDC)订阅,满足低延迟实时数据处理场景需求。 |
高效批写批读 | 全量数据以列存格式持久化到远程存储(COS/HDFS),支持高效的离线批量分析与扫描查询,兼容传统数据湖使用方式。 |
冷热分离行列混存 | Setats 对表内置支持数据分层存储,远程以列存格式高效存储全量数据,本地以行存格式缓存热数据加速数据定写入合并与点查等场景。 Setats 自动管理数据在本地和远程的流转与淘汰,无需手动配置 TTL 或定时刷盘策略,从而对用户无感,并兼顾离线分析的高吞吐与在线查询的低延迟。 |
点查能力 | 支持高效的 Flink Lookup Join,并通过定制客户端支持高性能主键点查和主键前缀查询能力(后续版本发布) |
状态存储 | 支持 Flink Delta Join 等算子状态存储(后续版本发布) |
多索引加速 | 支持二级索引加速数据查询性能(后续版本发布) |
生态兼容 | 兼容 Iceberg 等常用开源湖格式(后续版本发布) |
产品架构
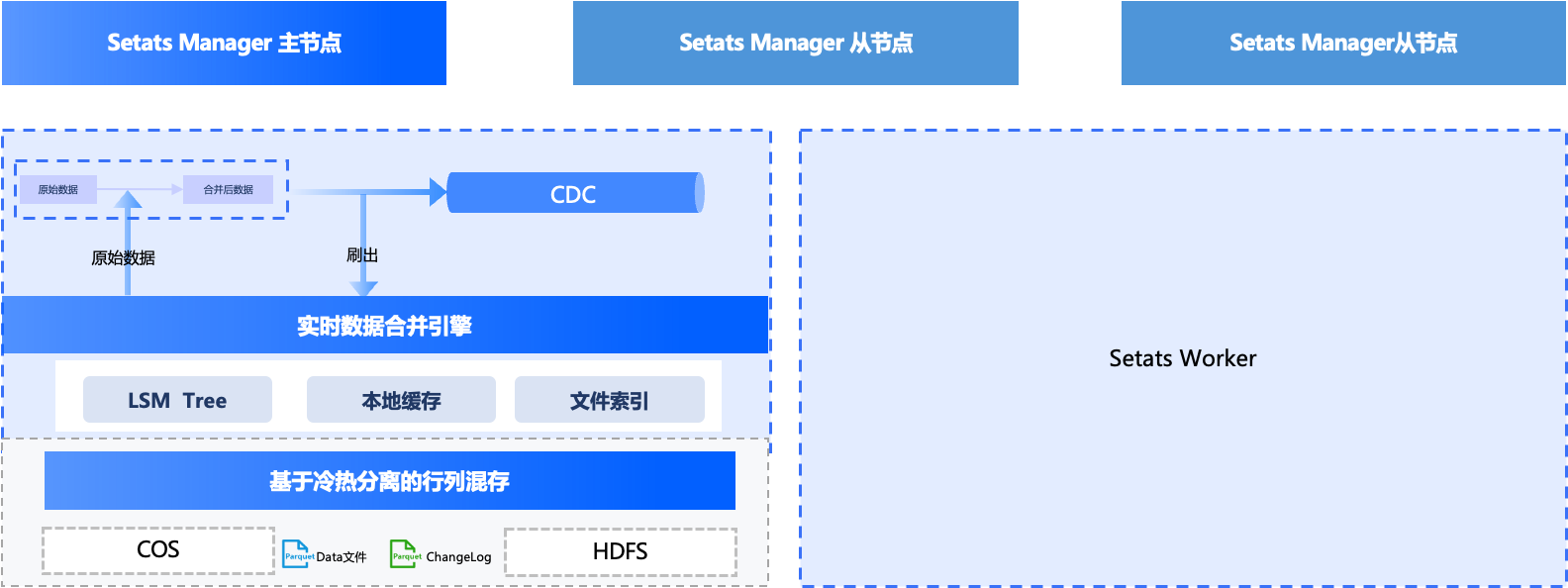
分布式架构
Setats 采用经典的 Manager / Worker 分布式架构。Setats 表数据采用 分区(Partition)+ 分桶(Bucket)两层组织结构:
分区:按照用户指定的分区键对数据进行逻辑划分,支持按时间、业务维度等灵活分区,便于数据生命周期管理与查询裁剪。
分桶:在分区内部,按主键哈希进一步拆分为多个桶,作为数据分布与调度的最小粒度,并可用于主键查询等场景加速。
Manager 节点负责全局的元数据管理、分桶调度与节点协调,支持多副本部署,主节点(Active)与备节点(Standby)之间通过状态同步实现自动故障切换,保障集群管理面的高可用性。Worker 节点以分桶为粒度承担实际的数据读写与存储,每个桶独立管理自己的数据文件与索引,天然支持并行处理与水平扩展,可根据业务负载按需增减 Worker 节点。
即时 Merge-on-Write 数据合并
Setats 支持不同的数据写入语义如部分列更新等,这类写入需要将新数据与历史记录进行合并才能得到完整的最新行;同时 Setats 支持生成完整的 Changelog,即更新操作需要产出包含全字段的 UpdateBefore 与 UpdateAfter,这同样依赖于写入时查询到历史数据。因此,数据合并是 Setats 写入链路中重要环节。
传统数据湖通常采用批量写入后定期合并(Merge-on-Read / 定期 Compaction)的策略,数据写入后需要等待后台合并调度完成才能对下游可见,可见性延迟通常在分钟级甚至更长。而 Setats 需要支持秒级数据可见性,因此采用了一种即时数据合并策略:数据写入后,首先通过 Lookup 操作按主键查找对应的历史数据,并立即完成新旧数据的合并——例如 Partial Update 场景下将新写入的部分列与历史记录的其余列拼接为完整记录。合并完成后,最新的完整数据写入内存缓冲区,同时产生对应的 Changelog 供下游实时订阅。缓冲区中的数据会定期异步写入远程存储(COS/HDFS)进行持久化。查询端通过综合本地缓冲区中的最新数据与远程存储中的历史数据,实现秒级数据可见。
