1. 背景
Spark on Kubernetes 结合了 Spark 强大的数据处理能力与 Kubernetes 卓越的容器编排能力,实现了资源的统一调度和弹性扩展。这不仅显著提升了集群的利用率,还简化了运维管理,为企业提供高效、低成本的大数据云原生解决方案。
针对许多在线业务集群 CPU 利用率偏低或存在显著的潮汐特性,可以利用 TKE 集群混部技术,实现 Spark 离线任务与在线任务的混合部署。在不影响在线业务 QoS 的前提下,进一步提升节点资源的利用率,从而有效降低整体成本。
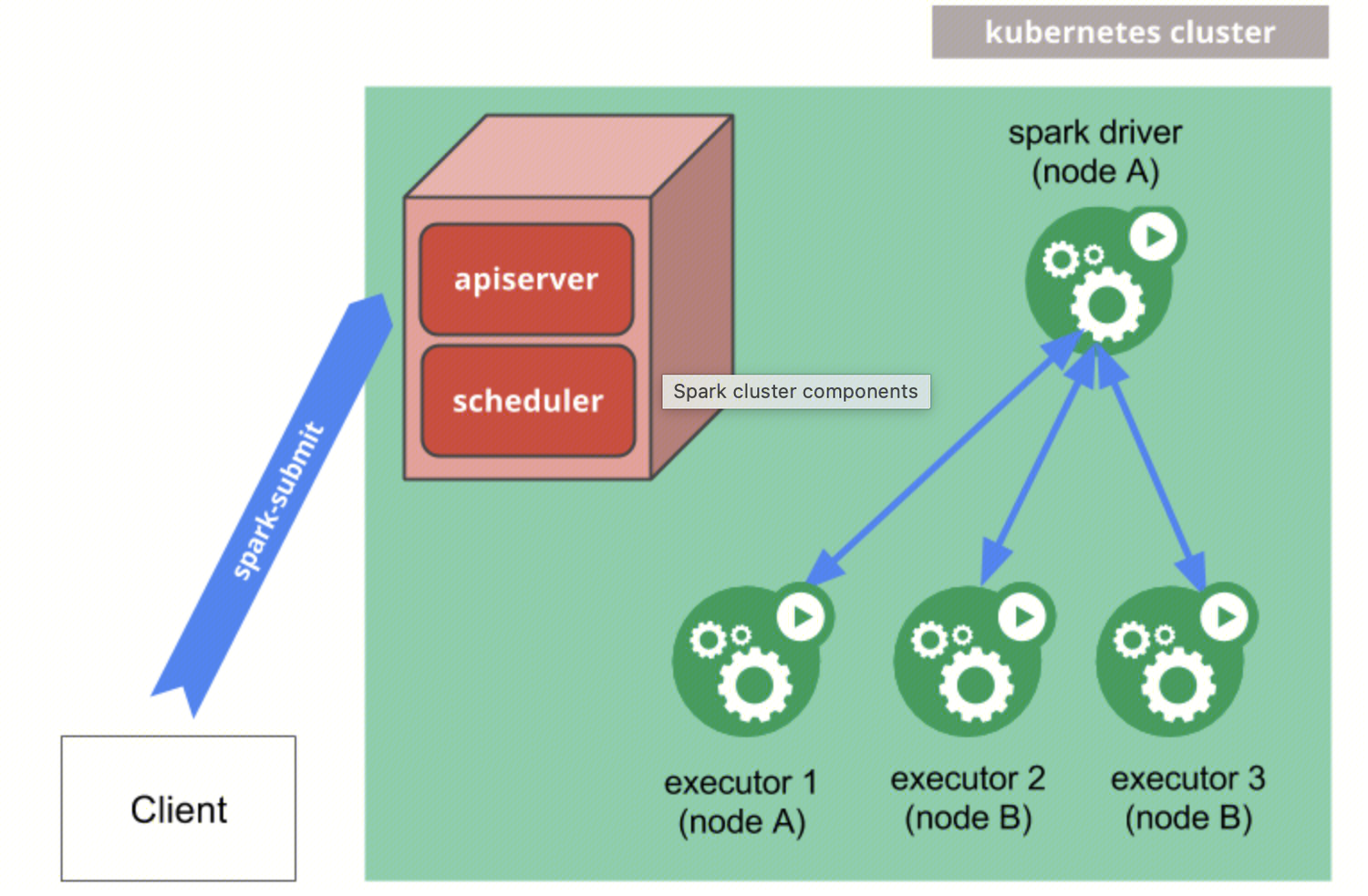
具体来说,Spark 首先通过客户端构建 driver pod 对象,并向 Kubernetes 的 apiserver 发送请求以创建 driver pod。Spark 的 driver 进程运行在 driver pod 中。driver 启动后,会在内部构建并创建这些 executor pod,同时通过 watch 和 list 等机制持续监听各 executor pod 的状态。任务执行结束后,executor pod 会被自动清理,而 driver pod 则会以 completed 状态继续保留。
2. 环境准备
参考文档 TKE 集群混部原理与部署介绍,准备 TKE 集群,确保集群包含可用的原生节点,并正确安装 craned 和 QoSAgent 组件。请确保 QoSAgent 组件已勾选 “CPU 使用优先级”、 “CPU 超线程隔离”、“网络 QoS 增强”三项能力。
3. 使用原生 spark-submit
3.1 安装 Spark 环境
在准备好的 TKE 集群的一台节点上,或任一可访问集群 ApiServer 的 CVM 上部署 Spark 环境:
mkdir /usr/local/service/cd /usr/local/service/wget https://archive.apache.org/dist/spark/spark-3.3.2/spark-3.3.2-bin-hadoop3.tgztar -xzvf spark-3.3.2-bin-hadoop3.tgzmv spark-3.3.2-bin-hadoop3 spark
在集群上部署 Spark 任务使用的 ServiceAccount:
首先创建名为 “workspark” 的 namespace。这里我们假设 Spark 相关的 pod 运行在该 namespace 中。
apiVersion: v1kind: ServiceAccountmetadata:name: sparknamespace: workspark---apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRoleBindingmetadata:name: spark-cluster-admin-binding-worksparksubjects:- kind: ServiceAccountname: sparknamespace: worksparkroleRef:kind: ClusterRolename: cluster-adminapiGroup: rbac.authorization.k8s.io
