基本信息配置
1. 服务基础信息
参数填写说明:
参数 | 说明 |
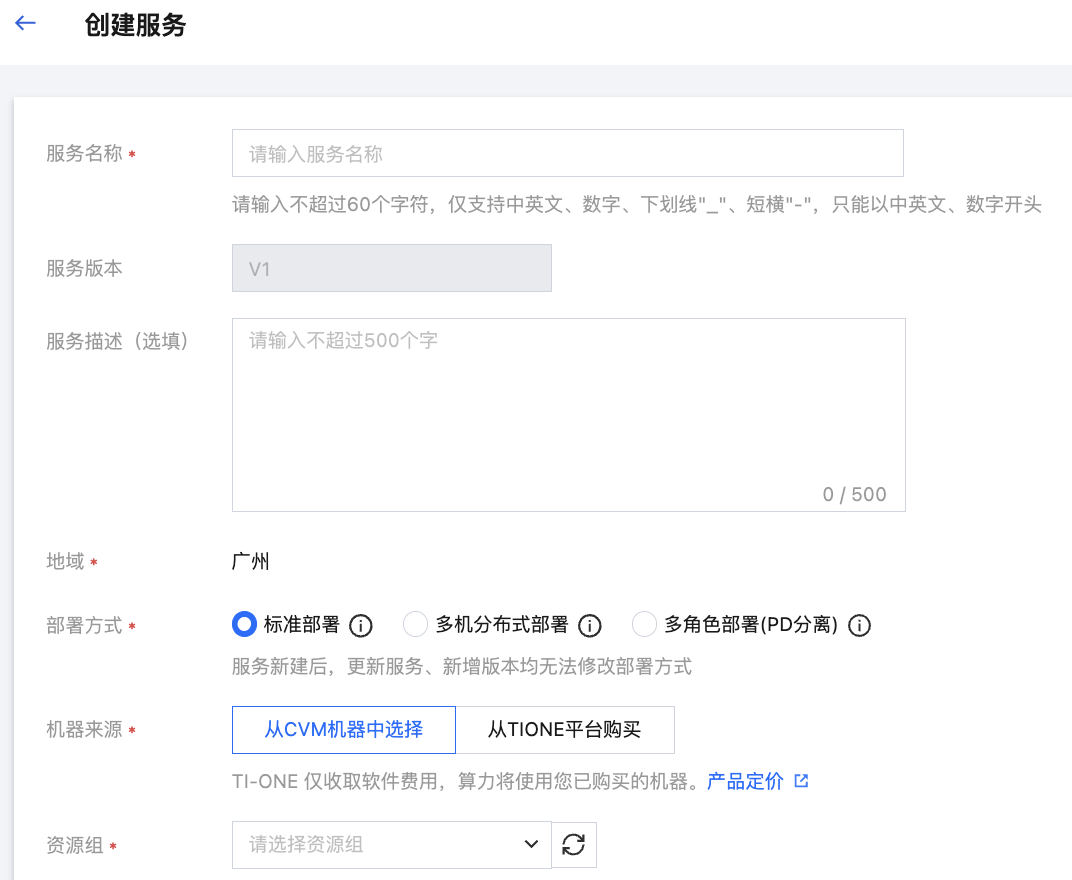
服务名称 | 服务的名称,按照界面提示的规则填写即可。 |
服务版本 | 版本号系统自动生成。 |
服务描述 | 可按需为服务配置描述信息。 |
地域 | 同账号下的服务按地域进行隔离,地域字段取值根据您在服务列表页面所选择的地域自动带入。 |
部署方式 | 支持多种部署方式: 标准部署:单副本下有1个实例运行,适用于大多数标准场景。 多机分布式部署:单副本下有多个实例协调运行,适用于模型需要多机并行的场景。 多角色部署(PD 分离):目前仅支持白名单开放,适用于服务需要分多个角色部署的场景(如 Prefill 和 Decode 角色),单副本下有若干角色,每个角色下有1个或多个实例协调运行。 注意: 服务新建后,更新服务、新增版本均无法修改部署方式,请新建的时候谨慎选择。 |
机器来源 | 可选择“从 CVM 机器中选择”或“从 TIONE 平台购买”: “从 CVM 机器中选择”模式下,可使用在资源组管理模块已购买的 CVM 机器的资源组部署服务,算力费用在购买资源组时已支付,启动服务时无需扣费。 “从 TIONE 平台购买”模式下,用户无需预先购买资源组,根据服务依赖的算力规格,启动服务时冻结两小时费用,之后每小时根据运行中的实例数量按量扣费。 |
资源组 | 若选择“从 CVM 机器中选择”模式,可选择资源组管理模块的资源组。 |
服务副本配置
参数填写说明:
参数 | 说明 |
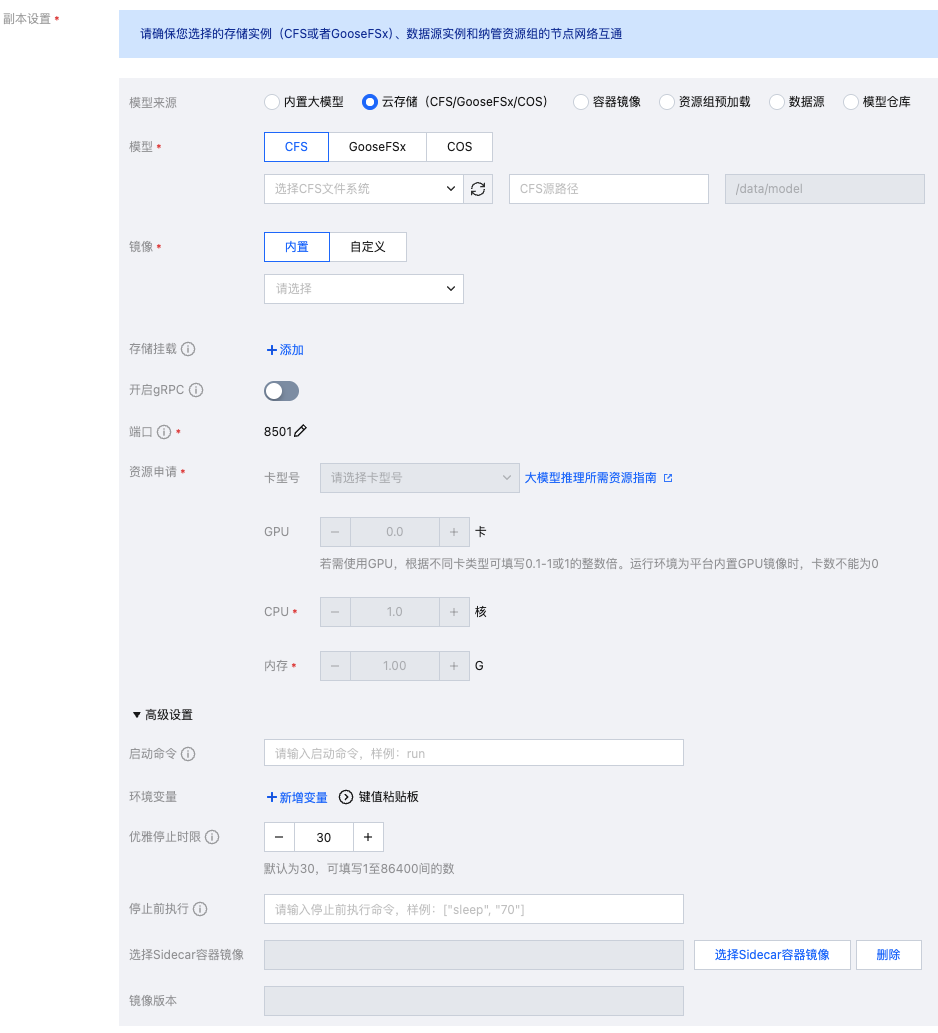
