功能概述
模型 API 接入是 AI Agent 安全网关提供的核心业务接入能力,用于将大模型服务安全、便捷地接入网关,实现对大模型流量的集中管控和安全防护。
通过模型 API 接入,用户可以在网关层面统一管理大模型的访问入口、后端路由和安全策略,享受以下核心价值:
协议标准化:基于 OpenAI 协议标准封装,屏蔽不同模型厂商的接口差异,用户无需逐一对接各模型的 API 规范,即可快速完成接入。
多模型管理:支持多模型后端的负载均衡和智能路由,适用于企业在多模型场景下的高可用和灵活调度需求。
安全防护:在网关层统一配置流量控制、token 控制、内容安全、提示词安全和 IP 黑白名单等安全策略,防止敏感数据泄露,拦截恶意请求。
操作场景
本文介绍如何在 AI Agent 安全网关中完成模型 API 接入的全流程配置,将大模型后端服务接入业务应用调用链路。
适用于以下场景:
需要将第三方或自建的大模型服务(自定义模型应用)通过网关进行安全代理和访问控制。
需要对多个大模型后端进行负载均衡,实现高可用和故障切换。
需要为大模型调用配置统一的凭据鉴权,保护后端模型服务的访问安全。
需要在应用维度统一实施流量控制、token 控制、内容安全、提示词安全和 IP 黑白名单等安全策略。
前提条件
如需接入自定义模型服务,需确保模型服务已部署且网络可达(支持公网或内网访问),并已获取模型服务的访问地址和鉴权凭据。
创建应用时如需配置登录认证,需已在鉴权配置 > 认证中心中创建 API 认证 和 MCP 认证,详情请参见 认证配置。
如需配置内容安全策略,需已开通 内容安全服务。
操作步骤
模型 API 接入的整体流程为:创建应用 → 新建模型 → 新建模型 API → 关联应用与模型 API。
步骤一:创建应用
应用是 AI Agent 安全网关的业务管理入口,用于统一管理 MCP 和大模型服务的访问。所有大模型侧的流量统一以应用作为访问入口。
1. 登录 AI Agent 安全网关 页面,在左侧导航栏中,单击应用。
2. 在应用页面,单击新建应用。
3. 在新建应用弹窗中,配置以下参数:
参数 | 说明 |
应用名称 | 输入应用的名称,建议使用有业务含义的命名,例如"智能客服应用"。 |