3.2 准备 podTemplate 文件
假设我们需要为 driver pod 申请2核2G的资源,创建 driver-pod-template.yaml:
apiVersion: v1kind: Podspec:containers:- name: spark-kubernetes-driverresources:limits:gocrane.io/cpu: "2"gocrane.io/memory: 2Girequests:gocrane.io/cpu: "2"gocrane.io/memory: 2Gi
注意:
这里需要使用
gocrane.io/cpu 和 gocrane.io/memory 扩展资源,K8s 才会把相关资源只调度到有离线资源可用的节点上。假设我们需要为 executor pod 申请2核2G的资源,创建 executor-pod-template.yaml:
apiVersion: v1kind: Podspec:containers:- name: spark-kubernetes-executorresources:limits:gocrane.io/cpu: "2"gocrane.io/memory: 2Girequests:gocrane.io/cpu: "2"gocrane.io/memory: 2Gi
注意:
这里需要使用
gocrane.io/cpu 和 gocrane.io/memory 扩展资源,K8s 才会把相关资源只调度到有离线资源可用的节点上。3.3 准备 PodQOS 规则
apiVersion: ensurance.crane.io/v1alpha1kind: PodQOSmetadata:name: podqos-sparkspec:labelSelector:matchExpressions:- key: spark-roleoperator: Invalues:- driver- executorresourceQOS:cpuQOS:cpuPriority: 7
说明:
这里通过匹配 driver pod 和 executor pod 的 label 来区分 spark-submit 提交后创建的 spark pod。
3.4 准备 spark-submit 命令
可以通过以下方式查看 Apiserver 的 URL:
$ kubectl cluster-infoKubernetes control plane is running at https://10.2.16.107......