模型来源/模型 | 支持多种模型来源(不同部署方式下支持的模型来源也不完全一致): 内置大模型:适用于平台大模型广场内置提供的业界主流开源大模型。 云存储(CFS/GooseFSx/COS) CFS:部署服务所需的模型文件已放在 CFS 文件系统,选择模型所在的 CFS 实例,路径输入到模型所在路径的层级(如模型为精调出来的 checkpoint500,则路径输入到/a/b/checkpoint500这一层级)。CFS Turbo 仅支持机器来源为“从 CVM 机器中选择”时使用。 GooseFsx:部署服务所需的模型文件已放在 GooseFSx 文件系统,选择模型所在的 GooseFSx 实例,路径输入到模型所在路径的层级。GooseFSx 仅支持机器来源为“从 CVM 机器中选择”时使用。 COS:部署服务所需的模型文件已放在 COS 文件系统,选择模型所在存储桶实例和所在路径的层级。COS 仅支持机器来源为“从 CVM 机器中选择”时使用。 容器镜像:部署服务所需的自定义镜像已封装模型文件,不需要再进行模型文件挂载,且自定义镜像已上传至容器镜像服务 TCR 的场景。 资源组预加载:仅适用于“从 CVM 机器中选择”场景,用户提前将模型文件/镜像文件预加载到对应资源组,提高服务启动时的模型加载速度。 数据源:选择用户提前在“平台管理-数据源管理”模块新增好的数据源文件,数据源模块可提供统一的文件权限管理功能。 模型仓库:部署服务所需的模型文件已导入至模型仓库。 |
