服务部署与启动异常
资源/显存/内存不足类
如何解决在线服务实例处于"等待中"无法启动?
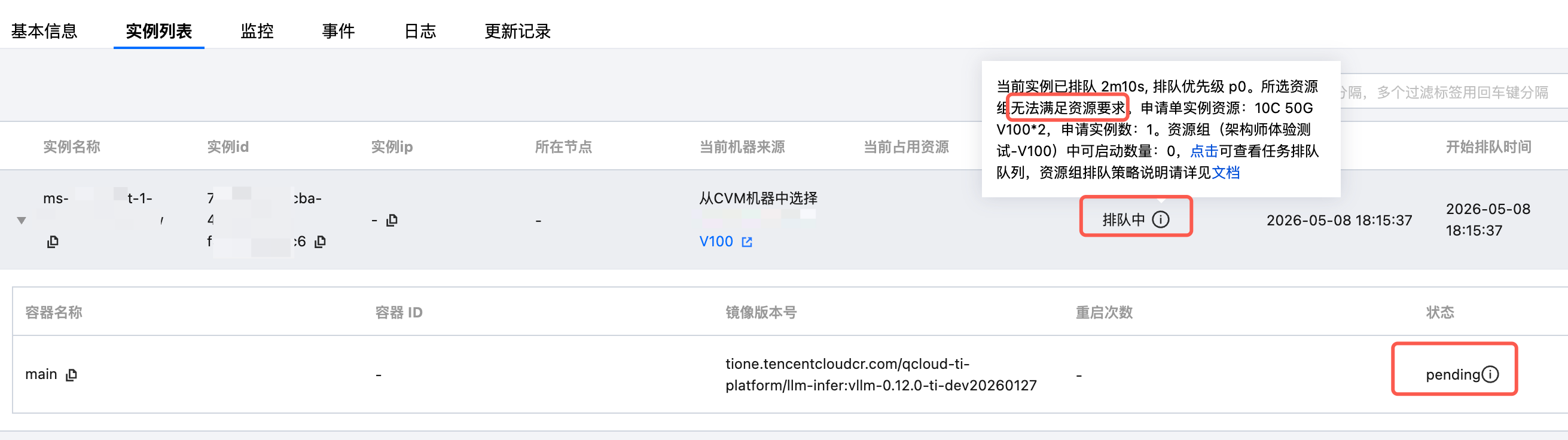
现象:在线服务创建后状态长期停留在"等待中",无法进入运行状态。实例事件中可能出现以下一种或多种信息。
常见原因与排查方式:
场景 | 典型事件/现象 | 处理方式 |
资源不足 | 实例事件显示 Insufficient GPU / Insufficient CPU / Insufficient Memory,或提示"无可用节点" | |
未通过健康检查 | 实例反复进入 NotReady 状态,事件显示 Readiness probe failed / Liveness probe failed | 业务进程未在健康检查超时时间内启动成功;或业务进程监听端口与平台健康检查端口(默认 8501)不一致。 |
镜像拉取失败 | Pod 状态 ImagePullBackOff / ErrImagePull,事件显示无法访问镜像仓库或镜像不存在 | 镜像地址填写有误,或私有镜像未配置拉取凭证。 |
如何排查资源不足?
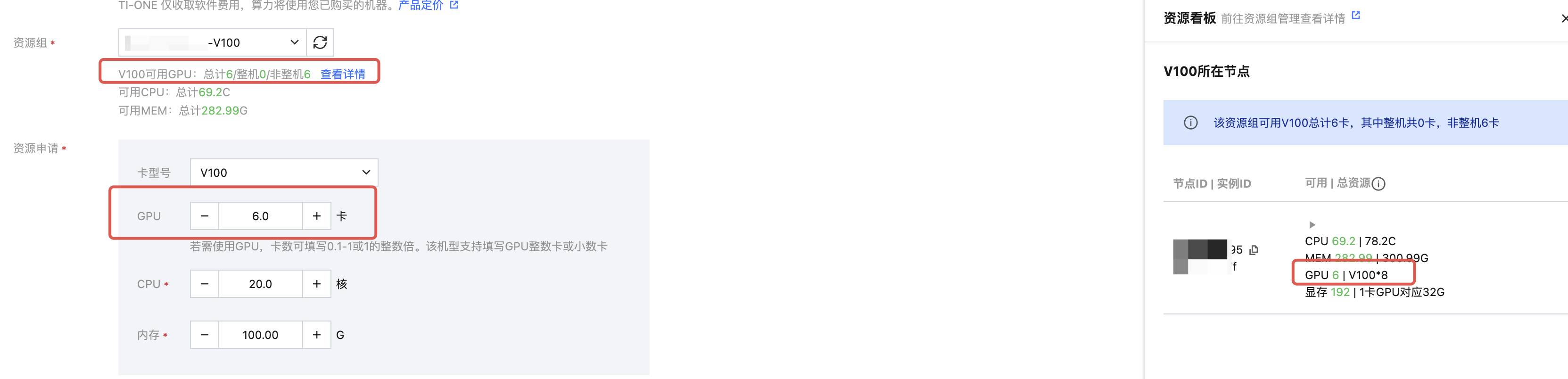
部署在线服务时,资源组下拉框下方会直接展示该资源组当前可用的总量,单击查看详情可打开资源看板,看到每个节点的可用资源明细(CPU/MEM/GPU/显存)。
重点确认以下两类信息:
总量是否满足:资源看板顶部展示的可用总量是否覆盖本次部署申请的规格。
单节点是否碎片化:若总量够但单节点不够,需要整机/多卡部署的在线服务仍会因无法调度而长期等待。此时从节点明细中查看各节点的单独空闲资源。
判断示例:
假设某资源组中包含 2 个 GPU 节点,当前各节点的资源占用情况如下:
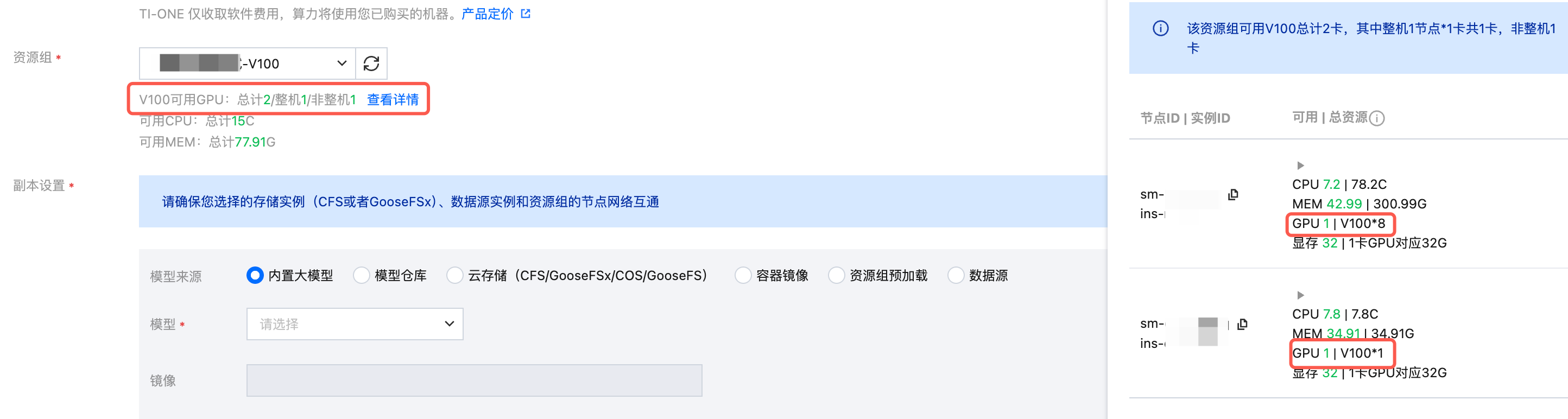
资源组当前累计可用 GPU 为 2 张,分别位于两个不同的节点上,每个节点各剩余 1 张可用。在该资源条件下,部署一个申请 2 张 GPU 卡的在线服务:
