关注背景信息的运动物体发现

关注背景信息的运动物体发现

CreateAMind
发布于 2024-06-05 18:27:06
发布于 2024-06-05 18:27:06
The Background Also Matters: Background-Aware Motion-Guided Objects Discovery
https://arxiv.org/abs/2311.02633


摘要
近期的研究表明,对象发现可以从视频数据中固有的运动信息中大大受益。然而,这些方法缺乏适当的背景处理,导致非对象区域被过度分割成随机片段。在无监督设置中,这是一个关键限制,因为无法区分对象片段和噪声。为了解决这个限制,我们提出了BMOD,一种背景感知的运动引导的对象发现方法。具体来说,我们利用从光流中提取的运动对象掩模,并设计了一个学习机制来将它们扩展到由运动和静态对象组成的真正前景。背景,作为学习到的前景类别的补充概念,然后在对象发现过程中被隔离。这使得对象发现任务和对象/非对象分离的联合学习成为可能。我们在合成和现实世界数据集上进行的实验表明,将我们的背景处理与各种尖端方法相结合每次都能带来相当大的改进。具体来说,我们在大幅度提高对象发现性能的同时,为对象/非对象分离建立了一个强有力的基线。
1. 引言
基于深度学习的方法已经在解决各种计算机视觉任务方面取得了显著的成功[5]。然而,这些方法的高性能严重依赖于大量标记数据的可用性:稀疏的标签或标签质量的下降削弱了有监督方法的有效性[37]。当处理像分割这样的密集任务时,这一限制变得具有挑战性,因为获取准确的标签需要大量的资源。这一观察激发了众多研究提出替代架构,包括弱监督[19, 40]、半监督[24, 39]和无监督方法[27, 36],旨在以最少的监督处理视觉任务。
在这项工作中,我们解决的是在不使用人工注释的情况下在视频中定位对象的任务。这个任务通常被当作一个分割问题来处理[2, 8, 17],由于其在静态图像方面的优势,特别适合视频数据。具体来说,从视频中提取的运动信息提供了一种获取移动对象定位的免费伪标签的方法。这使得探索能够利用运动线索的自监督方法的动机变得更加强烈。此外,围绕对象定义的模糊性,这一直是图像中对象发现的一个挑战[15, 34],在视频数据中可以得到解决。具体来说,依靠运动线索来定位对象,按设计提供了对象是什么的定义:我们认为任何能够表现出独立运动的实体都是对象。这个定义甚至符合人类感知,如[30]中所证明的:在我们的感知中,我们将观察到的场景划分为能够运动而保持连接的部分。一些最近的方法从这一结果中汲取灵感,并在此基础上构建,以解决移动对象定位[6]。
最近,以对象为中心的学习架构展示了解决对象发现任务的显著潜力[21]。它作为一种新的基于深度学习的方法出现,以无监督的方式将输入图像分解为有意义的区域。尽管最初在简单的合成图像数据集上得到验证,但许多后续工作提出了这种架构的变体,将其扩展到视频数据以及更复杂的场景。这些工作主要集中在修改重建空间(光流[17],深度[8])和增强编码器的能力[29]。最近,一些工作引入了使用运动线索来指导插槽学习过程,并提供了这种引导信号在解决复杂场景中的对象发现方面的有效性的证据[1, 2]。
