背景信息
用户通常需要花费大量的时间对作业进行调优。例如新上线一个作业时,需要考虑如何配置该作业的并行度、TaskManager 个数、TaskManager CU 数等。此外,作业运行过程中,还需要考虑如何调整作业资源配置,提升作业的资源利用率;而作业出现反压或延时增大的情况时,需要考虑增大作业资源配置等。
Oceanus 提供的自动调优功能,可以帮助用户更合理地调整作业并行度和资源配置,全局优化您的作业,解决作业吞吐量不足、作业繁忙以及资源浪费等各种性能调优问题。
使用限制
作业自动调优功能支持 SQL 和 JAR 作业。
自动调优无法解决流作业本身的性能瓶颈。
因为调优策略对作业的处理模式是基于一定的假设的。例如,流量平滑变化、不能有数据倾斜、每个算子的吞吐能力能够随并发度的升高而线性拓展。当业务逻辑严重偏离以上假设时,作业可能会存在异常。如果作业本身存在问题,您需要进行手动调优。常见的作业异常如下:
无法修改作业并发度。
作业不能达到正常状态、作业持续重启。
自定义函数 UDF 性能问题。
数据严重倾斜。
自动调优无法解决外部系统导致的问题。
外部系统故障或访问变慢时,会导致作业并行度增大,加重外部系统的压力,导致外部系统雪崩。如果出现外部系统问题,您需要自行解决。常见的外部系统问题如下:
源头消息队列分区数不足或吞吐量不足。
下游 Sink 性能问题。
下游数据库死锁。
操作步骤
1. 登录 流计算 Oceanus 控制台,在作业管理中,切换到调优页面的自动调优页面。
2. 单击自动调优开关,在弹窗中单击确定,即可开启自动调优功能。
3. 单击调优配置右侧的编辑后,修改自动调优相关参数。(如果页面不合符,说明集群不支持,如果需要,可以 联系我们)
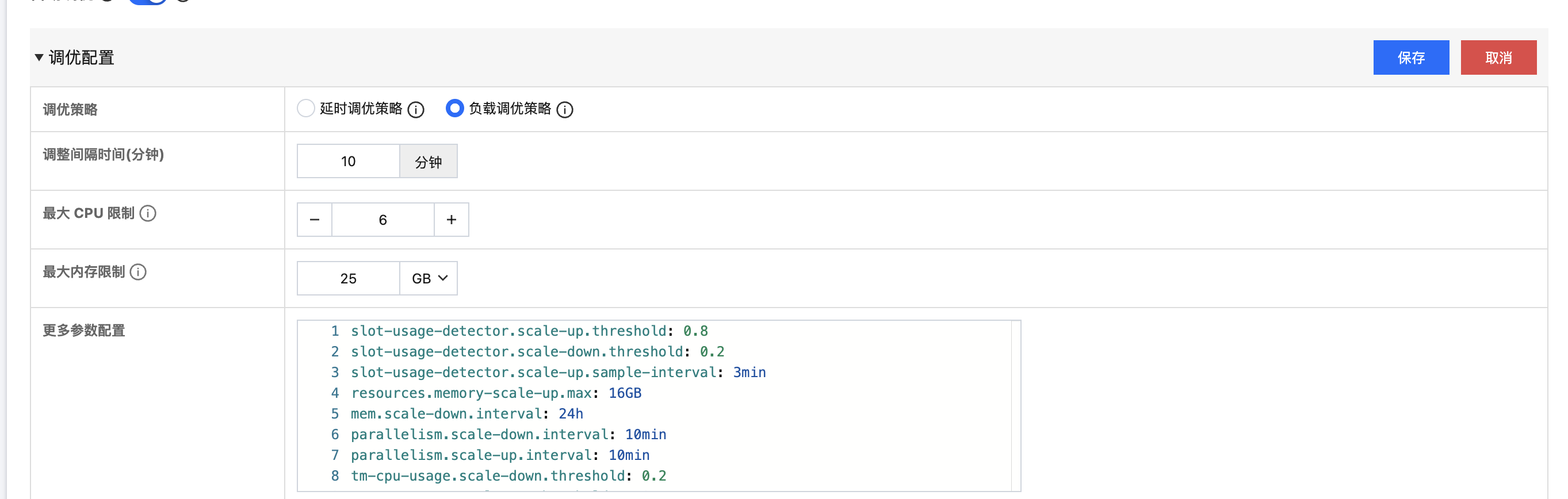
参数 | 说明 |
调优策略 | 负载调优策略:通过应用该策略,系统会监控作业的负载情况,根据负载情况,自动的调整作业的资源。 延时调优策略(默认):在负载调优策略的基础上,增加了对消费数据源头的延迟的监控,当消费数据源头的延迟达到设定的时间后,会自动的增加作业的并行度,以降低 source 延迟。 负载调优策略 |
调整间隔时间(分钟) | 两次调优之间间隔的时间。 |
最大 CPU 限制 | 该作业最多可使用的 CPU 数量。 |
最大内存限制 | 该作业最多可使用的内存。 |
更多参数配置 | 可使用一些额外配置改变自动调优的默认配置,可参考后面的更多参数。 |
自动调优默认规则
如果您开启了自动调优,则系统默认会从并发度和内存两个方面为您进行自动调优:
自动调优会调整作业的并发度来满足作业流量变化所需要的吞吐。
自动调优会监控消费源头数据的延迟变化情况、TaskManager(TM) CPU 实际使用率和各个算子处理数据能力来调整作业的并发度。详情如下:
基于延迟的策略模式:
作业延迟 Delay 指标正常,不修改当前作业并发。
作业延迟 Delay 指标超过默认阈值60s,分以下两种情况来调整并发度:
延迟正在下降,不进行并发度调整。
延迟增加并且连续上升3分钟, 默认调整作业并发度到当前实际TPS的两倍,但不超过设置最大的资源(默认为4 CPU和16GB)。
基于负载的策略模式:
作业某 VERTEX 节点(包括 Source 节点)连续 3 分钟实际处理数据时间占比超过80%,调大作业并发度使得 VERTEX 使用率降低到50%,但不超过设置最大的资源(默认为4 CPU和16GB)。
所有 TaskManager 的最大 CPU 使用率连续24小时低于20%,且所有 VERTEX 的实际处理数据时间低于20%时,调低作业的并发度。
作业所有 TaskManager 的 CPU 使用率连续 10 分钟超过 80%,将作业默认并行度调高为原来的一倍,但作业运行 CU 数不超过设置最大的资源(默认为4 CPU和16 GB)。
自动调优也会监控作业的内存使用情况,来调整作业的内存配置。详情如下:
在某个 TM 内存使用率超过95%时,会调大 TM 的内存。将 TaskManager 内存调高为原来的一倍。