从总量看,资源组累计可用 GPU 数量满足本次部署所需的 2 卡规格。但单实例所申请的多卡资源必须由同一节点统一提供,调度器无法将分散在不同节点上的 GPU 资源拼接为一份多卡资源分配给同一实例。因此,调度器在遍历两个节点时,节点 1 仅剩 1 张可用 GPU、节点 2 也仅剩 1 张可用 GPU,均不满足 2 卡的整体申请,调度失败,实例将持续停留在等待中(Pending)状态。
资源组总量虽满足申请规格,但可用资源已被零散占用、分布于多个节点,无任何一个节点能够独立提供完整的多卡资源。如需成功调度,需先停止、迁移或缩容其中一个节点上占用 GPU 的其他在线服务,使该节点空出 2 张连续可用的 GPU 卡后,方可成功调度。
处理方式:
总量不足:释放不必要的其他在线服务(如已停用的训练任务、开发机、历史实例)回收资源;或向资源组中添加新节点。
碎片化:优先停止分散占用在多个节点上的小规格在线服务,腾出整机,使大规格在线服务能成功调度。
如何解决在线服务启动时显存不足或出现 OOM 错误?
现象:实例日志中包含
CUDA out of memory 或 OOMKilled,或实例退出码为 137。处理方式:
1. 确认模型资源需求:进入 TI-ONE 大模型广场,在对应模型卡片的详情中查看其推荐的 GPU 机型与显存要求,核对当前部署使用的机型与卡数是否满足。若不满足,按模型卡片推荐规格调整资源配置。
2. 减小最大上下文长度:在高级设置 > 环境变量中配置
MAX_MODEL_LEN,降低最大上下文长度。例如从 128K 调整为 32K,KV Cache 预分配的显存占用会线性下降。
如何解决在线服务启动时内存(RAM)不足?
现象:实例事件显示
OOMKilled,退出码为 137,监控中内存使用率突然上升至 100%。原因分析:
模型加载过程中需要将权重从磁盘加载到内存再搬运到显存,峰值内存需求较高。
内存(RAM)配置低于 GPU 显存总量。
解决方案:
将内存(RAM)配置为不低于 GPU 显存总量。例如 4 张 80GB 显存的 GPU 卡,建议配置至少 320GB 内存。
使用多卡部署时,按卡数等比例分配整机内存资源。
如何解决在线服务运行一段时间后反复重启?