我们的工作符合这条研究线,但解决了现有方法未覆盖的一个特定问题,即对象发现任务中的背景控制。以前的工作没有专注于学习背景模式,导致背景被分割到插槽中的噪声区域,如图1所示。这种场景的过度分割甚至没有受到常用指标的惩罚,因为分割质量仅在前景区域进行评估。然而,在真实世界环境中,当真实标签不可用时,我们无法区分对象和背景片段。因此,这项工作的目标是在解决多对象发现任务的同时,学习这一对象/非对象边界。

我们提议利用运动线索来联合学习多个对象的发现和对象性任务(前景/背景分离)。运动线索是从光流中提取的运动对象掩模。对于第一项任务,每个运动掩模被用来引导一个插槽的注意力。对于第二项任务,我们提议学习从移动的前景(汇总的运动掩模)泛化到包含运动和静态对象的真实前景。互补的掩模,即背景,被定位在一个特定的插槽内,与其他所有插槽竞争,以隔离其独特的模式。
我们的贡献可以总结如下:
- 我们提出了 BMOD(Background-aware Motion-guided Objects Discovery),这是一个简单而有效的学习机制,可以在解决对象发现任务的同时对背景进行建模。据我们所知,这是第一种无需人工监督同时处理这两项任务的方法。
- 我们展示了对背景的建模不仅可以实现更精确的对象发现(自动过滤噪声片段),还可以改善前景对象的定位。这验证了我们的洞见:控制背景可以减少插槽捕获的噪声量,使模型更容易学习对象模式。
- 我们为对象发现任务中的对象性学习建立了一个新的基线。我们首次引入了计算适合评估对象性学习任务的指标(Jaccard 分数),或者通过同时评估两项任务(all-ARI)。
- 我们通过在具有挑战性的 TRI-PD 数据集以及真实世界数据集 KITTI 上进行的全面实验,证明了我们方法的有效性。实验表明,多种尖端方法从我们的对象性学习机制中获得了显著优势,而没有增加架构复杂性。此外,我们展示了我们的方法,当结合了最近 DINOv2 [23] 预训练提供的丰富特征后,带来了相当大的性能提升。这提供了当前方法中表示瓶颈的证据,通过使用改进的特征来克服。
2. 相关工作
2.1. 图像中的对象发现
图像中的对象发现是在不使用人工注释的情况下定位对象的任务。这项任务的开端是以启发式为基础的对象提议方法,这些方法依赖于图像的过度分割以及各种相似性度量来层次地合并相似的区域[25, 32, 41]。由于它们的精确度非常低,在无监督设置中使用这些对象候选一直很具挑战性。
在深度学习时代,对象发现已经从深度特征中受益,这些特征要么来自通过ImageNet分类任务学习的CNN[33-35],要么来自最近的自监督预训练,特别是视觉变换器(ViTs)[15,27,36]。在第一类中,方法通常旨在发现数据集结构,连接最紧密/相似的对象提议成为顶级对象候选。在第二类中,方法主要被激励去研究自监督特征空间中的无监督聚类,鉴于ViTs展示的分割属性[4]。在这两类中,方法仅依赖于图像模态内部学习到的语义信息,这限制了它们分离对象实例的能力。
