本文档首先介绍 TKE 混部的资源模型与产品架构,然后介绍如何通过控制台快速搭建混部所需的基础环境,并分别演示在线业务与离线任务的部署流程。在实践环节中,我们将验证离线任务上线后,在线业务的 QPS 持续稳定、不受影响。最后,提供 TKE 混部与 Kueue 的队列管理及 Gang 调度特性的联动示例,帮助您在保障服务稳定性的同时,实现批量任务的高效、可控调度。
背景
企业的 IT 服务通常分为两大类:在线服务与离线作业。典型的在线业务和离线作业具备如下特征:
对比项 | 在线业务 | 离线业务 |
典型应用 | 搜索、推荐、广告、微服务等 | 大数据批处理、视频转码、AI 训练等 |
时延 | 敏感 | 不敏感 |
SLO | 高 | 稍低 |
负载模型 | 分时性 | 持续占用资源 |
错误容忍 | 容忍度低,对可用性要求高 | 允许失败重试 |
运行时间 | 稳定持续运行 | 任务型、运行时间短 |
由于在线服务的资源利用率通常存在明显的波动,因此混部的主要应用场景是通过部署离线作业来充分利用各时段的空闲资源,从而降低企业的资源成本。
混部资源模型
在 Kubernetes 的资源管理机制中,业务容器通常采用 Request 和 Limit 的方式申请资源。为了保障服务的稳定运行,管理员常为业务类应用申请较高的资源 Request 和 Limit,这导致 K8s 资源的分配率(Requested)较高,而实际利用率(Usage)偏低,资源空闲现象较为明显。

如上图所示,节点的浅色部分表示可动态超卖的资源量,可以分配给离线任务使用。
下文提到的要安装的 QoSAgent 组件,会动态计算各个节点的可用离线资源,并在节点的 Resource 部分展示出来。
status:allocatable:gocrane.io/cpu: "16"gocrane.io/memory: 32Gicapacity:gocrane.io/cpu: "16"gocrane.io/memory: 32Gi
离线任务的 Pod,需要在 Request 和 Limit 中指定使用离线扩展资源,示例如下:
spec:containers:- resources:limits:gocrane.io/cpu: "3"gocrane.io/memory: 2048Mirequests:gocrane.io/cpu: "3"gocrane.io/memory: 2048Mi
当 Pod 指定扩展资源后,调度器会将该 Pod 调度到有该扩展资源的节点上。
产品优势
TKE 混部架构具有如下优势:
对可混部资源实时动态计算,更好地平衡资源充分利用与业务 QoS 需求。
对 Kubernetes 无侵入式修改。
配合 TKE 原生节点,从内核层面在 CPU、内存、IO、网络等各方面,全面保障了在线和离线的隔离。