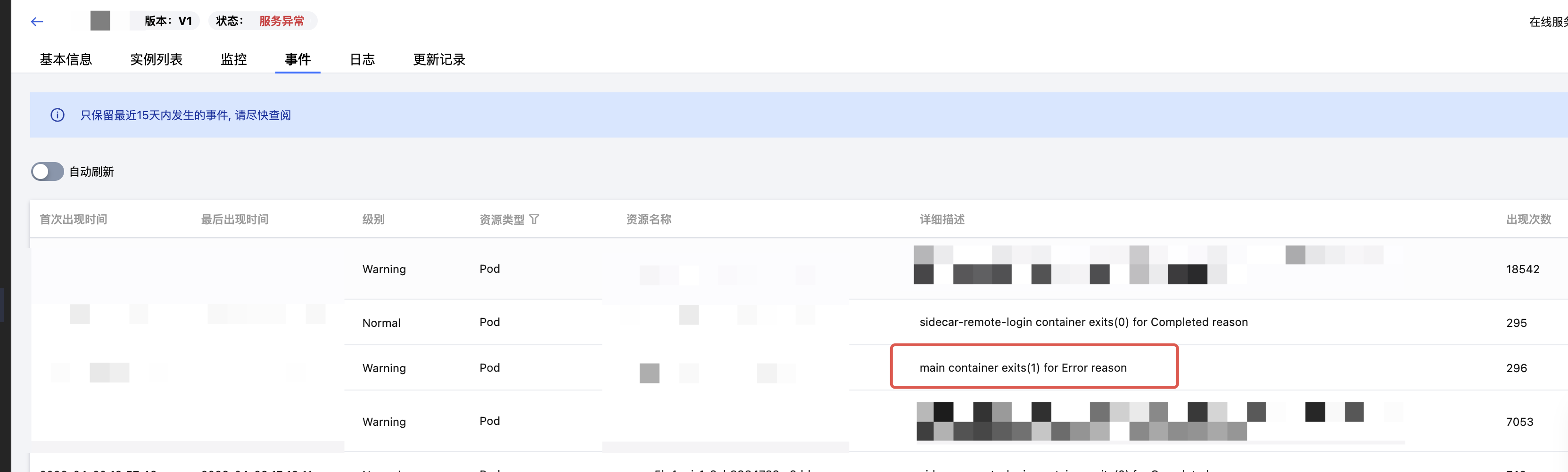
现象:在线服务启动后能正常接收请求,但运行一段时间后实例被自动重启,事件中出现
CrashLoopBackOff。原因分析:实例异常退出可通过退出码定位:
退出码 | 含义 | 典型原因 |
137 | 被系统终止 | 内存/显存超限(OOM) |
139 | 段错误 | 程序访问非法内存,常见于 CUDA 驱动异常 |
1 | 通用错误 | 代码异常、配置错误 |
127 | 命令未找到 | 启动命令路径错误 |
示例:
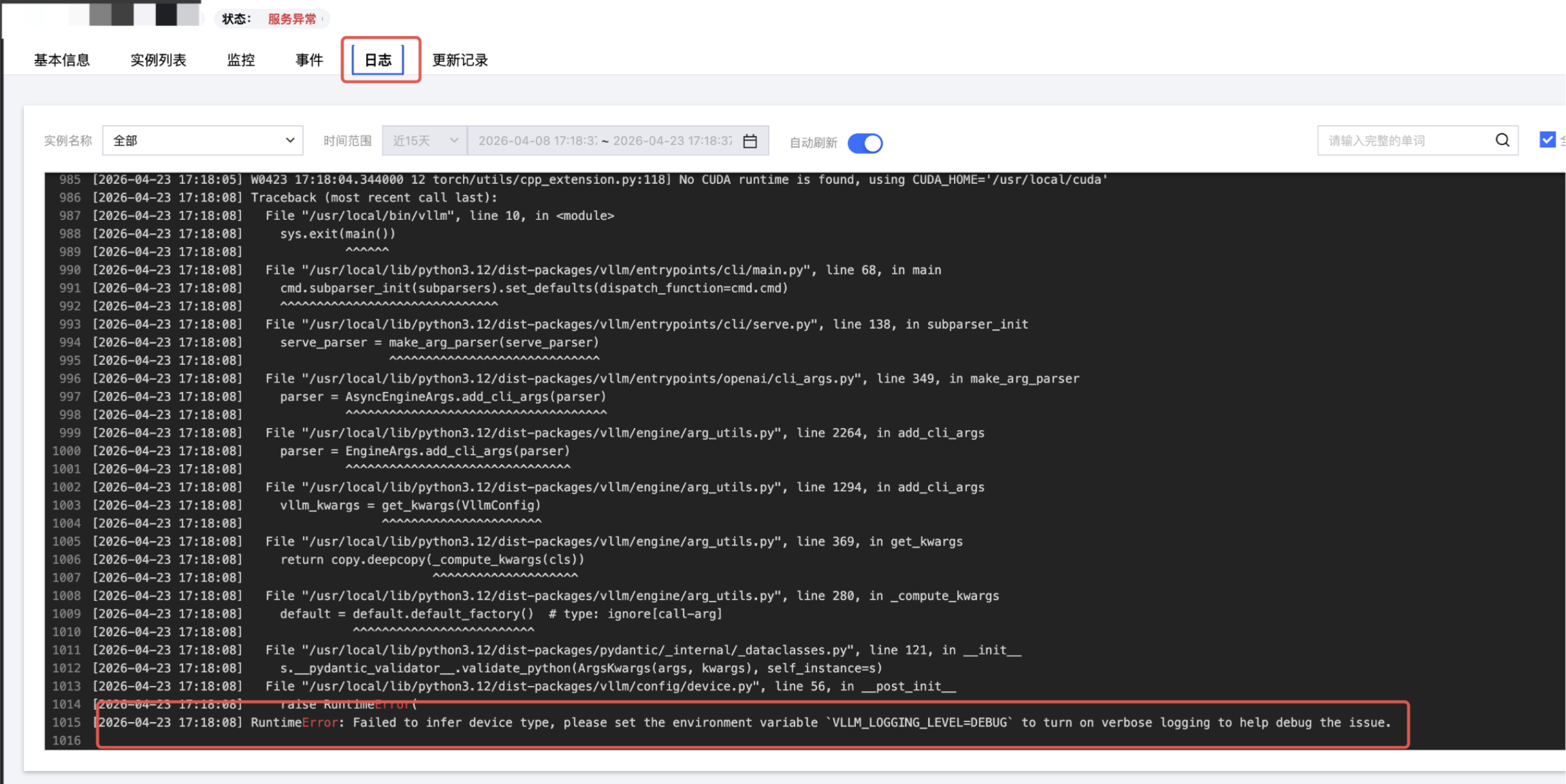
运行中 OOM 的常见原因:
运行中出现超长输入请求(超出上下文上限)。
并发数超过 GPU 实际承载能力。
KV Cache 碎片化累积。
解决方案:
查看实例日志(含崩溃前日志),根据退出码和错误堆栈定位。
若为 OOM:参考上一问的解决方案降低显存占用。
若为 CUDA 驱动层错误(如
Memory access fault by GPU):提交工单由运维协助排查 GPU 硬件。结合监控中的「请求并发数」和「输入 Token 数」曲线,确认崩溃前是否存在异常请求。
镜像/网络类
如何解决镜像拉取失败?