最近,被称为组合生成模型的方法论组作为深度学习基础的替代传统聚类方法出现了[20]。值得注意的是,MONet[3]采用注意力机制专注于个别场景部分。然后,输入图像和注意力图被一起传入变分自编码器模块,只重建相应掩模中突出显示的场景部分/对象。IODINE[10]用迭代推理替换了一次性注意力机制,以通过多个步骤细化对图像的理解。在这一类中,SCALOR[13]将生成过程适应了更多的对象,而Slot-Attention[21]提出了一种更有效的对象发现架构,只需单次图像编码步骤。[21]通过在自编码器架构的潜在空间内强制解耦来发现对象。
所有以前的方法,无论是基于启发式的还是深度学习的,都受到对象定义模糊的限制。这一限制阻碍了基于定义的方法的设计和客观评价标准的建立。现在,努力正被转向视频数据,这些数据提供了更通用的对象定义手段(见第2.2节)。在这项工作中,尽管我们专注于分析视频数据,我们提供了与最新基于图像的方法的比较,应用于单独的帧。
2.2. 视频中的对象发现
在这项工作中,我们解决的是视频中对象发现的问题,这与视频对象分割(VOS)是一个不同的任务。后者更多是关于运动分割,目标是在视频中定位一个显著的运动对象[38]。相比之下,我们解决的任务包括定位能够移动的对象,即使它们在分析序列中保持静止。
视频中的对象发现作为一个有前景的研究领域而出现,这在很大程度上是由视频与静态图像相比内在的运动信息所驱动的。利用视频数据定位对象的动机并不新鲜;最早的方法通常从对象候选中选择兴趣区域作为时空管,最大化跨视频的相似性,同时保持时间一致性[18]。
最近,被认为是对象发现有前途解决方案的插槽-注意力架构[21]的出现,激发了许多努力将其扩展到视频数据。SAVI[17]和Karazija等人[16]将光流纳入了更符合目标分割任务的重建空间。[17]还提出了对初始帧进行弱监督的使用,例如要在整个序列中跟踪的对象中心。按设计,[17]呈现了仅限于定位运动对象的限制。相比之下,SAVI++[8]也通过重建更通用的深度信号来定位静态对象。[8]还展示了数据增强的潜力,这在无监督设置中经常被低估。在利用运动线索进行对象发现的方法中,Bao等人[1]引入了对插槽学习的显式引导,使用从光流中提取的运动对象掩模。STEVE[29]是一项并发的工作,研究了使用更强大变换器解码器的使用。在这些先前方法的发现基础上,MoTok[2]通过一个标记化的重建空间提出了一个更强大的运动引导插槽注意力架构。
在之前的方法中,注意力只被允许用于发现前景对象,而没有考虑适当的背景建模。然而,我们的洞见是,适当的背景建模可以防止每个插槽捕获的噪声区域,这有利于对象结构的学习。我们在这项工作中提出了一个完整的运动引导对象发现架构,以联合学习多个对象定位任务和前景/背景分离。
2.3. 无监督背景分割
早期解决前景/背景分离任务的尝试集中在图像模态上。在背景简洁的简单场景中,方法通常依赖于颜色空间或其他手工设计特征中的阈值处理或二元聚类[14]。