作业所有 TaskManager 的堆内存使用率连续 24 小时低于 30% 时,将 TaskManager 内存调低为原来的一半。
注意:
旧集群还是会使用这个旧版本的默认调优规则,只有新集群才是这个默认调优规则。
旧版本的默认调优规则
开启自动调优后,Oceanus 会自动调整作业并行度和 TaskManager CU(内存和 CPU) 数这两个配置,对作业进行优化。
1. 自动调优会调整作业并行度来满足作业流量变化所需要的吞吐。自动调优会监控 TaskManager CPU 使用率和各个算子处理数据能力来调整作业的并发度。详情如下:
作业所有 TaskManager 的 CPU 使用率连续 10 分钟超过 80%,将作业默认并行度调高为原来的一倍,但作业运行 CU 数不超过设置最大的资源(默认为 64 CU)。
作业任意一个 Vertex 节点连续 10 分钟处理数据时间占比超过 80%,将作业默认并行度调高为原来的一倍,但作业运行 CU 数不超过设置最大的资源(默认为 64 CU)。
作业所有 TaskManager 的 CPU 使用率连续 4 小时低于 20%,并且所有 Vertex 节点 4 小时内处理数据时间占比均低于 20% 时,将作业默认并行度调低为原来的一半,最小降低到 1。
2. 自动调优也会监控作业的 TaskManager 内存使用情况来调整作业的内存配置。详情如下:
作业所有 TaskManager 的堆内存使用率连续 1 小时超过 80%,将 TaskManager CU 数调高为原来的一倍。
作业所有 TaskManager 的堆内存使用率连续 4 小时低于 30% 时,将 TaskManager CU 数调低为原来的一半。
注意:
旧集群还是会使用这个旧版本的默认调优规则。
作业并行度最小降低到 1。TaskManager CU 数根据集群是否开启细粒度资源可以有不同的配置,开启细粒度资源则 CU 数可以为 0.25、0.5、1、2,否则 CU 数只能为 1。
更多参数配置(仅新集群)
slot-usage-detector.scale-up.threshold:监控数据处理节点空闲时间,当 VERTEX 处理数据时间占比持续大于该值时,触发调大并发度的操作,以提升资源的使用,默认值为0.8。
slot-usage-detector.scale-down.threshold:监控数据处理节点空闲时间,当 VERTEX 处理数据时间占比持续小于该值时(需同时满足TM的CPU均同时小于其阈值),触发调小并发度的操作,以降低资源的使用,默认值为0.2。
slot-usage-detector.scale-up.sample-interval (单位可选min、h):监控 slot 空闲指标的时间间隔,以便计算该时间间隔的平均值。默认值为3分钟,与 slot-usage-detector.scale-up.threshold 结合使用。当3分钟内的空闲时间平均值大于0.8,则进行 scale-up。
tm-cpu-usage.scale-up.threshold:监控 TM 的 CPU 使用率,当 CPU 的使用率在设置的时间内均超过阈值时,触发调大并发度的操作,默认值为0.8。
tm-cpu-usage.scale-down.threshold:监控 TM 的 CPU 使用率,当 CPU 的使用率在设置的时间内均低于阈值时(需同时满足vertex的处理时间占比均同时小于其阈值),触发缩小并发度的操作,默认值为0.2。
tm-memory-usage.scale-up.threshold:监控 TM 的 内存使用率,当内存的使用率超过阈值时,立即触发增加内存一倍的操作,默认值为0.95。
tm-memory-usage.scale-down.threshold:监控 TM 的 内存使用率,当内存的使用率在24小时(默认值)均低于國值时,触发减少一半内存的调优操作,默认值为0.3。
mem.scale-down.interval (单位可选min、h):调低内存时最小触发时间间隔,默认值为24小时。24小时内,检测内存使用率如果小于阈值,则会降低内存,或建议降低内存。