现象:实例事件中出现
ImagePullBackOff 或 ErrImagePull,容器无法启动。常见原因与解决方案:403
报错关键词 | 原因 | 解决方案 |
manifest unknown / not found | 镜像地址或 Tag 拼写错误 | 检查镜像地址、命名空间、Tag 是否正确 |
401 Unauthorized / denied | 镜像仓库鉴权失败 | 确认镜像仓库的用户名、密码或 Token 配置正确 |
dial tcp ... timeout | 网络不通 | 使用同地域的内网访问地址;或确认镜像仓库对平台网络开放 |
no space left on device | 系统盘空间不足 | 参见下一问"在线服务启动时磁盘空间不足" |
如何解决在线服务启动时磁盘空间不足?
现象:日志中出现
No space left on device,实例无法正常启动。原因分析:模型文件、日志、临时缓存等占满了实例的系统盘。大模型场景下尤其常见,模型文件通常从数十 GB 到数百 GB 不等。
解决方案:
方案一:更新在线服务时,增大系统盘配置。
方案二:将模型文件存储在 COS / CFS 中,通过存储挂载方式读取,减少系统盘占用。
启动配置类
如何解决自定义镜像部署后在线服务长期处于"等待中"状态且日志无异常?
现象:使用自定义镜像部署,日志显示进程已启动并监听了某个端口,但平台始终显示在线服务未就绪。
原因分析:平台通过健康检查探测实例是否就绪,默认监听端口为 8501。若业务进程监听的端口与平台配置不一致,健康检查将持续失败。
解决方案:
方式一:修改代码或启动命令,让业务进程监听 8501 端口。
方式二:在在线服务配置中修改端口号,使其与代码中实际监听的端口保持一致。
如何解决更新在线服务时返回 501 错误?
现象:控制台更新在线服务时返回 501 错误。
原因分析:请求被腾讯云 Web 应用防火墙(WAF)拦截。通常因为启动命令中包含了被 WAF 识别为潜在安全风险的字符或脚本片段。
解决方案:将启动命令封装为脚本文件:
1. 将完整的启动命令写入脚本文件(如
start.sh),打包到镜像中或上传至 COS。2. 在在线服务配置的启动命令中改为执行该脚本,例如:
bash /path/to/start.sh。
服务调用与网络
调用报错类
如何解决调用时返回 403 错误(HTML 页面含 AccessDenied)?
现象:通过公网地址调用时,返回 403 状态码,响应内容为一个标题含
AccessDenied 的 HTML 页面。原因分析:请求被腾讯云 Web 应用防火墙(WAF)拦截。公网请求默认经过 WAF 安全检测,请求中的特殊字符或代码片段可能触发安全规则。
解决方案:
检查请求内容是否包含可能触发 WAF 规则的字符或格式。
改用 VPC 内网调用方式,内网请求不经过 WAF。
如必须使用公网调用,请 提交工单 申请 WAF 规则调整。
如何解决调用时返回 "model does not exist" 错误?
