场景说明
Cosmos-Predict2 是英伟达(NVIDIA)开源的一套物理 AI 世界基础模型,属于 Cosmos 世界基础模型系列,专门用于从文本、图像或视频生成具有物理合理性的未来世界状态,为机器人、自动驾驶等物理 AI 系统提供合成数据和仿真环境。本文档将介绍如何在 TIONE 平台上进行 Cosmos-Predict2 系列模型的部署和精调。
前置准备
1. 下载 checkpoints
2. 下载 datasets
下载完成后,checkpoints 目录结构如下:
├── depth-anything│ └── Depth-Anything-V2-Small-hf│ └── sam2-hiera-large├── google-t5│ └── t5-11b├── IDEA-Research│ └── grounding-dino-tiny├── meta-llama│ └── Llama-Guard-3-8B└── nvidia├── Cosmos-1.0-Guardrail├── Cosmos-Guardrail1├── Cosmos-Predict2-14B-Text2Image├── Cosmos-Predict2-14B-Video2World├── Cosmos-Predict2-2B-Text2Image├── Cosmos-Predict2-2B-Video2World├── Cosmos-Reason1-7B├── Cosmos-Tokenize1-CV8x8x8-720p├── Cosmos-Transfer1-7B├── Cosmos-Transfer1-7B-Sample-AV├── Cosmos-Transfer1-7B-Sample-AV-Single2MultiView└── Cosmos-UpsamplePrompt1-12B-Transfer