一个更为近期的类别,被称为显著性检测方法,旨在以无监督的方式从背景中提取显著的前景。特别是,LOST和TokenCut[27, 36]使用了预训练视觉变换器(ViTs)[4]的深度特征。LOST将对象区域定义为与整张图片相关性最小的区域,而TokenCut研究了将谱聚类[26]应用于自监督ViTs特征。最近,FOUND[28]提出将背景作为在ViT激活图中激活最少的类别来发现,然后使用轻量级分割头进行细化。这种方法被提出作为克服对象定义模糊性的一种方式。然而,我们认为对象定义的问题对于背景类别仍然有效,因为它们是补充的语义概念。
在视频模态中,受到显著关注的二元分割是运动分割。在这方面已经建立了活跃的基准,并以视频对象分割(VOS)[38]的术语进行定义。虽然这为对象识别提供了一个明确标准(即运动对象),但我们认为这个定义是限制性的。实际上,如果不同时定位静态对象,我们只能对场景有一个有限的理解。
相比之下,我们的方法在设计上提出了前景/背景分离,目标前景由运动和静态对象组成。通过从光流中提取运动线索,确保了我们方法在复杂场景中的鲁棒性,这通常对颜色空间中背景复杂度的增加不敏感。此外,我们还将前景类别分解为对象实例,这是以前背景分割方法未涵盖的。
3. 方法
3.1. 背景:运动引导的插槽注意力用于对象发现
由于我们的方法是基于一个涉及使用运动信息的插槽注意力架构[21],我们首先简要描述这两种方法。
插槽注意力架构[21]被提出作为经典的无监督聚类方法[20]的深度学习替代方案。它由一个自动编码器架构组成,其中潜在空间被划分为称为插槽的嵌入向量。该架构在这些插槽之间进行竞争,以提供对输入图像的全面解释。通过使用小型解码器来鼓励划分图像的机制:每个插槽单独通过解码器传递。小型解码器无法从单个插槽解释整个场景,这迫使特征在插槽之间被分割,鼓励将图像划分为有意义的区域。
在我们的方法中,我们基于一个利用运动线索指导插槽学习的插槽注意力的最新变体[1]。具体来说,该方法接收T个视频帧序列作为输入。每个帧通过CNN编码器传递以提取特征。然后使用convGRU模块结合T帧的特征,以获得每个帧I_t的空间时间信息H_t。然后通过注意力模块将此表示分配给K个插槽。具体来说,给定k、q、v三个可学习的线性投影,特征H和插槽S之间的注意力被计算为W = √(1/D)k(H) · q(S) ∈ R^(N×K),其中N是特征图的大小,D是投影后特征的维度。

注意力用于更新当前插槽状态St = Wtv(Ht),其中Wt使用帧It−1的插槽状态计算。[1]通过假设可以获得T帧序列的M个运动掩模,引入了运动引导的使用。这些掩模被调整大小以匹配注意力图W的尺寸,然后通过一个二分图匹配算法与它们配对。然后,在这些掩模m和学习到的注意力图W之间进行运动监督。该方法表明,引入运动线索取代了关于单个插槽解码的初始归纳偏差,这减少了内存需求。尽管这种架构展示了对没有相应掩模的对象的泛化能力,但它仍然受到对象/非对象模糊的影响,因为没有监督的插槽可能包含对象或背景区域。这激发了我们的工作,我们在接下来的部分中描述。
3.2. 利用运动线索对背景类别进行建模

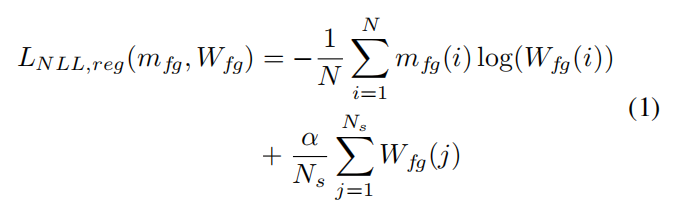
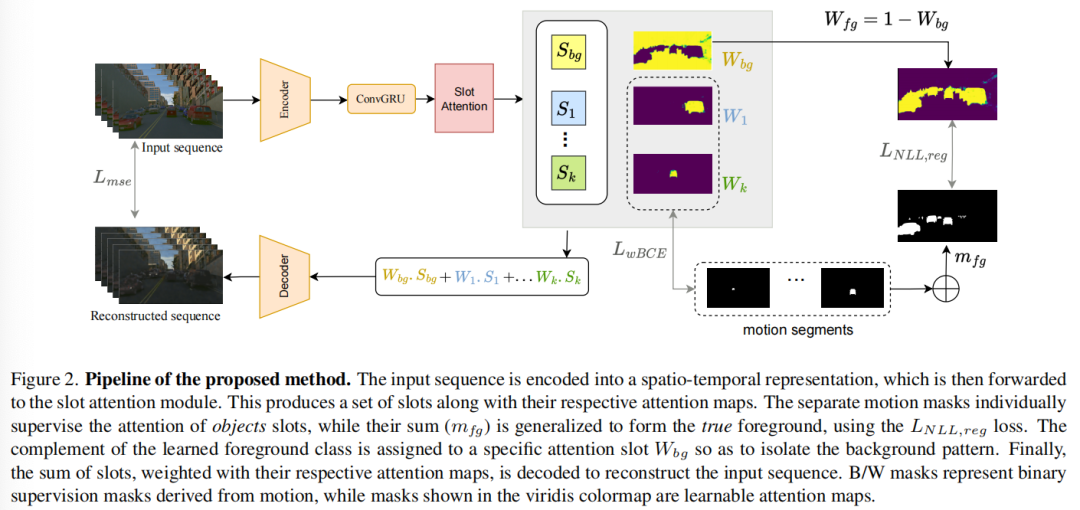

