用户可以在 SQL 作业中的库表管理使用变量。SQL 作业的临时表和元数据表都可以通过表变量替换对使用变量进行替换。
表变量语法:
${变量名称}${变量名称:默认值}${变量名称}:默认值注意
变量名称分隔符用下划线
_ 。推荐使用${变量名称}这种语法。新建变量
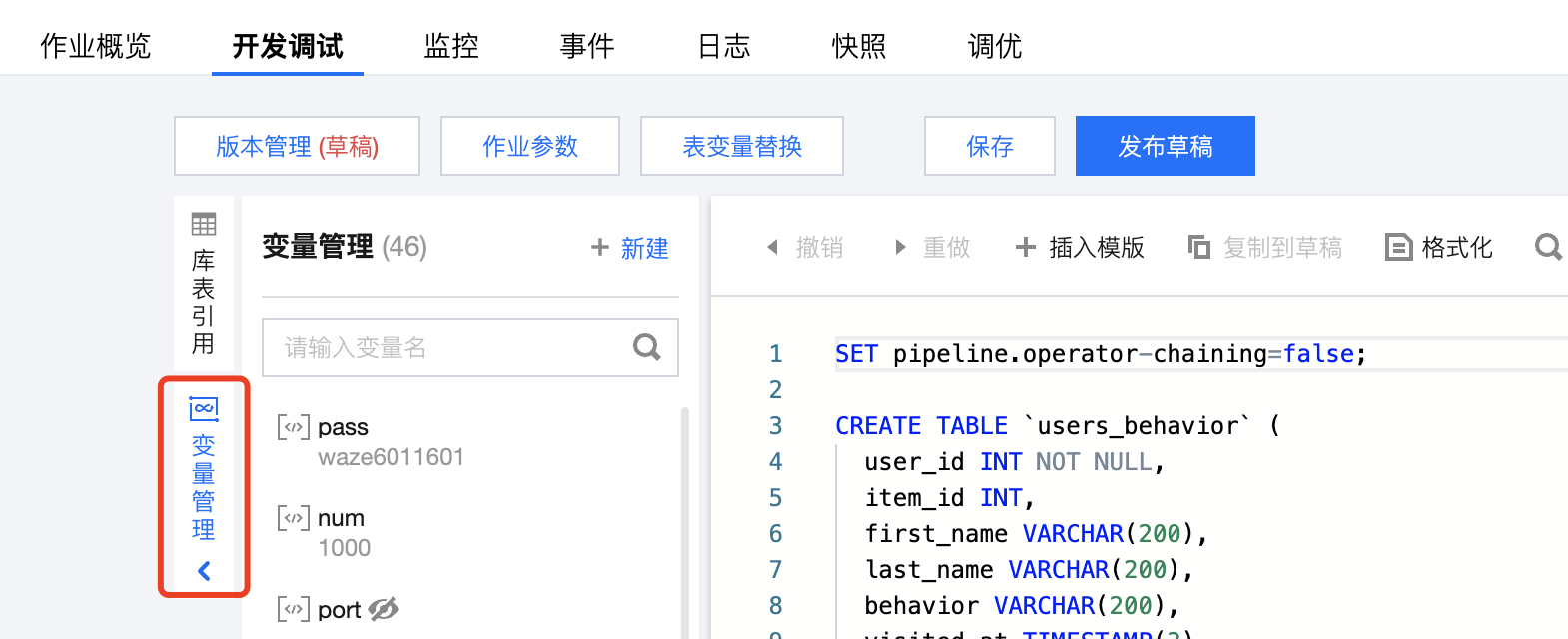
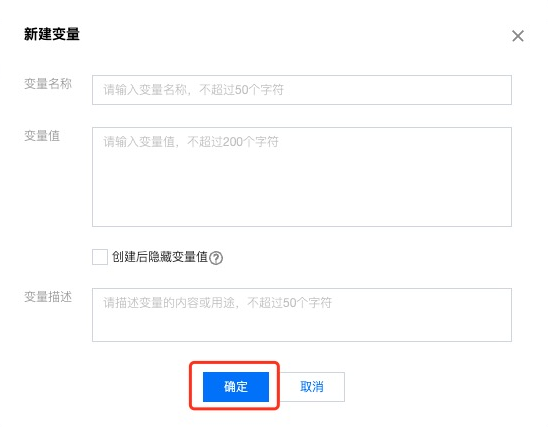
在变量管理功能界面中,选择右上角的新建,在弹窗中填写变量信息,然后单击确定。
数据表中引用全局变量
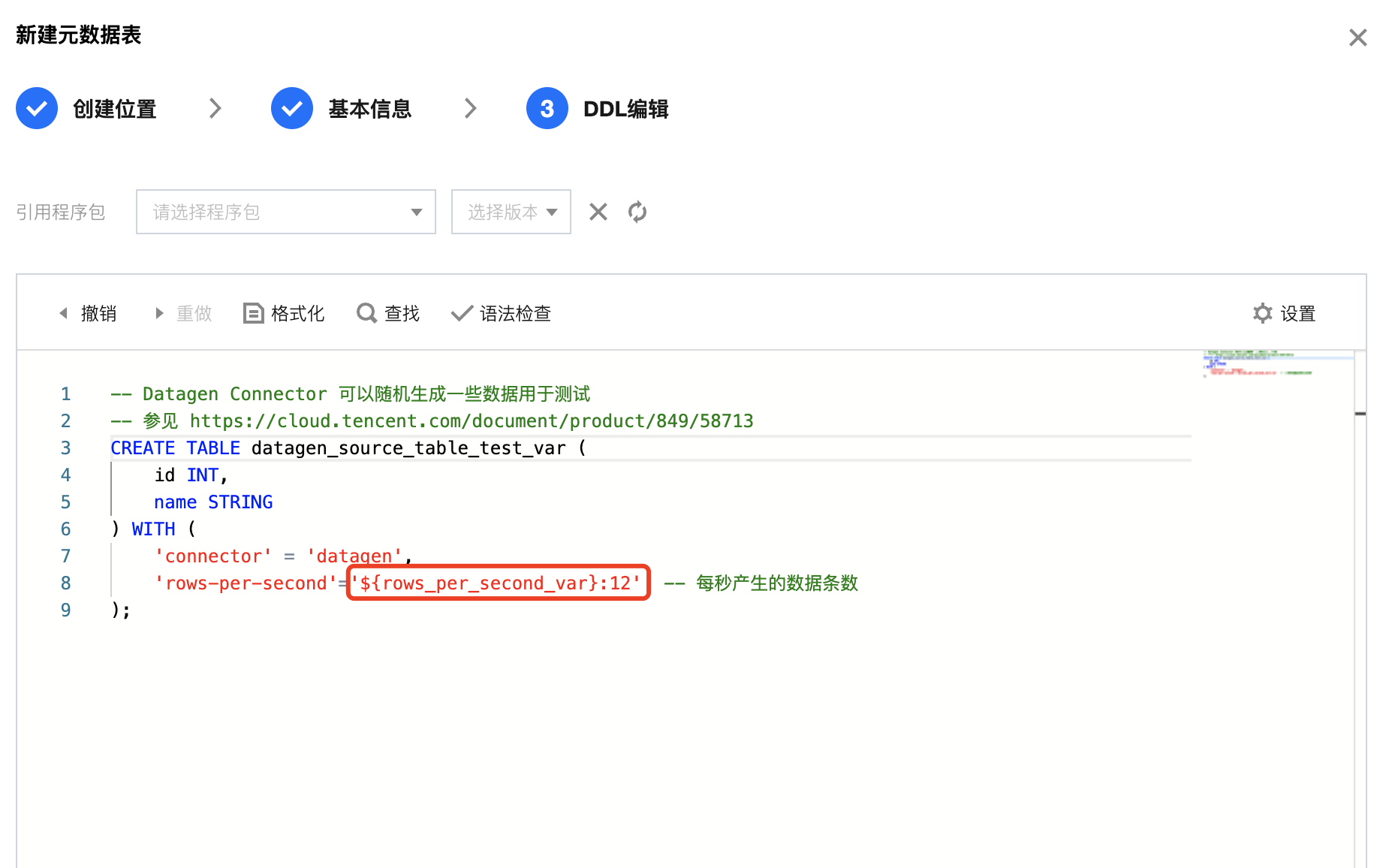