对于相同主键数据多次写入,Setats 整体采用 Merge-on-Write 策略:在 Lookup 历史数据的过程中,同时定位旧版本记录的存储位置并生成删除向量(Deletion Vector),将旧版本标记为失效。这样在查询时,只需根据删除向量过滤已失效的记录即可,无需再执行耗时的合并操作,大幅降低了读取端的开销。
冷热分离行列混存
为了支持快速 Lookup 操作。Setats 在存储架构上采用冷热分离的行列混合存储架构来应对这一挑战。
全量数据以列存格式(如 Parquet)持久化到远程存储(COS/HDFS),满足离线分析场景下的高吞吐批量扫描需求并降低整体存储成本。
热数据以行存格式缓存在本地内存与磁盘中,保障即时合并时历史记录的高效查询,同时支持低延迟的主键点查等场景。当行存缓存未命中时,Setats 支持直接基于远程列存文件进行高效点查,并同时在后台将热点数据加载到缓存中,避免等待文件格式转换造成的阻塞,降低查询的整体延迟。
系统在元数据层通过 LSM Tree、Bloom Filter、Min-max 等索引与批量操作进一步加速 Lookup 的性能。
高性能数据读写引擎
为了支持高性能秒级延迟的数据读写,Setats 实现了一套基于全异步的高性能数据读写引擎。单条数据处理过程中的 I/O 操作(如读取本地或远程文件)不会阻塞后续数据的处理,多条数据的合并流程可以并发执行,从而最大化 CPU 利用率,避免 CPU 空转等待 I/O 返回。该设计在大规模即时合并场景下尤为关键,使得 Setats 在保持秒级可见性的同时,仍能维持高写入吞吐。
多引擎对接
Setats 提供了一个统一的数据存储层,支持流式读写、批量读写、主键检索等不同访问模式。Setats 通过一个开放格式支持多种计算引擎的读写与查询,包括 Flink、Spark、Doris、StarRocks 等。通过统一的 Catalog 和表接口,不同的计算引擎可以无缝访问 Setats 中的数据。
运维支持
Setats 服务提供运维管理能力,帮助用户高效管理集群与数据:
监控告警:内置多维度的集群与表级监控指标(如写入吞吐、读取延迟、缓冲区使用率、远程存储读写量等),支持对接主流监控告警平台,实现异常状态的实时感知与及时告警。
Setats UI:提供可视化管理界面,支持查看表的元信息、分区与分桶分布、数据量统计,以及各 Worker 节点的运行状态、资源使用与分桶分配情况,便于运维人员快速定位问题与评估集群健康状况。



