day 8 拟时序分析
原创

单样本
输入数据
输入数据是降维聚类分群注释的数据
做拟时序分析通常不是拿全部的细胞,而是拿感兴趣的一部分。用subset提取子集即可。因为要使用差异基因来排序,所以要两类及以上细胞。例如下面选择NK和CD8 T细胞;如果只做一类细,就需要二次分群(后面介绍)
rm(list = ls())
library(Seurat)
library(monocle)
library(dplyr)
load("../day5-6/sce.Rdata") #加载单样本数据
scRNA = sce
scRNA$celltype = Idents(scRNA) #新增细胞类型一列
scRNA = subset(scRNA,idents = c("NK","CD8 T")) #levels(Idents(scRNA)) #查看目标细胞
#抽样节省资源
set.seed(1234)
scRNA = subset(scRNA,downsample = 100)创建CellDataSet对象
newCellDataSet()创建count矩阵的对象
ct <- scRNA@assays$RNA$counts
gene_ann <- data.frame(gene_short_name = row.names(ct), row.names = row.names(ct))
fd <- new("AnnotatedDataFrame",data=gene_ann) #featureData
pd <- new("AnnotatedDataFrame",data=scRNA@meta.data) #临床信息
sc_cds <- newCellDataSet(
ct, phenoData = pd,featureData =fd,
expressionFamily = negbinomial.size(),