镜像 | 内置大模型:平台为每个内置大模型均提供了对应的内置运行镜像,用户无须修改。 云存储/资源组预加载/数据源:均支持2种类型的镜像选择 内置:平台提供各开源内置镜像以及腾讯自研推理加速镜像。 自定义:用户可自定义选择容器镜像服务,或输入自定义镜像地址(同时输入私有镜像仓库的账号密码,若有) 容器镜像:用户可直接选择已上传到容器镜像服务的自定义镜像,镜像中也包含了所需的模型文件。 模型仓库:运行环境会根据模型仓库的配置信息自动赋值。如需使用自定义镜像启动服务,镜像文件大小建议不超过34G。 |
存储挂载 | 新建推理服务时,支持用户在配置模型文件的同时,再额外配置输入输出的文件挂载路径。 |
开启 gRPC | 开关默认关闭。关闭时仅支持 HTTP 协议调用。开启后支持 gRPC 协议调用。 |
端口 | 支持配置容器对外暴露的端口,可填范围 1024-65535,但不包括 8502-8510,6006,9092。 额外注意两个特殊端口号:8500 是 gRPC 的默认端口,8501 是 REST 的默认端口,不可混淆使用。 |
资源申请/算力规格 | 1. 包年包月(资源组)模式下,可设置从所选资源组中申请多少资源用于启动当前服务。 2. 按量计费模式下,可按需选择启动当前服务所需的算力规格。 |
启动命令 | 支持配置容器的启动命令,选填。 |
环境变量 | 支持配置容器的环境变量,选填。 |
优雅停止时限 | |
停止前执行 | |
选择 Sidecar 容器镜像 | 支持用户自定义配置 Sidecar 容器镜像,选填。 |
服务特性配置

参数说明:
参数 | 说明 |
请求限流 | 支持配置服务限流值: 不限流默认单个服务最大的 QPS 为500,限流值大于500时,按照500进行限流,当购买服务升级包后,服务的总限流值以购买升级包的上限为准。 单副本 QPS 的限流值为单个实例的限流。 单副本最大并发数为单个实例的限流。 注意: 该限流值为单个副本的限流,当服务进行扩缩容时,服务整体限流值将按照设置的值 * 副本数进行更新;单个服务组最大的 QPS 为500,当服务组下设置的服务总限流值大于500时,按照500进行限流。 |