在上述情况下,我们可以通过将 --master k8s://http://10.2.16.107 作为参数传递给 spark-submit 来将 spark 任务提交至该 Kubernetes 集群。
通过 spark-submit 提交以下任务:
/usr/local/service/spark/bin/spark-submit \\--master k8s://https://10.2.16.107 \\--deploy-mode cluster \\--name spark-pi \\--class org.apache.spark.examples.SparkPi \\--conf spark.executor.instances=2 \\--conf spark.kubernetes.namespace=workspark \\--conf spark.kubernetes.driver.container.image=ccr.ccs.tencentyun.com/use-test/spark:v3.3.2 \\--conf spark.kubernetes.executor.container.image=ccr.ccs.tencentyun.com/use-test/spark:v3.3.2 \\--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \\--conf spark.kubernetes.driver.podTemplateFile=./driver-pod-template.yaml \\--conf spark.kubernetes.executor.podTemplateFile=./executor-pod-template.yaml \\--conf spark.kubernetes.driver.limit.cores=2 \\--conf spark.kubernetes.driver.request.cores=0 \\--conf spark.kubernetes.executor.limit.cores=2 \\--conf spark.kubernetes.executor.request.cores=0 \\--conf spark.driver.memory=2g \\--conf spark.executor.memory=2g \\local:///opt/spark/examples/jars/spark-examples_2.12-3.3.2.jar 20000
命令参数说明如下:
3.4.1 基础部分
1. 通过
--conf spark.executor.instances 指定 executor pod 的数量。2. 通过
--conf spark.kubernetes.namespace 指定的 namespace 应与创建 ServiceAccount 时一致,此处使用 “workspark”。3.4.2 镜像部分
通过
--conf spark.kubernetes.driver.container.image 和 --conf spark.kubernetes.executor.container.image 指定自己编译的要运行的镜像。3.4.3 Pod 模板部分
我们需要让 spark pod 使用集群的离线资源。因为
gocrane.io/cpu 和 gocrane.io/memory 属于扩展资源,spark-submit 要求这类扩展资源放在 pod 模板文件中。请根据实际资源需求,变更相关 pod 模板中资源的值。3.4.4 resources 要求说明
1. CPU 资源部分:
(1)通过
--conf spark.kubernetes.{driver,executor}.request.cores 指定为0。(2)通过
--conf spark.kubernetes.{driver,executor}.limit.cores 指定为规划的 limit 的值。2. 内存资源部分:
需要主动通过
--conf spark.driver.memory 指定内存 limit 要求的大小。3.5 提交命令并查看 pod 状态
1. 查看运行的 spark pod 的 yaml,可以确认 driver pod 和 executor pod 是否按预期使用了 “gocrane.io/cpu” 和 “gocrane.io/memory” 的资源。
2. 查看 spark pod 是否包含 key 为 “gocrane.io/cpu-qos” 和 “gocrane.io/qos” 的 Annotation。当 pod 有了这些特定的 Annotation,代表已经正确使用了对应的离线资源。
3.6 Spark-submit 配合 Volcano 提交任务
3.6.1 部署 Volcano
参考 Volcano 官网,可以通过如下方式对 Volcano 进行安装。
helm repo add volcano-sh https://volcano-sh.github.io/helm-chartshelm repo updatehelm install volcano volcano-sh/volcano -n volcano-system --create-namespace
说明:
安装完成后通过
kubectl get all -n volcano-system 确认 volcano-controllers、volcano-scheduler 等 pod 已经处于 Running 状态。 3.6.2 准备支持 Volcano 的 Spark 版本
因为需要通过 spark-submit 使用 Volcano 相关高级特性,需要参阅 Apache Spark 文档中 https://dlcdn.apache.org/spark/docs/3.3.2/running-on-kubernetes.html#build 小节,重新编译部署的 spark 版本:

说明:
为通过实验验证功能,我们也可以通过将 spark-kubernetes_2.12-3.3.2.jar、volcano-client-5.12.2.jar、volcano-model-v1beta1-5.12.2.jar 三个 jar 包拷贝进我们对应 jars 目录(如 /usr/local/service/spark/jars)的方法,来满足这里 Spark 版本需求。
3.6.3 准备支持 Volcano 的 Spark 镜像
因为需要使用 Volcano 高级特性,Spark 镜像需包含相关 jar 包。
这里作为实验,我们可以通过以下 Dockerfile.patch 来构建我们测试使用的支持 Volcano 的镜像:
FROM ccr.ccs.tencentyun.com/use-test/spark:v3.3.2COPY spark-kubernetes_2.12-3.3.2.jar /opt/spark/jars/COPY volcano-client-5.12.2.jar /opt/spark/jars/COPY volcano-model-v1beta1-5.12.2.jar /opt/spark/jars/
3.6.4 准备 Volcano 队列
按照实际情况,创建我们要使用的 Volcano 队列。这里假设我们的 Volcano 队列名字为 “sparkqueue”。