认证类型 | APIKey:应用密钥,用于标识和验证应用的身份,确保 API 调用的安全性。 SecretKey:增强认证安全性,生成令牌或签名。 免认证:纯代理模式,关联的模型 API 和 MCP 资源无需凭据即可访问。 登录:即 OAuth2 认证,实现授权码流、客户端凭据等标准流程。需在已创建的 API 认证 和 MCP 认证中分别进行选择,可多选。 每种认证类型最多支持创建 10 条凭据数据;免认证类型无凭据,无需生成密钥。 |
应用描述 | 输入对该应用的描述信息,便于后续管理和识别。 |
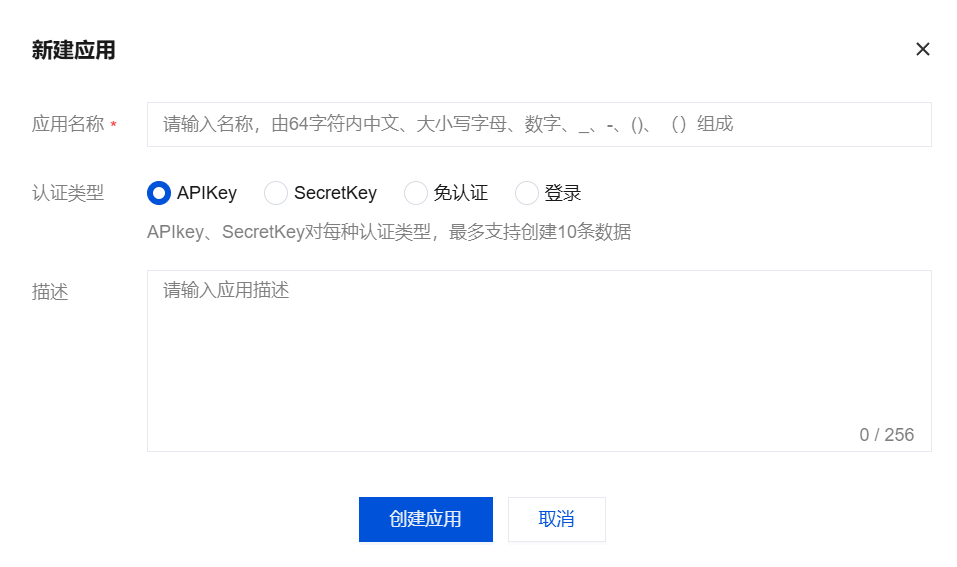
4. 单击创建应用,完成应用创建。
创建成功后,系统将自动为认证方式为 APIkey 和 SecretKey 的应用生成一组默认凭据(APIKey 或 SecretKey),用于后续客户端调用网关时的身份验证。
说明:
为降低密钥泄露风险,仅在新建时提供默认凭据,后续不可再进行查询,请妥善保存默认凭据。
步骤二:创建模型
模型管理用于注册和管理后端大模型服务的连接信息,包括模型类型、后端地址、通信协议和负载方式等。
1. 在左侧导航栏中,单击模型 > 模型管理。
2. 在模型管理页面,单击新建模型。
3. 在新建模型页面,配置以下参数:
参数 | 说明 |
模型名称 | 自定义模型名称,用于标识模型用途,例如"混元大模型"。支持中英文、数字、下划线,长度不超过 64 个字符。 |
模型类型 | 选择后端模型服务的类型,支持以下模型类型: TI-ONE 应用:接入已在 TI-ONE 平台部署的模型推理服务。 自定义模型应用:接入第三方或自部署的模型服务,需手动填写后端路径。 |
modelID | 请求体中的 model 字段(非必填),长度不超过128个字符。 若不填写则保持请求原始 model 字段不变; 若填写,命中该模型时请求体中的 model 字段将自动替换为配置值。 |
描述 | 备注该模型的用途或说明,仅供管理员识别,不影响实际请求转发(非必填),长度不超过1024个字符。 |
选择服务 | 当模型类型选择 TI-ONE 应用 时,选择对应的服务名称、版本以及调用类型。 |