parallelism.scale-down.interval (单位可选min、h):调低并行度的最小触发时间间隔。默认值为24小时。24小时内,检测内存使用率如果小于阈值,则会降低内存,或建议降低内存。
parallelism.scale-up.interval (单位可选min、h):调高并发度触发时间间隔。默认值为10 分钟。10 分钟内,检测内存使用率如果小于阈值,则会降低内存,或建议降低内存。
说明:
mem.scale-down.interval、parallelism.scale-down.interval、parallelism.scale-up.interval 的时间还会受制于作业调优间隔时间,即假如parallelism.scale-up.interval 设置为5分钟,就会监控作业5分钟的指标变化来决定是否触发并行度扩容,但是由于作业调优间隔默认是10分钟,它会延后5分钟执行。
parallelism.scale.max:并发度向上调整时,最大并发限制。默认值为-1,表示最大并发没有限制。
parallelism.scale.min:并发度向下调整时,最小并发限制。默认值为1,表示最小并发为1。
resources.memory-scale-up.max (单位GB):单个 TM 调优最大内存,默认值是16GB。
注意:
1. 调整并发度的检测时间:
1.1 TM 的 CPU 使用率导致的扩缩容检查时间与 parallelism.scale-down.interval、parallelism.scale-up.interval 相关。
1.2 Vertex 的扩容检测时间与 slot-usage-detector.scale-up.sample-interval 相关;缩容检测时间与 parallelism.scale-down.interval 相关。
2. 调整内存的检测时间与 mem.scale-down.interval 相关。
示例
slot-usage-detector.scale-up.threshold: 0.8slot-usage-detector.scale-down.threshold: 0.2slot-usage-detector.scale-up.sample-interval: 3minresources.memory-scale-up.max: 16GBmem.scale-down.interval: 24hparallelism.scale-down.interval: 10minparallelism.scale-up.interval: 10mintm-cpu-usage.scale-down.threshold: 0.2tm-cpu-usage.scale-up.threshold: 0.8tm-memory-usage.scale-up.threshold: 0.95tm-memory-usage.scale-down.threshold: 0.3parallelism.scale.max: -1parallelism.scale.min: 2
注意事项
自动调优功能为目前处于公开测试阶段(Beta 版本),暂不建议对重要的生产任务开启自动扩缩容。
自动调优触发后需要重启作业,因此会导致作业短暂停止处理数据。大状态的作业由于启停过程耗时较长,可能导致长时间停流,不建议开启自动扩缩。
连续两次自动调优触发间隔默认为10分钟。
如果用户为 Jar 类型的作业开启了自动调优,请确认作业代码中未配置作业并行度,否则自动扩缩容将无法调整作业资源,即自动调优配置无法生效。如果作业代码中配置作业并行度想让调优生效,可在作业参数 > 高级参数中设置参数忽略代码中配置作业并行度,以作业参数中并行度为准。
execution.parallelism.disabled: true
由于集群资源限制,当前作业自动调优过程为并行执行,但是因为集群资源有限,太多作业一起调优,可能会出现问题,因此不要为集群中所有作业开启自动调优,否则会相互影响。