apiVersion: scheduling.volcano.sh/v1beta1kind: Queuemetadata:name: sparkqueuespec:weight: 1reclaimable: falsecapability:gocrane.io/cpu: 20gocrane.io/memory: 100Gi
3.6.5 准备 podGroup 模板文件
apiVersion: scheduling.volcano.sh/v1beta1kind: PodGroupspec:# Specify minMember to 1 to make a driver podminMember: 1# Specify minResources to support resource reservation (the driver pod resource and executors pod resource should be considered)# It is useful for ensource the available resources meet the minimum requirements of the Spark job and avoiding the# situation where drivers are scheduled, and then they are unable to schedule sufficient executors to progress.minResources:gocrane.io/cpu: "6"gocrane.io/memory: "6Gi"# Specify the priority, help users to specify job priority in the queue during scheduling.priorityClassName: system-node-critical# Specify the queue, indicates the resource queue which the job should be submitted toqueue: sparkqueue
说明:
1. 如官方注释所要求:minMember 这里需要设置为 1,请勿修改。
2. minResources 中
gocrane.io/cpu 和 gocrane.io/memory 可以按实际情况进行配置。这里指定为 driver pod 和 executor pod 对资源需求的和。3. 通过 queue 可以指定使用的 Volcano 队列。这里我们指定使用我们创建的名字为 “sparkqueue” 的队列。
3.6.6 准备 spark-submit 命令
/usr/local/service/spark/bin/spark-submit \\--master k8s://https://10.2.16.107 \\--deploy-mode cluster \\--name spark-pi \\--class org.apache.spark.examples.SparkPi \\--conf spark.executor.instances=2 \\--conf spark.kubernetes.namespace=workspark \\--conf spark.kubernetes.driver.container.image=ccr.ccs.tencentyun.com/use-test/spark:v3.3.2-volcano-patch3 \\--conf spark.kubernetes.executor.container.image=ccr.ccs.tencentyun.com/use-test/spark:v3.3.2-volcano-patch3 \\--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \\--conf spark.kubernetes.driver.podTemplateFile=./driver-pod-template.yaml \\--conf spark.kubernetes.executor.podTemplateFile=./executor-pod-template.yaml \\--conf spark.kubernetes.driver.limit.cores=2 \\--conf spark.kubernetes.driver.request.cores=0 \\--conf spark.kubernetes.executor.limit.cores=2 \\--conf spark.kubernetes.executor.request.cores=0 \\--conf spark.driver.memory=2g \\--conf spark.executor.memory=2g \\--conf spark.kubernetes.scheduler.name=volcano \\--conf spark.kubernetes.driver.pod.featureSteps=org.apache.spark.deploy.k8s.features.VolcanoFeatureStep \\--conf spark.kubernetes.executor.pod.featureSteps=org.apache.spark.deploy.k8s.features.VolcanoFeatureStep \\--conf spark.kubernetes.scheduler.volcano.podGroupTemplateFile=./podgroup-template-gocrane.yaml \\local:///opt/spark/examples/jars/spark-examples_2.12-3.3.2.jar 20000
说明:
这里增加了如下几行配置:
--conf spark.kubernetes.scheduler.name=volcano \\
--conf spark.kubernetes.driver.pod.featureSteps=org.apache.spark.deploy.k8s.features.VolcanoFeatureStep \\
--conf spark.kubernetes.executor.pod.featureSteps=org.apache.spark.deploy.k8s.features.VolcanoFeatureStep \\
--conf spark.kubernetes.scheduler.volcano.podGroupTemplateFile=./podgroup-template-gocrane.yaml
其中这里最后一行配置需要指定上文中准备好的 podGroup 模板文件的路径。
另外,需要注意的是,这里我们需要使用新构建的支持 Volcano 的镜像。
3.6.7 提交命令并查看 pod 状态
提交命令,可以看到首先会创建一个 driver pod,然后会创建出来两个 executor pod。我们依次验证相关状态,可以看到:
1. 在driver pod 和 executor pod 的 yaml 中会指定 schedulerName: volcano。表明 spark pod 已经在使用 Volcano 调度器了。
2. 通过