nvidia 目录下面包含了多余的模型,例如 transfer1 等,这是 Cosmos 系列的一个超集。
其余目录请确保自己正确传入了 hf token,并同意了用户协议,例如 meta-llama 系列模型,否则可能下载失败。
模型部署
步骤一:确认所需资源
14B-Text2World 部署推荐资源如下,您可以根据实际的资源情况进行选择。
标准部署 31C288G GPU-HCCPNV6*2
标准部署 60C600G GPU-HCCPNV6*4
标准部署 125C1207G GPU-HCCPNV6*8
步骤二:创建在线服务
模型来源:选择腾讯云存储,选择前置准备中下载好的 checkpoints 路径。
镜像:选择内置
PYTORCH/cosmos-predict2-cu128存储挂载:配置容器内路径 /opt/ml/output,对应输出视频目录。这里在推理容器启动时会被软连接到
/workspace/cosmos-predict2/output,所以下面 webui 显示的是软连接的路径、不影响输出。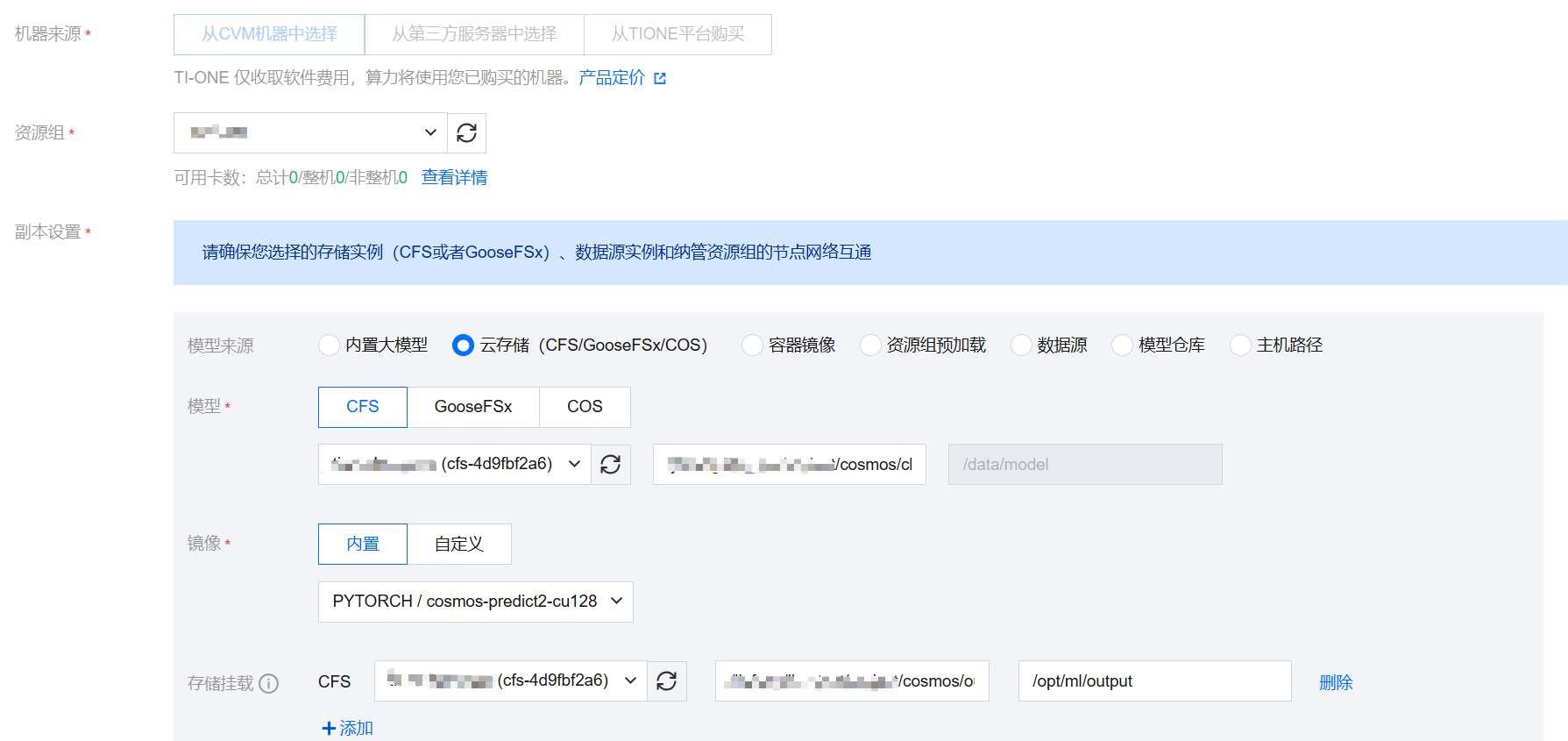
资源申请:根据自己业务需要以及上方的推荐资源选择自己的方案。
环境变量:
MODEL_SIZE:可选值 2B/14B,默认为 14B
DISABLE_GUARDRAIL:关闭 guardrail 模型检查,默认未开启。只要配置了就是关闭,配置任意值即可。2B 模型可选,14B 必选,否则容易 OOM 以及造成 CUDA OOM。
DISABLE_PROMPT_REFINER:关闭 prompt 优化功能,默认未开启、可以优化短 prompt。只要配置了就是关闭,配置任意值即可。2B 模型可选,14B 必选,否则容易 OOM 以及造成 CUDA OOM。