配合 Request 智能推荐对在线资源画像,可减少对离线任务的压制和驱逐,最大程度保障调度后的离线任务质量。
产品架构
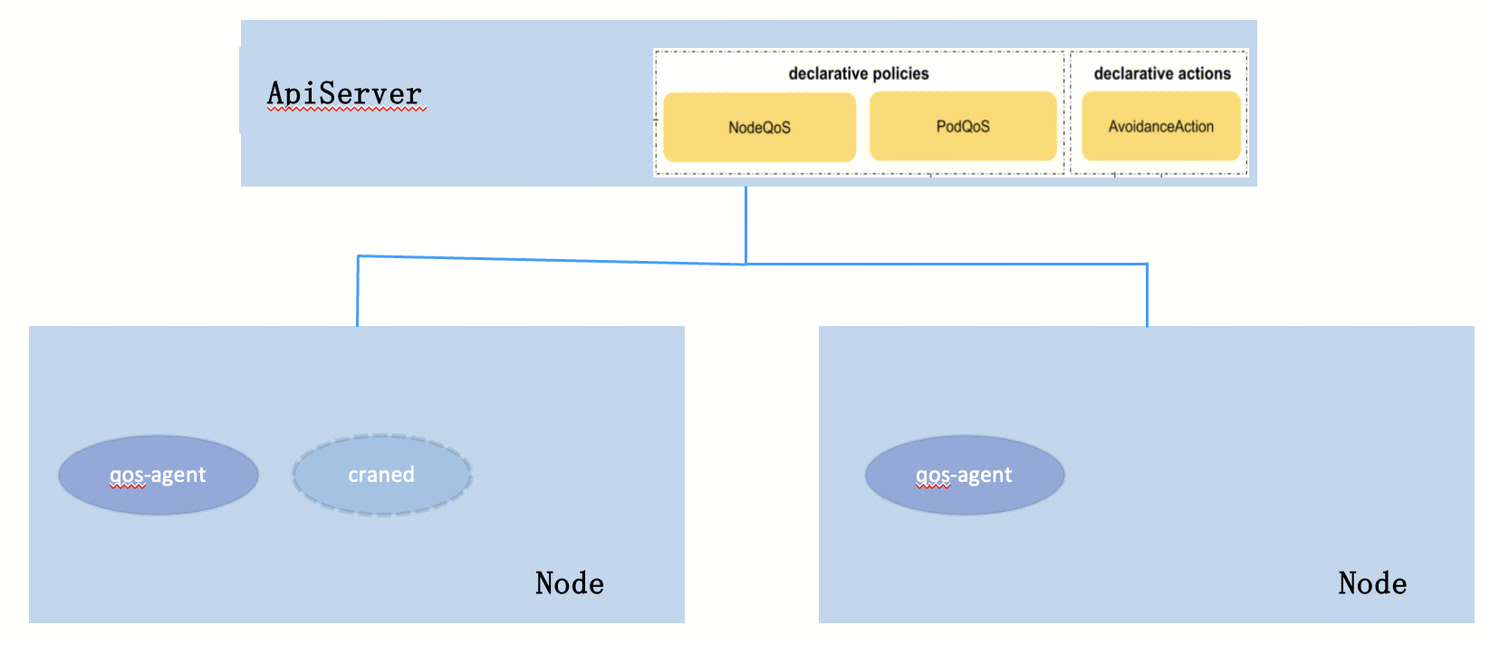
TKE 混部主要涉及以下几个概念,介绍如下:
QosAgent 是一个 Daemonset 方式部署的组件,负责根据新定义 CRD 对象中的规则,对离线 Pod 的 CPU、内存、IO 等资源进行设置。
craned 为一个 Deployment 方式部署的组件,负责数据采集、干扰检测、资源预测等功能。
其中 NodeQOS、PodQOS、AvoidanceAction 是新增的三个 CRD 对象,分别介绍如下。
NodeQOS 是 Kubernetes 节点级资源质量保障的自定义资源对象,支持通过 NodeSelector 精确选择需要管控的节点,并可以灵活配置弹性 CPU 限制、内存管理(如页面缓存限制)、网络带宽限制等多方面功能,从而为节点定制资源保障方案,提升节点资源利用率和业务稳定性。
PodQOS 是 Kubernetes 集群中用于精细化管控 Pod 资源限制的自定义资源对象。它支持通过 labelSelector 精确选择受控 Pod,并可灵活设置避障动作(如节流、驱逐)、CPU、内存、IO、网络等资源的优先级和限制策略。
AvoidanceAction 是用于定义业务 Pod 资源避障行为的自定义资源。允许根据业务场景和保障规则,灵活配置异常情况下的资源规避动作,如 Pod 驱逐、资源节流等。
环境准备
第一步:准备集群
1. 进入腾讯云 容器服务控制台。
2. 选择您所需要部署业务的TKE 集群,如果您还没有集群,请参见 创建集群。
3. 如果是已有集群,请确认该集群有 原生节点。如果新建集群,请添加原生节点池,混部组件只支持在原生节点上部署。
第二步:组件安装
1. 进入 TKE 集群列表页,单击目标 TKE 集群 ID,进入集群详情页。
2. 在左侧选择组件管理,在组件页面单击新建。
3. 勾选其他 > Craned,单击完成即可创建组件。
4. 选择全部,输入 “QOSAgent” 搜索,勾选后单击完成安装该组件。组件安装完成后,在组件管理页面,找到该组件,点击更新配置,勾选 “CPU 使用优先级”、“CPU 超线程隔离”、“网络 QoS 增强” 三项能力。其他相关能力可以按需开启。
第三步:确认节点离线可用资源
查看节点的 yaml,可确认节点的 status.capacity 和 status.allocatable 中是否已包含 “gocrane.io/cpu” 和 “gocrane.io/memory” 的扩展资源。例如:
status:allocatable:gocrane.io/cpu: "16"gocrane.io/memory: 32Gicapacity:gocrane.io/cpu: "16"gocrane.io/memory: 32Gi