在库表引用功能界面中,选择右上角的新建 > 数据表,在弹窗中选择 Catalog 和 Database,然后单击下一步,进入选择创建元表的方式,可使用模板、自定义、云资源。如果选择自定义或者云资源,则需输入相应的连接信息。在 WITH 参数中设置表变量并点击完成,表变量命名规则参考 库表管理。
引用多个全局变量
注意:
引用多个变量,可以使用
${变量名称}或${变量名称:默认值}样式进行拼接。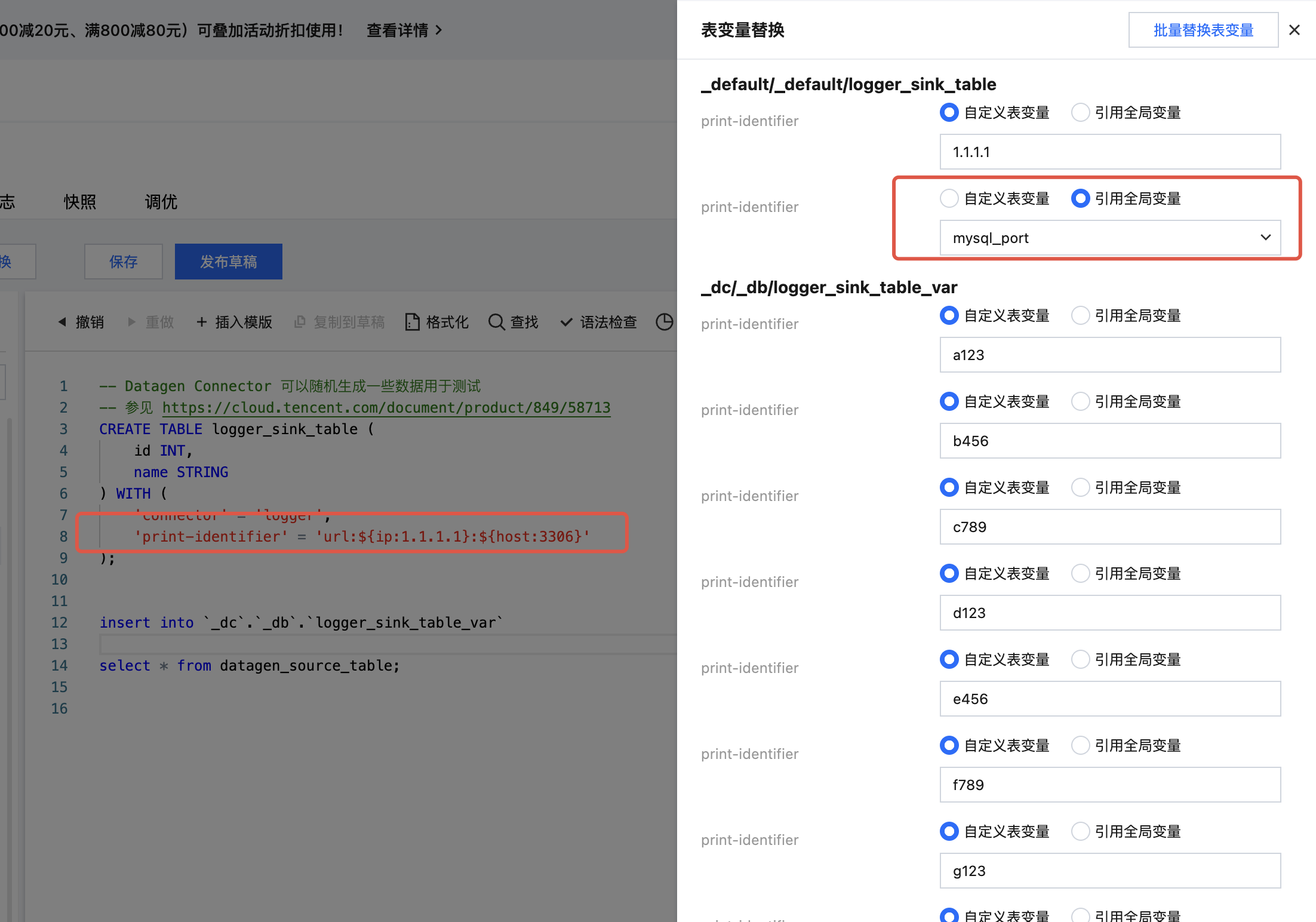
SQL 作业引用全局变量
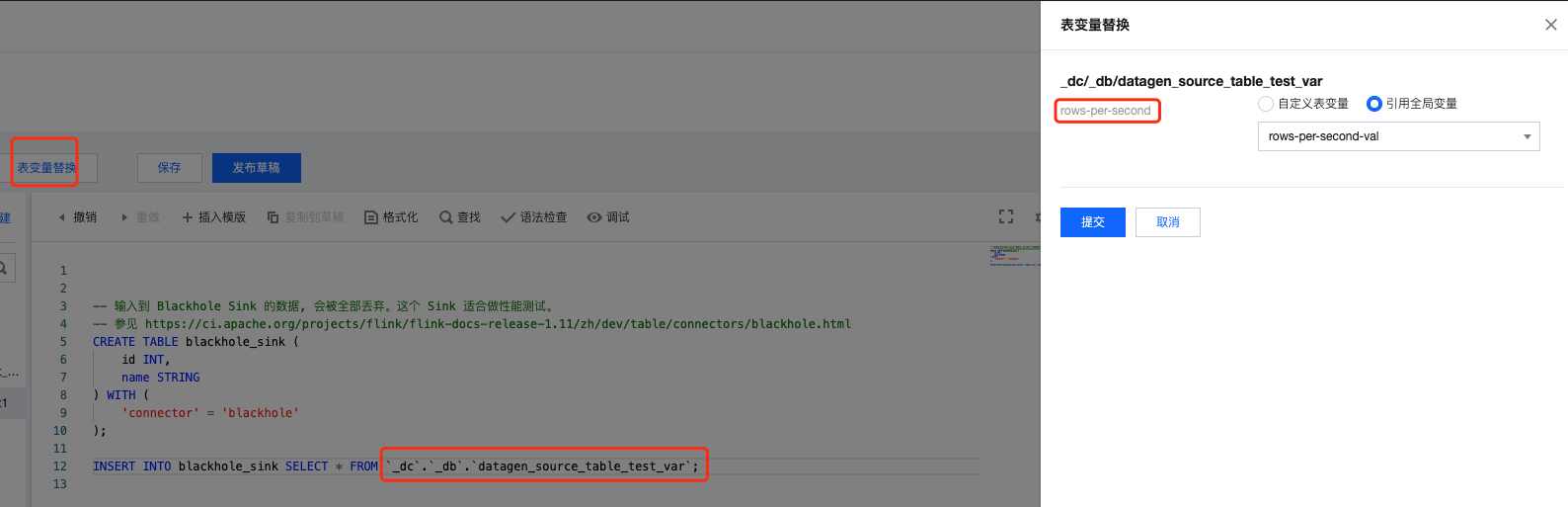
在 SQL 作业中可以直接引用全局变量,单击表变量替换,右侧会显示操作菜单,单击引用全局变量,最后单击提交。
系统变量
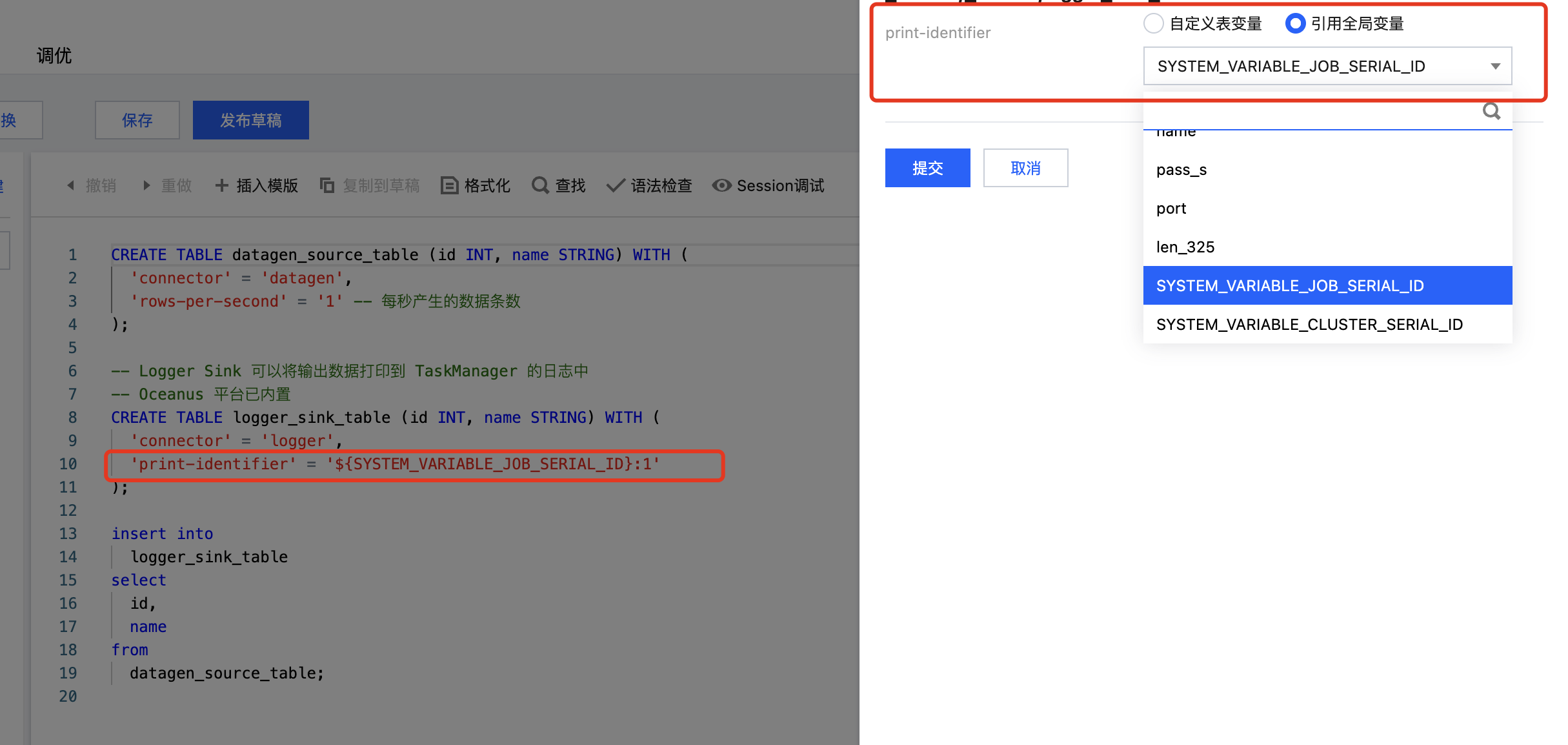