副本调节 | 手动调节:可以自定义设置服务的副本数量,副本数量最小为1。 自动调节:可以选择基于时间的定时策略、基于 HPA 的自动策略、或定时+HPA 的组合策略。该部分详细说明请查看 在线服务运营。  |
使用RDMA | 当副本数量或者单副本实例数量大于1时,若选择的卡型支持 RDMA,则可选择开启 RDMA。当开启 RDMA 后,服务会优先调度到支持 RDMA 的节点;当单节点 RDMA 网卡 IP 不足时,可能会调度到多节点。 |
调度策略 | 针对“标准部署”模式,支持用户自定义多副本时的节点调度策略: 优先占满整机:多副本调度时优先填满单个节点,以此减少碎卡概率。 优先分散部署:多副本调度时优先分散节点部署,以此提高服务高可用(请注意分散部署成功的前提是资源充足)。 |
是否生成鉴权 | 若开启,则服务调用时会进行签名认证,已启动的服务可在服务调用页面查看签名密钥及签名计算指引。 开启鉴权后,将会为您自动生成服务的首个密钥,您可在服务详情页-服务鉴权中查看并创建更多密钥。 |
CLS 日志投递 | 平台为用户提供免费的近15日服务日志存储,若需要持久化日志存储以及更灵活的日志检索能力、日志监控告警能力 ,可开启 CLS 日志投递,开启后服务日志会根据日志集与日志主题投递至腾讯云日志服务 CLS。 |
滚动更新策略 | 支持设置服务滚动更新策略,确保服务平滑升级: MaxSurge:表示滚动更新期间,允许超出所需规模的最大副本数量。 MaxUnavailable:表示滚动更新期间,允许不可用副本数量的上限。 |