第四步:部署模拟在线业务
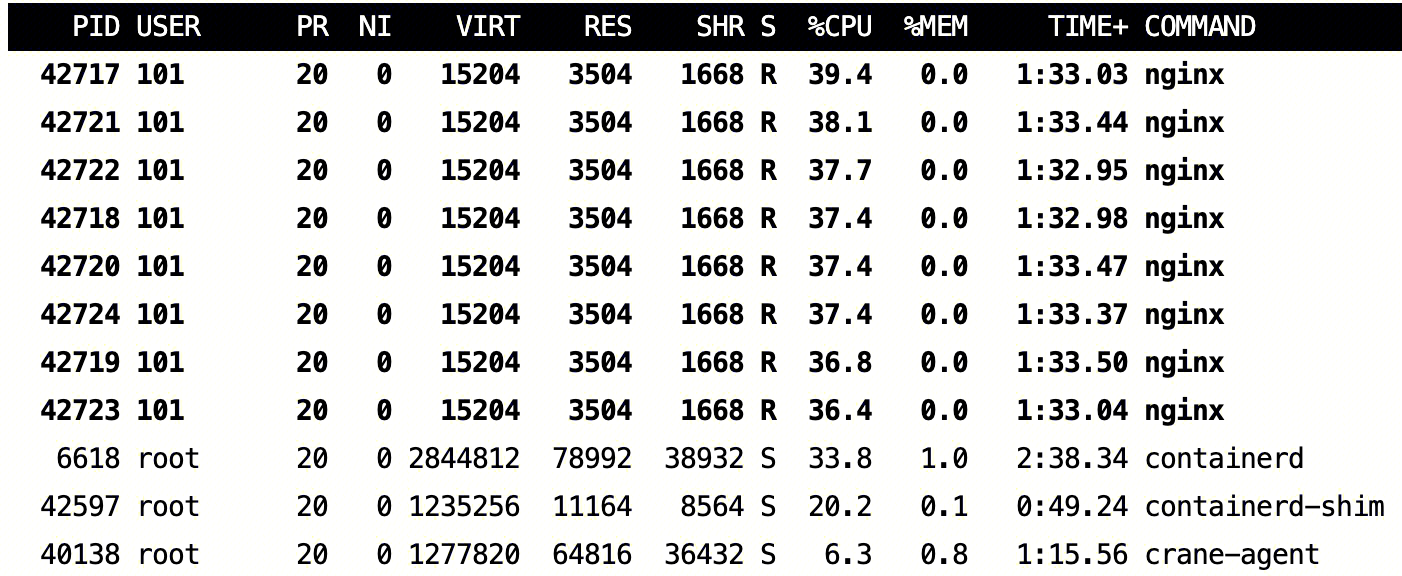
我们使用一个 Nginx 的 Deployment 来模拟在线业务。
apiVersion: apps/v1kind: Deploymentmetadata:labels:k8s-app: online-severname: online-severspec:replicas: 1selector:matchLabels:k8s-app: online-severtemplate:metadata:labels:k8s-app: online-severspec:containers:- name: serverimage: nginximagePullPolicy: Alwaysresources:limits:cpu: "3"memory: 3072Mirequests:cpu: "2"memory: 256Mi
从一台其他 CVM 通过类似以下命令访问上面创建的 Nginx 服务器:
./wrk -t30 -c90 -d3600s -H "Connection: close" --latency http://NginxIP/此时,Nginx Server 所在的 Pod 会有一定负载,类似如下:
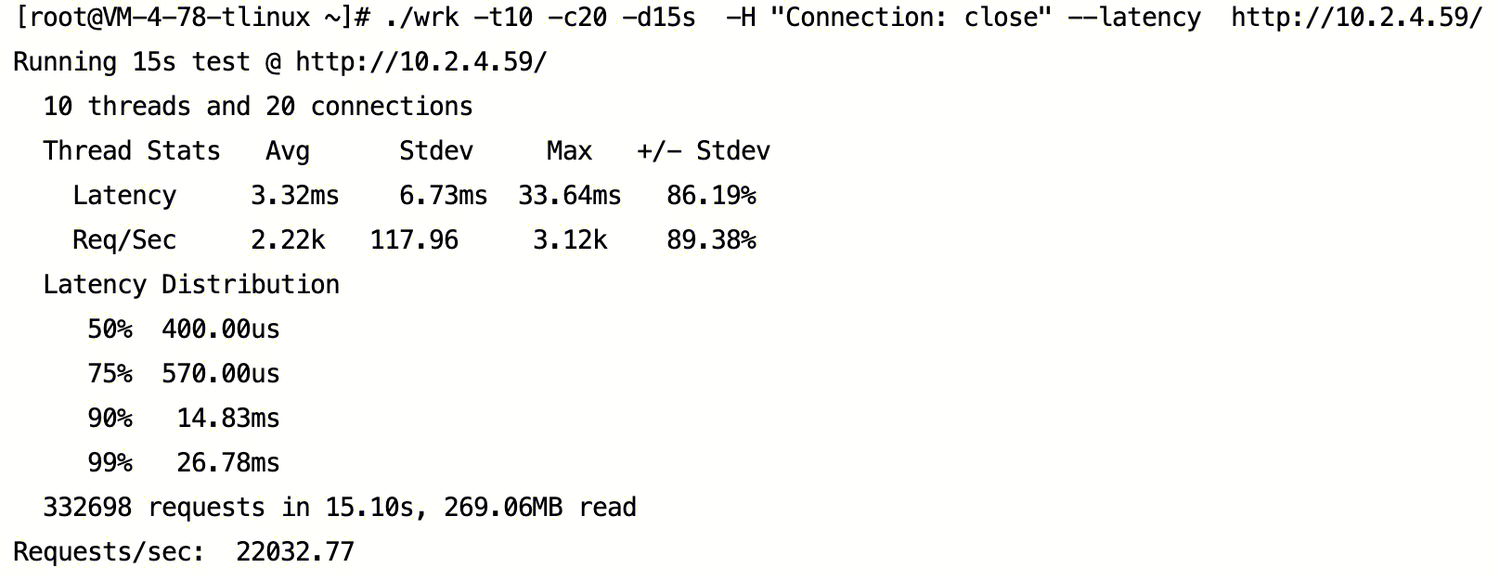
可以看出此时客户端访问的 QPS 大约22000,P99时延为约26.5 ms。
规划并部署离线业务
第一步:部署回避资源
AvoidanceAction 主要字段说明如下:
coolDownSeconds:避障动作的冷却期,单位为秒。即每次执行避障后,系统会间隔设定的时间才可再次执行同类动作,提升策略的稳定性与控制力。例如默认值 300 秒。
description:用于对该避障动作做补充说明,便于团队理解其应用场景及运维指南,最大支持 1024 字符。
eviction:驱逐类动作相关配置,支持设置 pod 的优雅终止时间(terminationGracePeriodSeconds),允许按需缩短或立即强制驱逐,及时释放资源。
throttle:资源节流相关配置,可定义 CPU 节流(cpuThrottle)和内存节流(memoryThrottle)方式:
cpuThrottle 包含最小 CPU 比例(minCPURatio)和每次下调步进比例(stepCPURatio),实现对低优先级任务的弹性降额策略。
memoryThrottle 支持强制触发低优先级 Pod 的页面缓存回收,辅助节点在内存紧张时快速释放资源。
status:记录避障动作的执行和调度状态,方便系统追踪及可观测性提升。