lowerDetectionLimit=1)
sc_cds <- estimateSizeFactors(sc_cds)
sc_cds <- estimateDispersions(sc_cds)选择差异基因来构建细胞发育轨迹
选择基因有不同的策略,我这里还是differentialGeneTest,官网是按照平均表达量大于某个数字。
fdif = "diff_test_res.Rdata"
if(!file.exists(fdif)){
diff_test_res <- differentialGeneTest(sc_cds,
fullModelFormulaStr = "~celltype",
cores = 4)
save(diff_test_res,file = fdif)
}
load(fdif)
ordering_genes <- row.names(subset(diff_test_res, qval < 0.01))
#查看基因,筛选适合用于排序的,设置为排序要使用的基因
head(ordering_genes)
length(ordering_genes)
sc_cds <- setOrderingFilter(sc_cds, ordering_genes)
#画出选择的基因
plot_ordering_genes(sc_cds) #纵坐标是基因表达量的变异性(离散性),横坐标是每个基因在所有细胞种的平均表达量
sc_cds <- reduceDimension(sc_cds) #降维
sc_cds <- orderCells(sc_cds) #细胞排序多样本
类似的步骤,但几处不同:
输入数据(数据不同)
rm(list = ls())
library(Seurat)
library(monocle)
library(dplyr)
load("../day7/scRNA.Rdata") #加载单样本数据