健康检测 | Kubernetes 的健康检查机制,支持自动检测并恢复失败的容器,确保流量分发到健康的实例上。 存活检测:Liveness Probes,验证服务进程是否存活,容器是否正常运行。触发阶段:容器启动后持续运行(整个生命周期)。 就绪检测:Readiness Probes,确认服务已具备处理请求的能力,容器是否准备好接收流量。触发阶段:容器启动后持续运行(整个生命周期)。 启动检测:Startup Probes,对慢启动容器进行监控检查,检测容器内应用是否完成。触发阶段:仅在容器启动阶段运行(成功后停止)。 检查方法支持三种:HTTPGet、TCPSocket、Exec。 |
自动停止 | 平台支持自动停止模型服务,当开启该开关后,在线服务将在指定的停止时间自动停止,同时停止服务算力计费。 |
标签 | 支持为服务添加标签,用于按照标签进行授权等。 |
确认服务配置信息无误后,单击启动服务进行服务部署。服务部署过程中将为您创建网关并调度计算资源,需要等待一段时间,待服务成功完成部署时,服务状态将变为运行中。
部署参数最佳实践
本章节会针对服务部署的部分重要参数进行详细的解释说明,为用户提供一些参数配置的最佳实践建议。
健康检测
1. 健康检测是什么
健康检测是保障您的在线服务稳定运行的重要机制。它通过定期检测服务实例(Pod)的健康状态,确保流量只会被转发到健康的实例,并且在实例不健康时重启或替换,从而提升服务的可用性和可靠性。
TI-ONE 平台基于 Kubernetes 提供了三种类型的健康检测探针:
