milvus Delete api写s3的流程
原创
milvus Delete api写s3的流程
原创
melodyshu
发布于 2024-02-23 16:57:29
发布于 2024-02-23 16:57:29
Delete api写s3的流程
milvus版本:v2.3.2
整体架构:
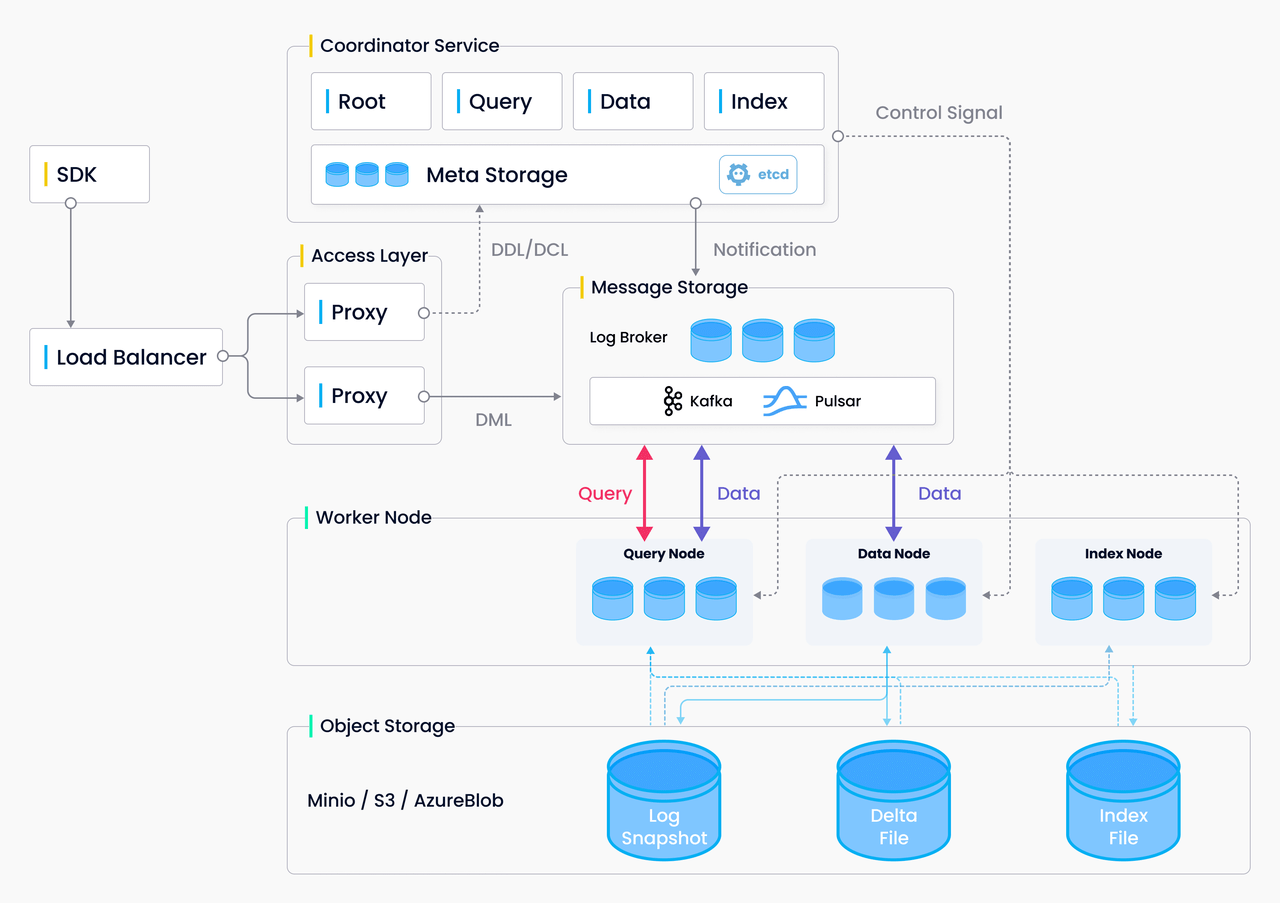
Delete 的数据流向
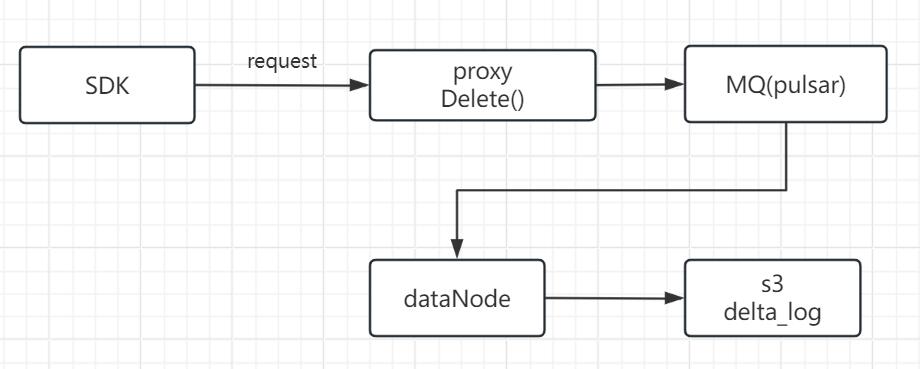
delete相关配置
dataNode:
segment:
insertBufSize: 16777216 # Max buffer size to flush for a single segment.