后端协议 | 选择与后端模型服务通信的协议,可选 HTTP 或 HTTPS。 |
协议检查 | 当后端协议选择 HTTPS 时,选择是否启用协议检查。启用后,网关将校验后端服务的 SSL/TLS 证书有效性。 |
协议版本 | 选择协议版本,支持1.1和2.0。如模型服务支持 gRPC,请选择 2.0。 |
后端服务 | 后端服务节点地址,添加多个节点。 原始域名/IP:后端服务节点的实际域名或 IP 地址,用于指定网关转发请求的目标地址。 {domain}:{port}形式。转发权重:用于设定当前后端节点的流量分配权重,取值范围 1-100,默认值为 10。权重越高,分配到该节点的请求比例越大。 |
后端路径 | 输入后端模型服务的 API 路径,例如 /v1/chat/completions。 |
凭据选择 |
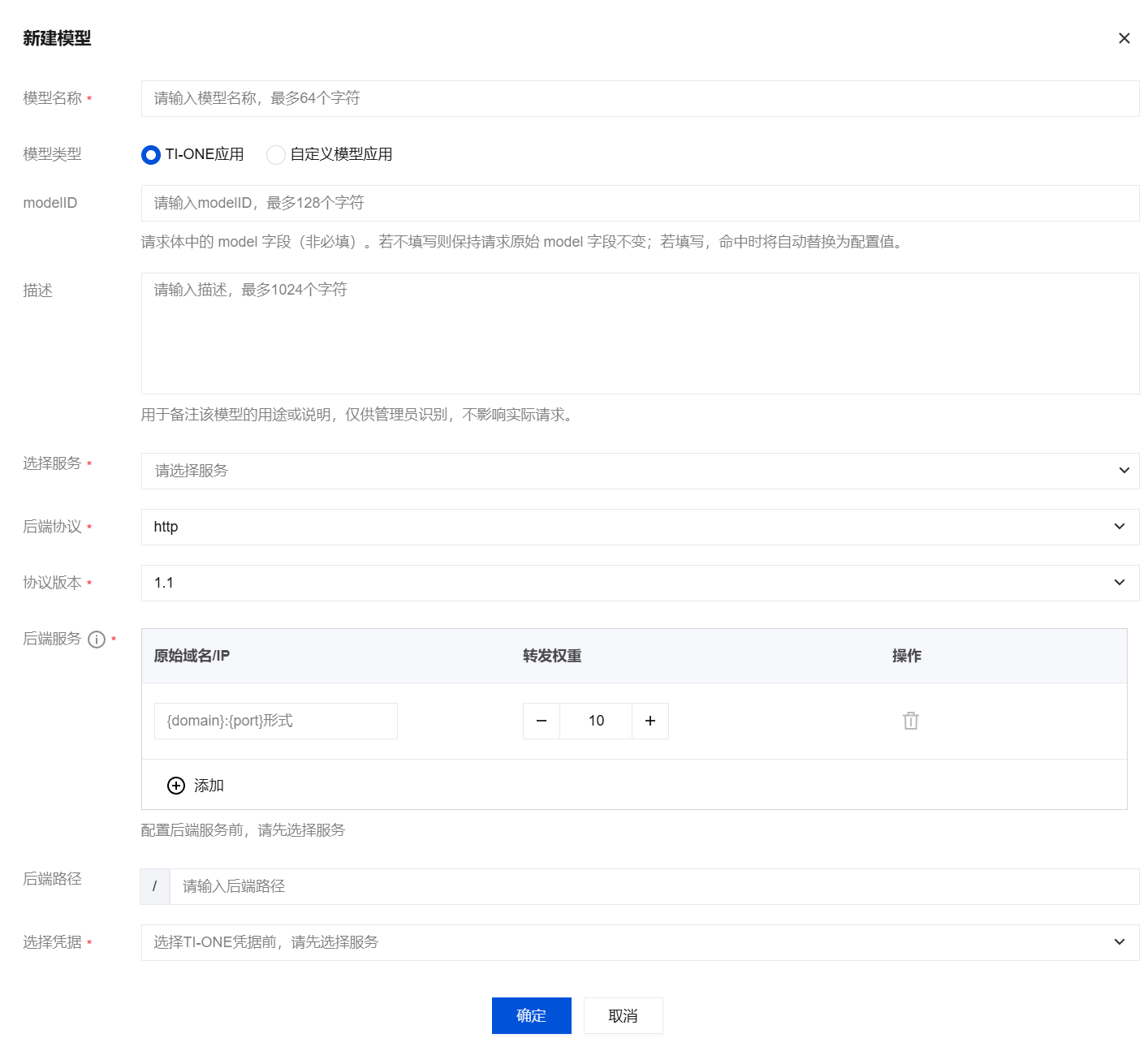
4. 单击确定,完成模型创建。
注意:
修改模型的后端路径后,关联该模型的所有模型 API 的请求转发目标将同步变更,请确认不影响线上业务后再执行修改操作。
步骤三:创建模型 API
模型 API 用于定义接入路由,将前端请求路径映射到后端模型服务,是连接应用和后端模型的桥梁。
1. 在左侧导航栏中,单击模型 > 模型 API。
2. 在模型 API 页面,单击新建模型 API。
3. 在新建模型 API 页面,配置以下参数:
参数名称 | 说明 |
基本信息 | |
名称 | 自定义模型 API 名称,用于标识当前 API 的业务用途,例如"对话补全接口"。由64以内的中文、大小写字母、数字、_、-、()、()组成,实例下唯一。 |
协议模型 | OpenAI 协议: 兼容 OpenAI /v1/chat/completions 等接口规范,常见的对外提供 OpenAI 兼容接口的模型平台均可对接。Anthropic 协议:兼容 Anthropic /v1/messages 接口规范,适用于 Claude 系列及其兼容模型。 |
描述 | 对模型 API 的补充说明信息。长度1024以内。 |
前端配置 | |