探针类型 | 启动探针(Startup Probe) | 就绪探针(Readiness Probe) | 存活探针(Liveness Probe) |
核心作用 | 检测容器内应用是否完成启动 | 检测容器是否准备好接收流量 | 检测容器是否正常运行 |
触发阶段 | 仅在容器启动阶段运行(成功后停止) | 容器启动后持续运行(整个生命周期) | 容器启动后持续运行(整个生命周期) |
失败后果 | 终止容器并重启 | 从服务负载均衡池中移除,停止流量转发(不重启容器) | 终止容器并重启 |
典型场景 | 慢启动应用(如Java服务预热、数据加载) | 依赖初始化完成(如数据库连接、配置文件加载) | 处理死锁、进程崩溃或不可恢复的异常 |
检测频率 | 低频(通常时隔较长,如10s) | 中频(根据业务需求调整) | 高频(快速发现异常,如5s) |
优先级 | 最高(启动期间禁用其他探针) | 中等 | 低 |
2. 健康检测的作用
提升服务可用性
通过就绪探针,确保只有准备好的实例才会接收流量,避免请求被发送到尚未就绪的实例,从而减少请求失败。
自动恢复故障
通过存活探针,检测到运行中的实例出现故障(如应用死锁但进程仍在)时,自动重启实例,快速恢复服务。
优雅处理启动和终止
对于启动较慢的应用,就绪探针可以避免在启动过程中就接收流量;对于需要优雅关闭的应用,就绪探针可以配合生命周期钩子,确保在终止前从负载均衡器中移除。
3. 如何配置健康检测
在 TI-ONE 平台上,您可以在新建或更新服务时,在参数表单中配置健康检测。您需要根据您的应用特点,选择合适的检测方式。
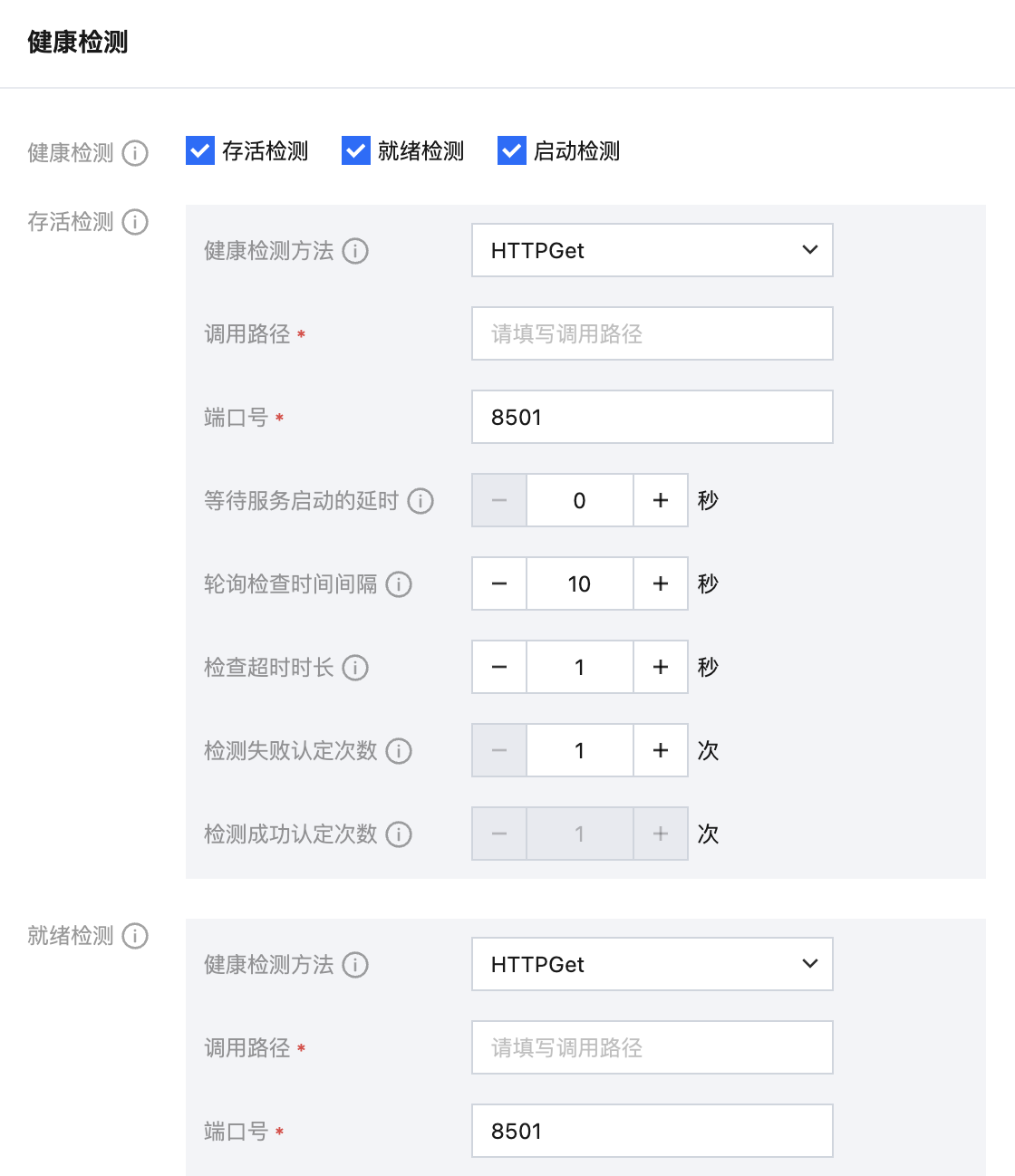