将以下变量替换为真实的 job_id 和 cluster_id
${SYSTEM_VARIABLE_JOB_SERIAL_ID}:xx${SYSTEM_VARIABLE_CLUSTER_SERIAL_ID}:xx
全局 SQL 变量
注意
全局 SQL 变量与表变量不同,表变量仅作用于数据表的 WITH 参数中,而全局 SQL 变量可以在 SQL 编辑器中的任意位置使用,包括 DDL 语句、DML 语句中的字段名、表名、参数值等。
变量语法
与表变量一致:
${变量名称}${变量名称:默认值}注意
变量名称分隔符用下划线
_ 。推荐使用${变量名称}这种语法。在 SQL 中引用
在 SQL 编辑器中,直接使用
${变量名称} 语法引用。变量会在作业保存/发布时被替换为实际值。SET pipeline.operator-chaining = ${chaining_enabled};CREATE TABLE source (id INT,name STRING) WITH ('connector' = 'datagen','rows-per-second' = '${rows_per_second}');INSERT INTO sink SELECT * FROM source;
动态表达式变量
全局 SQL 变量支持动态表达式,变量值会在作业保存/发布时动态计算。
-- 使用日期工具获取当天日期CREATE TABLE sink (id INT,dt STRING) WITH ('connector' = 'filesystem','path' = '/data/${dateUtil.today()}');-- 使用 UUID 工具生成唯一标识INSERT INTO sink SELECT id, '${IdUtil.simpleUUID()}' FROM source;
工具类前缀 | 对应 Hutool 类 |
dateUtil | cn.hutool.core.date.DateUtil |
idUtil | cn.hutool.core.util.IdUtil |
randomUtil | cn.hutool.core.util.RandomUtil |
strUtil | cn.hutool.core.util.StrUtil |
注意:
仅上述 4 个工具类前缀在白名单中,使用其他前缀的表达式会被跳过,保持原样输出。