请求路径 | 前缀匹配:API 请求的路径以"路径"的配置为前缀。 绝对匹配:API 请求的路径要与"路径"的配置一致,匹配优先级最高。 正则匹配:API 请求的路径正则匹配"路径"的配置,支持路径参数,参数必须以{}包裹,作为独立部分包含在路径中(示例:/{param}/),匹配优先级最低。 输入访问路径,以"/"进行分隔,如 /ebus/amp/rio/web。 |
后端配置 | |
负载方式 | 随机负载:使用网关集群,按照权重采用随机负载方案,每个请求落在随机的服务器。 会话保持:使用网关集群,采用一致性负载方案,同一个会话的请求会被转发到同一台服务器。 |
会话判定方式 | 当负载方式选择会话保持时,需要配置此参数。 根据客户端 IP:相同源 IP 的请求视为同一会话,适用于客户端 IP 稳定的场景。 根据 Header Key:根据请求头中的指定字段(如 X-Session-Id)识别会话,适用于客户端能稳定携带会话标识的场景。 自动探测:由网关基于请求特征自动识别会话归属。 |
模型地址 | 后端模型:选择已创建的模型。如果尚未创建模型,请先前往 模型管理 页面创建。 匹配名称:关联模型后自动展示的后端模型访问地址。 模型权重:用于设定当前模型在流量分发中的权重比例,权重越高分配到的请求越多。 可关联多个模型。关联多个模型时,请求将按照模型管理中配置的负载方式进行分发。 |
Fallback | 开启:主模型响应失败或超时时,请求自动切换到 Fallback 模型组继续处理。 关闭:主模型响应失败或超时时,直接返回错误。 |
Fallback 模型组 | |
超时时间 | 后端请求超时时间,单位为秒,取值范围 1-600,默认 60 秒。建议根据模型推理耗时设置。 |
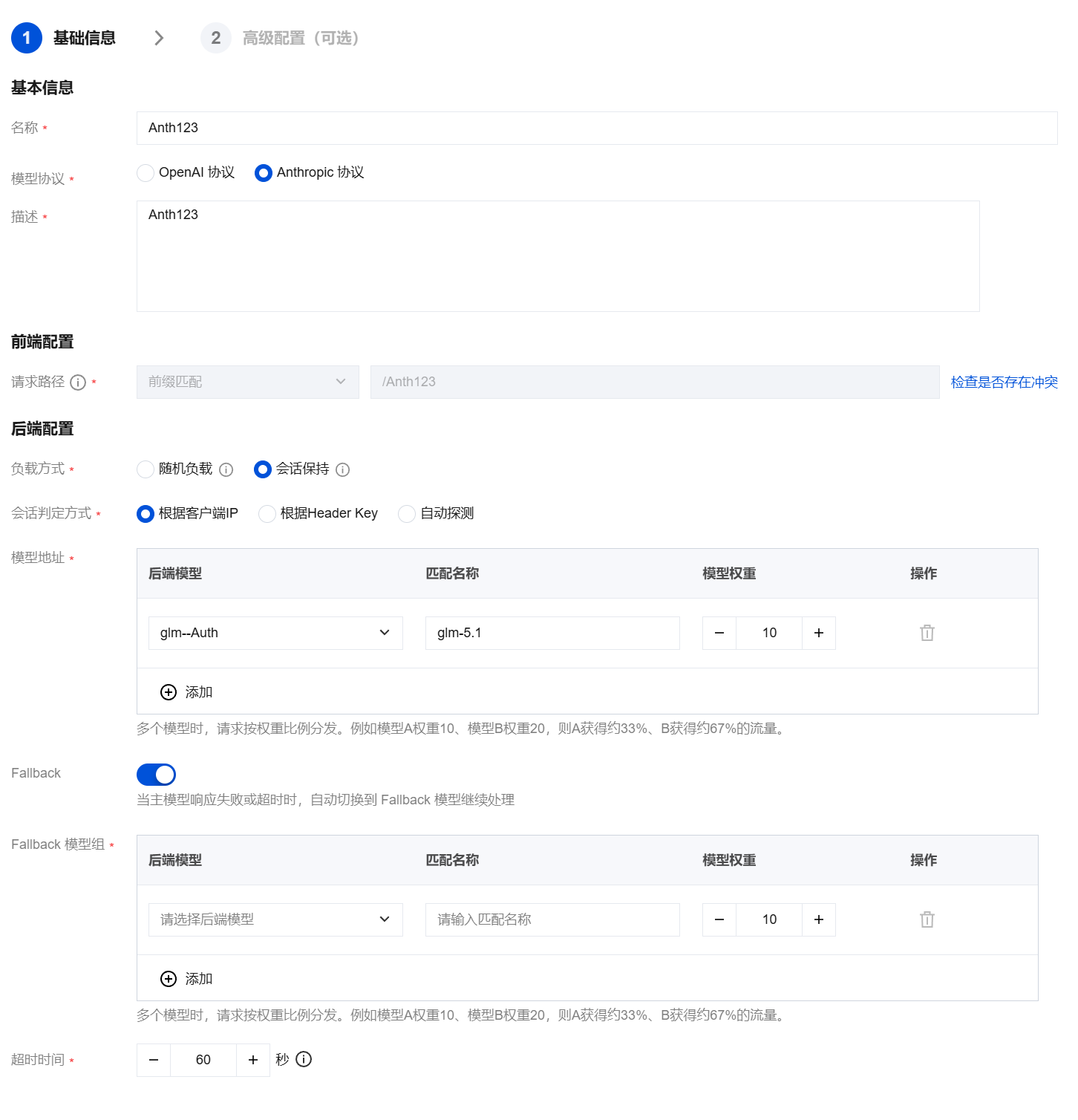
4. 单击下一步,完成高级配置。
参数 | 说明 |
流量控制 | 开启后可自定义某个时间内最大请求次数、时间窗口长度、转发超时时间等。提供四种控制方法: 令牌桶:从固定容量的桶中取令牌,取不到的则触发限流。调整令牌桶容量可以限制请求的数量;调整令牌生成速率可以限制请求的速率。 漏斗:向固定容量的漏斗中加水,水溢出则触发限流。调整漏斗容量可以限制请求的数量;调整漏斗流速可以限制请求的速率。 滑动窗口:长度固定窗口向前滑动,请求固定进来占据位置,满则触发限流。调整窗口内最大请求次数可以限制请求的数量;调整窗口长度可以限制请求的速率。 时间窗口:调整时间窗口内最大请求次数可以限制请求的数量;调整时间长度可以限制请求的速率。 |