deleteBufBytes: 67108864 # Max buffer size to flush del for a single channel
syncPeriod: 600 # The period to sync segments if buffer is not empty.当collection已经有flushed文件,如果后续有insert和delete操作,这个配置文件控制这个行为。
s3文件不支持进行文件内容的编辑。因此需要有一种机制能够进行insert和delete。
delete在内存中(buffer)的流程
堆栈:
start()(internal\util\flowgraph\node.go)
|--go nodeCtx.work()(同上)
|--n.Operate(input)(同上)
|--dn.bufferDeleteMsg()(internal\datanode\flow_graph_delete_node.go)
|--dn.delBufferManager.StoreNewDeletes()(同上)func (m *DeltaBufferManager) StoreNewDeletes(segID UniqueID, pks []primaryKey,
tss []Timestamp, tr TimeRange, startPos, endPos *msgpb.MsgPosition,
) {
// 获取delDataBuf
buffer, loaded := m.Load(segID)
// 如果不存在则新建
if !loaded {
buffer = newDelDataBuf(segID)
}
// 将pks存入buffer
size := buffer.Buffer(pks, tss, tr, startPos, endPos)
m.pushOrFixHeap(segID, buffer)
m.updateMeta(segID, buffer)
m.usedMemory.Add(size)
metrics.DataNodeConsumeMsgRowsCount.WithLabelValues(
fmt.Sprint(paramtable.GetNodeID()), metrics.DeleteLabel).Add(float64(len(pks)))
}pks存储的是主键值。
这是对内存的操作。
delete写入s3的流程
Start()(internal\util\flowgraph\node.go)
|--go nodeCtx.work()(同上)
|--n.Operate(input)(同上)
|--dn.flushManager.flushDelData()(internal\datanode\flow_graph_delete_node.go)
|--m.handleDeleteTask()(internal\datanode\flush_manager.go)
|--m.getFlushQueue(segmentID).enqueueDelFlush()(同上)
|--q.getFlushTaskRunner(pos).runFlushDel()(同上)
|--runFlushDel()(internal\datanode\flush_task.go)
|--task.flushDeleteData()(同上)
|--t.MultiWrite(ctx, t.data)(internal\datanode\flush_manager.go)当达到syncPeriod或者buffer满或者执行flush操作,会触发写s3操作。
看看这个函数flushDelData():