现象:调用接口返回类似以下错误:
{"message": "The model `Qwen3-30B-A3B-Instruct` does not exist.","type": "NotFoundError","code": 404}
原因分析:
请求中
model 参数的值与在线服务实际的模型标识不匹配。TI-ONE 平台在线服务的默认模型标识为服务组 ID(如 ms-xxxxxxxx),而非模型的社区名称。模型标识可在在线服务的服务调用页面中找到: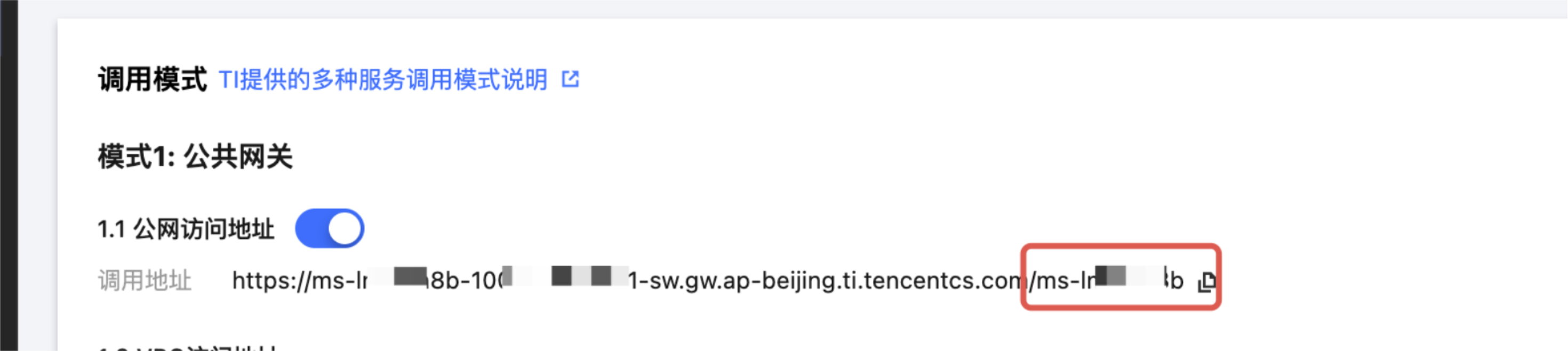
解决方案:使用服务组 ID 作为
model 参数调用。操作步骤如下:1. 进入服务详情页,复制"服务组 ID"(格式:
ms-xxxxxxxx)。2. 在请求中使用该 ID 作为
model 参数。
示例:
{"model": "ms-xxxxxxxx","messages": [{"role": "user", "content": "你好"}]}
如何解决调用 Reranker 模型时返回 "Not Found" 错误?
现象:部署 Reranker 模型(如 Qwen3-Reranker-8B)后,使用常规的
/v1/chat/completions 接口调用返回 Not Found。原因分析:Reranker 模型有专用的调用接口,不使用标准的 Chat Completions API。
解决方案:使用 Reranker 专用接口
/v1/rerank:curl --request POST \\--url https://<您的服务地址>/v1/rerank \\--header "Authorization: Bearer $API_KEY" \\--header "Content-Type: application/json" \\--data '{"model": "<您的服务组ID>","query": "什么是文本排序模型","documents": ["文档1", "文档2"],"top_n": 2}'
说明:
不同类型的模型(Embedding、Reranker 等)可能有各自专用的接口路径和请求格式,具体参见对应模型的部署文档。
网络配置类
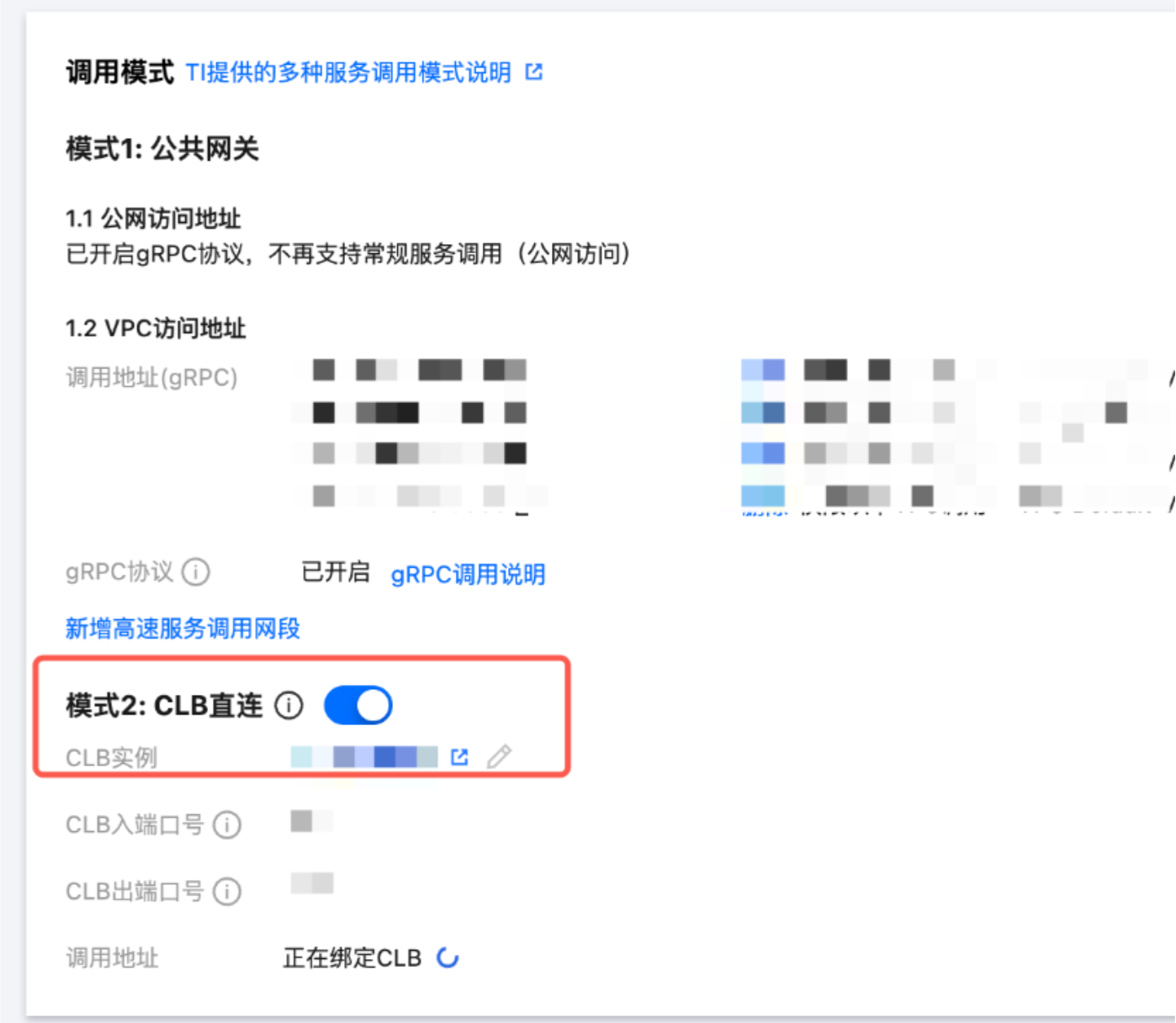
公网调用延迟为什么明显高于内网?