token 控制 | 开启后可选择时间窗口、自然天或自然月三种统计方法,设定累计总量消耗上限或单次请求消耗上限控制,即下面条件一或条件二任一满足则会触发 token 控制: 条件一:统计周期内累计 token 达到消耗上限。统计方法提供三种选项: 时间窗口:自定义滑动时间窗口(分钟),在窗口内统计累计消耗量,窗口滑过后自动恢复。 自然天:按自然日(00:00 - 23:59:59)统计,每天 00:00:00(北京时间)自动重置计数器。 自然月:按自然月(每月1日至月末)统计,每月1日 00:00:00(北京时间)自动重置计数器。 条件二:单次请求 token 达到消耗上限。 说明: 累计 token 同时计入请求 + 响应;流式 SSE 按最终聚合长度计入;两个条件可单独或同时开启,任一命中即拦截。 新建策略时默认为时间窗口模式。切换统计方法并保存后,系统将重置累计计数器,从新的统计周期开始重新统计。 自然天和自然月的重置时间均以北京时间(UTC+8)为准。 |
内容安全 | 开启后可对请求和响应内容进行安全检测,支持内置原生检测模型或腾讯云上内容安全产品命中后按所选执行动作处理。 检测引擎:当前版本固定使用产品内置的原生检测模型,暂不支持切换。 检测范围:指定检测作用的报文方向。多选,建议同时勾选,覆盖双向风险。 合并检测 event 数:检测范围为响应时显示且必填。 0:不合并,对每个响应 event 单独检测。 N(>0):将当前 event 与前 N 个 event 合并后整体送检。 执行动作: 观察:仅记录命中日志,不改变请求内容。 脱敏:保留请求结构,命中片段按等长 * 替换后透传给后端模型。上下文范围: 全部消息:对当前会话的所有历史消息进行安全检测,覆盖范围较广,会话较长时检测耗时会相应增加。 仅最新消息:仅对最新发送的一条消息进行检测,检测耗时较短,但不覆盖历史会话中的风险。 响应拦截内容:响应被拦截时的展示内容。当执行动作为拦截时必填,支持 128 字以内的文本,可包含中英文标点符号。 |