通过上述字段,AvoidanceAction CRD 支持多种业务规避和恢复策略,结合 NodeQOS 策略和系统自动化触发能力,实现云平台资源动态管控和业务弹性保障的智能化运维管理。
apiVersion: ensurance.crane.io/v1alpha1kind: AvoidanceActionmetadata:name: evictionspec:coolDownSeconds: 300#当节点回避指标率触发阈值时,将该节点设置为禁用调度,该字段表示节点从禁止调度状态到正常状态的最小等待时间description: "evict low priority pods"eviction:terminationGracePeriodSeconds: null#驱逐pod优雅删除时间,0表示强制删除,null表示使用pod默认的优雅删除时间,其他非负数表示驱逐的pod优雅删除时间
注意:
回避资源规则需要和 NodeQOS 和 PodQOS 配合使用。
第二步:设置节点离线水位和驱逐规则
NodeQOS 主要字段说明如下:
selector:通过标签选择器指定该 NodeQOS 策略作用的对象范围。
elasticCpuLimit: 用于配置节点弹性 CPU 的资源限制。支持细粒度的单核 CPU 限制(elasticCoreCpuLimit)、时间周期限制(elasticCoreCpuLimitPeriod)、CPU 避障策略(elasticCpuAvoidance)、及整节点 CPU 使用上限(elasticNodeCpuLimit)。可有效针对弹性或扩展 CPU 资源做动态管控。
memLimit:节点内存管理相关参数,包括是否启用全局页面缓存限制(pageCacheLimitGlobal),以及重试次数设置(pageCacheLimitRetryTimes),帮助缓解内存资源争抢,提高节点稳定性。
memoryCompression:设置是否启用内存压缩功能,对部分内存进行压缩以提升可用资源,优化节点 Memory 使用。
netLimits:节点网络 IO 限制,包括接收速率(rxBpsMax/rxBpsMin)和发送速率(txBpsMax/txBpsMin)的上下限配置。保障关键业务在网络资源紧张时的服务质量。
rules:定义触发资源保障行为的规则,包括规约对象、触发计数、恢复计数、目标 Metric、以及具体的避障和预览策略,可灵活制定响应行为。
通过上述字段,用户可以对节点的 CPU、内存、网络等核心资源进行全面的策略配置,实现智能、自动化的节点资源治理和高可用保障。