原因分析:公网调用链路中经过了共享的 CLB(负载均衡)和 WAF(Web 应用防火墙),两者分别带来延迟:
CLB:多租户共享流量带宽,高峰期可能排队。
WAF:安全检测流程增加额外延迟。
解决方案:
推荐方案:在服务调用页面启用 CLB 调用,绑定独立的公网 CLB 获得独享带宽。
如何配置 VPC 内网调用?
操作步骤:
1. 登录 TI-ONE 控制台,进入在线服务列表页。
2. 单击目标在线服务名称,进入服务详情页。
3. 切换至服务调用页签。
4. 在高速服务调用区域,单击新增高速服务调用网段,配置需要打通的 VPC 网段。
在线服务是否支持 WebSocket 协议?
支持。WebSocket 目前仅支持通过高速内网调用方式使用,公网网关暂不支持。
配置步骤:
1. 在服务调用页面开启高速服务调用。
2. 将 VPC 调用地址中的协议从
http 改为 ws,例如:ws://172.27.x.x/ms-xxxxxxxx-1
如何配置 IP 白名单限制访问来源?
公网场景(通过 CLB 安全组)
前置条件:已在"服务调用"页面启用 CLB 调用,绑定了独立的公网 CLB。
配置步骤:
1. 进入 CLB 控制台,找到绑定的 CLB 实例。
2. 进入 CLB 的"安全组"配置页。
3. 添加入站规则:
源 IP:允许访问的 IP 列表
协议:TCP
端口:CLB 监听端口
内网场景(通过终端节点安全组)
前置条件:已配置 VPC 内网调用,产生了私有连接 > 终端节点。
配置步骤:
1. 找到在线服务 VPC 调用地址对应的私有连接终端节点。
2. 对终端节点绑定安全组规则:
源 IP:允许访问的 VPC 网段或 IP 列表
协议:TCP
端口:服务端口(默认 8501)
在线服务的出口 IP 是否固定及如何查看?
按量计费和包年包月场景下,在线服务的外网出口 IP 均为固定 IP。
查看方式:
1. 登录 TI-ONE 控制台,进入在线服务的实例列表页面。
2. 单击目标实例进入容器终端。
3. 执行以下命令查看出口 IP:
curl ifconfig.me
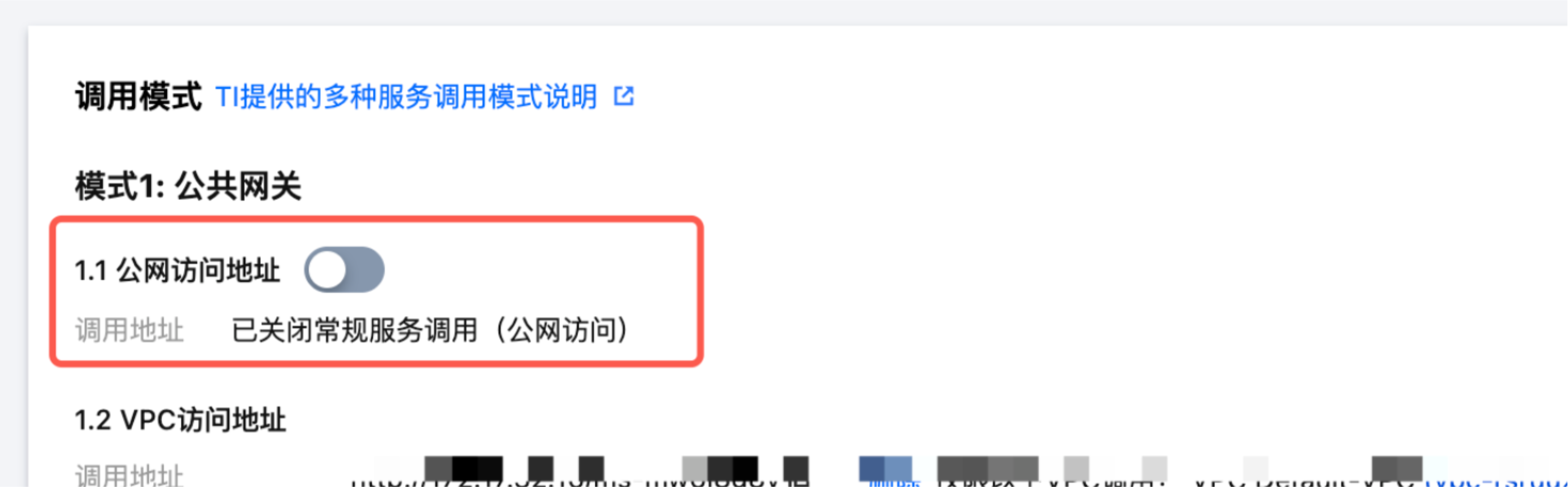
是否支持关闭在线服务公网访问入口?