提示词安全 | 开启后可对请求内容进行提示词安全检测。 执行动作: 观察:仅记录命中日志,不改变请求内容。 脱敏:保留请求结构,命中片段按等长 * 替换后透传给后端模型。上下文范围: 双重检测:先对全部会话消息进行检测,发现风险后再单独检测最新一条,精确定位风险来源。执行动作为拦截时可选。 全部消息:对当前会话的所有历史消息进行安全检测,覆盖范围较广,会话较长时检测耗时会相应增加。 仅最新消息:仅对最新发送的一条消息进行检测,检测耗时较短,但不覆盖历史会话中的风险。 响应拦截内容:响应被拦截时的展示内容。当执行动作为拦截时必填,支持 128 字以内的文本,可包含中英文标点符号。 |
敏感词检测 | 开启后对请求内容进行敏感信息检测,覆盖身份证、手机号、邮箱等关键数据字段。 检测范围:当前版本固定为对请求内容进行检测。 检测规则:选择需要进行检测的信息类型和匹配内容,最多可以添加11条。 执行动作: 观察:仅记录命中日志,不改变请求内容。 拦截:阻断请求,返回网关拒绝响应。 脱敏:保留请求结构,命中片段按等长 * 替换后透传给后端模型。上下文范围: 双重检测:先对全部会话消息进行检测,发现风险后再单独检测最新一条,精确定位风险来源。执行动作为拦截时可选。 全部消息:对当前会话的所有历史消息进行安全检测,覆盖范围较广,会话较长时检测耗时会相应增加。 仅最新消息:仅对最新发送的一条消息进行检测,检测耗时较短,但不覆盖历史会话中的风险。 响应拦截内容:响应被拦截时的展示内容。当执行动作为拦截时必填,支持 128 字以内的文本,可包含中英文标点符号。 |
IP 黑名单 | 开启后可限定指定的 IP 无法访问该模型 API,其他 IP 都可访问。单击 + 添加逐条录入 IP 地址。 |
IP 白名单 | 开启后只允许指定的 IP 访问该模型 API,其他 IP 都无法访问。单击 + 添加逐条录入 IP 地址。 |
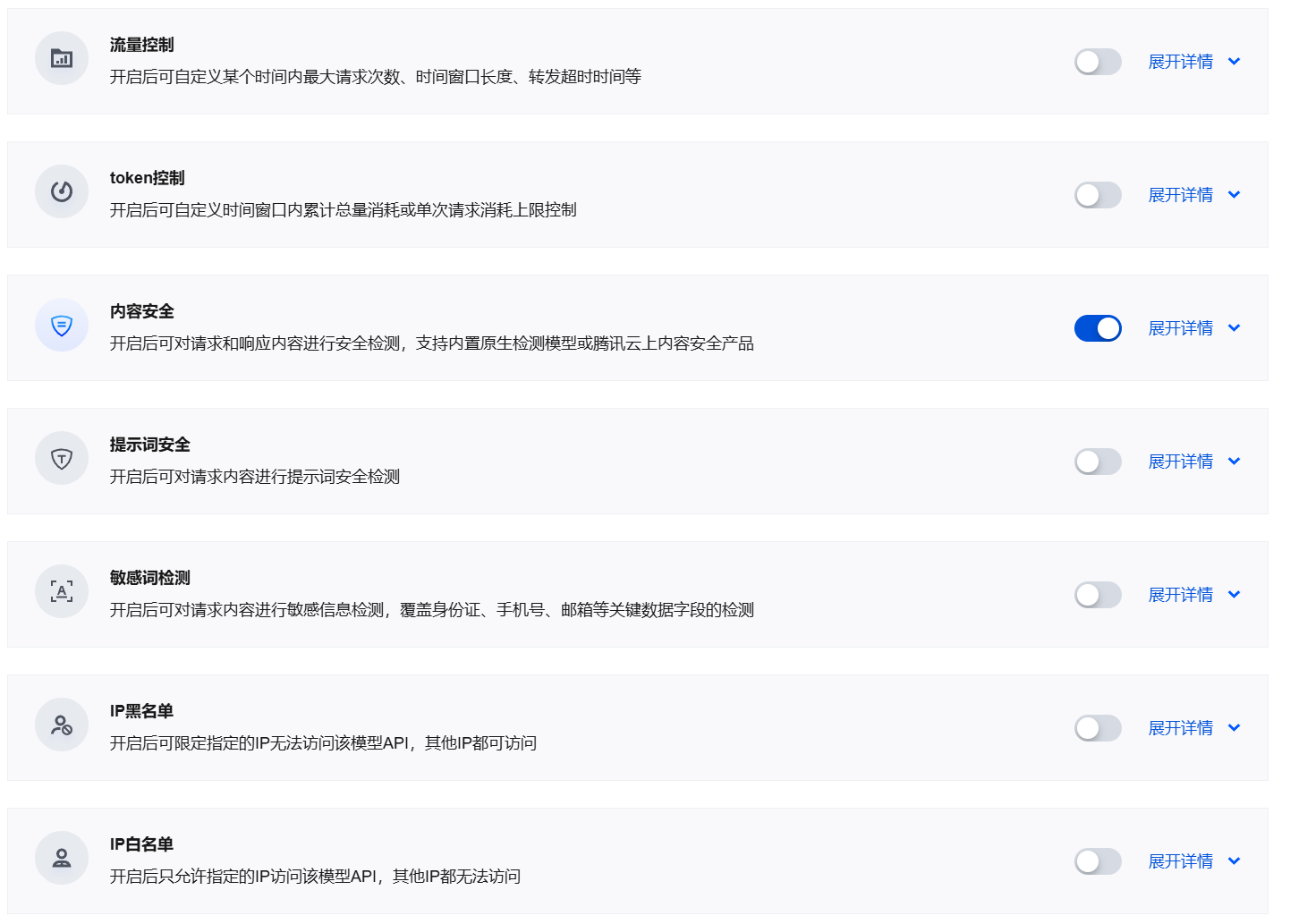
5. 单击保存,完成模型 API 创建。
步骤四:关联应用与模型 API