OFFLOAD_GUARDRAIL:将 guardrail 模型 offload 到内存来减少显存占用,默认未开启。只要配置了就是关闭,配置任意值即可。14B 模型如果未配置 DISABLE_GUARDRAIL 则必须开启此选项、同时比上面推荐的资源配置的内存增大一个档位。
OFFLOAD_PROMPT_REFINER:将 prompt 优化模型 offload 到内存来减少显存占用,默认未开启。只要配置了就是关闭,配置任意值即可。14B 模型如果未配置 DISABLE_PROMPT_REFINER 则必须开启此选项、同时比上面推荐的资源配置的内存增大一个档位。
步骤三:查看 WebUI
等待服务启动,然后单击打开WebUI页面。

展开 File Viewer 能够预览
/workspace/cosmos-predict2/output 下面所有的视频和文件等。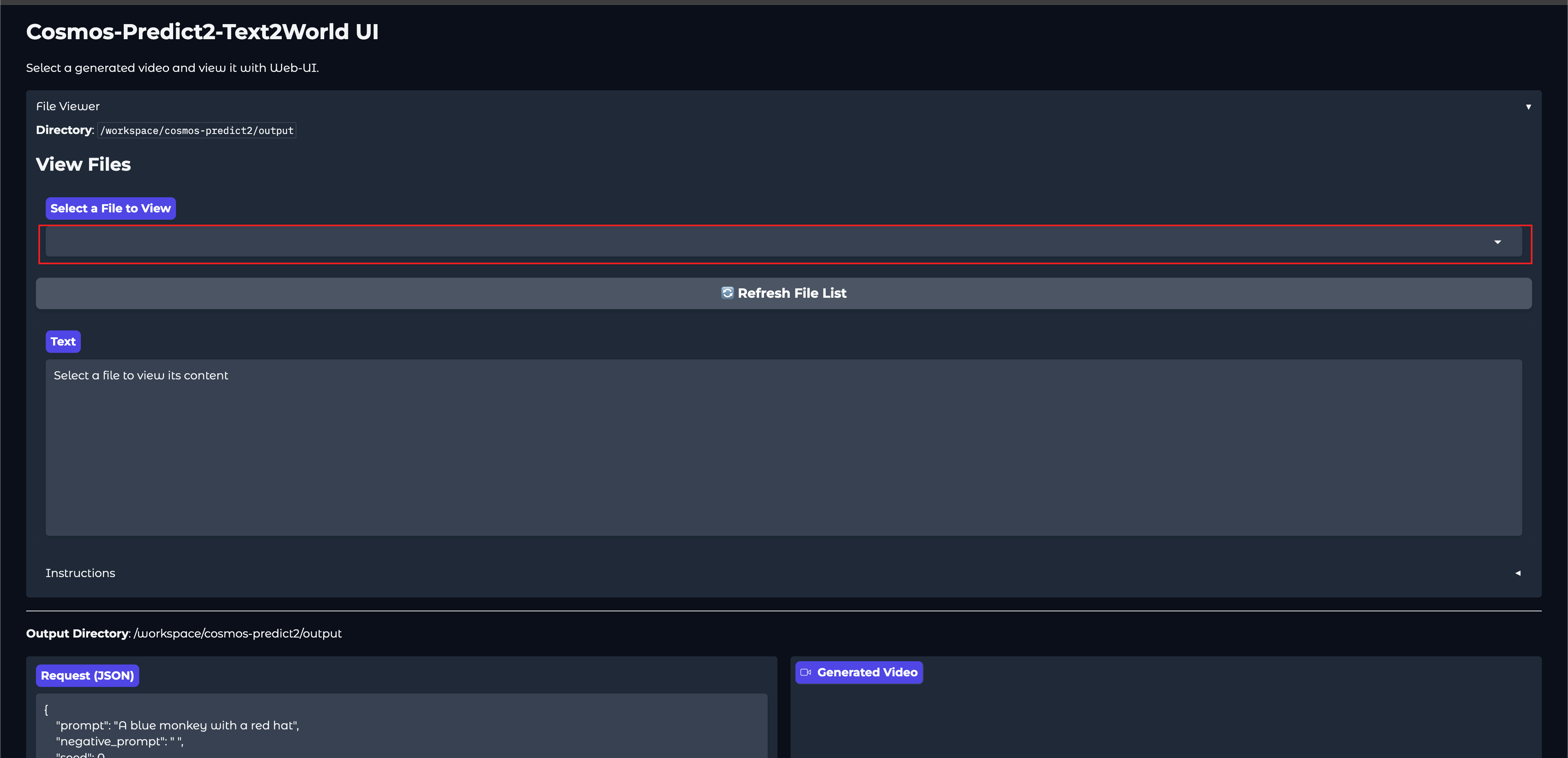
下方可以发起请求以及查看生成好的视频。
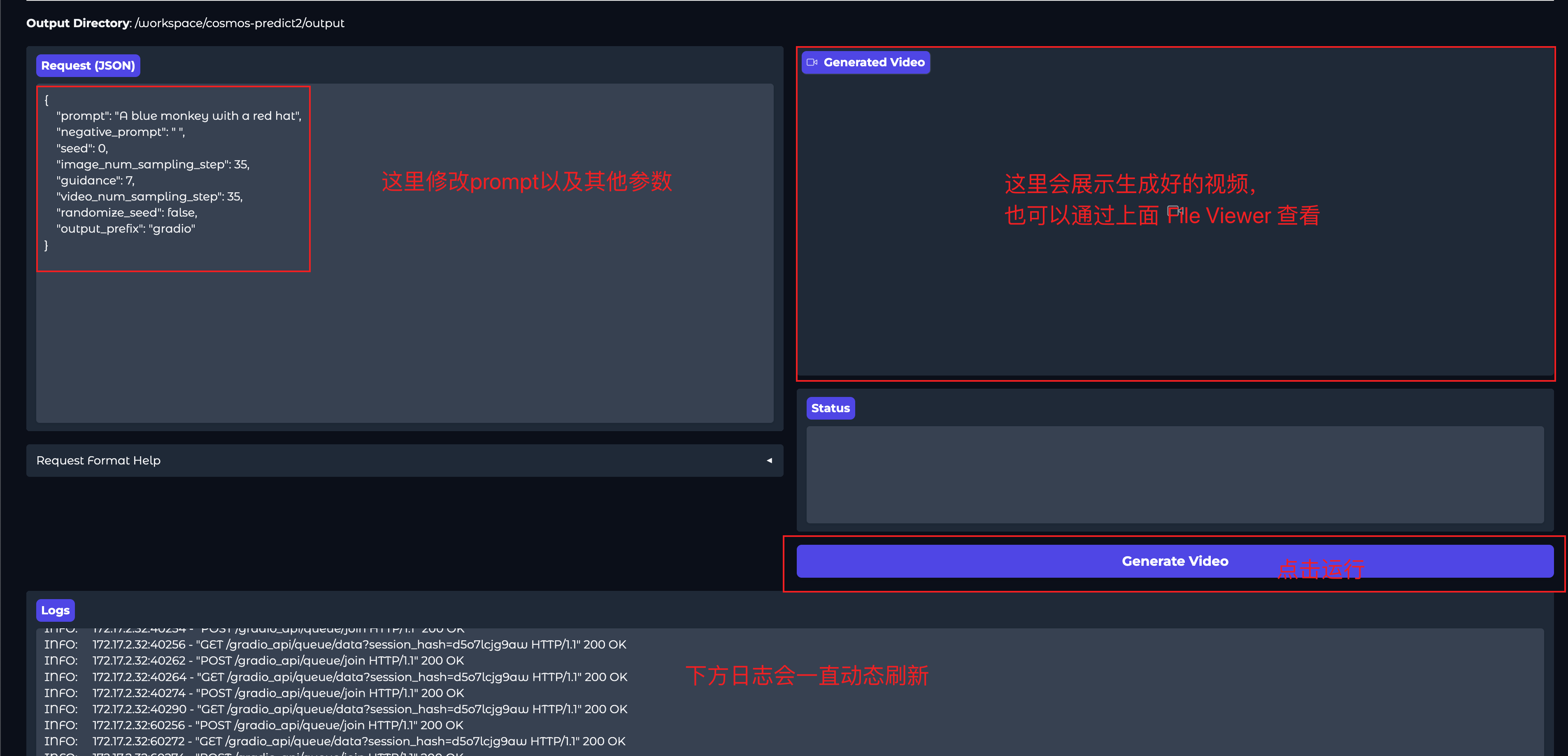
性能提示
1. 单卡 HCCPNV6 启动:image_num_sampling_step=35、video_num_sampling_step=5,大概需要跑13分钟。所以如果是默认的 35 应该需要跑 13*7=91分钟。
2. 目前支持了多卡 CP 推理加速,可以按照上面推荐资源配置、自己的业务需求来选择合适的方案。以8卡 HCCPNV6 为例,默认配置 image_num_sampling_step=35、video_num_sampling_step=35,应该能在 91/8 ≈ 12 分钟内跑完一个请求。
3. 如果生成时间很长无法接受,又没有足够的卡,可以通过减小 video_num_sampling_step 来等比例显著减少任务耗时、但是生成的视频质量也会更差。
模型精调
步骤一:配置存储路径