支持关闭。通过在线服务 > 服务调用 > 调用模式 > 公网访问地址的开关,可以控制公网访问是否开启。
模型推理与效果调优
参数与调用方式
如何开启流式调用?
说明:
TI-ONE 部署的大模型在线服务均支持流式(Streaming)调用。
在请求体中设置
"stream": true:{"model": "ms-xxxxxxxx","messages": [{"role": "user", "content": "你好"}],"stream": true}
调用在线服务时 model 字段如何取值?
背景说明:
通过 OpenAI 兼容接口(如
/v1/chat/completions)调用在线服务时,请求体必须携带 model 字段,例如:{"model": "ms-xxxxxxxx","messages": [{"role": "user", "content": "你好"}]}
该字段的取值并非开源模型的社区名称(如
Qwen3-30B-A3B-Instruct、DeepSeek-V3),而是 TI-ONE 在线服务对外暴露的服务标识。默认值:
model 字段的默认值为服务组 ID,格式为 ms-xxxxxxxx。可在服务详情页 > 服务调用中查看:
自定义取值的场景:
业务代码已经按照
Qwen3-30B-A3B-Instruct、my-chat-model 等名称写死在 model 字段中,不希望为了适配平台而改代码,此时可在在线服务侧将 model 的可接受取值改为业务需要的名称。
自定义配置方式(二选一):
方式一:在高级设置 > 启动命令中添加参数:
run --served-model-name Qwen3-30B-A3B-Instruct
方式二:在高级设置 > 环境变量中新增:
SERVED_MODEL_NAME=Qwen3-30B-A3B-Instruct
配置后调用示例:
{"model": "Qwen3-30B-A3B-Instruct","messages": [{"role": "user", "content": "你好"}]}
说明:
配置后,原服务组 ID(
ms-xxxxxxxx)将不再作为有效的 model 取值,需使用自定义名称调用。
如何查看当前模型生效的最大上下文长度?
开源模型原生支持的长度:见模型社区
config.json 中的 max_position_embeddings 字段。TI-ONE 内置模型的默认配置:参见大模型广场中对应模型卡片的详情。
效果异常类
如何关闭 Qwen3 / GLM5 等模型的思维链输出?
Qwen3 系列:在请求体中添加
"chat_template_kwargs": {"enable_thinking": false} 参数:curl -X POST https://<您的服务地址>/v1/chat/completions \\-H 'Authorization: Bearer <your_token>' \\-H 'Content-Type: application/json' \\-d '{"model": "ms-xxxxxxxx","chat_template_kwargs": {"enable_thinking": false},"messages": [{"role": "user", "content": "你好"}]}'
如何解决模型输出乱码或特殊字符?
常见原因:
情况 | 原因 | 解决方案 |
对话模板或 Tokenizer 不匹配 | 推理框架加载的配置与模型不匹配 | 检查模型目录中的 tokenizer_config.json 和 chat_template 配置 |
输入超过模型原生支持长度 | 位置编码(RoPE)失效 | 缩短输入长度;或配置 RoPE 缩放参数(如 YaRN) |
YaRN 缩放示例(以 Qwen3 支持 64K 输入为例):
--context-length 65536 --json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":2.0,"original_max_position_embeddings":32768}}'
如何解决模型重复生成过多内容?
解决方案:在请求体中添加
repetition_penalty 参数(重复惩罚系数):{"model": "ms-xxxxxxxx","messages": [{"role": "user", "content": "你好"}],"repetition_penalty": 1.05}
说明:
该值大于 1.0 时生效,推荐范围为 1.02~1.10。过高可能影响输出流畅度。
同一模型在 vLLM 和 SGLang 上输出效果为什么不一致?
原因分析:
1. 对话模板(chat_template):两个框架对
chat_template 的解析和应用方式可能略有不同。2. 采样参数默认值:如
temperature、top_p、repetition_penalty 等参数的默认值可能不同。3. 随机种子:未固定
seed 时,采样具有随机性。解决方案:
在请求体中显式指定所有关键采样参数(
temperature、top_p、seed 等)。检查两个框架加载的
chat_template 是否一致。如对一致性要求极高,在两个框架上均设置固定的
seed 值。
弹性伸缩与服务变更
更新在线服务后配置为什么没生效?
现象:修改了 COS / CFS 中的模型文件或配置文件后,在线服务行为未发生变化。
原因分析:TI-ONE 平台仅感知通过控制台页面发起的配置变更(如镜像版本、启动命令、环境变量等)。直接修改 COS / CFS 中的文件内容,平台无法自动感知。
解决方案:修改存储中的文件后,需要手动触发在线服务更新:
1. 进入在线服务的服务管理页面。
2. 单击更新,无需修改任何配置项,直接提交更新即可触发重新加载。
注意:
若修改的是模型目录中的配置文件(如
config.json),需确保修改的是原始路径中的文件,而非 COS 副本。实例重启后文件会从 COS 重新拉取,本地修改会被覆盖。
业务流量增长但在线服务为什么没有自动扩容?