kind: NodeQOSmetadata:name: offlinespec:elasticCpuLimit:elasticNodeCpuLimit:percent: 60 #节点离线水位rules: #驱逐规则,包含指标,驱逐阈值- name: "cpu_total_utilization"avoidanceThreshold: 1 #达到阈值并持续多少次,回避规则被触发# restoreThreshold: 1 #当阈值未达到并继续多次, 回避规则已恢复actionName: "eviction" #匹配AvoidanceAction资源namemetricRule:name: "cpu_total_utilization"value: 60 #这里指标使用cpu使用率,阈值为60%name: "memory_total_utilization"value: 60 #这里指标使用内存使用率,阈值为60%
注意:
metricRule 中 "cpu_total_utilization" 和 "memory_total_utilization" 的阈值,需要根据在线业务实际情况验证来确定。
建议验证方法如下:
首先,观测在线业务的 P99 时延或者尾时延指标,例如 P99 时延要求为50ms。
然后,向节点调度更多离线 Pod,观测在线业务时延指标是否受到影响。
如果在线业务指标不受影响,可以适当增大该参数;如果在线业务指标受影响了,需要适当调小该参数。
第三步:部署 cpu 消耗型离线任务
PodQOS 主要字段说明如下:
allowedActions:限定此类 Pods 被允许执行的避障/资源管理动作,如 Throttle(节流)、Evict(驱逐)等。
labelSelector:标签选择器,用于匹配可被 PodQOS 管控的目标 Pod,仅对选定对象生效,支持标准 Kubernetes label 匹配模式。
resourceQOS:核心 QoS 配置,涵盖 CPU、内存、网络、IO 等多维资源的优先级、限制与隔离策略:
cpuQOS:支持容器优先级(containerPriority)、RDT 支持(containerRdt、rdt)、CPU burst 限制(cpuBurst)、CPU 绑核策略(cpuSet)、HT 隔离、限额超时、以及缓存与流量细节管控。详细介绍见 CPU 使用优先级、CPU 超线程隔离、CPU Burst、应用启动时 CPU 突增。
memoryQOS:包括异步回收(memAsyncReclaim)、页面缓存限制(memPageCacheLimit)、内存优先级(memPriority)、内存水位标记、内存压缩等策略。详细介绍见 内存精细调度。
diskIOQOS:磁盘吞吐和 IOPS 限制(diskIOLimit),磁盘权重(diskIOWeight)。详细介绍见 磁盘 IO 精细调度。
netIOQOS:网络流量限制、优先级、设备限流、白名单端口等细粒度配置。详细介绍见 网络精细调度。
status:记录 QOS 策略的执行与生效情况,提升可观测性和可追踪能力。
在部署离线 workload 之前,我们可以通过 PodQOS 规则匹配离线 pod,使其使用最低的 CPU 优先级。