创建模型 API 后,需要将其关联到应用中,并配置安全策略,使客户端能够通过应用入口访问大模型服务。
1. 在左侧导航栏中,单击应用。
2. 在应用页面,单击目标应用名称。
3. 在应用详情页面,单击左下角的关联模型 API。
4. 在关联模型 API 弹窗中,配置以下参数:
参数 | 说明 |
模型 API | 下拉选择已创建的模型 API。 |
流量控制 | 开启后可自定义某个时间内最大请求次数、时间窗口长度、转发超时时间等。提供四种控制方法: 令牌桶:从固定容量的桶中取令牌,取不到的则触发限流。调整令牌桶容量可以限制请求的数量;调整令牌生成速率可以限制请求的速率。 漏斗:向固定容量的漏斗中加水,水溢出则触发限流。调整漏斗容量可以限制请求的数量;调整漏斗流速可以限制请求的速率。 滑动窗口:长度固定窗口向前滑动,请求固定进来占据位置,满则触发限流。调整窗口内最大请求次数可以限制请求的数量;调整窗口长度可以限制请求的速率。 时间窗口:调整时间窗口内最大请求次数可以限制请求的数量;调整时间长度可以限制请求的速率。 |
token 控制 | 开启后可选择时间窗口、自然天或自然月三种统计方法,设定累计总量消耗上限或单次请求消耗上限控制,即下面条件一或条件二任一满足则会触发 token 控制: 条件一:统计周期内累计 token 达到消耗上限。统计方法提供三种选项: 时间窗口:自定义滑动时间窗口(分钟),在窗口内统计累计消耗量,窗口滑过后自动恢复。 自然天:按自然日(00:00 - 23:59:59)统计,每天 00:00:00(北京时间)自动重置计数器。 自然月:按自然月(每月1日至月末)统计,每月1日 00:00:00(北京时间)自动重置计数器。 条件二:单次请求 token 达到消耗上限。 说明: 累计 token 同时计入请求 + 响应;流式 SSE 按最终聚合长度计入;两个条件可单独或同时开启,任一命中即拦截。 新建策略时默认为时间窗口模式。切换统计方法并保存后,系统将重置累计计数器,从新的统计周期开始重新统计。 自然天和自然月的重置时间均以北京时间(UTC+8)为准。 |
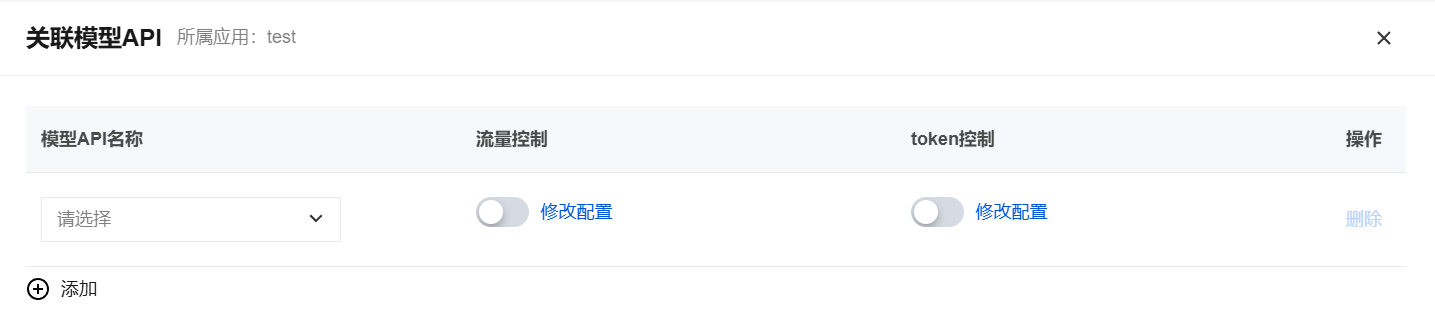