3.1 检测方式
TI-ONE 平台支持以下三种检测方式:
检测方式 | 方式说明 | 适用场景 | 配置示例 |
HTTP GET 检测 | 向容器内指定路径和端口发送 HTTP GET 请求,如果返回状态码在200到399之间,则视为成功 | Web 服务、API 服务 | 路径:/health,端口:8080 |
TCP Socket 检测 | 尝试与容器指定端口建立 TCP 连接,如果连接成功建立,则视为成功 | 数据库、缓存、非 HTTP 服务 | 端口:6379(Redis) |
Exec 命令执行检测 | 在容器内执行指定的命令,如果命令退出码为0,则视为成功 | 需要复杂检查逻辑的服务 | 命令:python check_health.py |
3.2 配置参数说明
三种探针支持的配置参数说明如下:
参数 | 参数说明 | 参数建议值 |
等待服务启动的延时 | 容器启动后,等待多久开始第一次检测。请根据应用启动时间设置,避免因应用尚未启动而误判 | 如:30-60秒,给应用足够的启动时间,避免误判 |
轮询检查时间间隔 | 每次检测的间隔时间,频率过高对 Pod 有较大的额外开销,频率过低无法及时反映容器错误 | 如:5-15秒,平衡实时性和系统开销 |
检查超时时长 | 每次检测的超时时间,超过则视为失败 | 如:3-5秒,避免因网络抖动导致误判 |
检测失败认定次数 | 连续检测失败多少次,才将实例标记为不健康 | 如:3次,连续3次失败才标记为不健康,避免瞬时故障误判 |
检测成功认定次数 | 连续检测成功多少次,才将实例标记为健康 | 如:1次,对于可快速自愈的瞬时故障,设置为1可尽快恢复服务 |
3.3 配置示例