apiVersion: ensurance.crane.io/v1alpha1kind: PodQOSmetadata:name: podqos-offlinespec:allowedActions:- evictionlabelSelector:matchLabels:pod-type: offlineresourceQOS:cpuQOS:cpuPriority: 7
说明:
该规则会匹配 label 为
pod-type: offline 的 Pod,设置为离线业务类型。部署离线 Job 完成模拟高 CPU 消耗型计算任务:
apiVersion: batch/v1kind: Jobmetadata:name: offlinespec:completions: 2parallelism: 2activeDeadlineSeconds: 600 # 300秒后自动终止template:metadata:labels:pod-type: offlinespec:containers:- name: offlineimage: polinux/stress-ngcommand:- stress-ng- -c- "4"- --timeout- "600"resources:limits:gocrane.io/cpu: "4"gocrane.io/memory: 200Mirequests:gocrane.io/cpu: "4"gocrane.io/memory: 200MirestartPolicy: Never
注意:
pod 的 resources 这里需要使用 gocrane.io/cpu 和 gocrane.io/memory,以确保这些离线 Pod 正确调度到有离线集群的节点上。
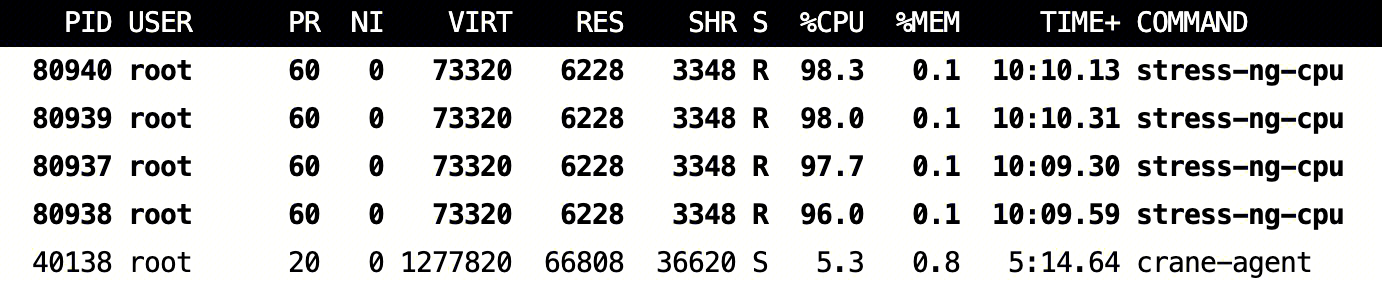
为了验证离线对在线影响,可以使用亲和性规则等手段,这里将离线 Pod 主动调度到在线 Nginx Server 所在的节点上。
在线 Nginx Server 无任何访问流量时,节点 CPU 占用情况如下:
第四步:检查在线业务情况
在离线 Pod 占用 CPU 的情况下,我们使用 wrk 模拟客户端增大对在线业务的访问。

示例显示,客户端的访问性能未受影响:P99 时延没有任何增加。
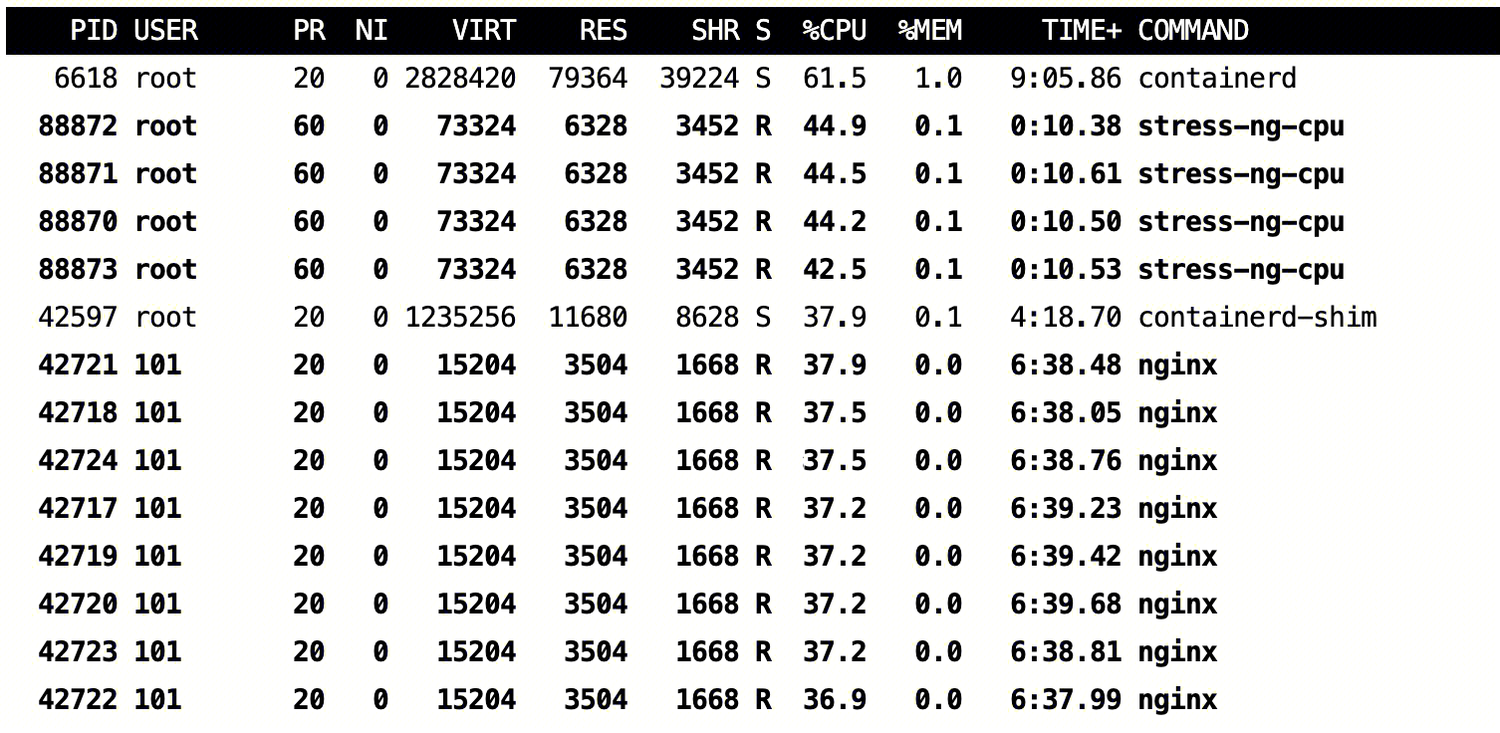
在线和离线同时部署时,节点 CPU 使用情况表明:
1. 在线 Nginx Server 的 CPU 使用并无受到影响。
2. 当在线需要使用 CPU 时,离线 CPU 会迅速被抢占。
3. 当在线使用较低时,在线和离线总体使用的 CPU 总和,不超过节点整体水位。
第五步:验证离线 Pod 被驱逐情况
在线业务使用的 CPU 超节点阈值情况