1. 不管是开发机还是任务式建模,最终都要把目录挂载到对应路径。任务式建模可以按照下方指引自行配置,开发机则需要自己创建软连接。
2. 对应的目录要求如下:
将前置准备中下载好的 checkspoints 目录,挂载到:
/workspace/cosmos-predict2/checkpoints将前置准备中下载好的 datasets 目录,参考下方指引进行预处理,并挂载到:
/workspace/cosmos-predict2/datasets如果 Text2Image、Video2World 都已完成预处理,最终
/workspace/cosmos-predict2/datasets 的目录结构如下:├── cosmos_nemo_assets│ ├── metas│ ├── t5_xxl│ └── videos└── cosmos_nemo_assets_images├── images├── metas└── t5_xxl
步骤二:精调 14B-Text2Image
(请按照指引下载并处理好 datasets 后再进行下面的步骤)
训练模块:开发机
训练资源配置:128C1024G HCCPNV6*8
训练配置:
/workspace/cosmos-predict2/cosmos_predict2/configs/base/experiment/cosmos_nemo_assets.py在开发机中运行训练命令:
cd /workspace/cosmos-predict2source $HOME/.local/bin/env && source .venv/bin/activateexport HF_ENDPOINT=https://hf-mirror.comtorchrun --nproc_per_node=8 --master_port=12341 -m scripts.train --config=cosmos_predict2/configs/base/config.py -- experiment=predict2_text2image_training_14b_cosmos_nemo_assets