scRNA$celltype = Idents(scRNA)
scRNA = subset(scRNA,idents = c("CD8+ T-cells","NK cells"))
set.seed(1234)
scRNA = subset(scRNA,downsample = 100)创建CellDataSet对象(相同)
newCellDataSet()创建count矩阵的对象
ct <- scRNA@assays$RNA$counts
gene_ann <- data.frame(gene_short_name = row.names(ct), row.names = row.names(ct))
fd <- new("AnnotatedDataFrame",data=gene_ann)
pd <- new("AnnotatedDataFrame",data=scRNA@meta.data)
sc_cds <- newCellDataSet(
ct, phenoData = pd,featureData =fd,
expressionFamily = negbinomial.size(),
lowerDetectionLimit=1)
sc_cds <- estimateSizeFactors(sc_cds)
sc_cds <- estimateDispersions(sc_cds)选择差异基因来构建细胞发育轨迹(不同:differentialGeneTest和reduceDimension的参数不同)
fdif = "diff_test_res2.Rdata"
if(!file.exists(fdif)){
diff_test_res <- differentialGeneTest(sc_cds,
fullModelFormulaStr = " ~ celltype + orig.ident",
reducedModelFormulaStr = " ~ orig.ident",
cores = 8)
save(diff_test_res,file = fdif)
}
load(fdif)
ordering_genes <- row.names(subset(diff_test_res, qval < 0.01))
sc_cds <- setOrderingFilter(sc_cds, ordering_genes)
plot_ordering_genes(sc_cds)
#降维排序
sc_cds <- reduceDimension(sc_cds,residualModelFormulaStr = "~orig.ident")
sc_cds <- orderCells(sc_cds)可视化展示
发育轨迹图
p123很清晰的展示了pseudotime、state和celltype是怎样变化的: Pseudotime数值从小到大就是顺序就是推断的发育顺序,在这里越深就是时间与早;和State是一致的
library(ggsci)
p1 = plot_cell_trajectory(sc_cds)+ scale_color_nejm()
p2 = plot_cell_trajectory(sc_cds, color_by = 'Pseudotime')
p3 = plot_cell_trajectory(sc_cds, color_by = 'celltype') + scale_color_npg()
library(patchwork)
p2+p1/p3
#多样本的添加这个可以看去批次效应
plot_cell_trajectory(sc_cds, color_by = 'orig.ident')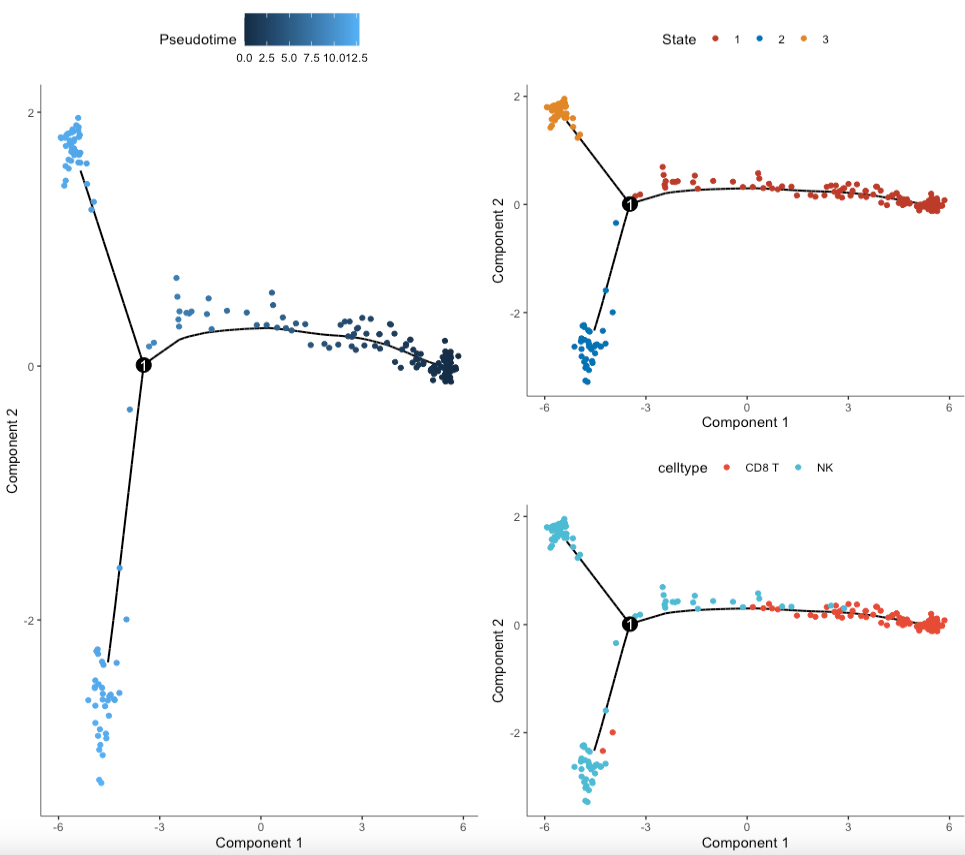
单样本
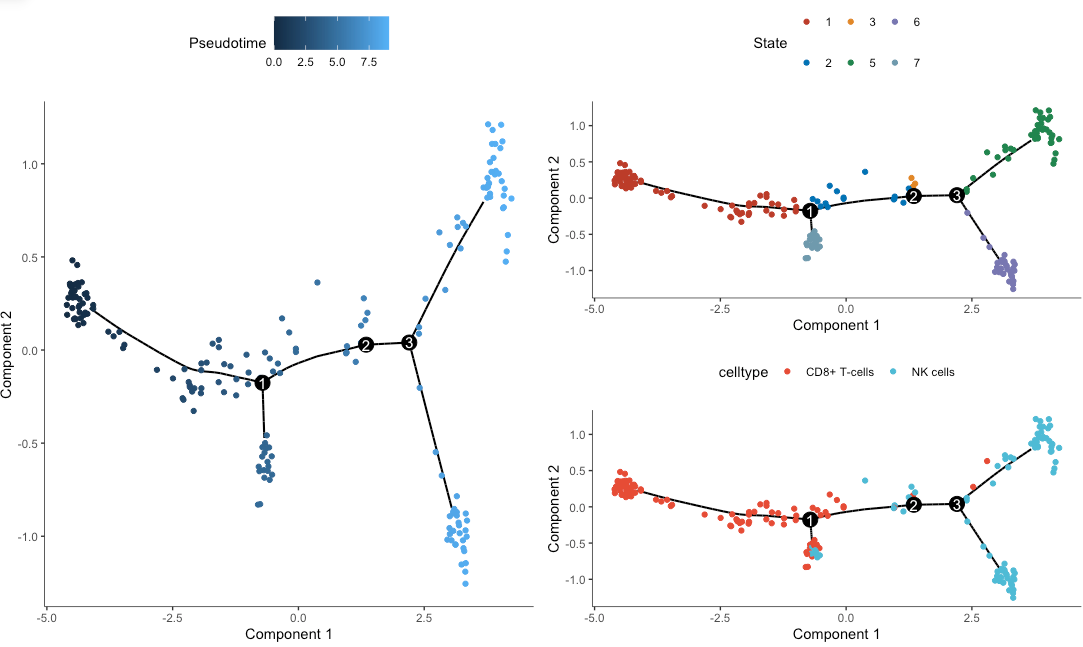