修改前文模拟的在线业务的 Deployment 的 resources 如下:
.... #Deployment其他配置不变,limit.cpu 从 “2”修改为 “8”resources:limits:cpu: "8"memory: 3072Mirequests:cpu: "2"memory: 256Mi
开始时,在线业务没有访问量,此时节点 CPU 情况:
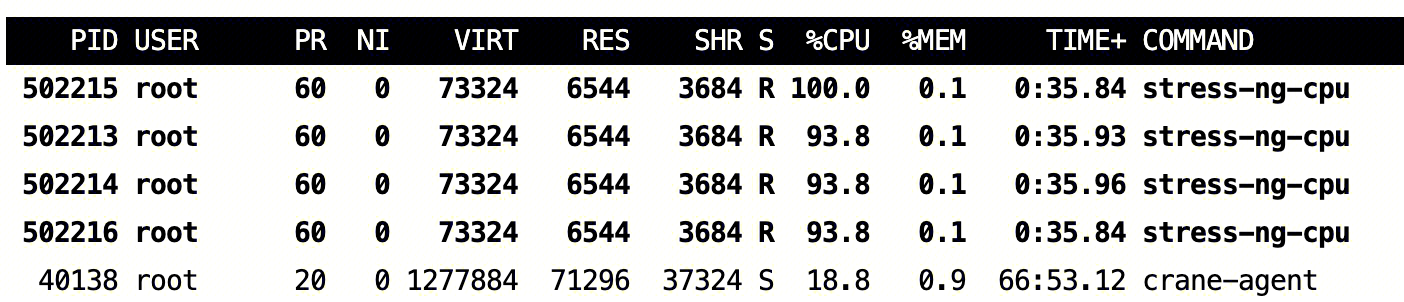
./wrk -t30 -c90 -d3600s -H "Connection: close" --latency http://NginxIP/
我们通过类似以下命令给 Nginx Server 增加压力,使 Nginx 消耗的 CPU 超过节点的压制门限,可以看到离线 Pod 被驱逐了:

此时节点的 CPU 使用情况如下:
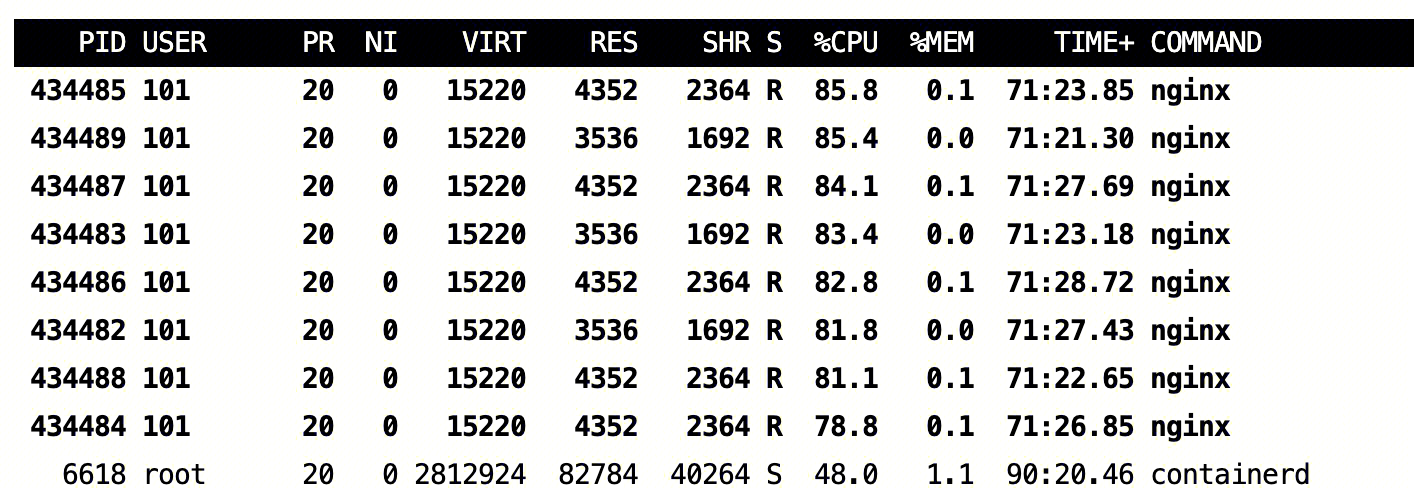
在线业务使用的内存超节点阈值情况
使用以下 workload,模拟内存消耗很大的在线业务:
apiVersion: apps/v1kind: Deploymentmetadata:labels:k8s-app: online-sever-stressname: online-sever-stressspec:replicas: 1selector:matchLabels:k8s-app: online-sever-stresstemplate:metadata:labels:k8s-app: online-sever-stressspec:containers:- name: serverimage: polinux/stress-ngcommand:- sleep- "3600"resources:limits:cpu: "8"memory: 8192Mirequests:cpu: "2"memory: 256Mi
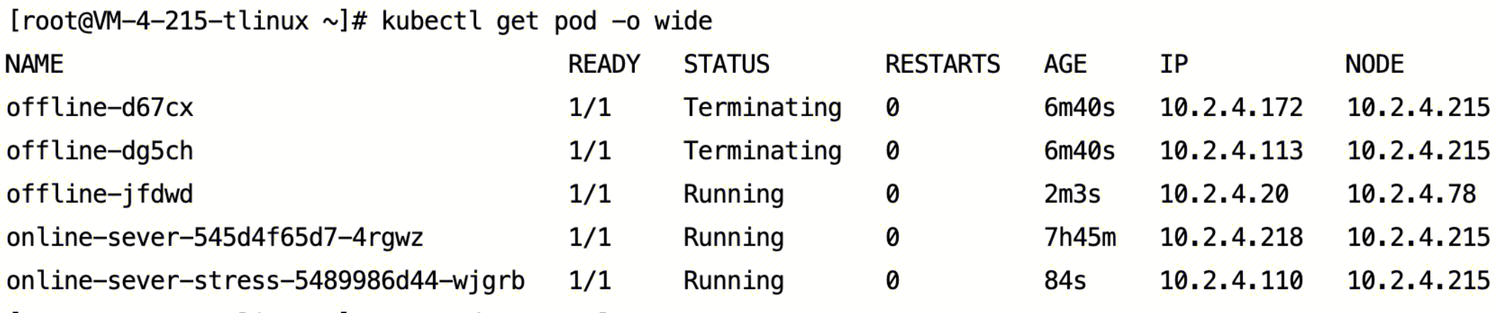
部署成功后,在 Pod 内执行
stress-ng --vm 7 --vm-bytes 1G --timeout 60s 命令,模拟对内存的占用。可以看到离线 Pod 被驱逐了。
混部配合 Kueue 使用 Gang 和队列等高级特性
部署 Kueue
使用 kubectl 快速安装版本kubectl apply --server-side -f https://github.com/kubernetes-sigs/kueue/releases/download/v0.14.1/manifests.yaml
说明:
由于网络环境原因,镜像 registry.k8s.io/kueue/kueue:v0.14.1 可能无法拉取,可以替换为镜像 ccr.ccs.tencentyun.com/qcloud/kueue:v0.14.1。