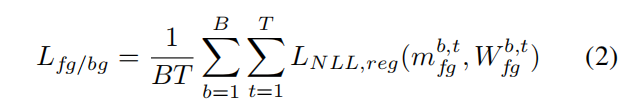
3.3. 背景感知的运动引导对象发现

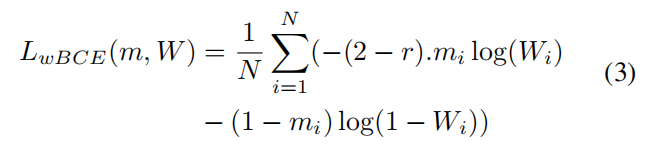

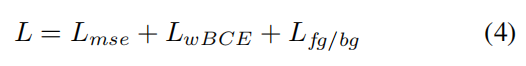
4. 实验
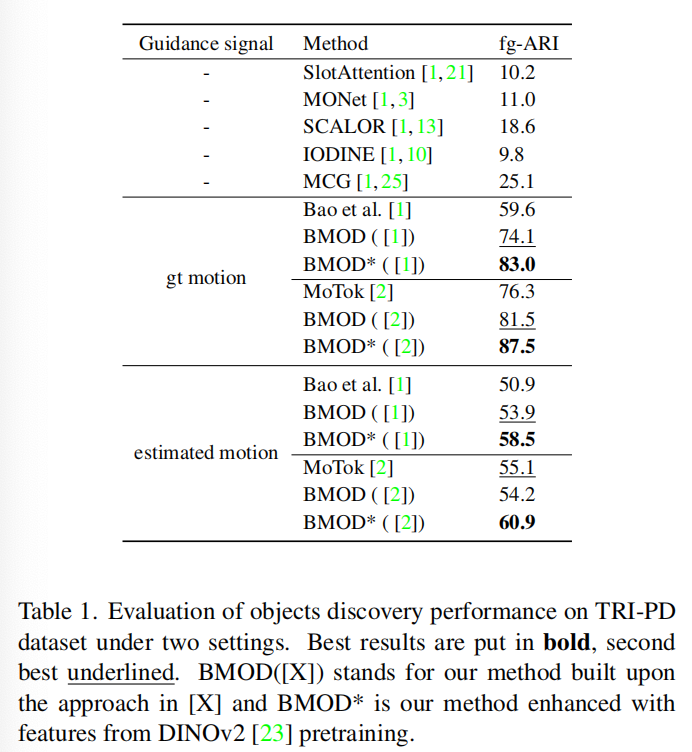
我们在两个视频对象发现基准上进行实验:ParallelDomain (TRI-PD) [1] 和 KITTI [9]。
我们进一步展示了所提出的背景学习机制的普适性,将其集成到另一种最先进的方法[2]中。在TRI-PD上的这种比较在两个不同的设置下进行,它们在运动掩模的来源上有所不同。在无监督设置中,结果表中称为“estimated”,这些掩模是从光流中获得的(见第4.3节)。在第二个设置中,称为“gt”,使用运动对象的真实实例掩模作为引导信号。这种设置下的结果为无监督方法提供了一个上限。
4.1. 数据集
ParallelDomain (TRI-PD):由[1]引入,TRI-PD是最近的城市驾驶场景对象发现的基准。这是一个具有挑战性的数据集,由密集、逼真的场景组成,它还为各种视觉任务提供了有用的支持,因为它包括多样化的语义和实例级注释。按照[1],我们在每个长200帧的924个视频片段上训练我们的对象发现模型。评估在另外的51个视频序列的独立测试集上执行。
KITTI 是一个真实世界的城市场景视频数据集,也是各种感知任务的活跃基准。我们使用 KITTI 基准测试的所有原始数据(无注释),总共147个视频。按照之前的作品[1, 2],评估在 KITTI 的实例分割子集上进行,由200帧组成。
4.2. 指标
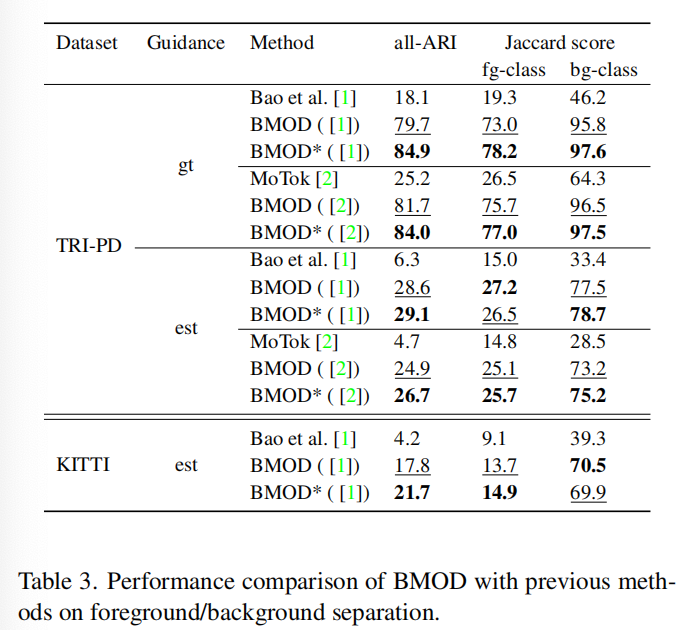
fg-ARI 和 all-ARI:调整的 Rand 指数 (ARI) 是一种度量,用于以排列不变的方式来量化两个聚类(真实和预测)之间的相似性。在对象发现的文献中,研究通常计算 fg-ARI,即前景区域中的 ARI。这个指标没有考虑背景区域的分割质量。我们在本文中引入了 all-ARI 指标的计算,通过也将背景类别纳入真实聚类。在 all-ARI 中,既评估了前景对象的发现,也评估了背景分割的质量。
Jaccard 分数:Jaccard 分数被计算为两个标签集:真实标签和预测标签的交集大小与并集大小的比率。我们使用这个指标来评估前景/背景类别分离的质量。两个类别的最终得分是所有帧中 Jaccard 分数的平均值。
4.3. 实现细节
基础设置(BMOD):在这种设置中,我们使用了一个没有预训练的resnet18编码器[11]。为了公平比较,我们遵循了我们将背景处理机制整合进去的方法[1, 2]的相同训练计划。具体来说,我们使用批量大小为8,输入序列长度为T = 5。帧大小分别调整为TRI-PD的(480 × 968)和KITTI的(368 × 1248)。在背景建模中涉及的正则化强度α被设置为TRI-PD的0.2和KITTI数据集的0.4。在无监督设置中,我们使用与以前的方法[1, 2]相同的运动掩模。这些是使用[7]提出的方法生成的,该方法将光流映射到实例掩模。光流是使用RAFT[31]计算的,映射是在合成数据集FlyingThings3D[22]上学习的。按照以前的方法,训练KITTI上模型时,使用在TRI-PD数据集上训练并使用估计的运动掩模进行初始化。