假设您有一个 Web 服务,监听端口 8080,并且有一个健康检查接口 /health,该服务启动需要约30秒。
存活探针配置(建议):
检测方式:HTTP GET
调用路径:/health
端口号:8080
等待服务启动的延时:40秒(确保应用已启动)
轮询检查时间间隔:10秒
检查超时时长:5秒
检测失败认定次数:3
检测成功认定次数:1
就绪探针配置(建议):
检测方式:HTTP GET
调用路径:/health
端口号:8080
等待服务启动的延时:40秒
轮询检查时间间隔:5秒(就绪检测可以更频繁,以便快速加入负载均衡)
检查超时时长:5秒
检测失败认定次数:1(一次失败就标记为未就绪)
检测成功认定次数:1
注意:
如果您的服务没有专门的健康检查接口,可以使用根路径/或者使用 TCP 端口检测。对于非 Web 服务,可以选择 TCP 检测或命令执行检测。
4. 如何查看健康检测状态
在 TI-ONE 平台上,您可以通过以下方式查看健康检测的状态和事件:
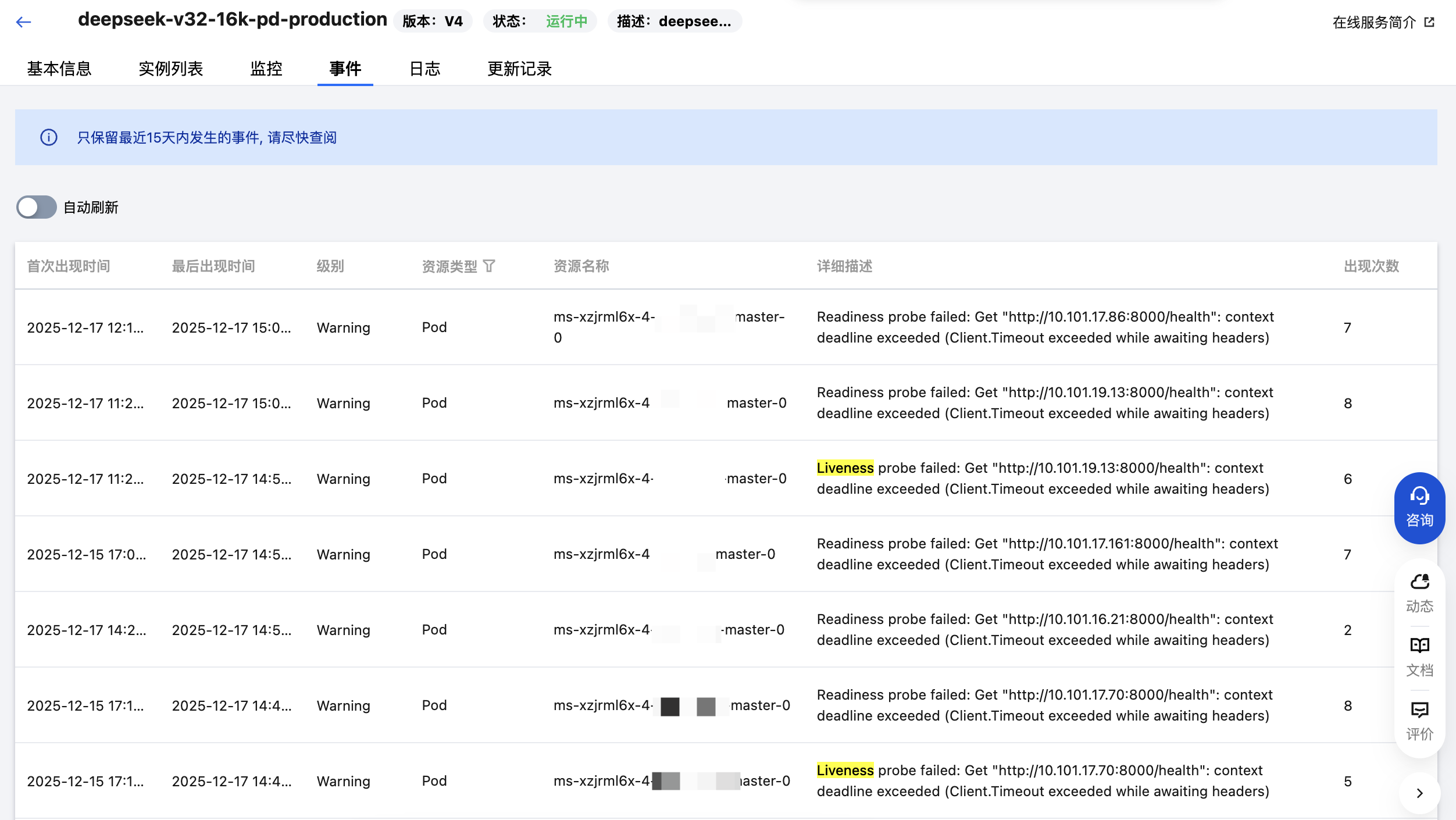
4.1 服务实例列表
进入在线服务详情页,查看“实例列表”Tab页面。每个实例会显示其当前状态(运行中、就绪中等)。如果实例因为健康检测失败而重启,您可以看到容器的重启次数和状态变化。
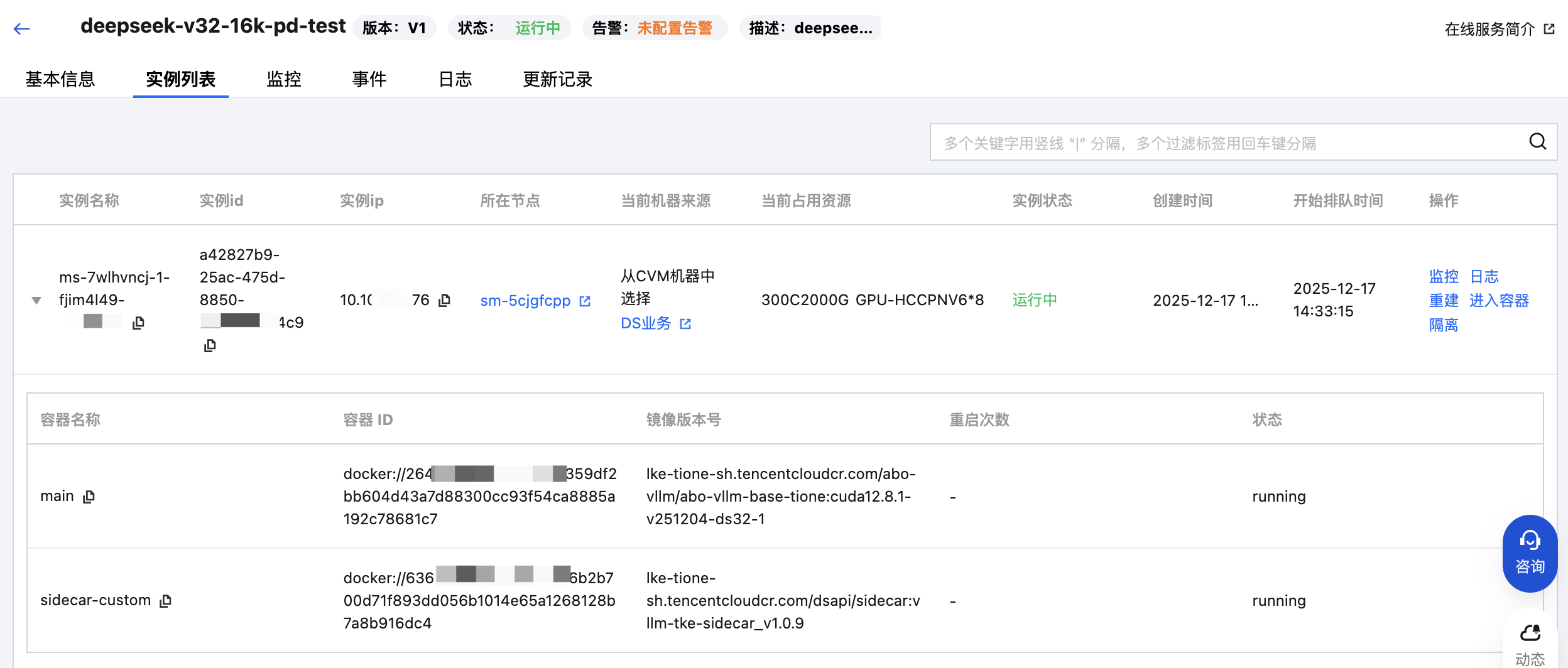
4.2 事件日志
进入在线服务详情页,查看“事件”Tab页面。平台会记录健康检测失败、容器重启等事件。您可以在这里看到具体的失败原因,例如“Liveness probe failed”或“Readiness probe failed”。