验证安装
# 检查 Kueue 组件状态kubectl get pods -n kueue-system# 输出如下NAME READY STATUS RESTARTS AGEkueue-controller-manager-5ff7ff7bcd-bdbbt 1/1 Running 0 147m
创建 ResourceFlavor
apiVersion: kueue.x-k8s.io/v1beta1kind: ResourceFlavormetadata:name: "default-flavor"
创建 ClusterQueue
apiVersion: kueue.x-k8s.io/v1beta1kind: ClusterQueuemetadata:name: cluster-queuespec:namespaceSelector: {} # 允许所有命名空间使用resourceGroups:- coveredResources: ["gocrane.io/cpu", "gocrane.io/memory"]flavors:- name: "default-flavor"resources:- name: "gocrane.io/cpu"nominalQuota: 8- name: "gocrane.io/memory"nominalQuota: 4Gi
创建 LocalQueue
kind: LocalQueuemetadata:namespace: defaultname: user-queuespec:clusterQueue: cluster-queue
离线 Job 指定使用该 LocalQueue
apiVersion: batch/v1kind: Jobmetadata:generateName: sample-job-namespace: defaultlabels:kueue.x-k8s.io/queue-name: user-queuespec:parallelism: 4completions: 4suspend: truetemplate:spec:containers:- name: dummy-jobimage: polinux/stress-ngcommand: [ "/bin/sh" ]args: [ "-c", "sleep 6000" ]resources:requests:gocrane.io/cpu: "1"gocrane.io/memory: "1Gi"limits:gocrane.io/cpu: "1"gocrane.io/memory: "1Gi"restartPolicy: Never
在 K8s 集群中运行该 Job 后,运行状态如下:
此时查看 Pod 的 yaml,可以确认 Pod 已经在使用扩展资源了。