kubectl describe 命令查看 driver pod 和 executor pod,可以看到 “Normal Scheduled 29m volcano Successfully assigned workspark/xxxx-xxxxx to xxxxNode” 类似的 Event(事件)。3. 在 driver pod 和 executor pod 的 Annotation中,都可以看到 key 为 “scheduling.k8s.io/group-name” 的行,类似如下:
scheduling.k8s.io/group-name: spark-d41b280c285741b9b6d3a2d3f3cf6eec-podgroup 这表明 driver pod 和 executor pod 共同使用的是同一个 podGroup。查看该 podGroup,类似如下,相关参数正是我们 podGroup 模板指定的:
apiVersion: scheduling.volcano.sh/v1beta1kind: PodGroupmetadata:name: spark-0ed23d5712a04c76ab15935d7fd6c49b-podgroupnamespace: worksparkspec:minMember: 1minResources:gocrane.io/cpu: "6"gocrane.io/memory: 6GipriorityClassName: system-node-criticalqueue: sparkqueuestatus:conditions:- lastTransitionTime: "2025-11-04T08:53:06Z"reason: tasks in gang are ready to be scheduledstatus: "True"transitionID: f8e70311-3b30-4a01-8b00-4c0de38fced4type: Scheduledphase: Completedsucceeded: 1
在 driver pod 和 executor pod 运行期间,查看 “sparkqueue” 这个Volcano 队列的状态,表明我们的 spark pod 已经占用了本队列的部分资源:
apiVersion: scheduling.volcano.sh/v1beta1kind: Queuemetadata:annotations:name: sparkqueueresourceVersion: "1305744284"uid: b88f3034-0e5f-487d-9ad1-a3e9b9781f66spec:capability:gocrane.io/cpu: 10gocrane.io/memory: 20Giparent: rootreclaimable: falseweight: 4status:allocated:gocrane.io/cpu: "6"gocrane.io/memory: "6442450944"memory: 7296Mipods: "3"tke.cloud.tencent.com/eni-ip: "3"reservation: {}state: Open
4. 使用 Spark on K8s Operator
Spark Operator 是专为在 Kubernetes 集群中运行 Spark 工作负载而设计,旨在自动化管理 Spark 作业的生命周期。通过 SparkApplication 等 CRD 资源,您可以灵活提交和管理 Spark 作业。利用 Kubernetes 的自动扩展、健康检查和资源管理等特性,Spark Operator 可以更有效地监控和优化 Spark 作业的运行。
相比 spark-submit 的使用优势:
简化管理:通过 Kubernetes 的声明式作业配置,自动化部署 Spark 作业并管理作业的生命周期。
弹性资源供给:利用原生节点池等弹性资源,可在业务高峰期快速获得大量弹性资源,平衡性能和成本。
适用场景:
数据分析:数据科学家可以利用 Spark 进行交互式数据分析和数据清洗等。
批量数据计算:运行定时批处理作业,处理大规模数据集。
实时数据处理:Spark Streaming 库提供了对实时数据进行流式处理的能力。
4.1 部署 Spark Operator 环境
依次执行如下命令,部署 Spark Operator 运行相关资源。
helm repo add spark-operator https://kubeflow.github.io/spark-operatorhelm repo updatehelm install spark-operator spark-operator/spark-operator --version 2.3.0 --namespace spark-operator --create-namespace --set controller.batchScheduler.enable=true
部署后,检查确认 spark-operator-controller、spark-operator-webhook pod 已经处于 Running 状态。
注意:
这里有可能遇到镜像拉取的问题,原始镜像地址为 ghcr.io/kubeflow/spark-operator/controller:2.3.0,如果该地址不能访问,可以变更为 ccr.ccs.tencentyun.com/use-test/spark-operator:controller-2.3.0 用于测试。
4.2 准备 SparkApplication 任务
apiVersion: "sparkoperator.k8s.io/v1beta2"kind: SparkApplicationmetadata:name: spark-pinamespace: defaultspec:arguments:- "10000"type: Scalamode: clusterimage: "apache/spark:v3.3.2"imagePullPolicy: AlwaysmainClass: org.apache.spark.examples.SparkPimainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.12-3.3.2.jar"sparkVersion: "3.3.2"restartPolicy:type: Nevervolumes:- name: "test-volume"hostPath:path: "/tmp"type: Directorydriver:memory: "2g"template:spec:containers:- name: spark-kubernetes-driverresources:limits:gocrane.io/cpu: "2"gocrane.io/memory: "2Gi"requests:gocrane.io/cpu: "2"gocrane.io/memory: "2Gi"labels:version: 3.3.2serviceAccount: sparkvolumeMounts:- name: "test-volume"mountPath: "/tmp"executor:instances: 2memory: "2g"template:spec:containers:- name: spark-kubernetes-executorresources:limits:gocrane.io/cpu: "2"gocrane.io/memory: "2Gi"requests:gocrane.io/cpu: "2"gocrane.io/memory: "2Gi"labels:version: 3.3.2volumeMounts:- name: "test-volume"mountPath: "/tmp"