// notify flush manager del buffer data
func (m *rendezvousFlushManager) flushDelData(data *DelDataBuf, segmentID UniqueID,
pos *msgpb.MsgPosition,
) error {
// del signal with empty data
if data == nil || data.delData == nil {
m.handleDeleteTask(segmentID, &flushBufferDeleteTask{}, nil, pos)
return nil
}
collID, partID, err := m.getCollectionAndPartitionID(segmentID)
if err != nil {
return err
}
// 编码解码器,提供序列化,反序列化功能
delCodec := storage.NewDeleteCodec()
// 序列化
blob, err := delCodec.Serialize(collID, partID, segmentID, data.delData)
if err != nil {
return err
}
logID, err := m.AllocOne()
if err != nil {
log.Error("failed to alloc ID", zap.Error(err))
return err
}
blobKey := metautil.JoinIDPath(collID, partID, segmentID, logID)
blobPath := path.Join(m.ChunkManager.RootPath(), common.SegmentDeltaLogPath, blobKey)
// 合成kvs
kvs := map[string][]byte{blobPath: blob.Value[:]}
data.LogSize = int64(len(blob.Value))
data.LogPath = blobPath
log.Info("delete blob path", zap.String("path", blobPath))
m.handleDeleteTask(segmentID, &flushBufferDeleteTask{
ChunkManager: m.ChunkManager,
data: kvs,
}, data, pos)
return nil
}delCodec.Serialize()返回的变量blob类型为*Blob。
// Blob is a pack of key&value
type Blob struct {
Key string
Value []byte
Size int64
RowNum int64
}blobPath为s3的文件路径。
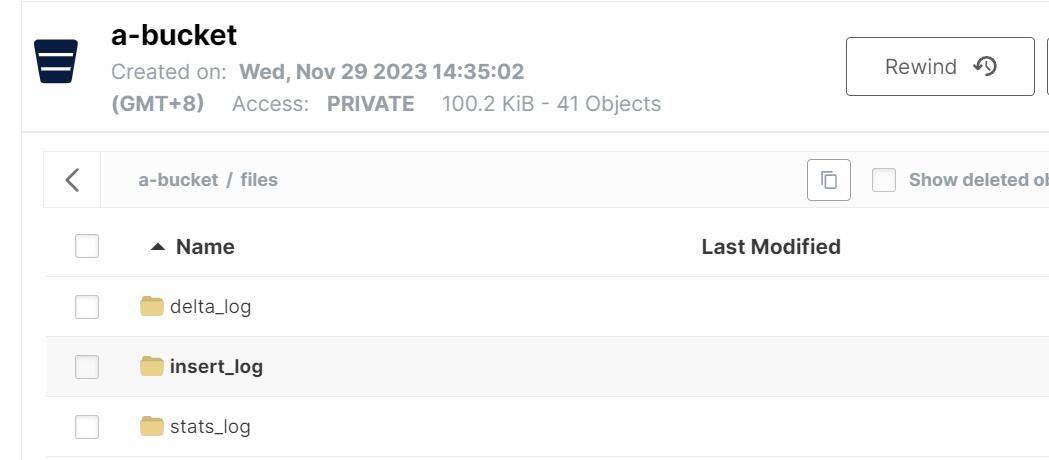
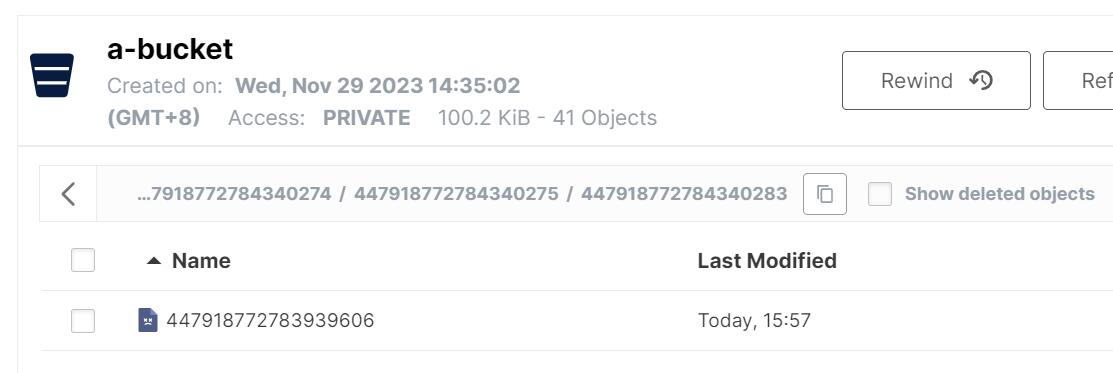
files/delta_log/447918772784340274/447918772784340275/447918772784340283/447918772783939606delta_log存储的是insert和delete增量数据。
s3的截图:
总结
1.delete/insert增量数据写入buffer。
2.满足一定条件buffer刷入s3。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号