现象:已配置 HPA 策略,但在流量增长时在线服务未自动扩容。
原因分析:最常见的原因是 HPA 策略指标尚未达到阈值。平台对指标阈值有一定的容忍区间,在阈值附近的短暂波动不会立即触发扩缩容。
解决方案:
1. 检查策略中配置的指标类型和阈值是否合理。
2. 在服务监控中查看实际指标值是否确实达到或超过阈值。
3. 适当调低阈值,以便更灵敏地触发扩容。
4. 如使用 TI-ONE 内置推理框架,可通过配置内置环境变量启用多进程,提升单实例资源利用率。
滚动更新是否会中断线上流量?
平台默认使用滚动更新,即先创建新 Pod,新 Pod 就绪后再下线旧 Pod,更新期间旧副本持续承接流量,理论上不中断服务。
操作步骤:
1. 进入服务详情页,修改目标配置(镜像、环境变量等)。
2. 保存后系统自动执行滚动更新。
3. 新 Pod 就绪 → 切流量 → 下线旧 Pod。
如需调整更新策略(如同时更新多个实例以加快速度),可在高级设置中修改
maxSurge / maxUnavailable。
如何配置缩容时优先关闭实例的策略?
缩容策略为优先关闭最近创建的实例。如需关闭特定的旧实例,可先隔离该实例,系统在下次缩容时会优先关闭被隔离的实例。
监控与日志
如何配置在线服务日志投递和告警?
操作步骤:
1. 在新建或更新在线服务时,开启日志投递至 CLS(日志服务)选项。
2. 登录 CLS 控制台,在对应的日志主题中配置:
日志检索分析:对在线服务日志进行搜索和 SQL 分析。
告警策略:根据关键词(如
ERROR、OOM)或指标阈值配置告警通知。日志中为什么存在大量 /metrics 请求记录?
现象:在线服务日志中包含大量
GET /metrics 404 或 GET /metrics 200 的请求记录(由平台监控采集产生)。解决方案:更新在线服务,在高级设置 > 环境变量中添加:
环境变量 | 值 | 说明 |
METRICS_DISABLE | 1 | 关闭 /metrics 接口的数据采集和对应的请求日志 |
注意:
关闭后,平台将无法采集该在线服务的部分监控指标(如并发数)。如仍需查看监控指标,请勿开启此环境变量。
如何实现在线服务的链路追踪?
说明:TI-ONE 在线服务基于 OpenAI 兼容 API 提供请求链路追踪能力,通过
X-Request-Id 请求头(vLLM)或请求体 rid 字段(SGLang)实现请求在客户端、网关、推理引擎之间的统一标识。平台会对每个入站请求生成或透传该标识,并记录到访问日志的 request_id 字段中,便于问题排查时串联整条请求链路。
vLLM(v0.6.5+)
vLLM 原生支持
X-Request-Id 协议,无需额外配置。客户端请求头携带
X-Request-Id,响应的 id 字段即为该请求 ID。
响应示例:
{"id": "chatcmpl-7f3a1b2c-4d5e-6f7a-8b9c-0d1e2f3a4b5c","object": "chat.completion","model": "ms-abcdefgh","choices": []}
SGLang(v0.4.6.post5+)
SGLang 本身不支持
X-Request-Id 请求头,但支持通过请求体中的 rid 字段指定请求 ID。平台提供 TI_INJECT_ID 自动注入能力:开启后,平台会在请求转发到推理引擎前读取请求体,将网关生成的请求 ID 写入 rid 字段,使响应中返回的 id 与平台访问日志中的 request_id 保持一致,从而打通客户端、网关、推理引擎三端的请求标识。
开启方式:在线服务的高级设置 > 环境变量中新增
TI_INJECT_ID=1,并保存更新服务。
生效条件(需同时满足):
在线服务使用 SGLang 镜像。
环境变量已设置
TI_INJECT_ID=1。请求 Content-Type 为
application/json。请求路径为以下之一:
/v1/chat/completions/v1/completions您的服务地址/v1/embeddings/v1/classify性能提示:
开启
TI_INJECT_ID 后,平台需要读取并重写请求体以注入 rid 字段。请求体较大时(如 Embedding 批量输入 10000 Token 以上)会引入明显的性能开销,建议先评估对业务延迟的影响后再启用。
注入
rid 后的请求示例:{"rid": "7f3a1b2c-...", "model": "ms-abcdefgh", "messages": []}
响应示例:
{"id": "7f3a1b2c-4d5e-6f7a-8b9c-0d1e2f3a4b5c","object": "chat.completion","model": "ms-abcdefgh","choices": []}
其他常见问题
在线服务内置模型的存放在哪个路径?
在线服务的内置模型默认挂载目录为
/data/model/。
在线服务为什么无法删除?
请确认在线服务下所有实例是否已停止。进入服务详情页 > 实例列表,停止所有运行中的实例后,再执行删除操作。
自定义镜像是否可以使用平台缓存加速?
若自定义镜像基于平台基础镜像构建,可继承镜像缓存优势,加速拉取。
完全独立的自定义镜像无法自动享受缓存优化。
建议:构建自定义镜像时,尽量以平台提供的基础镜像作为
FROM 基础层。
部署后在线服务的调用地址和 IP 是否会变化?
调用地址 / 域名:只要不删除在线服务,重新部署或更新后调用地址和域名保持不变。
固定 IP:内网调用场景支持固定 IP;公网调用暂不支持。