单样本
经典拟时序热图
这里图展示基因随着时间的渐变,不同于findmarker,这里选q值最小的的50个基因
gene_to_cluster = diff_test_res %>% arrange(qval) %>% head(50) %>% pull(gene_short_name);head(gene_to_cluster)
plot_pseudotime_heatmap(sc_cds[gene_to_cluster,],
num_clusters = nlevels(Idents(scRNA)),
show_rownames = TRUE,
cores = 4,return_heatmap = TRUE,
hmcols = colorRampPalette(c("navy", "white", "firebrick3"))(100))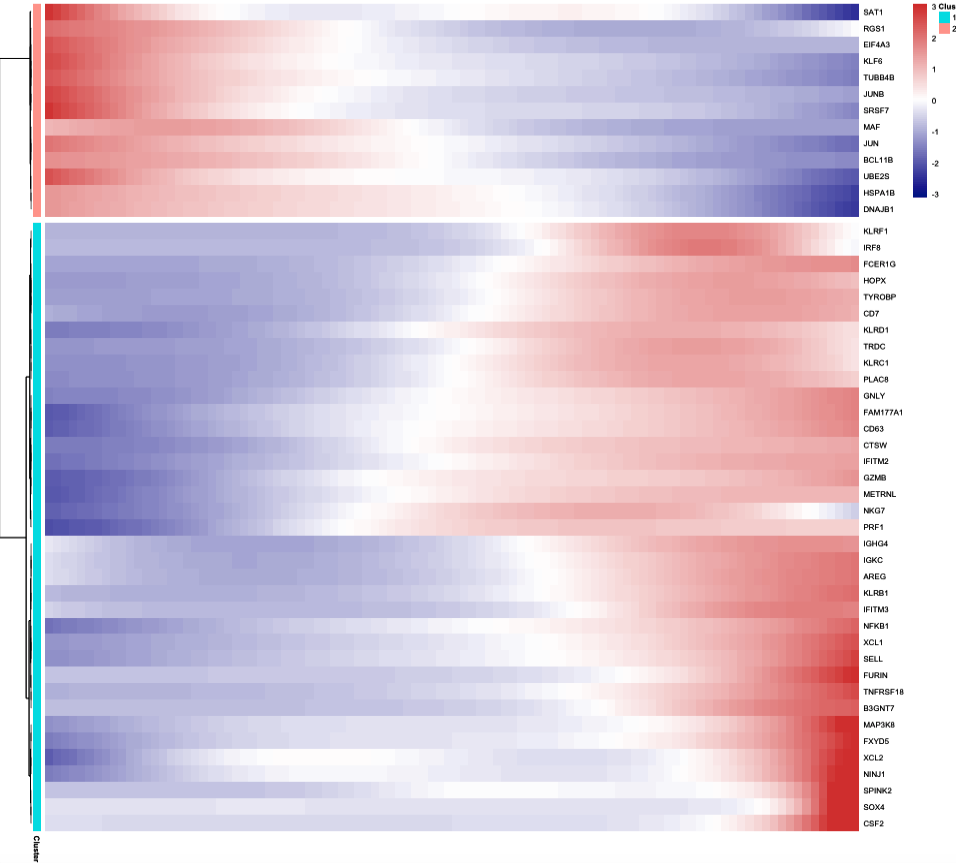
单样本
基因轨迹图
gs = head(gene_to_cluster)
plot_cell_trajectory(sc_cds,markers=gs,use_color_gradient=T)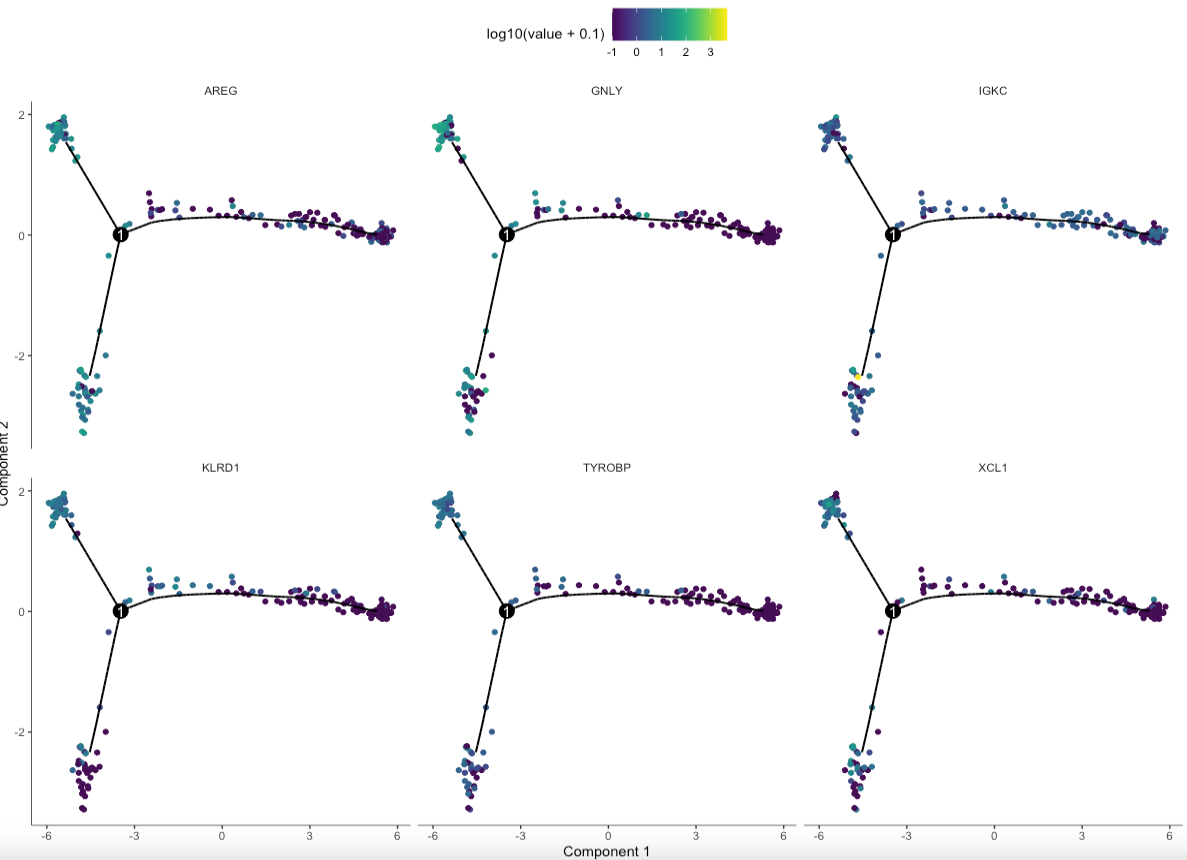
单样本的
基因拟时序点图
plot_genes_in_pseudotime(sc_cds[gs,],color_by = "celltype",
nrow= 3, ncol = NULL 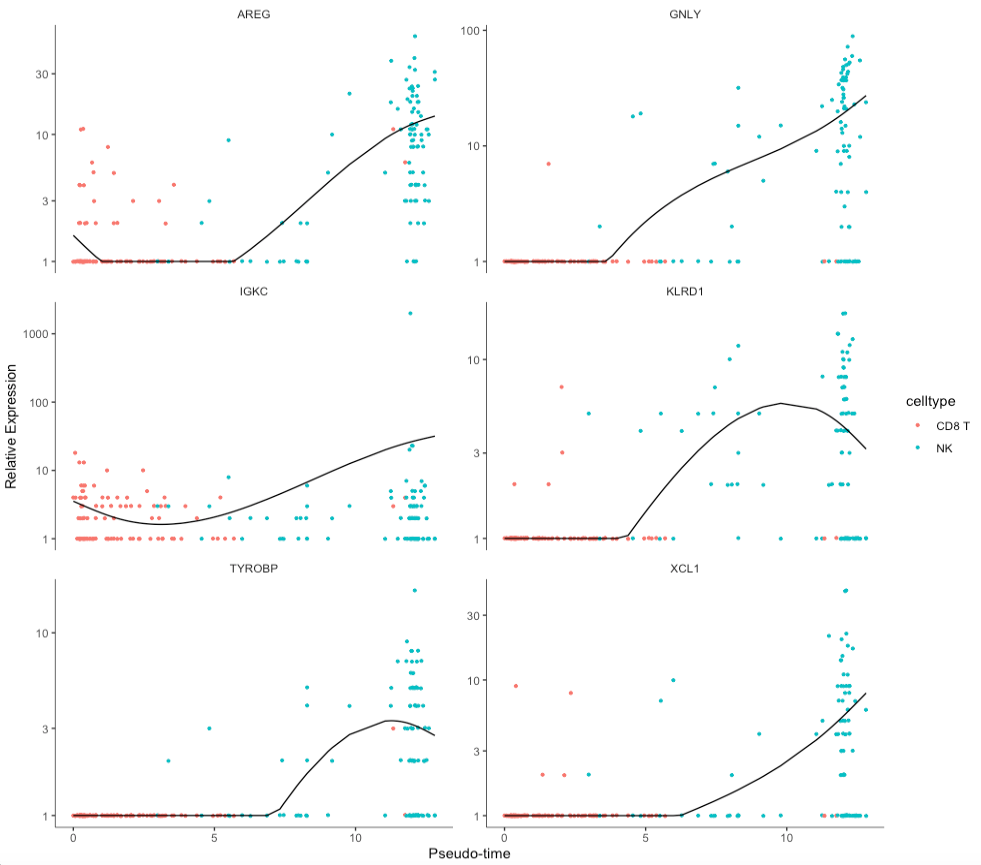
单样本
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
作者已关闭评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号