5. 单击确定,完成关联配置。
6. 关联成功后,业务应用即可通过应用的访问入口和凭据,经由网关调用后端大模型服务。
注意:
同一模型 API 、MCP Server、API 在同一时间只能被一种认证模式的应用有效关联。将应用与新资源关联时,该资源此前关联的其他应用将被自动解绑,请在操作前确认认证模式,避免影响已有应用的认证策略。
结果验证
完成上述步骤后,您可以通过以下方式验证模型 API 接入是否配置成功:
1. 在应用页面,单击目标应用名称进入详情页,在关联模型 API 区域确认目标模型 API 已显示在列表中。
2. 在模型 API 列表页中,确认后端模型数和关联应用列数据与预期一致。
3. 使用应用的凭据,通过网关地址发起测试请求,确认能正常调用后端模型并获得响应。
API 示例调用如下(以 curl 为例):
$ curl -X POST https://<网关域名>/v1/chat/completions \\-H "Content-Type: application/json" \\-H "Authorization: Bearer <模型 API Key>" \\-d '{"model": "<模型名称>","messages": [{"role": "user", "content": "您好"}]}'
免认证模式调用示例(无需凭据):
$ curl -X POST https://<网关域名>/v1/chat/completions \\-H "Content-Type: application/json" \\-d '{"model": "<模型名称>","messages": [{"role": "user", "content": "您好"}]}'
参数说明:
参数 | 说明 |
网关域名 | AI Agent 安全网关分配的访问域名。 |
/v1/chat/completions | 模型 API 中配置的前端请求路径,请替换为实际值。 |
模型 API Key | |
模型名称 | 后端模型的名称,根据实际使用的模型填写。 |
4. 若返回模型的正常响应结果,表示模型 API 接入配置成功,流量已通过 AI Agent 安全网关进行代理和防护。