部署该应用后:
1. 查看 spark pod 的资源已经按预期使用了 “gocrane.io/cpu” 和 “gocrane.io/memory” 相关扩展资源。
2. 查看 driver pod 和 executor pod 是否有 key 为 “gocrane.io/cpu-qos” 和 “gocrane.io/qos” 的Annotation,如果有这些 Annotation,代表已经正确使用了相关的离线资源。
4.3 Spark Operator 配合 Volcano 运行 Spark 任务
4.3.1 部署 Volcano
helm repo add spark-operator https://kubeflow.github.io/spark-operatorhelm install my-release spark-operator/spark-operator --version 2.3.0 \\--namespace spark-operator \\--create-namespace \\--set webhook.enable=true \\--set controller.batchScheduler.enable=true
注意:
这里需要依赖 Volcano 打开 batchScheduler 特性:controller.batchScheduler.enable=true
4.3.2 准备 Volcano 队列
4.3.3 准备使用 Volcano 的 SparkApplication 任务
apiVersion: "sparkoperator.k8s.io/v1beta2"kind: SparkApplicationmetadata:name: spark-pinamespace: defaultspec:arguments:- "10000"type: Scalamode: clusterimage: "apache/spark:v3.3.2"imagePullPolicy: AlwaysmainClass: org.apache.spark.examples.SparkPimainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.12-3.3.2.jar"sparkVersion: "3.3.2"batchScheduler: volcano # 新增batchSchedulerOptions: # 新增queue: "sparkqueue"restartPolicy:type: Nevervolumes:- name: "test-volume"hostPath:path: "/tmp"type: Directorydriver:memory: "2g"template:spec:containers:- name: spark-kubernetes-driverresources:limits:gocrane.io/cpu: "2"gocrane.io/memory: "2Gi"requests:gocrane.io/cpu: "2"gocrane.io/memory: "2Gi"labels:version: 3.3.2serviceAccount: sparkvolumeMounts:- name: "test-volume"mountPath: "/tmp"executor:instances: 2memory: "2g"template:spec:containers:- name: spark-kubernetes-executorresources:limits:gocrane.io/cpu: "2"gocrane.io/memory: "2Gi"requests:gocrane.io/cpu: "2"gocrane.io/memory: "2Gi"labels:version: 3.3.2volumeMounts:- name: "test-volume"mountPath: "/tmp"
说明:
其中以下部分为新增:
1. batchScheduler: Volcano 指定了 driver pod 和 executor pod 使用 Volcano 调度器。
2. batchSchedulerOptions: queue: "sparkqueue" 部分,指定了使用名字为 “sparkqueue” 的 Volcano queue。
4.3.4 部署 SparkApplication 任务并查看 pod 状态
1. 在 driver pod 和 executor pod 的 yaml 可发现 schedulerName 已经设置为 Volcano,表明已经在使用 Volcano 调度器了。
2. 通过
kubectl describe 命令查看 driver pod 和 executor pod,可以看到 “Normal Scheduled 10m Volcano Successfully assigned workspark/xxxx-xxxxx to xxxxNode” 类似的 Event(事件)。3. 在 driver pod 和 executor pod 的 Annotation中,都可以看到 key 为 “scheduling.k8s.io/group-name” 的行:
scheduling.k8s.io/group-name: spark-spark-pi-pg这表明 driver pod 和 executor pod 已经共同使用了同一个 podGroup。
查看这个 podGroup,类似如下,相关参数正是我们 podGroup 模板指定的:
apiVersion: scheduling.volcano.sh/v1beta1kind: PodGroupmetadata:name: spark-spark-pi-pgnamespace: defaultspec:minMember: 1minResources: {}queue: sparkqueuestatus:conditions:- lastTransitionTime: "2025-11-04T10:07:20Z"reason: tasks in gang are ready to be scheduledstatus: "True"transitionID: 28ba9ce7-c84c-438e-a71d-a02ef3459011type: Scheduledphase: Runningrunning: 3
4. 在 driver pod 和 executor pod 运行期间,查看 “sparkqueue” 这个 Volcano 队列的状态,表明我们的 spark pod 已经占用了本队列的部分资源:
apiVersion: scheduling.volcano.sh/v1beta1kind: Queuemetadata:name: sparkqueuespec:capability:gocrane.io/cpu: 10gocrane.io/memory: 20Giparent: rootreclaimable: falseweight: 4status:allocated:gocrane.io/cpu: "6"gocrane.io/memory: "6442450944"memory: 7296Mipods: "3"tke.cloud.tencent.com/eni-ip: "3"reservation: {}state: Open