在TRI-PD上的评估按照[1]中的协议进行,其中将T帧大小的窗口(与训练期间相同大小)连续传递给模型。在KITTI数据集中,由于测试帧在时间上没有关联,评估是对每个帧单独进行的。
增强设置,使用自监督预训练(BMOD*):在这种设置中,我们用使用最近的DINOv2方法[23]预训练的ViT-S/14编码器替换了resnet18编码器。为此,我们调整输入帧的尺寸以适应ViT的补丁大小。输入尺寸分别变为TRI-PD的(490 × 980)和KITTI的(378 × 1260)。我们测试了整合DINOv2论文中描述的多尺度特征。具体来说,我们从ViT模型的最后4层提取特征,我们将它们连接起来,得到大小为384×4的新嵌入向量,空间尺寸以14的因子下采样。在将这些特征图传递给convGRU之前,我们将它们上采样以匹配resnet18编码器产生空间尺寸,结果是以4的因子下采样。
4.4. 无监督对象发现
我们重申,我们工作的主要目标是启用背景处理,以实现更精确的对象发现。表1和表2中的结果表明,这种建模还改善了前景对象的定位(例如,在无监督设置下,我们观察到BMOD([1])的fg-ARI提高了3%)。这验证了我们的假设,即隔离背景最小化了学习到的注意力图中随机片段的存在,这有利于对象结构的正确学习。尽管我们在一次测试中(BMOD([2]), 估计,表1)观察到fg-ARI的轻微下降(-0.9),我们的在更全面的all-ARI指标上带来了显著的性能提升(+20.2,表3)。当我们使用自监督预训练(BMOD*)时,我们的结果得到了进一步的改善。鉴于这些特征中包含的丰富语义和深度信息[23],这是合理的:对象更容易被捕捉为独立运动、一致深度和类似语义的区域。
4.5. 利用运动线索进行背景建模
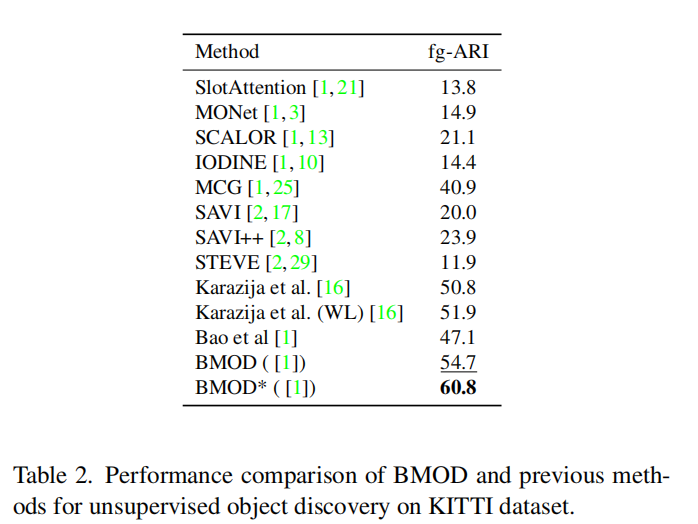
在这一部分中,我们突出了我们的主要贡献,即在没有人类监督的情况下学习对象/非对象边界。我们使用两种不同的指标来评估这项任务,即all-ARI和Jaccard分数(见4.2节)。我们回顾一下,在方法中,背景插槽是已知的,因为它是通过设计来约束的。因此,Jaccard分数的计算是直接的。然而,对于以前的方法,没有背景类的可用信息。为了公平比较,我们认为在这些方法中,所有插槽返回的最大片段作为背景。即便如此,表3中的结果显示了我们的方法在两个测试设置中带来的明显改进:有运动监督和无监督。特别是,将我们的训练机制整合到[1]中,在无监督设置下,TRI-PD上的all-ARI显著提高了+22.3,并且在KITTI数据集上进一步增强了+13.5。
我们还可以得出的另一个观察是,对于fg-ARI和fg/bg分离任务,gt和estimated两种设置之间存在很大的差距(上限结果非常高),这表明通过解决伪标签的质量有极大的改进潜力。