如果您没有修改配置的话,默认输出路径是在
/workspace/cosmos-predict2/checkpoints/posttraining/text2image,可以查看上面的训练配置对应的文件来修改 epoch、学习率等参数。训练后测试推理:
python examples/text2image.py \\--model_size 14B \\--dit_path "checkpoints/posttraining/text2image/14b_cosmos_nemo_assets/checkpoints/model/iter_000001000.pt" \\--prompt "An image of sks teal robot." \\--save_path output/generated_image_14b_teal_robot.jpg
步骤三:精调 14B-Video2World
(请按照指引下载并处理好 datasets 后再进行下面的步骤)
训练模块:任务式建模
训练资源配置:128C1024G HCCPNV6*8,节点数*2
训练配置:
/workspace/cosmos-predict2/cosmos_predict2/configs/base/experiment/cosmos_nemo_assets.py任务式建模启动命令:
set -excd /workspace/cosmos-predict2source $HOME/.local/bin/env && source .venv/bin/activateexport HF_ENDPOINT=https://hf-mirror.comDISTRIBUTED_ARGS="--nproc_per_node ${NPROC_PER_NODE:-$(nvidia-smi -L | wc -l)} \\--nnodes ${WORLD_SIZE:-1} \\--node_rank ${RANK:-0} \\--master_addr ${MASTER_ADDR:-127.0.0.1} \\--master_port ${MASTER_PORT:-23456}"torchrun $DISTRIBUTED_ARGS --rdzv_id 123 --rdzv_backend c10d --rdzv_endpoint $MASTER_ADDR:12341 -m scripts.train --config=cosmos_predict2/configs/base/config.py -- experiment=predict2_video2world_training_14b_cosmos_nemo_assets
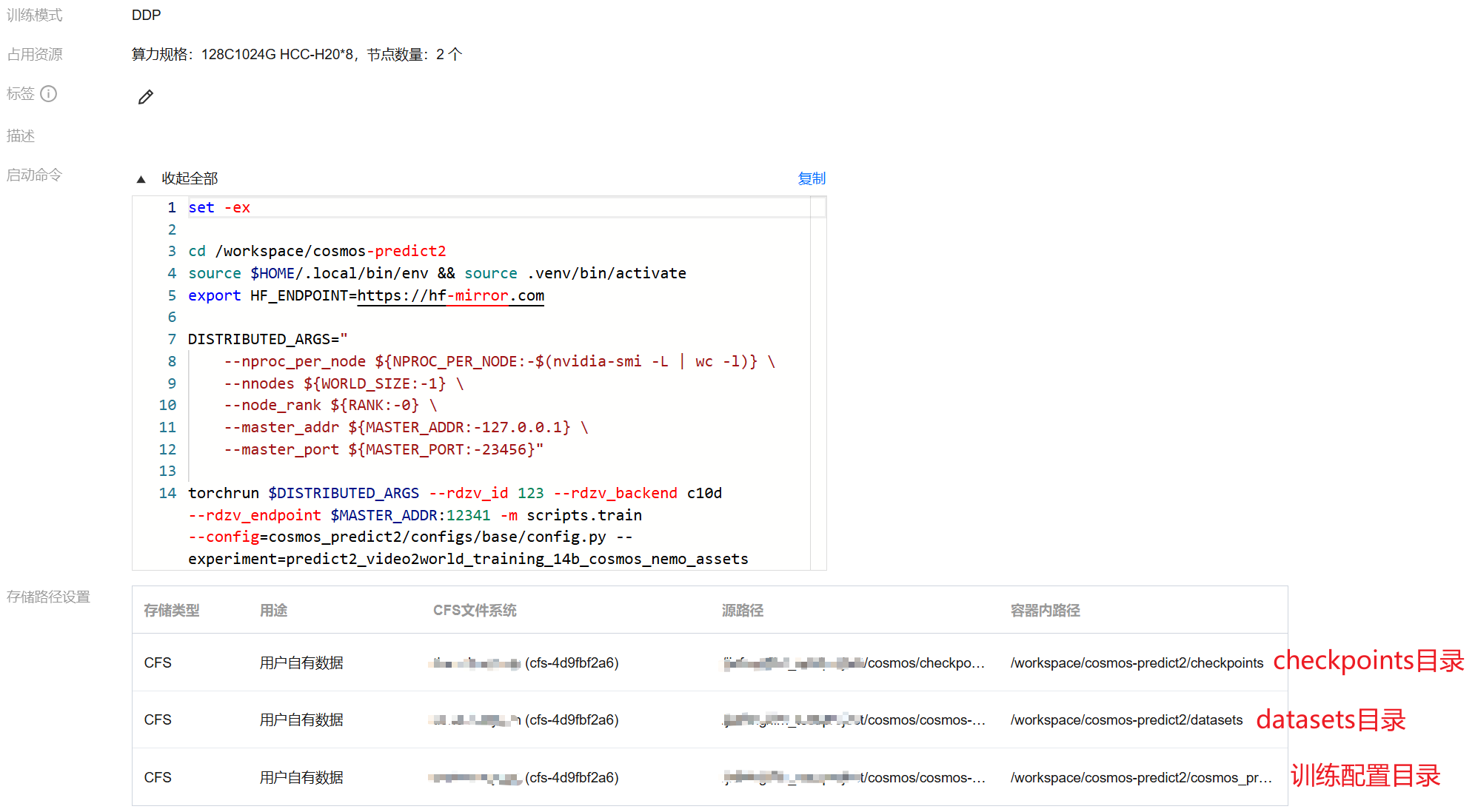
存储路径设置:
挂载 checkpoints 目录(必填):
源路径:您下载好的 checkpoints 目录
容器内路径:
/workspace/cosmos-predict2/checkpoints挂载 datasets 目录(必填):
源路径:您下载并处理好的 datasets 目录
容器内路径:
/workspace/cosmos-predict2/datasets挂载 config 目录(可选):
原路径:您本地修改过的 config 目录。选择到 `cosmos_predict2/configs/base` 这一级子目录即可,避免路径太长无法挂载。