5. 消融和进一步分析
5.1. 目标函数组成的分析
在这一部分中,我们研究了我们目标函数的组成。首先,我们测试了一种更朴素的方式来隔离背景,通过明确地将非运动背景放置在一个插槽的注意力图中,并使用BCE损失。正如所料,这种方法未能捕获大部分前景对象,导致fg-ARI严重下降。实际上,在估计的掩模中,非运动背景包含了所有静态对象和一些移动但难以捕获的实例。所有这些元素在以前的测试中都被考虑为背景。另一个测试是将正则化应用于整个注意力图。有人可能被激励这样做是为了减少估计运动掩模中包含的噪声区域,但这并不是最优的,因为它鼓励模型也减弱对象区域的激活。最后,我们测试了我们提出的损失函数的变体,没有在第3.3节中描述的动态加权BCE,而是设置了一个固定的权重为一。正如所料,当我们的方法中有一个群体/类别占主导地位(背景)时,不考虑对象大小,鼓励模型将更多的对象放在那个群体中,导致对象丢失(见表4)。

这里没有报告all-ARI结果,因为在fg-ARI有显著损失时,它们并不提供信息。在这种情况下,一个高的all-ARI意味着对象被错误地归属于占主导地位的类别(背景)。然而,我们的目标是在不损害捕获对象能力的情况下,处理背景中的噪声。
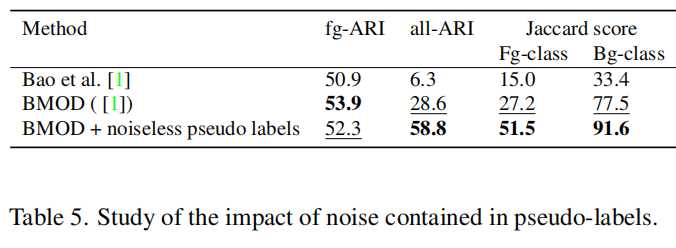
5.2. 提高无监督设置性能:无噪声伪标签的增益
在这一部分中,我们研究了在无监督设置中可以实现的上限性能,这对应于从光流中提取的运动对象的伪掩模的使用。需要注意的是,这些估计的标签会受到由相机运动引起的大量噪声的影响。这些噪声以随机片段的形式出现,用于引导插槽学习。在这项研究中,我们应用了一个与被分析场景的性质相关的简单启发式方法,来过滤掉这种噪声。由于我们旨在定位驾驶场景中的对象,这些对象不太可能位于帧的顶部,我们对对象的位置应用了启发式方法,过滤掉图像第一上行的任何片段。正如下面所见,这种简单的启发式方法为all-ARI提供了更强的基线,同时保持了对象定位性能(等效的fg-ARI)。这表明该方法改进的潜力与伪标签的质量有关,这为在这个领域的进一步探索提供了理由。
6. 结论
在这项工作中,我们提出了一种对象发现方法,它考虑了背景这一特殊的语义概念,在将场景分解为对象区域的同时将其隔离。我们通过计算适应的指标展示了我们的方法在无人类监督的情况下分离对象/非对象区域的有效性。此外,对象定位受益于背景建模,这一重要结果得到了我们方法引起的噪声减少的证实,使我们能够更好地专注于对象区域。我们希望这项工作中提出的基线能够激发对对象发现中背景建模的进一步研究。
进一步的分析显示了通过提高运动掩模的质量来扩展方法性能的潜力。我们相信这值得在未来的工作中进一步探索。最后,考虑到我们产生的片段中噪声的减少,这项工作为重新使用发现的对象打开了视角,例如,通过伪标签方法。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-06-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号