容器内路径:/workspace/cosmos-predict2/cosmos_predict2/configs/base
任务启动后日志:
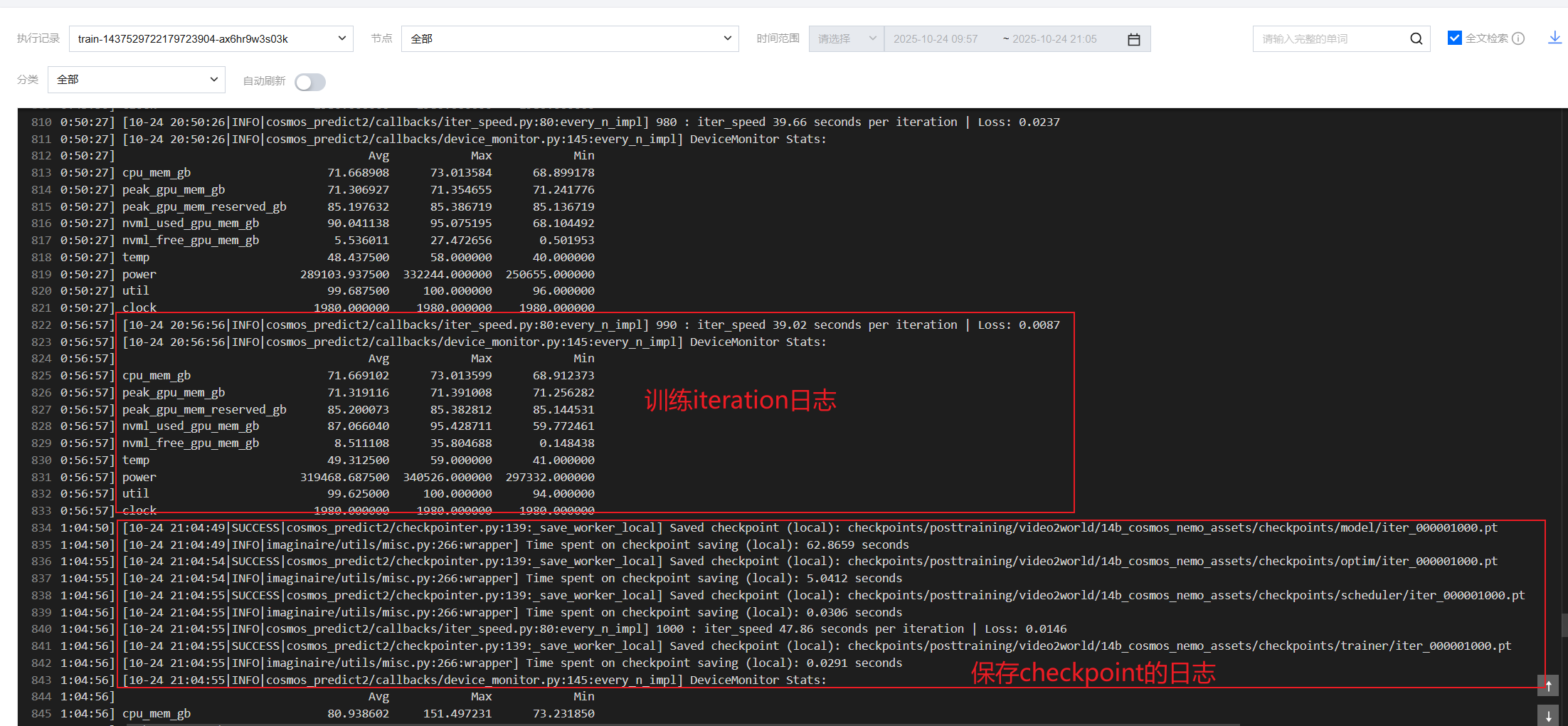
如果您没有修改配置的话,默认输出路径是在
/workspace/cosmos-predict2/checkpoints/posttraining/video2world,可以查看上面的训练配置对应的文件来修改 epoch、学习率等参数。训练后测试推理:
python examples/video2world.py \\--model_size 14B \\--dit_path "checkpoints/posttraining/video2world/14b_cosmos_nemo_assets/checkpoints/model/iter_000001000.pt" \\--prompt "A video of sks teal robot." \\--input_path "assets/video2world_cosmos_nemo_assets/output_Digit_Lift_movie.jpg" \\--save_path output/cosmos_nemo_assets/generated_video_teal_robot.mp4 \\--offload_guardrail \\--offload_prompt_refiner
查看生成好的视频
进入开发机,选择 Jupyter IDE。
在 Launcher 中新建一个 Notebook。

输入下面的代码,然后修改为自己的路径即可查看本地生成的视频。
from IPython.display import VideoVideo("project/cosmos/output/gradio-0bed11fc-b7c4-4d35-b784-a40f3b1c489a.mp4")